当前位置:网站首页>【统计学习方法】学习笔记——支持向量机(下)
【统计学习方法】学习笔记——支持向量机(下)
2022-07-07 10:28:00 【镰刀韭菜】
统计学习方法学习笔记——支持向量机(下)
3. 非线性支持向量机与核函数
非线性支持向量机,其主要特点是利用核技巧(kernel trick)。
3.1 核技巧
- 非线性分类问题、
非线性分类问题是指通过利用非线性模型才能很好地进行分类的问题。
一般来说,对给定的一个训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\} T={ (x1,y1),(x2,y2),...,(xN,yN)},其中,实例 x i x_i xi属于输入空间, x i ∈ X = R n x_i\in \mathcal{X}=R^n xi∈X=Rn,对应的类标记有两类 y i ∈ y = { − 1 , + 1 } , i = 1 , 2 , . . . , N y_i\in \mathcal{y}=\{-1, +1\}, i=1,2,...,N yi∈y={ −1,+1},i=1,2,...,N。如果能用 R n R^n Rn中的一个超曲面将正负例正确分来,则称这个问题为非线性可分问题。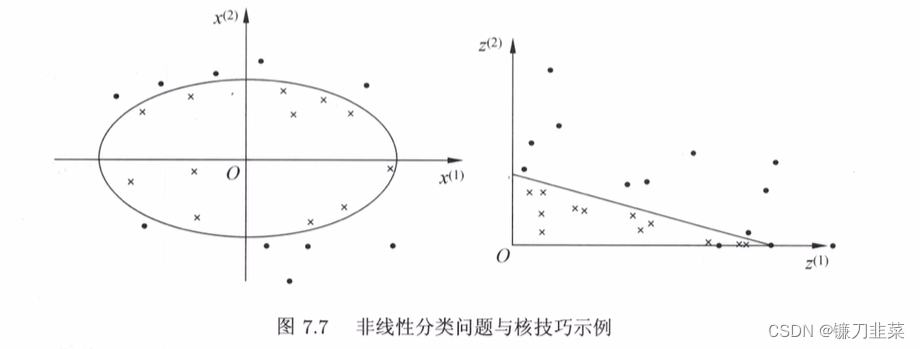
左图分类问题无法用直线(线性模型)将正负实例正确分开,但可以用一条椭圆曲线(非线性模型)将它们正确分开。
如果能用一个超曲面将正负例正确分开,则称这个问题为非线性可分问题。非线性问题往往不好求解,所以希望能用解线性分类问题的方法解决这个问题。所采取的方法是进行一个非线性变换,将非线性问题变换为线性问题。通过求解线性问题来求解原问题。
设原空间为 X ⊂ R 2 , x = ( x ( 1 ) , x ( 2 ) ) T ∈ X \mathcal{X}⊂R^2,x=(x^{(1)},x^{(2)})^T\in \mathcal{X} X⊂R2,x=(x(1),x(2))T∈X,新空间为 Z ⊂ R 2 \mathcal{Z}⊂R^2 Z⊂R2, z = ( z ( 1 ) , z ( 2 ) ) T ∈ Z z=(z^{(1)},z^{(2)})^T∈\mathcal{Z} z=(z(1),z(2))T∈Z,定义原空间到新空间的映射: z = ϕ ( x ) = ( ( x ( 1 ) ) 2 , ( x ( 2 ) ) 2 ) T z=ϕ(x)=((x^{(1)})^2,(x^{(2)})^2)^T z=ϕ(x)=((x(1))2,(x(2))2)T
则原空间的椭圆 w 1 ( x ( 1 ) ) 2 + w 2 ( x ( 2 ) ) 2 + b = 0 w_1(x^{(1)})^2+w_2(x^{(2)})^2+b=0 w1(x(1))2+w2(x(2))2+b=0
变换成新空间的直线 w 1 z ( 1 ) + w 2 z ( 2 ) + b = 0 w_1z^{(1)}+w_2z^{(2)}+b=0 w1z(1)+w2z(2)+b=0
核技巧应用到SVM,基本想法是通过一个非线性变换将输入空间(欧式空间 R n R^n Rn或者离散集合)对应于一个特征空间(希尔伯特空间 H \mathcal{H} H),使得输入空间 R n R^n Rn中的超曲面对应于特征空间 H \mathcal{H} H的超平面模型(支持向量机)。这样,分类问题的学习任务通过在特征空间中求解线性SVM就可以完成。
- 核函数的定义

核技巧的想法是,学习与预测中只定义核函数 K ( x , z ) K(x,z) K(x,z),而不是显示的定义映射函数 ϕ ϕ ϕ。通过,直接计算 K ( x , z ) K(x,z) K(x,z)比较容易,而通过 ϕ ( x ) ϕ(x) ϕ(x)和 ϕ ( z ) ϕ(z) ϕ(z)计算 K ( x , z ) K(x,z) K(x,z)并不容易。特征空间 H \mathcal{H} H一般是高维的,甚至是无穷维的。
对于给定的核 K ( x , z ) K(x,z) K(x,z),特征空间 H \mathcal{H} H和映射函数 ϕ ϕ ϕ的取法并不唯一,可以取不同的特征空间,即使在同一特征空间里也可以取不同映射。
- 核技巧在支持向量机中的应用
在线性支持向量机的对偶问题中,无论是目标函数还是决策函数(分离超平面)都只涉及输入实例与实例之间的内积。在对偶问题的目标函数中的内积 x i ⋅ x j x_i\cdot x_j xi⋅xj可以用核函数 K ( x i , x j ) = ϕ ( x i ) ⋅ ϕ ( x j ) K(x_i, x_j)=ϕ(x_i) \cdot ϕ(x_j) K(xi,xj)=ϕ(xi)⋅ϕ(xj)来代替。此时对偶问题的目标函数成为: W ( α ) = 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i W(\alpha)=\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N \alpha_i\alpha_j y_i y_j K(x_i ,x_j)-\sum_{i=1}^N\alpha_i W(α)=21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi
