当前位置:网站首页>Dab-detr: dynamic anchor boxes are better queries for Detr translation
Dab-detr: dynamic anchor boxes are better queries for Detr translation
2022-07-07 04:14:00 【jjw_ zyfx】
Click to download the paper
Code
Abstract
In this paper, we show a novel query formula , That is to say DETR Use dynamic anchor frame on (DEtection TRansformer) And learn more about the query in DETR The role of . This new formula directly uses box coordinates as Transformer Queries in the decoder and dynamically update them layer by layer . Using box coordinates is not only helpful to improve feature similarity query by using explicit position priors , eliminate DETR The problem of slow convergence in training , It also allows us to use the width and height information of the box to adjust the positional attention map . Such a design clearly shows ,DETR Queries in can be implemented in a cascading manner to execute soft ROI pool . therefore , Under the same settings , Based on DETR In the detection model of , It's in MS-COCO The performance on the benchmark is the best , for example , Use ResNet50-DC5 Training as a skeleton 50 The wheel AP by 45.7%. We also conducted a large number of experiments to verify our analysis , The effectiveness of our method is verified . Code is located https://github.com/SlongLiu/DAB-DETR.
1、 introduction
Object detection is a widely used basic task in computer vision . Most classical detectors are based on convolution architecture , Remarkable progress has been made in the past decade (Ren wait forsomeone ,2017;Girshick,2015;Redmon wait forsomeone ,2016;Bochkovskiy wait forsomeone ,2020;Ge wait forsomeone ,2021). lately ,Carion wait forsomeone (2020) A new method based on Transformer End to end detector , And named DETR(DEtection TRansformer), It eliminates the need to manually design components , For example, anchor frame , And modern anchor frame based detectors ( for example Faster RCNN) comparison , It shows good performance (Ren wait forsomeone ,2017).
Compared with anchor frame based detector , DETR The model regards target detection as a set of prediction problems , And use 100 A learnable query to detect and pool features in an image , Thus, prediction can be made without using non maximum inhibition , However , Because of its inefficient design and use of queries ,DETR The training convergence speed of is very slow , Usually 500 It takes three cycles to achieve good performance . To solve this problem , Many follow-up work attempts to improve DETR Design of query , To achieve faster training convergence and better performance (Zhu et al., 2021; Gao et al., 2021; Meng et al., 2021; Wang et al., 2021).
Despite these advances , But learning query is DETR The role of is still not fully understood or utilized . Although most previous attempts have made DETR Each query in is more explicitly associated with a specific spatial location , Instead of being associated with multiple locations , But technical solutions are very different . for example , Conditional DETR Learn conditional space queries by adjusting queries based on content features to better match image features .
Driven by these studies , We further studied Transformer Cross attention module in decoder , It is recommended to use anchor box , namely 4D Box coordinates (x、y、w、h) As DETR Query in , And update them layer by layer . This new query formula considers the position and size of each anchor box , It introduces a better spatial priori for the cross attention module , This has also led to simpler implementations and improvements to DETR We have a deeper understanding of the role of query in .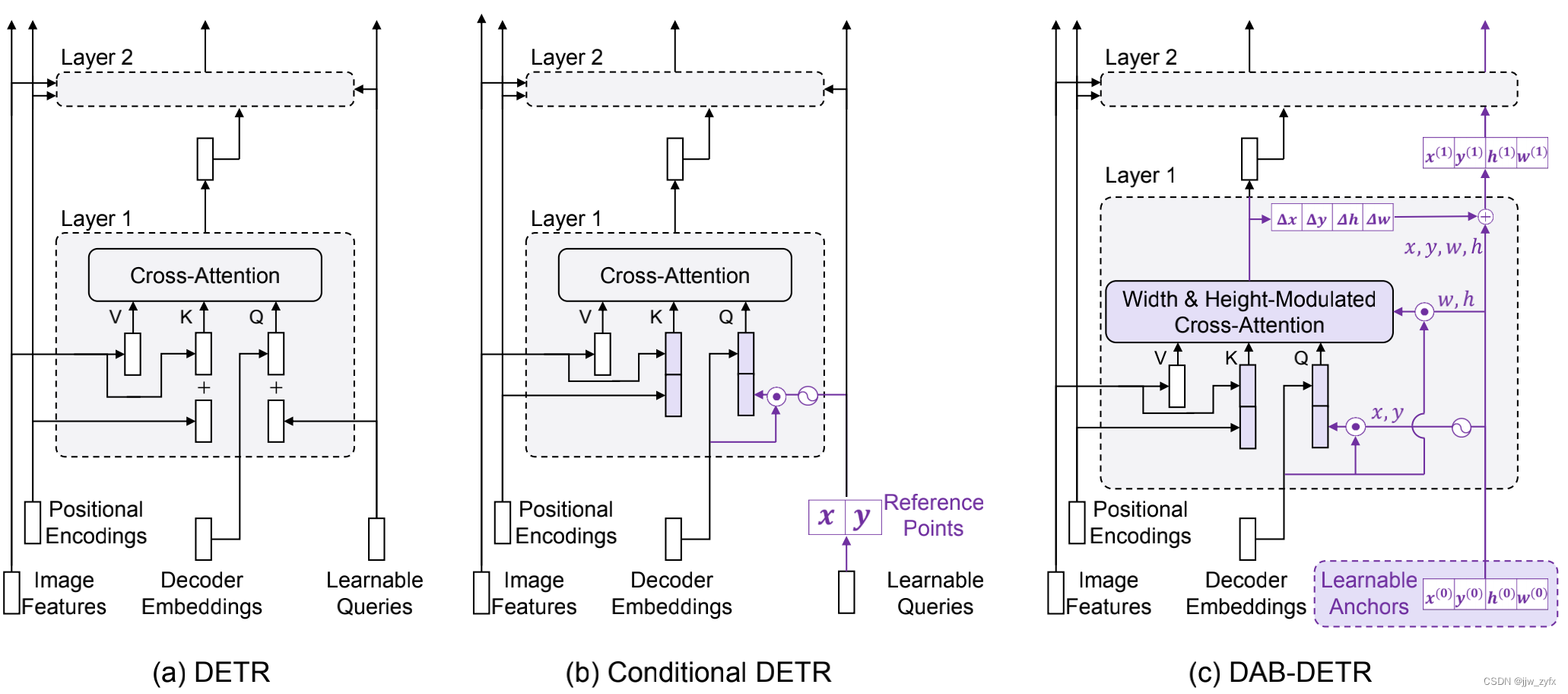
Figure 1: DETR, Conditional DETR And what we put forward DAB-DETR Comparison . For the sake of clarity , We only show Transformer The cross attention part of the decoder .(a) DETR Use learnable queries for all layers , There is no adaptation , This is the reason why the training convergence is slow .(b) Conditional DETR It mainly adjusts the learnable query of each layer , To provide better reference query points to pool the features in the image feature map . contrary ,(c)DAB-DETR Use the dynamically updated anchor box directly to provide reference query points (x,y) And reference anchor size (w,h), To improve cross attention calculation . We use purple to mark the differences between modules .
