当前位置:网站首页>Strengthen basic learning records
Strengthen basic learning records
2022-07-06 13:52:00 【I like the strengthened Xiaobai in Curie】
Actor-Critic Strengthen learning record
Reinforcement learning algorithms are roughly divided into three categories ,value-based、policy-based And the combination of the two Actor-Critic, Here is a brief description of the recent right AC Learning experience of .
One 、 Introduction to the environment
What we use here is gym Environmental ’CartPole-v1’, This environment is similar to that of the previous article ’CartPole-v0’ There's almost no difference , The main difference lies in the definition of the maximum number of steps per round and the reward , As shown in the figure below .
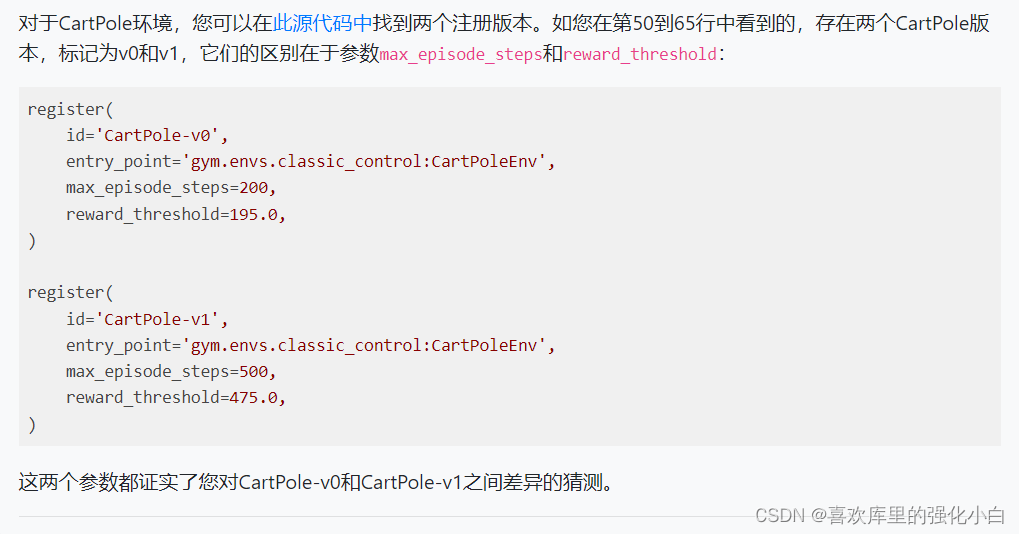
In this paper , Want to try to combine On-Policy The algorithm of , Therefore, the maximum number of steps in a single round is limited , The size is 100.
'CartPole-v0’ The detailed introduction of the environment is attached with a link .
link : OpenAI Gym Introduction to classic control environment ——CartPole( Inverted pendulum )
Two 、 A brief introduction to the algorithm
- Actor-Critic
The algorithm has two frameworks , That is, strategy related Actor Network and value related Critic The Internet . Because the randomness strategy is adopted here , therefore Actor The Internet takes advantage of softmax Function normalizes the probability ;Critic For network utilization v Values are calculated . Besides , So this is taking advantage of A2C The dominance function of (Advantage).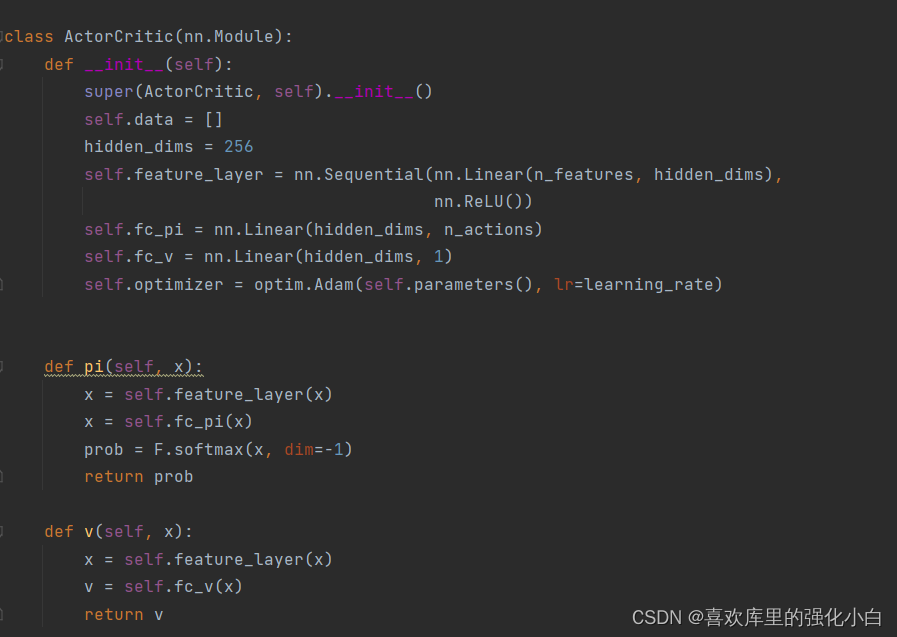
- On-Policy
Here we take On-Policy The algorithm of , Pay attention to each round 100 Step game , Will produce 100 strip transition, Wait for these transition After storage , Begin to learn , Use this directly 100 Samples , And empty the sample , In order to get new samples in the next round .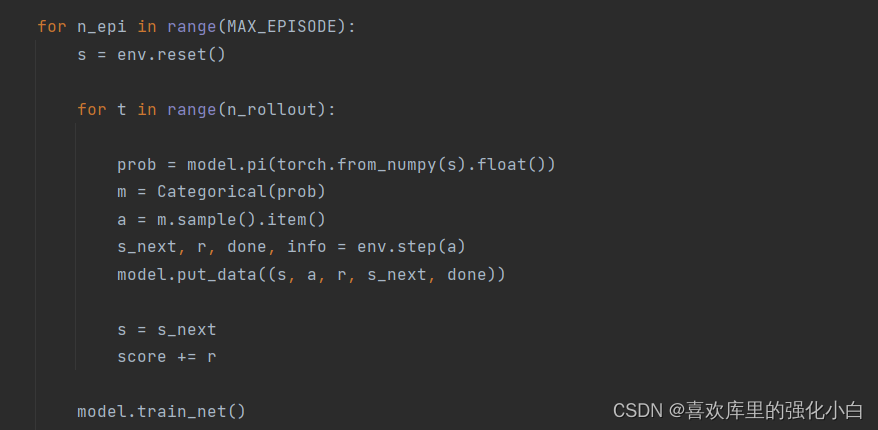
- AC(A2C) Pseudo code :