同样,分离决策函数中的内积也可以用核函数代替,而分类决策函数式成为 f ( x ) = s i g n ( ∑ i = 1 N s α i ∗ y i ϕ ( x i ) ⋅ ϕ ( x ) + b ∗ ) = s i g n ( ∑ i = 1 N s α i ∗ y i K ( x i , x ) + b ∗ ) f(x)=sign(\sum_{i=1}^{N_s} \alpha_i^* y_i \phi (x_i) \cdot \phi(x)+b^*)=sign(\sum_{i=1}^{N_s}\alpha_i^* y_i K(x_i, x)+b^*) f(x)=sign(i=1∑Nsαi∗yiϕ(xi)⋅ϕ(x)+b∗)=sign(i=1∑Nsαi∗yiK(xi,x)+b∗)
在新的特征空间里从训练样本中学习线性SVM。学习是隐式地在特征空间进行的,不需要显式地定义特征空间和映射函数。这样的技巧称为核技巧。当映射函数是非线性函数时,学习到的含有核函数的SVM是非线性分类模型。
在实际应用中,往往依赖领域知识直接选择核函数,核函数的有效性需要通过实验验证。
3.2 正定核
函数 K ( x , z ) K(x,z) K(x,z)满足什么条件才能称为核函数呢?通常所说的核函数就是正定核函数(positive definite kernel function)。首先介绍一些预备知识。
假设 K ( x , z ) K(x, z) K(x,z)是定义在 X × X \mathcal{X} \times \mathcal{X} X×X上的对称函数,并且对任意的 x 1 , x 2 , . . . , x m ∈ X x_1, x_2, ..., x_m\in \mathcal{X} x1,x2,...,xm∈X, K ( x , z ) K(x, z) K(x,z)关于 x 1 , x 2 , . . . , x m x_1, x_2, ..., x_m x1,x2,...,xm的Gram矩阵是半正定的。可以依据函数 K ( x , z ) K(x, z) K(x,z),构成一个希尔伯特空间,其步骤是:首先定义映射 ϕ \phi ϕ并构成向量空间 S \mathcal{S} S;然后在 S \mathcal{S} S上定义内积构成内积空间;最后将 S \mathcal{S} S完备化构成希尔伯特空间。
定义映射,构成向量空间 S \mathcal{S} S
先定义映射 ϕ : x → K ( ⋅ , x ) \phi: x \rightarrow K(\cdot , x) ϕ:x→K(⋅,x)
根据这一映射,对任意 x i ∈ X , α i ∈ R , i = 1 , 2 , . . . , m x_i \in \mathcal{X}, \alpha_i \in R, i=1,2,...,m xi∈X,αi∈R,i=1,2,...,m,定义线性组合 f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) f(\cdot) = \sum_{i=1}^m \alpha_i K(\cdot , x_i) f(⋅)=i=1∑mαiK(⋅,xi)考虑由线性组合为元素的集合 S \mathcal{S} S。由于集合 S \mathcal{S} S对加法和数乘运算是封闭的,所以 S \mathcal{S} S构成一个向量空间。在 S \mathcal{S} S上定义内积,使其成为内积空间
在 S \mathcal{S} S上定义一个运算 ∗ * ∗:对任意 f , g ∈ S f, g\in \mathcal{S} f,g∈S, f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) f(\cdot) = \sum_{i=1}^m \alpha_i K(\cdot, x_i) f(⋅)=i=1∑mαiK(⋅,xi) g ( ⋅ ) = ∑ j = 1 l β j K ( ⋅ , z j ) g(\cdot) = \sum_{j=1}^l \beta_j K(\cdot, z_j) g(⋅)=j=1∑lβjK(⋅,zj)定义运算 ∗ * ∗
f ∗ g = ∑ i = 1 m ∑ j = 1 l α i β j K ( x i , z j ) f * g=\sum_{i=1}^m \sum_{j=1}^l \alpha_i \beta_j K(x_i, z_j) f∗g=i=1∑mj=1∑lαiβjK(xi,zj)将内积空间 S \mathcal{S} S完备化为希尔伯特空间
现在将内积空间 S \mathcal{S} S完备化,由上式定义的内积可以得到范数 ∣ ∣ f ∣ ∣ = f ⋅ f ||f||=\sqrt{f\cdot f} ∣∣f∣∣=f⋅f
因此, S \mathcal{S} S是一个赋范向量空间。根据泛函分析理论,对于不完备的赋范向量空间 S \mathcal{S} S,一定可以使之完备化,得到完备的赋范向量空间 H \mathcal{H} H。一个内积空间,当作为一个赋范向量空间是完备的时候,就是希尔伯特空间。这样,就得到了希尔伯特空间 H \mathcal{H} H。
这一希尔伯特空间 H \mathcal{H} H称为再生核希尔伯特空间。这是由于核K具有再生性,即满足 K ( ⋅ , x ) ⋅ f = f ( x ) K(\cdot, x) \cdot f = f(x) K(⋅,x)⋅f=f(x)及 K ( ⋅ , x ) ⋅ K ( ⋅ , z ) = K ( x , z ) K(\cdot, x)\cdot K(\cdot, z)=K(x, z) K(⋅,x)⋅K(⋅,z)=K(x,z)