The key insight behind this formula is ,DETR Each query in consists of two parts : The content part ( Decoder self attention output ) And location section ( for example ,DETR Learnable query in ). The cross attention weight is calculated by comparing the query with a set of keys , This key consists of two parts , That is, the content part ( Encoded image features ) And location section ( Position insertion ). therefore ,Transformer The query in the decoder can be interpreted as a feature pool in the feature graph based on the feature similarity measure , The feature pool considers both content and location information . Although content similarity is used to pool semantically related features , But location similarity provides location constraints for the pooled features around the query location . This attention computing system urges us to express queries as anchor boxes , Pictured 1(c) Shown , Allow us to use the center position of the anchor box (x,y) To pool the characteristics around the center , And use the... Of the anchor box (w,h) To adjust the cross attention map , Adapt it to the size of the anchor box . Besides , Since coordinates are used as queries , The anchor box can be dynamically updated layer by layer . such ,DETR Queries in can be implemented in a cascading manner to execute soft ROI pool .
We adjust cross attention by using the size of the anchor box , It provides a better a priori location for pooling features . Because cross attention can pool the features in the whole feature map , Therefore, it is very important to provide an appropriate a priori location for each query , So that the cross attention module can focus on the local area corresponding to the target object . It can also accelerate DETR Training convergence speed . Most previous work has improved by associating each query with a specific location DETR, But they assume a fixed size isotropic Gaussian position a priori , This does not apply to objects of different scales . Use the information available in each query anchor box (w,h), We can modulate the Gaussian position a priori into an ellipse . More specifically , We will cross focus on weights ( stay softmax Before ) Of x Part and y Part divided by width and height , This helps Gauss a priori better match objects with different scales . In order to further improve the position a priori , We also introduce a temperature parameter to adjust the fluctuation of position attention , This has been ignored in all previous work .
All in all , What we proposed DAB-DETR( Dynamic anchor box DETR) By directly learning the anchor box as a query , Presents a new simulated query . This formula has a deeper understanding of the function of query , Allow us to use the anchor box to adjust Transformer Position cross attention map in decoder , And perform dynamic anchor box update layer by layer . Our results show that , In the same COCO Target detection benchmark setting ,DAB-DETR In the class DETR Get the best performance in the architecture . When using a single ResNet-50(He wait forsomeone ,2016) Model as skeleton training 50 Wheel time , The method we proposed can realize 45.7% Of AP. We also conducted a large number of experiments to verify our analysis , The effectiveness of our method is verified .
2、 Related work
Most classic detectors are based on anchor frames , Use anchor frame (Ren wait forsomeone ,2017;Girshick,2015;Sun wait forsomeone ,2021) Or anchor (Tian wait forsomeone ,2019;Zhou wait forsomeone ,2019). contrary ,DETR(Carion wait forsomeone ,2020) It is a completely anchor free detector , Use a set of learnable vectors as a query . Many follow-up works try to solve it from different angles DETR Slow convergence problem .Sun wait forsomeone (2020) Pointed out that ,DETR The reason for the slow training is due to the cross attention in the decoder , Therefore, an encoder only model is proposed .Gao wait forsomeone (2021) Gaussian prior is introduced to control cross attention . Although their performance has improved , But they are not concerned about the slow training speed and the query in DETR Give a proper explanation of the role of .
improvement DETR The other direction is more relevant to our work , That is, to deeply understand the query in DETR The role of . because DETR Learnable queries in are usually used to provide location constraints for feature pooling , Most related work attempts to make DETR Each query in is more clearly related to a specific spatial location , Not with ordinary DETR Multiple location patterns in are related . for example ,Deformable DETR(Zhu wait forsomeone ,2021) Direct will 2D Reference points are treated as queries , And predict the deformable sampling points of each reference point , To perform deformable cross attention operations .Deformable DETR(Meng wait forsomeone ,2021) Decouple the attention formula , And generate position query based on reference coordinates .Efficient DETR(Yao wait forsomeone ,2021) The dense prediction module is introduced , To choose top-K Location as target query . Although these efforts link queries to location information , But they do not give a clear formula for the use of anchor boxes .
Table 1: The representative correlation model is similar to our DAB-DETR Comparison of models . The term “ Learn to sing ?” Ask whether the model learns directly 2D Point or 4D Anchor box as a learnable parameter . The term “ Refer to anchor frame ” It refers to whether the model predicts relative to the reference point / Relative coordinates of anchor frame . The term “ Dynamic anchor frame ” Indicates whether the model updates the anchor box layer by layer . The term “ Standard attention ” It means whether the model utilizes standard intensive attention in the cross attention module . The term “ Object scale adjusts attention ” It refers to whether attention has been adjusted to better match multi-scale goals . The term “ Resize attention ” It refers to whether attention has been adjusted to better match multi-scale goals . The term “ Update the queries learned in the space ?” Indicates whether the learned query is updated layer by layer . Be careful , sparse RCNN It's not like DETR The architecture of . Here we list their anchor box formulas similar to ours . For a more detailed comparison of these models, see the appendix B.
