当前位置:网站首页>Feature of sklearn_ extraction. text. CountVectorizer / TfidVectorizer
Feature of sklearn_ extraction. text. CountVectorizer / TfidVectorizer
2022-07-06 12:00:00 【Want to be a kite】
sklearn.feature_extraction: feature extraction
The sklearn.feature_extraction Module processing extracts features from raw data . It currently includes methods of extracting features from text and images .
User guide : For more information , See the feature extraction section .
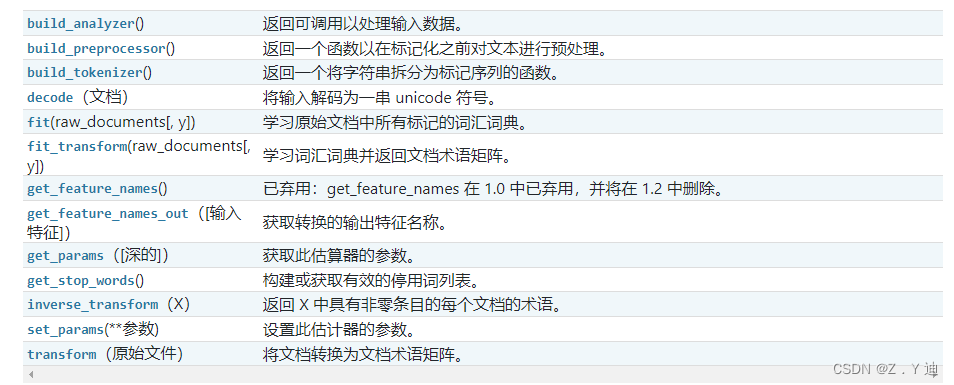
feature_extraction.DictVectorizer(*[, ...])
Convert the eigenvalue mapping list to a vector .
feature_extraction.FeatureHasher([...])
Implement feature hashing , That is, the hashing technique .
From image
The sklearn.feature_extraction.image The sub module collects utilities to extract features from images .
feature_extraction.image.extract_patches_2d(...)
take 2D The image is reshaped into a set of patches
feature_extraction.image.grid_to_graph(n_x, n_y)
Pixel to pixel connection diagram .
feature_extraction.image.img_to_graph( picture ,*)
Pixel to pixel gradient connection diagram .
feature_extraction.image.reconstruct_from_patches_2d(...)
Rebuild the image from all its patches .
feature_extraction.image.PatchExtractor(*[, ...])
Extract patches from image sets .
From text
The sklearn.feature_extraction.text The sub module collects utilities to build feature vectors from text documents .
feature_extraction.text.CountVectorizer(*[, ...])
Convert a collection of text documents into a token count matrix .
feature_extraction.text.HashingVectorizer(*)
Convert a collection of text documents into a matrix of mark occurrences .
feature_extraction.text.TfidfTransformer(*)
Convert the counting matrix into a standardized tf or tf-idf Express .
feature_extraction.text.TfidfVectorizer(*[, ...])
Convert the original document collection to TF-IDF Characteristic matrix .
sklearn.feature_selection: feature selection
The sklearn.feature_selection The module implements the feature selection algorithm . It currently includes univariate filter selection method and recursive feature elimination algorithm .
User guide : For more information , Please refer to the function selection section .
feature_selection.GenericUnivariateSelect([...])
Univariate feature selector with configurable policy .
feature_selection.SelectPercentile([...])
Select features according to the percentile of the highest score .
feature_selection.SelectKBest([score_func, k])
according to k Highest score selection feature .
feature_selection.SelectFpr([score_func, alpha])
filter : according to FPR Test selection below alpha Of pvalues.
feature_selection.SelectFdr([score_func, alpha])
filter : Choose for the estimated error detection rate p value .
feature_selection.SelectFromModel( It is estimated that ,*)
Meta converter for selecting features based on importance weight .
feature_selection.SelectFwe([score_func, alpha])
filter : Choice and Family-wise error rate Corresponding p value .
feature_selection.SequentialFeatureSelector(...)
A converter that performs sequential feature selection .
feature_selection.RFE( estimator ,*[,...])
Feature ranking with recursive feature elimination .
feature_selection.RFECV( estimator ,*[,...])
Use cross validation for recursive feature elimination to select the number of features .
feature_selection.VarianceThreshold([ critical point ])
Delete the feature selector for all low variance features .
feature_selection.chi2(X, y)
Calculate chi square statistics between each nonnegative feature and class .
feature_selection.f_classif(X, y)
Calculate ANOVA F value .
feature_selection.f_regression(X, y, *[, ...])
return F Statistics and p Univariate linear regression test of value .
feature_selection.r_regression(X, y, *[, ...])
Calculate for each feature and target Pearson Of r.
feature_selection.mutual_info_classif(X, y, *)
Estimate the mutual information of discrete target variables .
feature_selection.mutual_info_regression(X, y, *)
Estimate the mutual information of continuous target variables .
feature_extraction.text.TfidVectorizer
Example :
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> corpus = [
... 'This is the first document.',
... 'This document is the second document.',
... 'And this is the third one.',
... 'Is this the first document?',
... ]
>>> vectorizer = CountVectorizer()
>>> X = vectorizer.fit_transform(corpus)
>>> vectorizer.get_feature_names_out()
array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third',
'this'], ...)
>>> print(X.toarray())
[[0 1 1 1 0 0 1 0 1]
[0 2 0 1 0 1 1 0 1]
[1 0 0 1 1 0 1 1 1]
[0 1 1 1 0 0 1 0 1]]
>>> vectorizer2 = CountVectorizer(analyzer='word', ngram_range=(2, 2))
>>> X2 = vectorizer2.fit_transform(corpus)
>>> vectorizer2.get_feature_names_out()
array(['and this', 'document is', 'first document', 'is the', 'is this',
'second document', 'the first', 'the second', 'the third', 'third one',
'this document', 'this is', 'this the'], ...)
>>> print(X2.toarray())
[[0 0 1 1 0 0 1 0 0 0 0 1 0]
[0 1 0 1 0 1 0 1 0 0 1 0 0]
[1 0 0 1 0 0 0 0 1 1 0 1 0]
[0 0 1 0 1 0 1 0 0 0 0 0 1]]
sklearn.feature_extraction.text.TfidfVectorizer
Example :
>>> from sklearn.feature_extraction.text import TfidfVectorizer
>>> corpus = [
... 'This is the first document.',
... 'This document is the second document.',
... 'And this is the third one.',
... 'Is this the first document?',
... ]
>>> vectorizer = TfidfVectorizer()
>>> X = vectorizer.fit_transform(corpus)
>>> vectorizer.get_feature_names_out()
array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third',
'this'], ...)
>>> print(X.shape)
(4, 9)
边栏推荐
猜你喜欢