称为再生核。
- 正定核的充要条件
定理:正定核的充要条件:设 K : X × X → R K: \mathcal{X}\times \mathcal{X} \rightarrow R K:X×X→R是对称函数, 则 K ( x , z ) K(x, z) K(x,z)为正定核函数的充要条件是对任意 x i i n X , i = 1 , 2 , . . . , m , K ( x , z ) x_i\ in \mathcal{X}, i=1,2,...,m, K(x,z) xi inX,i=1,2,...,m,K(x,z)对应的Gram矩阵:
K = [ K ( x i , x j ) ] m × n K = [K(x_i, x_j)]_{m\times n} K=[K(xi,xj)]m×n
是半正定矩阵。
定义:正定核的等价定义:设 X ⊂ R 2 , K ( x , z ) \mathcal{X} ⊂R^2, K(x, z) X⊂R2,K(x,z)是定义在KaTeX parse error: Undefined control sequence: \tims at position 13: \mathcal{X} \̲t̲i̲m̲s̲ ̲\mathcal{X}上的对称函数,如果对任意 x i ∈ X , i = 1 , 2 , . . . , m , K ( x , z ) x_i \in \mathcal{X}, i=1,2,..., m, K(x,z) xi∈X,i=1,2,...,m,K(x,z)对应的Gram矩阵
K = [ K ( x i , x j ) ] m × n K = [K(x_i, x_j)]_{m\times n} K=[K(xi,xj)]m×n
是半正定矩阵,则称 K ( x , z ) K(x, z) K(x,z)是正定核。
3.3 常用核函数
(1)多项式核函数(polynomial kernel function)
K ( x , z ) = ( x ⋅ z + 1 ) p K(x,z)=(x\cdot z+1)^p K(x,z)=(x⋅z+1)p
对应的支持向量机是一个p次多项式分类器。在此情形下,分类决策函数成为
f ( x ) = s i g n ( ∑ i = 1 N s α i ∗ y i ( x i ⋅ x + 1 ) p + b ∗ ) f(x)=sign(\sum_{i=1}^{N_s}α_i^*y_i(x_i\cdot x+1)^p+b^∗) f(x)=sign(i=1∑Nsαi∗yi(xi⋅x+1)p+b∗)
(2)高斯核函数(Gaussian kernel function)
K ( x , z ) = e x p ( − ∣ ∣ x − z ∣ ∣ 2 2 σ 2 ) K(x,z)=exp(−\frac{||x−z||^2}{2σ^2}) K(x,z)=exp(−2σ2∣∣x−z∣∣2)
对应的支持向量机是高斯径向基函数分类器。在此情形下,分类决策函数成为
f ( x ) = s i g n ( ∑ i = 1 N s α i ∗ y i e x p ( − ∣ ∣ x − z ∣ ∣ 2 2 σ 2 ) + b ∗ ) f(x)=sign(\sum_{i=1}{N_s}α_i^*y_i exp(−\frac{||x−z||^2}{2σ^2})+b^∗) f(x)=sign(i=1∑Nsαi∗yiexp(−2σ2∣∣x−z∣∣2)+b∗)
(3)字符串核函数
核函数不仅可以定义在欧式空间上,还可以定义在离散数据的集合上。比如,字符串核是定义在字符串集合上的核函数。字符串核函数在文本分类,信息检索,生物信息等方面都有应用。
判断核函数
(1)给定一个核函数 K K K,对于 a > 0 a>0 a>0, a K aK aK也为核函数。
(2)给定两个核函数 K ′ K′ K′和 K ′ ′ K′′ K′′, K ′ K ′ ′ K′K′′ K′K′′也为核函数。
(3)对输入空间的任意实值函数 f ( x ) f(x) f(x), K ( x 1 , x 2 ) = f ( x 1 ) f ( x 2 ) K(x_1,x_2)=f(x_1)f(x_2) K(x1,x2)=f(x1)f(x2)为核函数。
3.4 非线性支持向量机
定义:非线性支持向量机: 从非线性分类训练集,通过核函数与软间隔最大化,或凸二次规划,学习得到的分类决策函数 f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i K ( x , x i ) + b ∗ ) f(x)=sign(\sum_{i=1}^N \alpha_i^* y_i K(x, x_i)+b^*) f(x)=sign(i=1∑Nαi∗yiK(x,xi)+b∗)称为非线性支持向量机, K ( x , z ) K(x,z) K(x,z)是正定核函数。
算法:非线性支持向量机学习算法
输入:训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\} T={ (x1,y1),(x2,y2),...,(xN,yN)},其中, x i ∈ X = R n x_i\in \mathcal{X}=R^n xi∈X=Rn, y i ∈ y = { − 1 , + 1 } , i = 1 , 2 , . . . , N y_i\in \mathcal{y}=\{-1, +1\}, i=1,2,...,N yi∈y={ −1,+1},i=1,2,...,N;