Different from the assumption that the learnable query vector contains box coordinate information in previous work , Our approach is based on a new perspective , That is, all the information contained in the query is box coordinates . in other words , about DETR The anchor box is a better query . Work in the same period Anchor DETR(Wang wait forsomeone ,2021) It is also recommended to learn anchor points directly , And like other previous jobs , It ignores anchor width and height information . except DETR Outside ,Sun wait forsomeone (2021) A sparse detector based on direct learning box is proposed , The detector has an anchor box formula similar to ours , It's abandoned Transformer structure , And use hard ROI Align for feature extraction . surface 1 It summarizes these related works and our DAB-DETR The main difference between . We compare our model with related work in five dimensions : Whether the model directly learns the anchor box , Whether the model predicts the reference coordinates ( In its intermediate stage ), Whether the model updates the reference anchor frame layer by layer , Whether the model uses standard intensive cross attention , Whether attention is modulated to better match different proportions of objects . Whether the model will update the learned query layer by layer . similar DETR For a more detailed comparison of the models, see Appendix B. For readers who have questions about the table , We recommend this section .
3、 Why can a position a priori speed up training ?
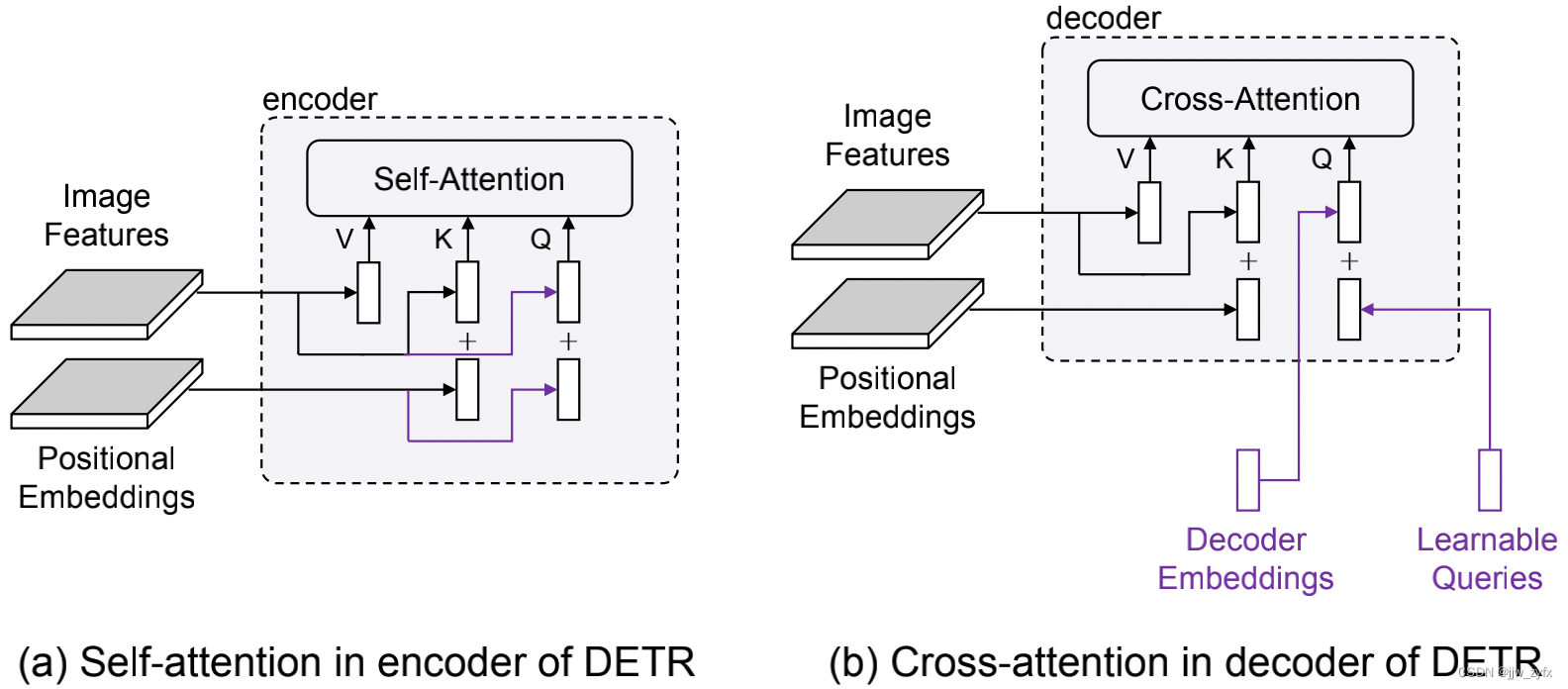
**Figure 2: **DETR Comparison between self attention in encoder and cross attention in decoder . Because they have the same key and value components , So the only difference is query . Each query in the encoder consists of image features ( Content information ) And position embedded ( Location information ) form , Each query in the decoder is embedded by the decoder ( Content information ) And learnable query ( Location information ) form . The difference between the two modules is marked in purple .