Mysql的索引实现之B树和B+树
IOT system framework learning
open-mmlab labelImg mmdetection

锂电池基础知识
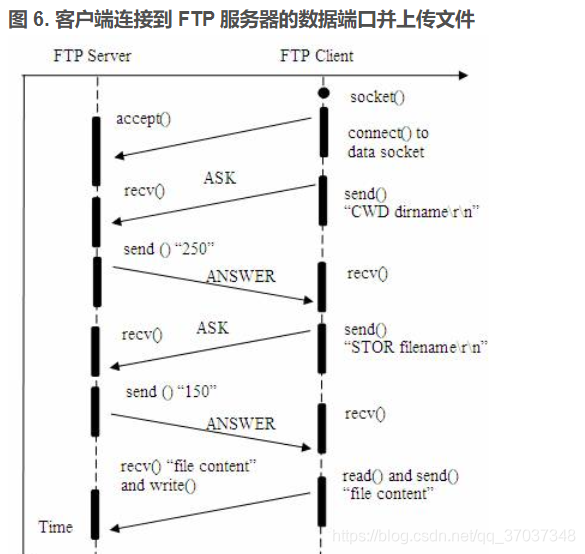
FTP file upload file implementation, regularly scan folders to upload files in the specified format to the server, C language to realize FTP file upload details and code case implementation
STM32型号与Contex m对应关系
uCOS-III 的特点、任务状态、启动

RT-Thread 线程的时间片轮询调度
![Several declarations about pointers [C language]](/img/9b/ace0abbd1956123a945a98680b1e86.png)
Several declarations about pointers [C language]
ToggleButton实现一个开关灯的效果
随机推荐
物联网系统框架学习
[CDH] modify the default port 7180 of cloudera manager in cdh/cdp environment
Vert. x: A simple TCP client and server demo
列表的使用
encoderMapReduce 随手记
RT-Thread 线程的时间片轮询调度
Togglebutton realizes the effect of switching lights
2020 WANGDING cup_ Rosefinch formation_ Web_ nmap
vim命令行笔记
数据库面试常问的一些概念
Missing value filling in data analysis (focus on multiple interpolation method, miseforest)
[mrctf2020] dolls
Pytorch实现简单线性回归Demo
Fashion-Gen: The Generative Fashion Dataset and Challenge 论文解读&数据集介绍
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
MongoDB
Pytoch Foundation
Kaggle competition two Sigma connect: rental listing inquiries
ToggleButton实现一个开关灯的效果
荣耀Magic 3Pro 充电架构分析