当前位置:网站首页>ACL 2022 | small sample ner of sequence annotation: dual tower Bert model integrating tag semantics
ACL 2022 | small sample ner of sequence annotation: dual tower Bert model integrating tag semantics
2022-07-07 12:46:00 【PaperWeekly】

author | SinGaln
This is an article from ACL 2022 The article , The general idea is meta-learning On the basis of , Adopt double towers BERT The model is used to match the text characters and the corresponding label Encoding , And carry out the two Dot Product( Point multiplication ) Get the output to do a classification . The article is not complicated on the whole , There are few formulas involved , It is easy to understand the author's ideas . For serial annotation NER It's a good idea .

Paper title :
Label Semantics for Few Shot Named Entity Recognition
Thesis link :
https://arxiv.org/pdf/2203.08985.pdf

Model
1.1 framework
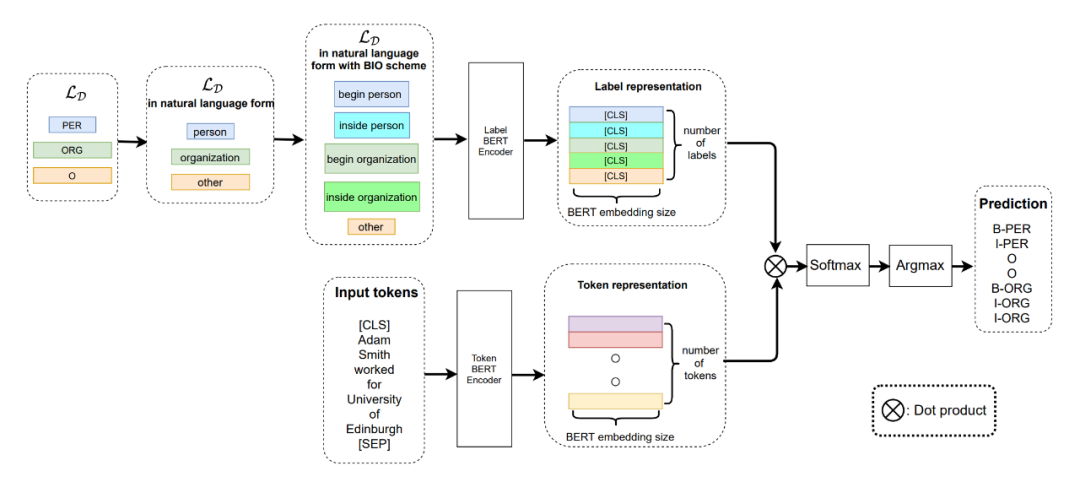
▲ chart 1. The overall framework of the model
You can see clearly from the picture above , The author adopts double towers BERT To separate the text Token And each Token Corresponding label Encoding . Here, the author's idea of adopting this method is also very simple , the reason being that Few-shot Mission , There's not enough data , So the author thinks that every Token Of label It can be for Token Provide additional semantic information .
The author's Meta-Learning It's using metric-based Method , An intuitive understanding is to calculate each sample first Token The vector representation of , Then compare with the calculated label Characterization calculation similarity , Here, from the Dot Product It can be intuitively reflected . Then the similarity matrix obtained ([batch_size,sequence_length,embed_dim]) Conduct softmax normalization , adopt argmax The function takes the one with the largest median in the last dimension index, And corresponding tag list , Get the present Token Corresponding label .
1.2 Detail