There has been a lot of work to speed up DETR Training convergence speed , However, there is a lack of unified understanding of the reasons for the effectiveness of its methods .Sun wait forsomeone (2020) indicate , Cross attention module is the main reason for slow convergence , But they simply deleted the decoder for faster training . Based on their analysis , Find out which sub module of cross attention will affect performance . Compare the self attention module in the encoder with the cross attention module in the decoder , We found that the key difference between their inputs comes from the query , Pictured 2 Shown . When the decoder embedding is initialized to 0 when , They are projected into the same space behind the first cross attention module as image features . after , They will experience a process similar to the image features in the encoder layer in the decoder layer . therefore , The root cause may be due to learnable queries .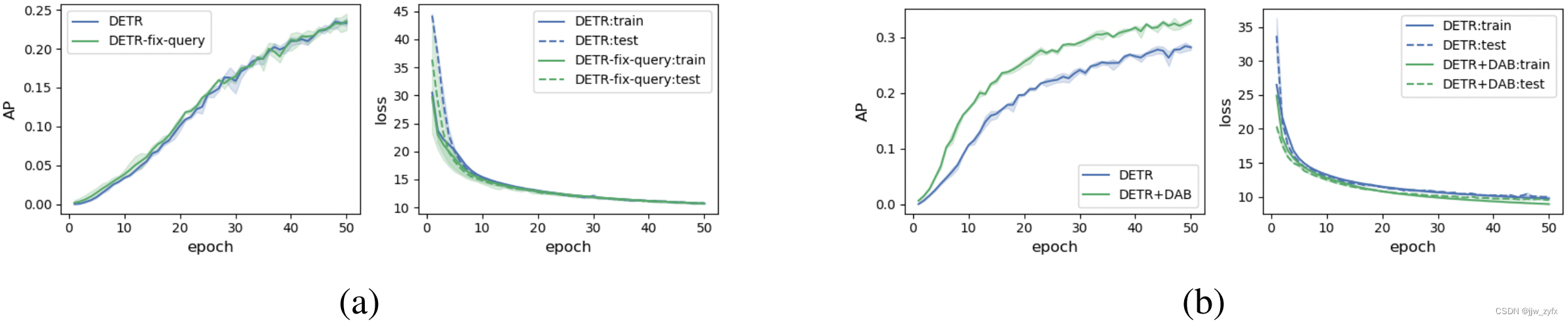
Figure 3: a): original DETR And with fixed queries DETR Training curve .b) : original DETR and DETR+DAB Training curve . We will run each experiment 3 All over , And draw the average value of each item and 95% confidence interval .
There are two reasons for the slow convergence of the model caused by cross attention :1) Due to optimization challenges , It's hard to learn to query ;2) The coding method of position information in the learned query is different from the sinusoidal position coding method used for image features . To determine whether this is the first reason , We reuse the resources from DETR Good learning query ( Keep them fixed ), Only train other modules . chart 3(a) The training curve in shows , Fixed queries are only in very early stages ( For example, before 25 round ) Slightly improved convergence . therefore , Inquiry learning ( Or optimize ) It may not be the key issue .
Figure 4: We are DETR、Conditional DETR And what we put forward DAB-DETR Visualize the location attention between location query and location key .(a) The four attention maps in are randomly sampled , We are (b) and (c) And (a) Graph of similar query location in . The deeper the color , The greater the attention weight , vice versa .(a) DETR Each attention graph in is calculated by performing dot product between learned query and location embedding from a feature graph , And can have a variety of patterns and inattention .(b) Conditional DETR Location query in is encoded in the same way as image location embedding , So as to generate a Gaussian like attention map . However , It doesn't adapt to targets of different scales .(c)DABDETR Use the width and height information of the anchor to explicitly adjust the attention map , Make it more suitable for the size and shape of the object . Adjusted attention can be seen as contributing to the implementation of soft ROI pool .
then , We turn to the second possibility , And try to find out whether the learned query has some unnecessary properties . Because the learned queries are used to filter targets in some areas , We are in the picture 4(a) Some position attention diagrams between the learned query and the embedding of image feature positions are visualized in . Each query can be regarded as a location a priori that allows the decoder to focus on the region of interest . Although they act as positional constraints , But it also has unwanted properties : Multi mode and almost uniform attention weight . for example , chart 4(a) The top two attention maps have two or more focus centers , When there are multiple targets in the image , It's hard to locate the target . chart 4(a) The base image of focuses on areas that are too large or too small , Therefore, it is impossible to inject useful location information into the feature extraction process . We speculate ,DETR The multiple models in the query may be the root cause of its slow training , We believe that it is desirable to introduce explicit location priors to constrain queries on local regions for training . To test this hypothesis , We use dynamic anchor box instead DETR Query formula in , Dynamic anchor boxes can force each query to focus on a specific area , The model is named DETR+DAB. chart 3(b) The training curve in shows , In detection AP And training / Test loss , And DETR comparison ,DETR+DAB Better performance . Be careful ,DETR and DETR+DAB The only difference between is the formulation of queries , No other technology was introduced , Such as 300 Query or focus loss . It turns out that , To solve the DETR After querying the multimodal problem , We can achieve faster training convergence speed and higher detection accuracy .
Some previous work has similar analysis , And confirmed this . for example ,SMCA(Gao wait forsomeone ,2021) The training is accelerated by applying a predefined Gaussian map around the reference point . Conditions DETR(Meng wait forsomeone ,2021) Use explicit location embedding as location query for training , Generate an attention map similar to a Gaussian kernel , Pictured 4(b) Shown . Although explicit positional priors perform well in training , But they ignore the scale information of the target . contrary , What we proposed DAB-DETR The target proportion information is explicitly considered , Adjust the attention weight adaptively , Pictured 4(c) Shown .
