当前位置:网站首页>E-commerce data analysis -- User Behavior Analysis
E-commerce data analysis -- User Behavior Analysis
2022-07-06 11:53:00 【Want to be a kite】
E-commerce data analysis – User behavior analysis
Data analysis process :
- Clear purpose
- get data
- Data exploration and preprocessing
- Analyze the data
- Come to the conclusion
- Verification conclusion
- Result presentation
User behavior refers to the behavior generated by the user on the product .( land 、 Browse 、 Buy 、 Add to cart )
User behavior data statistics :
- Daily active users
- Number of successful registrations
- Number of successful account login
- Number of people entering the product details page
- Number of people added to shopping cart
- Number of successful order submission
Analysis methods
How to conduct user behavior analysis to improve sales ?
Overall analysis of user shopping behavior ( Basic data analysis , Provide data support )
- PV、UV ( Count by cycle )
- Average visits ( Count by cycle )
- Jump loss rate ( Number of click behavior users /UV)
- The date and time period when the user is most active ( Every day 、 Wait a week )
Analysis of commodity purchase ( User preference analysis )
- Number of purchases ( Count by cycle )
- Product hits ( Count by cycle )
- Total analysis of commodity purchase times and clicks ( Carry out summary statistics in the same cycle )
- Commodity conversion rate ( Purchases and hits )
User fragrance conversion funnel analysis ( User text path analysis )
- Click the conversion rate of additional purchase ( Number of buyers / Number of clicks )
- Click the collection conversion rate ( Number of collectors / Number of clicks )
- Click purchase conversion ( Number of buyers / Number of clicks )
methodology (AARR Model)
The data packet , Use Pandas Medium Groupby.(df.groupby(‘str1’,‘str2’).sum())
AARR Model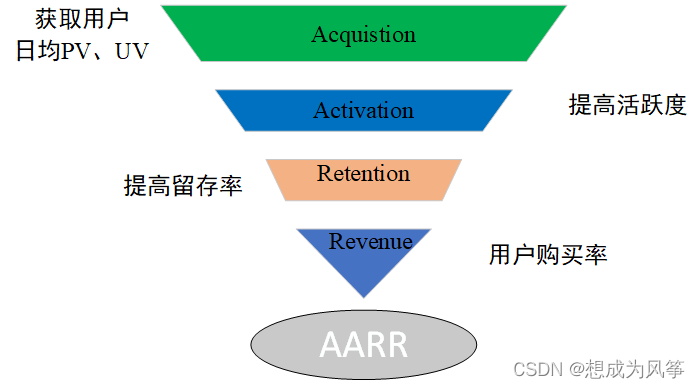
Retain users : Start using the product at a certain time , Users who continue to use the product after a period of time .
Retention : The number of users who still use the product / Initial total number of users
Repeat purchase rate : It refers to the proportion of total consumption users who consume twice or more within a certain time window
Repo rate : Users who consume in a certain time window , Proportion of consumption in the next time window .
E-commerce vulnerability analysis – node Click on 、 purchased 、 Collection 、 Buy
Project operation
Practical operation process
- Data exploration
- Data cleaning
- Data type conversion
- Build the model
- Data analysis
- Interpretation of results
Source code
import time
from datetime import datetime,timedelta,date
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Solve the problem of Chinese display
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# Import data
data = pd.read_csv(r"E:\customer_behavior.csv")
print(data.head())
del data['Unnamed: 0']
print(data.head())
# Analyze the double 11 Activities
data1 = data[(data.buy_time>='2019-11-05')&(data.buy_time<='2019-11-13')]
print(data1['be_type'].drop_duplicates())
print(data1.isnull().any())# Whether there are missing values
# Data processing
data1['day_id']=pd.to_datetime(data1['day_id'],format='%Y-%m-%d')
data1['month']=data1['day_id'].dt.month
data1['buy_time']=data1['day_id'].dt.date