Besides , When the author characterizes the label , Each label is also processed accordingly , In general, it is divided into the following three steps :
1. Change the abbreviation labels of words into natural language forms , for example PER-->person,ORG-->organization,LOC-->local wait ;
2. Start the label 、 The middle mark turns into natural language form , For example BIO If the form is marked, it can be changed into begin、inside、other wait , Other annotation forms are similar .
3. Combine after conversion according to the method of the previous two steps , for example B-PER-->begin person,I-PER-->inside person.
Because what is going on is Few-shot NER Mission , So the author is in many source datasets The training model above , Then they're in multiple unseen few shot target datasets The above verification has passed fine-tuning And without going through fine-tuning The effect of the model .
It's going on Token When coding , For each adopt BERT The model can get its corresponding vector , As shown below :
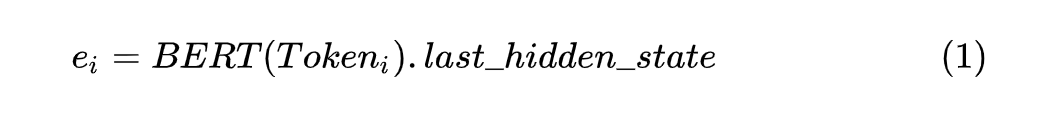
What needs to be noted here is BERT The output of the model is last_hidden_state As the corresponding Token Vector .
When encoding labels , Encode all tags in the tag set , Each complete label The obtained code is Part as its coding vector , And put all label Codes form a set of vectors , Finally, calculate each And The dot product , Form the following :
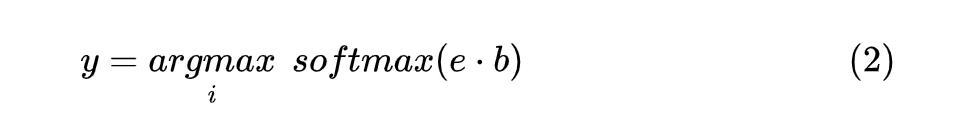
Because it's used here label The way of coding representation , Compared with other NER Method , Encounter new data and label when , There is no need to initiate a new top-level classifier , To achieve Few-shot Purpose .
1.3 Label Transfer
In the article, the author also lists the label conversion table of the experimental data set , Part of it is as follows :
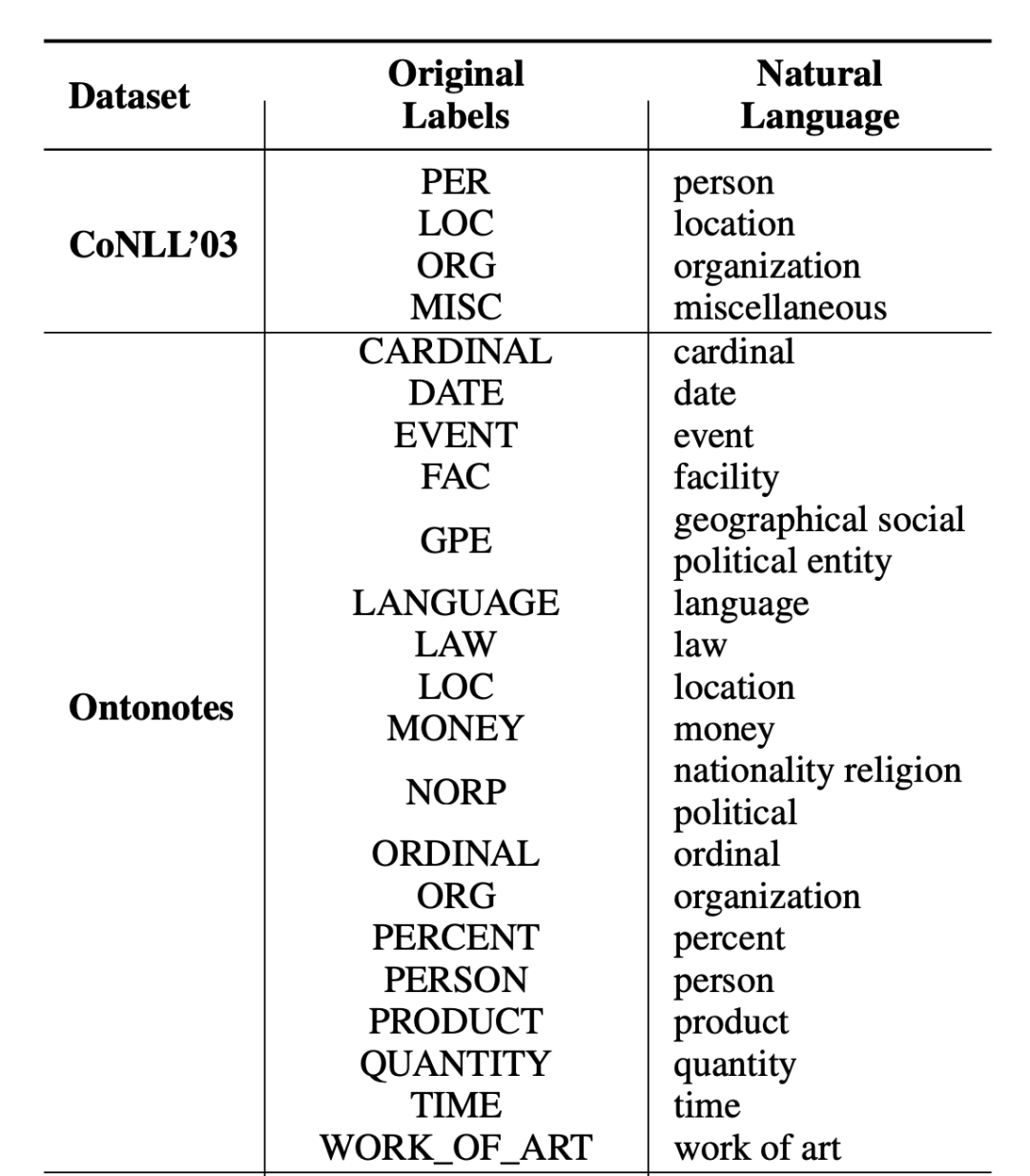
▲ chart 2. Experimental data sets Label Transfer
1.4 Support Set Sampling Algorithm
The sampling pseudocode is as follows :