4、DAB-DETR
4.1、 summary
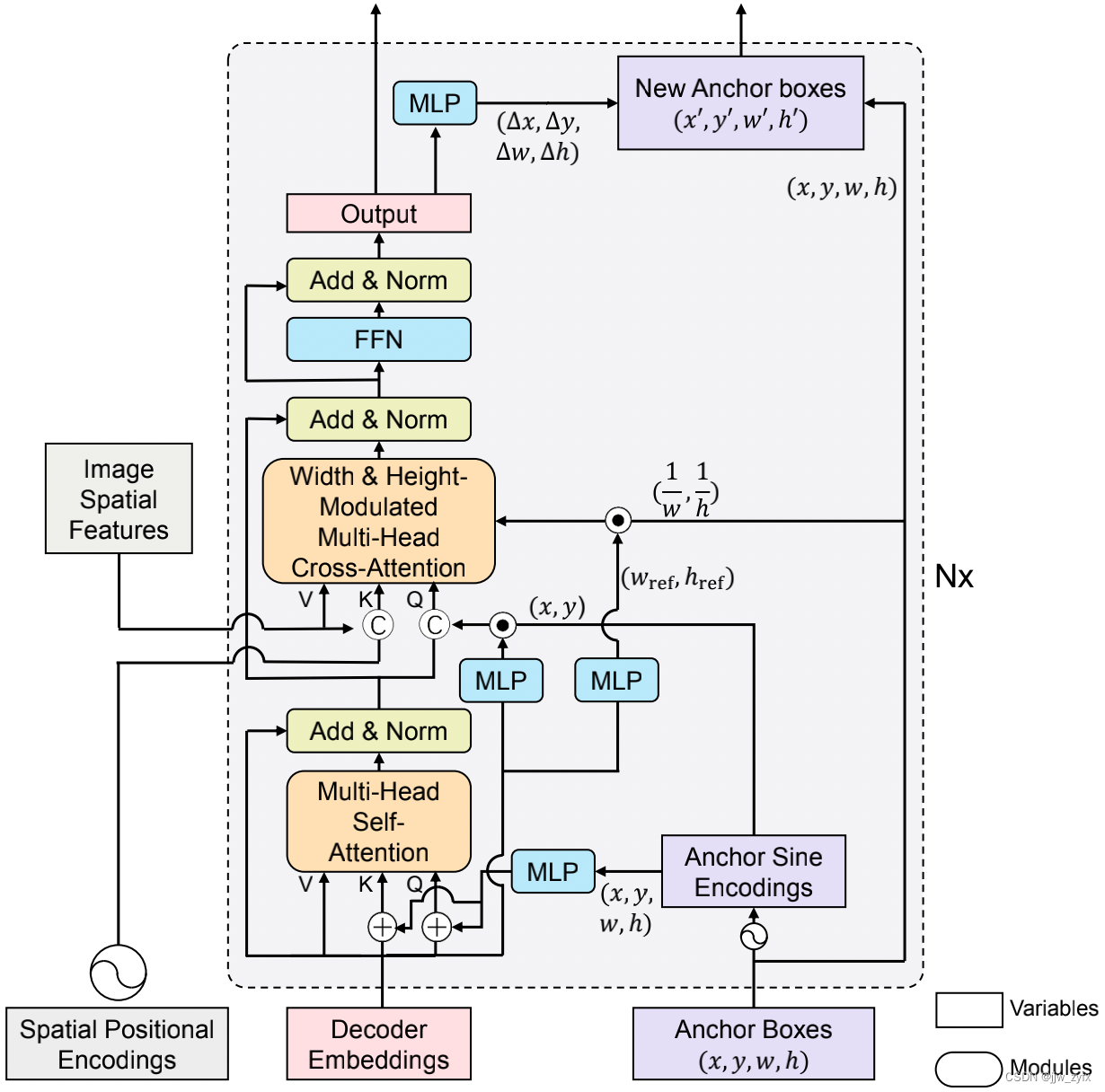
Figure 5: What we are talking about DAB-DETR Framework
Following DETR(Carion wait forsomeone ,2020 year ) after , Our model is an end-to-end target detector , It contains one CNN skeleton ,Transformer(Vaswani wait forsomeone ,2017 year ) Encoder and decoder , And the prediction head of the box and label . We mainly improved the decoder , Pictured 5 Shown .
Given a picture, we use CNN As a skeleton to extract the spatial features of the image , And then use Transformer Encoder to refine CNN Characteristics of , then , Will include location queries ( Anchor box ) And content query ( Decoder embedded ) Dual query input decoder , To detect the target corresponding to the anchor box and having a similar pattern with the content query . The double query will be updated layer by layer to gradually approach the real target object . The output of the final decoder layer usually predicts the target with label and box through the prediction header , Then the bipartite graph matching is performed to calculate DETR Loss in . To illustrate the versatility of our dynamic anchor box , We also designed a more powerful DABDeformable-DETR, See Appendix for details .
4.2、 Learn anchor box directly
As described in part I DETR The role of query in , We suggest learning query box or anchor box directly , And export location queries from these anchor boxes . Each decoder layer has two attention modules , Including self attention module and cross attention module , Used for query update and feature detection respectively . Each module needs to be queried 、 Keys and values to perform attention based value aggregation , But the input of these triples is different . We will A q = ( x q , y q , w q , h q ) A_q=(x_q,y_q,w_q,h_q) Aq=(xq,yq,wq,hq) Expressed as No q An anchor , x q , y q , w q , h q ∈ R 、 and C q ∈ R D and P q ∈ R D x_q,y_q,w_q,h_q∈ \Bbb R、 and C_q∈ \Bbb R^D and P_q∈ \Bbb R^D xq,yq,wq,hq∈R、 and Cq∈RD and Pq∈RD As its corresponding content query and location query , among D It is the dimension of decoder embedding and location query .