输出:分类决策函数
(1)选取适当的核函数 K ( x , z ) K(x,z) K(x,z)和适当的参数C,构造并求解最优化问题
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i \min_\alpha \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_j K(x_i, x_j) - \sum_{i=1}^N \alpha_i αmin21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi
s . t . ∑ i = 1 N α i y i = 0 , 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N s.t. \ \sum_{i=1}^N \alpha_i y_i = 0, 0\le \alpha_i \le C, i=1,2,..., N s.t. i=1∑Nαiyi=0,0≤αi≤C,i=1,2,...,N
求得最优解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^* = (\alpha_1^*, \alpha_2^*, ..., \alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T。
(2)选择 α ∗ \alpha^* α∗的一个分量 α j ∗ \alpha_j^* αj∗适合条件 0 < α j ∗ < C 0< \alpha_j^* < C 0<αj∗<C,计算 b ∗ = y j − ∑ i = 1 N y i α i ∗ y i K ( x i ⋅ x j ) b^*=y^j-\sum_{i=1}^Ny_i\alpha_i^*y_iK(x_i \cdot x_j) b∗=yj−∑i=1Nyiαi∗yiK(xi⋅xj)
(3)构造决策函数:
f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i K ( x ⋅ x i ) + b ∗ ) f(x)=sign(\sum_{i=1}^N \alpha_i^* y_i K(x\cdot x_i) + b^*) f(x)=sign(i=1∑Nαi∗yiK(x⋅xi)+b∗)
当 K ( x , z ) K(x, z) K(x,z)是正定核函数时,上述过程是求解凸二次规划问题,解是存在的。
4. 序列最小最优化算法
SMO算法:如何高效地实现支持向量机学习,是一种启发式算法,基本思路是:
如果变量的解都满足此最优化问题的KKT条件(Karush-Kuhn-Tucker conditions),那么这个最优化问题的解就得到了。因为KKT条件是该最优化问题的充分必要条件。否则,选择两个变量,固定其他变量,针对这两个变量构建一个二次规划问题。
4.1 两个变量二次规划的求解方法
为了求解两个变量的二次规划问题,首先分析约束条件,然后又在此约束条件下求极小。
4.2 变量的选择方法
SMO算法在每个子问题中选择两个变量优化,其中至少一个变量是违反KKT条件的。
(1)第一个变量的选择
SMO称选择第1个变量的过程为外循环,外层循环在训练样本中选取违反KKT条件最严重的样本点,并将其对应的变量作为第1个变量。
(2) 第2个变量的选择
SMO称选择第2个变量的过程为内层循环。假设在外层循环中已经找到第1个变量 a 1 a_1 a1,现在要在内层循环中找第2个变量 a 2 a_2 a2. 第2个变量选择标准是希望能使 a 2 a_2 a2有足够大的变化。
(3)计算阀值 b b b和差值 E i E_i Ei
在每次完成两个变量的优化后,都要重新计算阀值b。在每次完成两个变量的优化之后,还必须更新对应的 E i E_i Ei值,并将它们保存在列表中。
4.3 SMO算法

总结
- 支持向量机最简单的情况是线性可分支持向量机,或硬间隔支持向量机。构建它的条件是训练数据线性可分。其学习策略是最大间隔法。
- 现实中训练数据集时线性可分的情况较少,训练集往往是近似线性可分的,这时使用线性支持向量机,或软间隔支持向量机。线性支持向量机是最基本的支持向量机。
- 对于输入空间中的非线性分类问题,可以通过非线性变换将它转化为某个高维特征空间中的线性分类问题,在高维特征空间中学习支持向量机。由于在线性支持向量机学习的对偶问题里,目标函数和分类决策函数都只涉及实例与实例之间的内积,所以不需要显式地指定非线性变换,而是用核函数来替换当中的内积。核函数表示,通过一个非线性转换后的两个实例之间的内积。
- SMO算法是支持向量机学习的一种快速算法,其特点是不断地将原二次规划问题分解为两个变量的二次规划子问题,并对子问题进行解析求解,直到所有变量满足KKT条件为止,这样通过启发式的方法得到原二次规划问题的最优解。
内容来源
[1] 《统计学习方法》 李航
[2] https://blog.csdn.net/qq_42794545/article/details/121080091
边栏推荐
- Superscalar processor design yaoyongbin Chapter 8 instruction emission excerpt
- 源代码防泄密中的技术区别再哪里