data1['times']=data1['day_id'].dt.time
data1['hours']=data1['day_id'].dt.hour
data1['weekday']=data1['day_id'].dt.dayofweek+1
# View the processed data
print(data1.head())
#AARR model
# User behavior grouping statistics
behavior_count = data1.groupby('be_type')['cust_id'].count()
PV=behavior_count['pv']
print("PV=%d"%PV)
UV=len(data['cust_id'].unique())
print("UV=%d"%UV)
print(" Average visits PV/UV=%d"%(PV/UV))
data_pv=data1.loc[data1['be_type']=='pv',['cust_id']]
data_fav=data1.loc[data1['be_type']=='fav',['cust_id']]
data_cart=data1.loc[data1['be_type']=='cart',['cust_id']]
data_buy=data1.loc[data1['be_type']=='buy',['cust_id']]
# Set subtraction , Get the number of users with only click behavior
data_pv_only=set(data_pv['cust_id'])-set(data_fav['cust_id'])-set(data_cart['cust_id'])-set(data_buy['cust_id'])
pv_only=len(data_pv_only)
print(' The tripping rate is :%.2f%%'%(pv_only/UV*100))
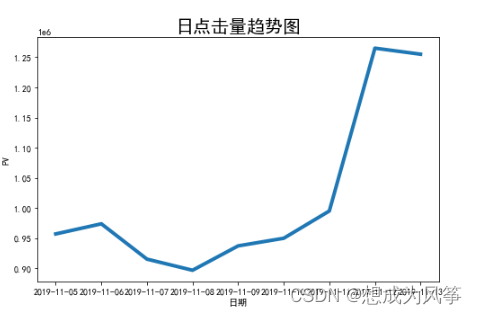
pv_day= data1[data1.be_type=='pv'].groupby('buy_time')['be_type'].count()
uv_day=data1[data1.be_type=='pv'].drop_duplicates(['cust_id','buy_time']).groupby('buy_time')['cust_id'].count()
attr = pv_day.index
v1 = pv_day.values
v2 = uv_day.values
# Set the line width
plt.figure(figsize=(8, 5))
plt.plot(attr,v1,linewidth=4)
# Set chart title , And label the axis
plt.title(" Daily hits trend chart ",fontsize=20)
plt.xlabel(' date ',fontsize=10)
plt.ylabel('PV',fontsize=10)
plt.show()
# Line drawing
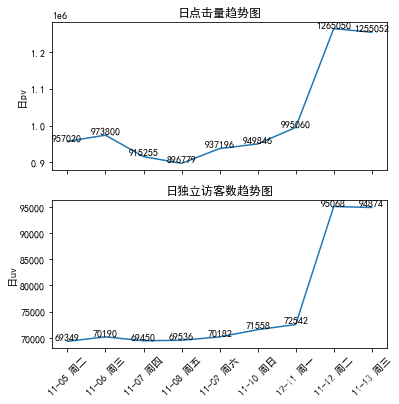
fig = plt.figure(figsize=(6,6))
plt.subplot(2,1,1)
xlabel=attr
plt.plot(range(len(xlabel)),v1)
plt.xticks(np.arange(9),'')
plt.title(' Daily hits trend chart ')
plt.ylabel(' Japan pv')
for a,b in zip(range(len(xlabel)),v1):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.subplot(2,1,2)
plt.plot(range(len(xlabel)),v2)
plt.xticks(np.arange(9),('11-05 Tuesday ','11-06 Wednesday ','11-07 Thursday ','11-08 Friday ','11-09 Saturday ','11-10 Sunday ','12-11 Monday ','11-12 Tuesday ','11-13 Wednesday '),rotation=45)
plt.title(' Trend chart of daily number of independent visitors ')
plt.ylabel(' Japan uv')
for a,b in zip(range(len(xlabel)),v2):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.show()
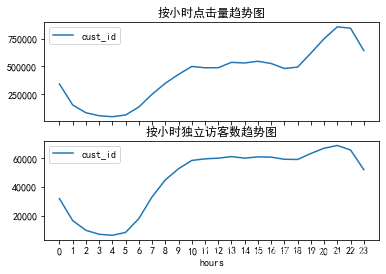
pv_hour=data1.groupby('hours')['cust_id'].count().reset_index().rename(columns={
' user ID':'pv'})
uv_hour=data1.groupby('hours')['cust_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={
' user ID':' when uv'})
fig,axes=plt.subplots(2,1,sharex=True)
pv_hour.plot(x='hours',y='cust_id',ax=axes[0])
uv_hour.plot(x='hours',y='cust_id',ax=axes[1])
plt.xticks(range(24),np.arange(24))
axes[0].set_title(' Hourly hits trend chart ')
axes[1].set_title(' Trend chart of number of independent visitors per hour ')
def cal_retention(data,n): #n by n Daily retention
user=[]
date=pd.Series(data.buy_time.unique()).sort_values()[:-n] # The time is intercepted before the last day n God
retention_rates=[]
for i in date:
new_user=set(data[data.buy_time==i].cust_id.unique())-set(user) # Identify new users , In this case, the initial number of users is set to zero
user.extend(new_user) # Add new users to the user group
# The first n Day retention
user_nday=data[data.buy_time==i+timedelta(n)].cust_id.unique() # The first n Users logged in in days
a=0