Given an anchor box A q A_q Aq, His location inquiry P q P_q Pq Generate : P q = M L P ( P E ( A q ) ) , ( 1 ) P_q = \mathbf{MLP(PE}(A_q)), \quad\quad\quad\quad\quad\quad\quad(1) Pq=MLP(PE(Aq)),(1) among ,PE Represents the position code that generates sine embedding from floating-point numbers ,MLP The parameters of are shared in all layers . because Aq It's a quaternion , We reload here PE Operator : P E ( A q ) = P E ( x q , y q , w q , h q ) = C a t ( P E ( x q ) , P E ( y q ) , P E ( w q ) , P E ( h q ) ) . ( 2 ) \mathbf{PE}(A_q) = \mathbf{PE}(x_q, y_q, w_q, h_q) = \mathbf{Cat(PE}(x_q), \mathbf{PE}(y_q), \mathbf{PE}(w_q), \mathbf{PE}(h_q)).\quad\quad(2) PE(Aq)=PE(xq,yq,wq,hq)=Cat(PE(xq),PE(yq),PE(wq),PE(hq)).(2) Cat Is a series function . In our implementation , Position coding function PE Map floating point numbers to D/2 Dimension vector : Such as PE: R → R D / 2 \Bbb R\rightarrow\Bbb R^{D/2} R→RD/2. therefore , function MLP take 2D The dimensional vector is projected onto D dimension :MLP: R 2 D → R D \Bbb R^{2D}\rightarrow\Bbb R^{D} R2D→RD,MLP The module has two sub modules , Each sub module consists of a linear layer and ReLU The activation function consists of , Feature compression in the first linear layer .
In the self attention module , Three queries 、 Keys and values have the same content items , Queries and keys contain additional location items : S e l f − A t t n : Q q = C q + P q , K q = C q + P q , V q = C q , ( 3 ) \mathbf{Self-Attn}: Q_q = C_q + P_q, K_q = C_q + P_q, V_q = C_q, \quad\quad\quad\quad(3) Self−Attn:Qq=Cq+Pq,Kq=Cq+Pq,Vq=Cq,(3)
suffer Conditional DETR(Meng wait forsomeone ,2021) Inspired by the , We connect location and content , As the query and key in the cross attention module , therefore , We can decouple the contribution of content and location to query feature similarity , The similarity is calculated as the dot product between the query and the key . To rescale the position embed , We also use conditional space queries (Meng wait forsomeone ,2021). More specifically , We learn M L P ( c s q ) : R D → R D \mathbf{MLP}^{(csq)}: \Bbb R^D\rightarrow\Bbb R^D MLP(csq):RD→RD Get the proportion vector based on content information , And use it to perform element multiplication with position embedding : C r o s s − A t t n : Q q = C a t ( C q , P E ( x q , y q ) ⋅ M L P ( c s q ) ( C q ) ) , \mathbf{Cross-Attn: }\quad\quad\quad\quad\quad Q_q = \mathbf{Cat}(C_q, \mathbf{PE}(x_q, y_q) · \mathbf{MLP}^{(csq)}(C_q)), Cross−Attn:Qq=Cat(Cq,PE(xq,yq)⋅MLP(csq)(Cq)), K x , y = C a t ( F x , y , P E ( x , y ) ) , V x , y = F x , y , ( 4 ) \quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad K_{x,y} = \mathbf{Cat}(F_{x,y}, \mathbf{PE}(x, y)), V_{x,y} = F_{x,y},\quad\quad\quad(4) Kx,y=Cat(Fx,y,PE(x,y)),Vx,y=Fx,y,(4) among F x , y ∈ R D F_{x,y} ∈ \Bbb R^D Fx,y∈RD Is the position (x,y) Image features at ,· It's element multiplication . Queries and position embedding in keys are generated based on two-dimensional coordinates , This makes the comparison location similarity more consistent , just as (Meng wait forsomeone ,2021;Wang wait forsomeone ,2021) Previous work .
4.3、 Anchor box update
Use coordinates as a learning query , You can update the coordinates layer by layer . contrary , For high-dimensional embedded queries , for example DETR(Carion wait forsomeone ,2020) and Conditional DETR(Meng wait forsomeone ,2021), It is difficult to perform layer by layer query refinement , Because it is not clear how to convert the updated anchor back to high-dimensional query embedding .
According to previous practice ( Zhu et al ,2021; Wang et al ,2021), We predict the relative position through the prediction head (∆x, ∆y, ∆w, ∆h) Then update the anchors in each layer . Pictured 5 Shown . Be careful , All prediction headers in different layers share the same parameters .
4.4、 Width and height modulated Gaussian kernel

Figure 6: Position attention map adjusted by width and height .
The traditional positional attention map is used as Gauss a priori , As shown on the left 6 Shown . But a priori only assumes isotropy and fixed size for all objects , Ignore its scale information ( Width and height ). In order to improve the position a priori , We suggest injecting scale information into the attention map .
The key similarity query in the original position attention map is calculated as the sum of the dot products of two coordinate codes : A t t n ( ( x , y ) , ( x r e f , y r e f ) ) = ( P E ( x ) ⋅ P E ( x r e f ) + P E ( y ) ⋅ P E ( y r e f ) ) / D , ( 5 ) \mathbf{Attn}((x, y),(x_{ref}, y_{ref})) = ( \mathbf{PE}(x) · \mathbf{PE}(x_{ref}) + \mathbf{PE}(y) · \mathbf{PE}(y_{ref}))/\sqrt D, \quad\quad(5) Attn((x,y),(xref,yref))=(PE(x)⋅PE(xref)+PE(y)⋅PE(yref))/D,(5) Among them 1 / D 1/\sqrt D 1/D Used to rescale values and Vaswani wait forsomeone (2017) The same advice as . We ( stay softmax Before ) By dividing by respectively from x Part and y Part of the relative anchor box width and height to adjust the position attention map , Smooth Gauss a priori , So as to better match objects with different scales : M o d u l a t e A t t n ( ( x , y ) , ( x r e f , y r e f ) ) = ( P E ( x ) ⋅ P E ( x r e f ) w q , r e f w q + P E ( y ) ⋅ P E ( y r e f ) h q , r e f h q ) / D , ( 6 ) \mathbf{ModulateAttn}((x, y),(x_{ref}, y_{ref})) = ( \mathbf{PE}(x) · \mathbf{PE}(x_{ref})\frac{w_{q,ref}}{w_q }+ \mathbf{PE}(y) · \mathbf{PE}(y_{ref})\frac{h_{q,ref}}{h_q})/\sqrt D, (6) ModulateAttn((x,y),(xref,yref))=(PE(x)⋅PE(xref)wqwq,ref+PE(y)⋅PE(yref)hqhq,ref)/D,(6) Among them , w q and h q yes anchor A q w_q and h_q It's an anchor A_q wq and hq yes anchor Aq Width and height , w q , r e f and h q , r e f w_{q,ref} and h_{q,ref} wq,ref and hq,ref Is the reference width and height calculated by the following formula : w q , r e f , h q , r e f = σ ( M L P ( C q ) ) . ( 7 ) w_{q,ref}, h_{q,ref} = σ(\mathbf{MLP}(C_q)).\quad\quad\quad\quad\quad\quad(7) wq,ref,hq,ref=σ(MLP(Cq)).(7) This adjusted positional attention helps us extract the features of targets with different widths and heights , The visualization of adjusted attention is shown in the figure 6 Shown .