▲ chart 3. Sampling pseudocode

experimental result
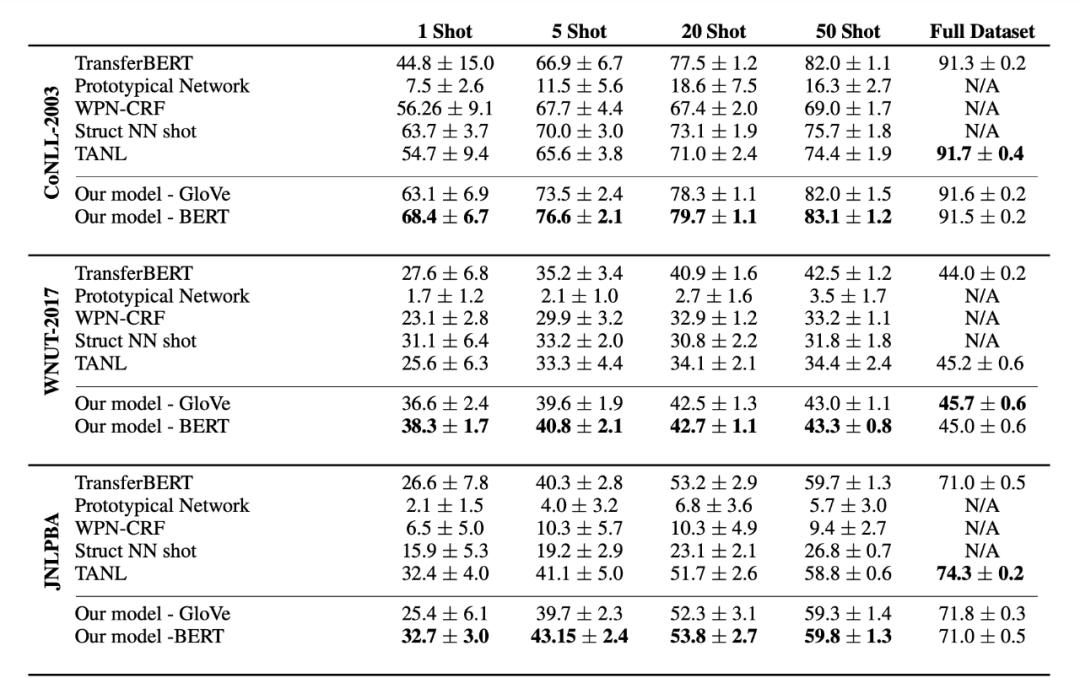
▲ chart 4. Some experimental results
From the experimental results , You can obviously feel this method in Few-shot It still has a good effect , stay 1-50 shot The effect of time model is better than that of other models , Shows label Semantic validity ; But in full data , This method is discounted , It shows that the larger the amount of data , The model is for label The less semantic dependency . Here, the author also has a point of view that under the full amount of data , The introduction of tag semantics in this way may slightly offset the original text semantics , Of course , That's the way it's said Few-shot Next is also established , It's just Few-shot The lower offset is a positive offset , It can enhance the generalization ability of the model , The offset under the full amount of data is a little overflowing .
Two towers BERT Code implementation ( There is no metric-based Method ):
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2022/5/23 13:49
# @Author : SinGaln
import torch
import torch.nn as nn
from transformers import BertModel, BertPreTrainedModel
class SinusoidalPositionEmbedding(nn.Module):
""" Definition Sin-Cos Location Embedding
"""
def __init__(
self, output_dim, merge_mode='add'):
super(SinusoidalPositionEmbedding, self).__init__()
self.output_dim = output_dim
self.merge_mode = merge_mode
def forward(self, inputs):
input_shape = inputs.shape
batch_size, seq_len = input_shape[0], input_shape[1]
position_ids = torch.arange(seq_len, dtype=torch.float)[None]
indices = torch.arange(self.output_dim // 2, dtype=torch.float)
indices = torch.pow(10000.0, -2 * indices / self.output_dim)
embeddings = torch.einsum('bn,d->bnd', position_ids, indices)
embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)
embeddings = embeddings.repeat((batch_size, *([1] * len(embeddings.shape))))
embeddings = torch.reshape(embeddings, (batch_size, seq_len, self.output_dim))
if self.merge_mode == 'add':
return inputs + embeddings.to(inputs.device)
elif self.merge_mode == 'mul':
return inputs * (embeddings + 1.0).to(inputs.device)
elif self.merge_mode == 'zero':
return embeddings.to(inputs.device)
class DoubleTownNER(BertPreTrainedModel):
def __init__(self, config, num_labels, position=False):
super(DoubleTownNER, self).__init__(config)
self.position = position
self.num_labels = num_labels
self.bert = BertModel(config=config)
self.fc = nn.Linear(config.hidden_size, self.num_labels)
if self.position:
self.sinposembed = SinusoidalPositionEmbedding(config.hidden_size, "add")
def forward(self, sequence_input_ids, sequence_attention_mask, sequence_token_type_ids, label_input_ids,
label_attention_mask, label_token_type_ids):
# Get text and labels encode
# [batch_size, sequence_length, embed_dim]
sequence_outputs = self.bert(input_ids=sequence_input_ids, attention_mask=sequence_attention_mask,
token_type_ids=sequence_token_type_ids).last_hidden_state
# [batch_size, embed_dim]
label_outputs = self.bert(input_ids=label_input_ids, attention_mask=label_attention_mask,
token_type_ids=label_token_type_ids).pooler_output
label_outputs = label_outputs.unsqueeze(1)
# Position vector
if self.position:
sequence_outputs = self.sinposembed(sequence_outputs)
# Dot Interaction
interactive_output = sequence_outputs * label_outputs
# full-connection
outputs = self.fc(interactive_output)
return outputs
if __name__=="__main__":
pretrain_path = "../bert_model"
from transformers import BertConfig
token_input_ids = torch.randint(1, 100, (32, 128))
token_attention_mask = torch.ones_like(token_input_ids)
token_token_type_ids = torch.zeros_like(token_input_ids)
label_input_ids = torch.randint(1, 10, (1, 10))
label_attention_mask = torch.ones_like(label_input_ids)
label_token_type_ids = torch.zeros_like(label_input_ids)
config = BertConfig.from_pretrained(pretrain_path)
model = DoubleTownNER.from_pretrained(pretrain_path, config=config, num_labels=10, position=True)
outs = model(sequence_input_ids=token_input_ids, sequence_attention_mask=token_attention_mask, sequence_token_type_ids=token_token_type_ids, label_input_ids=label_input_ids,
label_attention_mask=label_attention_mask, label_token_type_ids=label_token_type_ids)
print(outs, outs.size())Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
- Static vxlan configuration
- Is it safe to open an account in Ping An Securities mobile bank?
- ACL 2022 | 序列标注的小样本NER:融合标签语义的双塔BERT模型
- [statistical learning methods] learning notes - Chapter 4: naive Bayesian method
- Realize all, race, allsettled and any of the simple version of promise by yourself
- H3C HCl MPLS layer 2 dedicated line experiment
- Dialogue with Wang Wenyu, co-founder of ppio: integrate edge computing resources and explore more audio and video service scenarios
- Ctfhub -web SSRF summary (excluding fastcgi and redI) super detailed
- SQL blind injection (WEB penetration)
- 数据库安全的重要性
猜你喜欢
The IDM server response shows that you do not have permission to download the solution tutorial
leetcode刷题:二叉树20(二叉搜索树中的搜索)
Day-16 set