- Realization
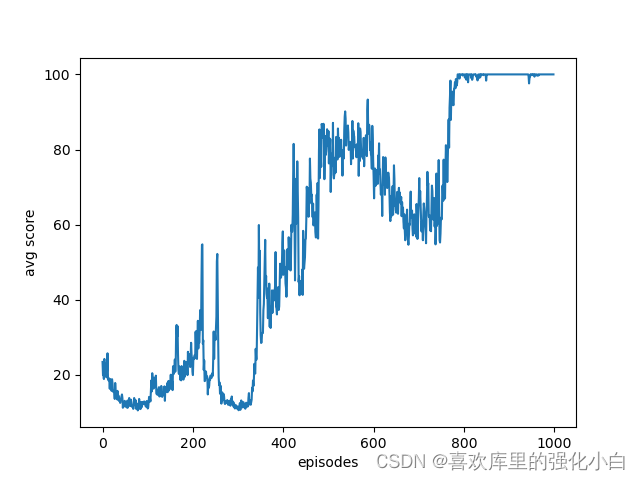
The implementation here refers to the online tutorial , But the source code is just Policy-Gradient Methods , Here is a simple modification . Besides , Here is the randomness strategy , Itself increases the exploratory , Different from the previous deterministic strategy , Yes torch The sampling function of , The details have not been studied . The results are also attached in the figure below , You can see that after training , Rewards basically converge to 100.
import gym
import numpy
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
import matplotlib.pyplot as plt
# Hyperparameters
learning_rate = 0.0002
gamma = 0.98
n_rollout = 100
MAX_EPISODE = 20000
RENDER = False
env = gym.make('CartPole-v1')
env = env.unwrapped
env.seed(1)
torch.manual_seed(1)
#print("env.action_space :", env.action_space)
#print("env.observation_space :", env.observation_space)
n_features = env.observation_space.shape[0]
n_actions = env.action_space.n
class ActorCritic(nn.Module):
def __init__(self):
super(ActorCritic, self).__init__()
self.data = []
hidden_dims = 256
self.feature_layer = nn.Sequential(nn.Linear(n_features, hidden_dims),
nn.ReLU())
self.fc_pi = nn.Linear(hidden_dims, n_actions)
self.fc_v = nn.Linear(hidden_dims, 1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x):
x = self.feature_layer(x)
x = self.fc_pi(x)
prob = F.softmax(x, dim=-1)
return prob
def v(self, x):
x = self.feature_layer(x)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_next_lst, done_lst = [], [], [], [], []
for transition in self.data:
s, a, r, s_, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r / 100.0])
s_next_lst.append(s_)
done_mask = 0.0 if done else 1.0
done_lst.append([done_mask])
s_batch, a_batch, r_batch, s_next_batch, done_batch = torch.tensor(numpy.array(s_lst),
dtype=torch.float), torch.tensor(
a_lst), torch.tensor(numpy.array(r_lst), dtype=torch.float), torch.tensor(
numpy.array(s_next_lst), dtype=torch.float), torch.tensor(
numpy.array(done_lst), dtype=torch.float)
self.data = []
return s_batch, a_batch, r_batch, s_next_batch, done_batch
def train_net(self):
s, a, r, s_, done = self.make_batch()
td_target = r + gamma * self.v(s_) * done
delta = td_target - self.v(s)
def critic_learn():
loss_func = nn.MSELoss()
loss1 = loss_func(self.v(s),td_target)
self.optimizer.zero_grad()
loss1.backward()
self.optimizer.step()
def actor_learn():
pi = self.pi(s)
pi_a = pi.gather(1, a)
loss = -torch.log(pi_a) * delta.detach() + F.smooth_l1_loss(self.v(s), td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
critic_learn()
actor_learn()
def main():
model = ActorCritic()
print_interval = 20
score = 0.0
avg_returns = []
for n_epi in range(MAX_EPISODE):
s = env.reset()
for t in range(n_rollout):
prob = model.pi(torch.from_numpy(s).float())
m = Categorical(prob)
a = m.sample().item()
s_next, r, done, info = env.step(a)
model.put_data((s, a, r, s_next, done))
s = s_next
score += r
model.train_net()
if n_epi % print_interval == 0 and n_epi != 0:
avg_score = score / print_interval
print("# of episode :{}, avg score : {:.1f}".format(n_epi, score / print_interval))
avg_returns.append(avg_score)
score = 0.0
env.close()
plt.figure()
plt.plot(range(len(avg_returns)),avg_returns)
plt.xlabel('episodes')
plt.ylabel('avg score')
plt.savefig('./plt_ac.png',format= 'png')
if __name__ == '__main__':
main()
边栏推荐
- Leetcode.3 无重复字符的最长子串——超过100%的解法
- Read only error handling
- [the Nine Yang Manual] 2018 Fudan University Applied Statistics real problem + analysis
- Implementation of count (*) in MySQL
- 9. Pointer (upper)
- Yugu p1012 spelling +p1019 word Solitaire (string)
- Canvas foundation 1 - draw a straight line (easy to understand)
- 这次,彻底搞清楚MySQL索引
- 【educoder数据库实验 索引】
- 【九阳神功】2017复旦大学应用统计真题+解析
猜你喜欢
canvas基础1 - 画直线(通俗易懂)
自定义RPC项目——常见问题及详解(注册中心)