4.5、 Temperature regulation
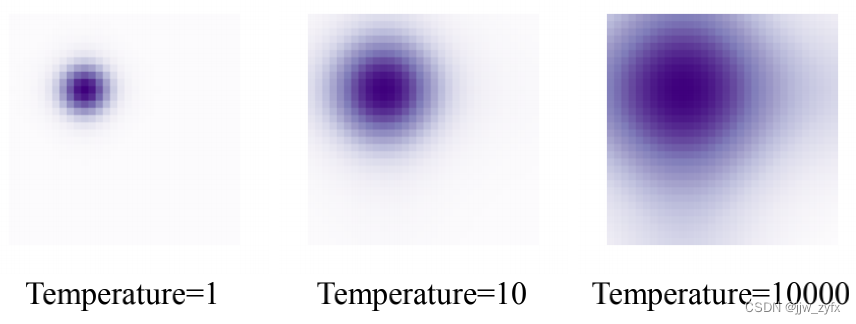
Figure 7: Location attention map at different temperatures
For location coding , We use sine functions (Vaswani wait forsomeone ,2017), The definition for : P E ( x ) 2 i = s i n ( x T 2 i / D ) , P E ( x ) 2 i + 1 = c o s ( x T 2 i / D ) , ( 8 ) \mathbf{PE}(x)_{2i} = sin(\frac{x}{T^{2i/D}}), \mathbf{PE}(x)_{2i+1} = cos(\frac{x}{T^{2i/D}}), \quad\quad\quad(8) PE(x)2i=sin(T2i/Dx),PE(x)2i+1=cos(T2i/Dx),(8) among T Is the manual design temperature , Superscript 2i and 2i+1 Represents the exponent in the coding vector . equation (8) Temperature in T Affect the size of the position a priori , Pictured 7 Shown .T The bigger it is , The flatter the attention map , vice versa . Be careful , In natural language processing , temperature T By (Vaswani wait forsomeone ,2017) Hard coded as 10000, among x The value of is an integer indicating the position of the word in the sentence . However , stay DETR in ,x The value of is between 0 and 1 Floating point value between , Represents the bounding box coordinates . therefore , The need for very high temperature values for visual tasks is similar to NLP Different . In this work , We choose from all models based on experience T=20.
5 、 experiment
We're in the appendix A Training details are shown in .
5.1、 The main result
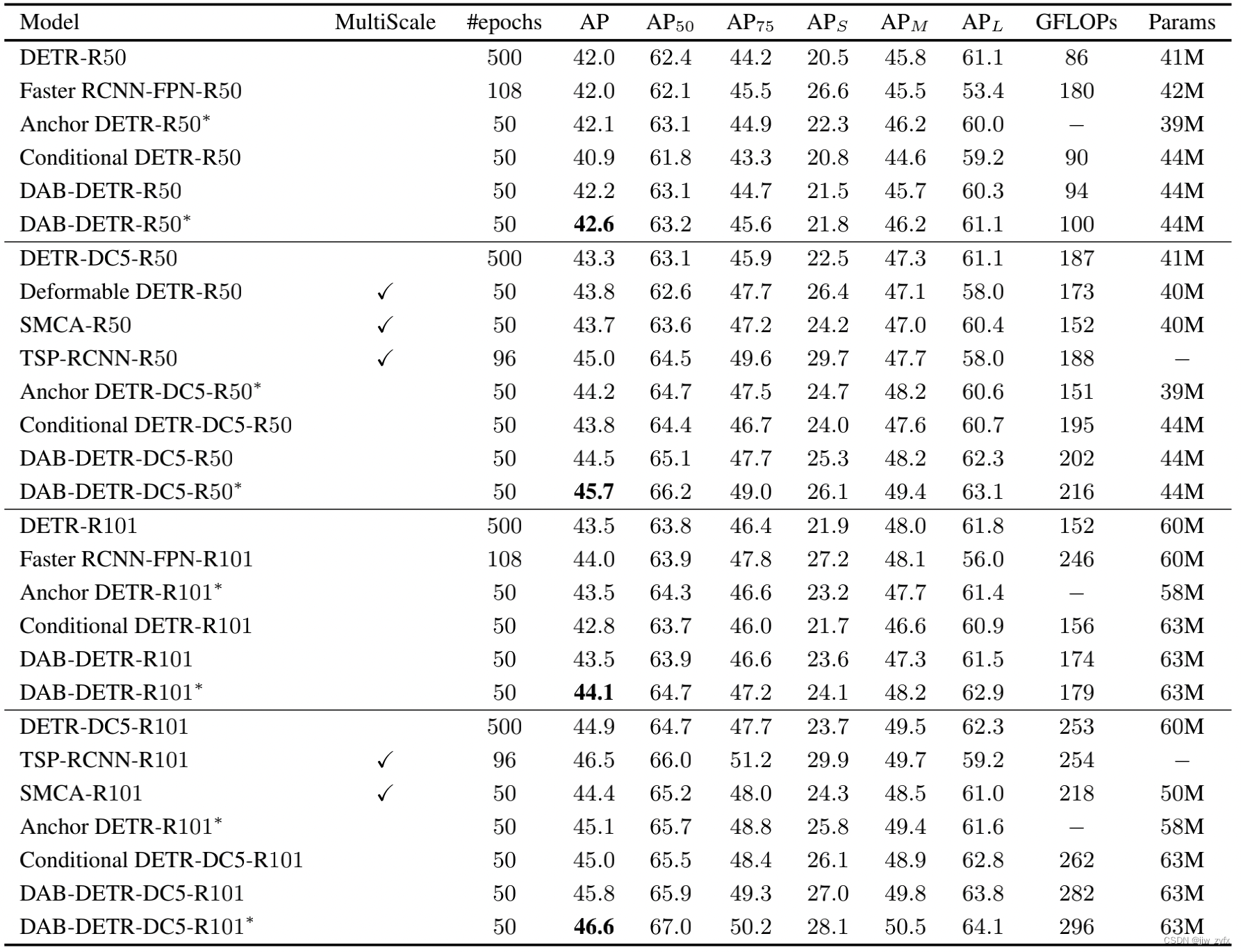
Table 2:DAB-DETR And the results of other detection models . except DETR Outside , All similar to DETR All models use 300 A query , and DETR Use 100 A query . belt ∗ Our model uses 3 Two modes are embedded , Such as Anchor DETR( Wang et al ,2021). We're still in the appendix G And appendices C Provides a more powerful DAB-DETR result .