- 112. Network security penetration test - [privilege promotion article 10] - [Windows 2003 lpk.ddl hijacking rights lifting & MSF local rights lifting]
- Fleet tutorial 15 introduction to GridView Basics (tutorial includes source code)
- Superscalar processor design yaoyongbin Chapter 10 instruction submission excerpt
- Flet tutorial 17 basic introduction to card components (tutorial includes source code)
- Learning and using vscode
- About sqli lab less-15 using or instead of and parsing
- SQL lab 11~20 summary (subsequent continuous update) contains the solution that Firefox can't catch local packages after 18 levels
- Matlab implementation of Huffman coding and decoding with GUI interface
猜你喜欢

Sign up now | oar hacker marathon phase III midsummer debut, waiting for you to challenge

powershell cs-UTF-16LE编码上线
File upload vulnerability - upload labs (1~2)
30. Few-shot Named Entity Recognition with Self-describing Networks 阅读笔记
《看完就懂系列》天哪!搞懂节流与防抖竟简单如斯~
SQL Lab (46~53) (continuous update later) order by injection

Attack and defense world - PWN learning notes
30. Feed shot named entity recognition with self describing networks reading notes
SQL Lab (36~40) includes stack injection, MySQL_ real_ escape_ The difference between string and addslashes (continuous update after)
Vxlan 静态集中网关
随机推荐
Completion report of communication software development and Application
Learning and using vscode
Improve application security through nonce field of play integrity API
110.网络安全渗透测试—[权限提升篇8]—[Windows SqlServer xp_cmdshell存储过程提权]
Flet tutorial 17 basic introduction to card components (tutorial includes source code)
2022 年第八届“认证杯”中国高校风险管理与控制能力挑战赛
SQL Lab (36~40) includes stack injection, MySQL_ real_ escape_ The difference between string and addslashes (continuous update after)
Attack and defense world - PWN learning notes
@Bean与@Component用在同一个类上,会怎么样?
SQL lab 11~20 summary (subsequent continuous update) contains the solution that Firefox can't catch local packages after 18 levels
What are the top-level domain names? How is it classified?
SQL Lab (41~45) (continuous update later)
Sign up now | oar hacker marathon phase III midsummer debut, waiting for you to challenge
跨域问题解决方案
解密GD32 MCU产品家族,开发板该怎么选?
Static comprehensive experiment
TypeScript 接口继承
Simple network configuration for equipment management
Vxlan 静态集中网关
SQL head injection -- injection principle and essence