for cust_id in user_nday:
if cust_id in new_user:
a+=1
retention_rate=a/len(new_user) # Calculate the day n Daily retention rate
retention_rates.append(retention_rate) # Summary n Daily data
data_retention=pd.Series(retention_rates,index=date)
return data_retention
data_retention=cal_retention(data1,3) # Ask the user 3 Daily retention
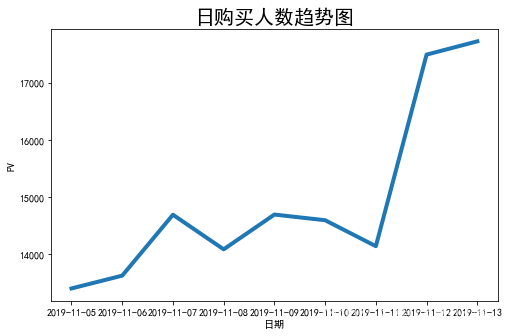
day_buy_user_num = data1[data1.be_type == 'buy'].drop_duplicates(['cust_id', 'buy_time']).groupby('buy_time')['cust_id'].count()
day_active_user_num = data1.drop_duplicates(['cust_id', 'buy_time']).groupby('buy_time')['cust_id'].count()
day_buy_rate = day_buy_user_num / day_active_user_num
attr = day_buy_user_num.index
v1 = day_buy_user_num.values
v2 = day_buy_rate.values
# Set the line width
plt.figure(figsize=(8, 5))
plt.plot(attr,v1,linewidth=4)
# Set chart title , And label the axis
plt.title(" Trend chart of daily number of buyers ",fontsize=20)
plt.xlabel(' date ',fontsize=10)
plt.ylabel('PV',fontsize=10)
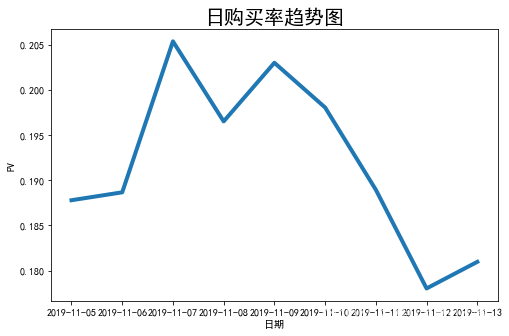
# Set the line width
plt.figure(figsize=(8, 5))
plt.plot(attr,v2,linewidth=4)
# Set chart title , And label the axis
plt.title(" Daily purchase rate trend chart ",fontsize=20)
plt.xlabel(' date ',fontsize=10)
plt.ylabel('PV',fontsize=10)
df_rebuy = data1[data1.be_type == 'buy'].drop_duplicates(['cust_id', 'day_id']).groupby('cust_id')['day_id'].count()
df_rebuy[df_rebuy >= 2].count() / df_rebuy.count()
data_AARR=data1.groupby('be_type')['cust_id'].count()
# Clicks
pv_value=data_AARR['pv']
# Collection volume
fav_value=data_AARR['fav']
# Additional purchase
cart_value=data_AARR['cart']
# Purchase volume
buy_value=data_AARR['buy']
## Calculate the conversion , There is no order between user collection and additional purchase in actual business , So calculate the conversion rate after the combination of the two
# Collection Plus purchase conversion rate
f_c_value=fav_value+cart_value
f_c_ratio=f_c_value/pv_value
print(' The conversion rate of Collection Plus purchase is :%.2f%%'%(f_c_ratio*100))
# Purchase conversion rate
buy_ratio=buy_value/pv_value
print(' The purchase conversion rate is :%.2f%%'%(buy_ratio*100))
pv_users = data1[data1.be_type == 'pv']['cust_id'].count()
fav_users = data1[data1.be_type == 'fav']['cust_id'].count()
cart_users =data1[data1.be_type == 'cart']['cust_id'].count()
buy_users = data1[data1.be_type == 'buy']['cust_id'].count()
attr = [' Click on ', ' Add to cart ', ' Collection ', ' Buy ']
values = [np.around((pv_users / pv_users * 100), 2),
np.around((cart_users / pv_users * 100), 2),
np.around((fav_users / pv_users * 100), 2),
np.around((buy_users / pv_users * 100), 2)]
from pyecharts.charts import Funnel
funnel1 = Funnel(" Overall transformation funnel ",width=800, height=400, title_pos='center')
funnel1.add(name=' link ', # Specify the legend name
attr=attr, # Specify the property name
value=values, # Specify the value corresponding to the attribute
is_label_show=True, # Confirm that the label is displayed
label_formatter='{c}'+'%', # Specify how labels are displayed
legend_top='bottom', # Specify the legend location , To avoid covering, choose the lower right display
# pyecharts The documentation of the package indicates , When label_formatter='{d}' when , Labels are displayed as a percentage .