surface 2 It shows that we are COCO 2017 The main results on the validation set . We will put forward our DAB DETR And DETR(Carion wait forsomeone ,2020)、Faster RCNN(Ren wait forsomeone ,2017)、Anchor DETR(Wang wait forsomeone ,2021)、SMCA(Gao wait forsomeone ,2021)、Deformable DETR(Zhu wait forsomeone ,2021)、TSP(Sun wait forsomeone ,2020) and Conditional DETR(Meng wait forsomeone ,2021) Made a comparison . We show two variants of the model : Standard models and belts ∗ Model with ∗ There are three patterns embedded in our model ( Wang et al ,2021). Our standard model is better than Conditional DETR There are great advantages . We noticed that , Our model introduces a slightly increased GFLOP.GFLOP It may vary depending on the calculation script , We used the author's table 2 Results reported in . actually , We found in the test , Our standard model GFLOP And based on our GFLOP Calculate the corresponding ConditionalDETR The model is almost the same , Therefore, our model still has advantages over previous work under the same setting . When using pattern embedding , Our belt ∗ Of DAB-DETR On all four backbones, it is similar to the previous DETR Our method has great advantages , Even better than multi-scale architecture . The correctness of the analysis and the effectiveness of the design are verified .
5.2、 Ablation Experiment

Table 3::DAB-DETR Ablation results . All models are in ResNet-50-DC5 Test on the backbone , Other parameters are the same as our default settings .
surface 3 It shows the effectiveness of each component in our model . We found that , All the modules we proposed have made significant contributions to our final results . And anchor formula ( Compare the first 3 Xing He 4 That's ok ) comparison , The anchor box formula changes the performance from 44.0%AP Up to 45.0%AP, The introduction of anchor box update makes there 1.7%AP promote ( Compare the first 1 Xing He 2 That's ok ), This proves the effectiveness of dynamic anchor frame design .
After removing modulation attention and temperature fine-tuning , The performance of the model is reduced to 45.0%( Compare the first 1 Xing He 3 That's ok ) and 44.4%( Compare the first 1 Xing He 5 That's ok ). therefore , Fine-grained adjustment of location attention is also very important to improve detection performance .
6、 Conclusion
This paper presents a new query formula , stay DETR Dynamic anchor box is used in , And query in DETR Have a deeper understanding of the role of . Using anchor boxes as queries has the following advantages , Including a better position a priori after temperature adjustment , Resizable attention to consider goals of different scales , And iterative anchor box update to gradually improve anchor box estimation . Such a design clearly shows ,DETR Queries in can be implemented in a cascading manner to execute soft ROI pool . A lot of experiments have been done , It effectively verifies our analysis , And verify our algorithm design .
边栏推荐
猜你喜欢
![[hcie TAC] question 3](/img/d2/38a7286be7780a60f5311b2fcfaf0b.jpg)
随机推荐
DAB-DETR: DYNAMIC ANCHOR BOXES ARE BETTER QUERIES FOR DETR翻译
The most complete security certification of mongodb in history
OSCP工具之一: dirsearch用法大全
UltraEdit-32 warm prompt: right association, cancel bak file [easy to understand]
Redis source code learning (30), dictionary learning, dict.h
Using thread class and runnable interface to realize the difference between multithreading
Leetcode: interview question 17.24 Maximum cumulative sum of submatrix (to be studied)
1.19.11.SQL客户端、启动SQL客户端、执行SQL查询、环境配置文件、重启策略、自定义函数(User-defined Functions)、构造函数参数
Kotlin Android environment construction
使用切面实现记录操作日志
Unity3D在一建筑GL材料可以改变颜色和显示样本
easyui出口excel无法下载框弹出的办法来解决
golang 压缩和解压zip文件
2022年电工杯B 题 5G 网络环境下应急物资配送问题思路分析
How to manage the expiration of enterprise distribution certificates- How to manage Enterprise Distribution certificate expiration?
接口自动化测试实践指导(中):接口测试场景有哪些
什么是 CGI,什么是 IIS,什么是VPS「建议收藏」
三重半圆环进度条,直接拿去就能用
再AD 的 界面顶部(菜单栏)创建常用的快捷图标
【OA】Excel 文档生成器: Openpyxl 模块