1. First knowledge of C language (1)
4. Branch statements and loop statements
A comprehensive summary of MySQL transactions and implementation principles, and no longer have to worry about interviews

1. Preliminary exercises of C language (1)
MATLAB打开.m文件乱码解决办法

PriorityQueue (large root heap / small root heap /topk problem)
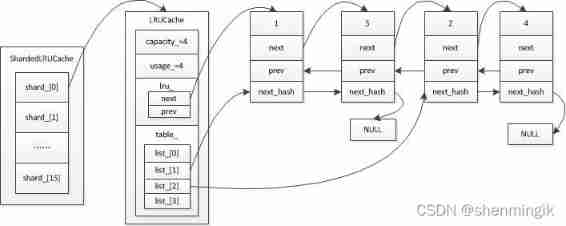
Caching mechanism of leveldb

2. First knowledge of C language (2)
随机推荐
[the Nine Yang Manual] 2018 Fudan University Applied Statistics real problem + analysis
力扣152题乘数最大子数组
The difference between cookies and sessions
实验九 输入输出流(节选)
2022泰迪杯数据挖掘挑战赛C题思路及赛后总结
杂谈0516
TypeScript快速入门
Inaki Ading
String abc = new String(“abc“),到底创建了几个对象
Principles, advantages and disadvantages of two persistence mechanisms RDB and AOF of redis
5月27日杂谈
The latest tank battle 2022 - Notes on the whole development -2
[hand tearing code] single case mode and producer / consumer mode
Implementation principle of automatic capacity expansion mechanism of ArrayList
甲、乙机之间采用方式 1 双向串行通信,具体要求如下: (1)甲机的 k1 按键可通过串行口控制乙机的 LEDI 点亮、LED2 灭,甲机的 k2 按键控制 乙机的 LED1
强化学习系列(一):基本原理和概念
【九阳神功】2018复旦大学应用统计真题+解析
Service ability of Hongmeng harmonyos learning notes to realize cross end communication
7. Relationship between array, pointer and array
PriorityQueue (large root heap / small root heap /topk problem)