# But when I do this , It is found that the displayed percentage does not correspond to the original data , I have to use the display form above
label_pos='outside', # Specify the location of the label ,inside,outside
legend_orient='vertical', # Specify the direction of legend display
legend_pos='right') # Specify the location of the legend
funnel1.render_notebook()
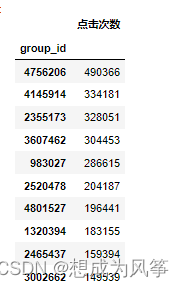
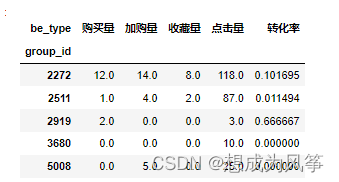
product_buy=data1.loc[data1['be_type']=='buy',['cust_id','group_id']]
product_buy_count=product_buy.groupby('group_id')['cust_id'].count().rename(' Number of sales ')
product_buy_count=pd.DataFrame(product_buy_count)
product_buy_count=product_buy_count.sort_values(by=' Number of sales ',axis=0,ascending = False)
product_buy_count=product_buy_count.iloc[:10,:]
product_buy_count

product_pv=data1.loc[data1['be_type']=='pv',['cust_id','group_id']]
product_pv_count=product_pv.groupby('group_id')['cust_id'].count().rename(' Number of hits ')
product_pv_count=pd.DataFrame(product_pv_count)
product_pv_count=product_pv_count.sort_values(by=' Number of hits ',axis=0,ascending = False)
product_pv_count=product_pv_count.iloc[:10,:]
product_pv_count
item_behavior=data.groupby(['group_id','be_type'])['cust_id'].count().unstack(1).rename(columns={
'pv':' Clicks ','fav':' Collection volume ','cart':' Additional purchase ','buy':' Purchase volume '}).fillna(0)
item_behavior.head()
item_behavior[' Conversion rate ']=item_behavior[' Purchase volume ']/item_behavior[' Clicks ']
item_behavior.head()
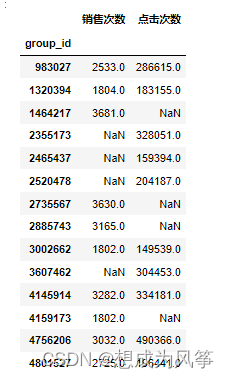
top=pd.concat([product_buy_count,product_pv_count],axis=1,sort=False)
top
Analysis report : From the analysis of the above results .
for example :
1、 The time period with the least hits every morning , The case with the least user visits . Peak user activity , What should be done for this peak period .
2、 The situation and analysis of user repurchase rate .
3、 Order analysis
4、 Funnel analysis
边栏推荐
- 分布式節點免密登錄
- Composition des mots (sous - total)
- 保姆级出题教程
- vs2019 桌面程序快速入门
- wangeditor富文本组件-复制可用
- [CDH] cdh5.16 configuring the setting of yarn task centralized allocation does not take effect
- Mtcnn face detection
- ImportError: libmysqlclient. so. 20: Cannot open shared object file: no such file or directory solution
- [蓝桥杯2020初赛] 平面切分
- 使用LinkedHashMap实现一个LRU算法的缓存
猜你喜欢




随机推荐
Contiki source code + principle + function + programming + transplantation + drive + network (turn)
Word typesetting (subtotal)
AcWing 242. A simple integer problem (tree array + difference)
[CDH] modify the default port 7180 of cloudera manager in cdh/cdp environment
物联网系统框架学习
Composition des mots (sous - total)
Come and walk into the JVM
[BSidesCF_2020]Had_a_bad_day
MATLAB学习和实战 随手记
Face recognition_ recognition
ToggleButton实现一个开关灯的效果
【CDH】CDH5.16 配置 yarn 任务集中分配设置不生效问题
MTCNN人脸检测
Encodermappreduce notes
天梯赛练习集题解LV1(all)
分布式節點免密登錄
牛客Novice月赛40
Contiki源码+原理+功能+编程+移植+驱动+网络(转)
Solution to the practice set of ladder race LV1 (all)
[Flink] Flink learning