Static comprehensive experiment
Tutorial on principles and applications of database system (010) -- exercises of conceptual model and data model
Solutions to cross domain problems

Day-19 IO stream
Processing strategy of message queue message loss and repeated message sending
Common knowledge of one-dimensional array and two-dimensional array

浅谈估值模型 (二): PE指标II——PE Band
随机推荐
Attack and defense world ----- summary of web knowledge points
Pule frog small 5D movie equipment | 5D movie dynamic movie experience hall | VR scenic area cinema equipment
【PyTorch实战】用PyTorch实现基于神经网络的图像风格迁移
IPv6 experiment
Several ways to clear floating
leetcode刷题:二叉树24(二叉树的最近公共祖先)
Vxlan static centralized gateway
What is an esp/msr partition and how to create an esp/msr partition
SQL Lab (41~45) (continuous update later)
Polymorphism, final, etc
The left-hand side of an assignment expression may not be an optional property access.ts(2779)
金融数据获取(三)当爬虫遇上要鼠标滚轮滚动才会刷新数据的网页(保姆级教程)
visual stdio 2017关于opencv4.1的环境配置
leetcode刷题:二叉树23(二叉搜索树中的众数)
Configure an encrypted web server
SQL Lab (36~40) includes stack injection, MySQL_ real_ escape_ The difference between string and addslashes (continuous update after)
Simple implementation of call, bind and apply
The IDM server response shows that you do not have permission to download the solution tutorial
[pytorch practice] write poetry with RNN
【二叉树】删点成林