当前位置:网站首页>电商数据分析--用户行为分析
电商数据分析--用户行为分析
2022-07-06 09:16:00 【想成为风筝】
电商数据分析–用户行为分析
数据分析流程:
- 明确目的
- 获取数据
- 数据探索和预处理
- 分析数据
- 得出结论
- 验证结论
- 结果展现
用户行为是指用户在产品上产生的行为。(登陆、浏览、购买、加入购物车)
用户行为数据统计:
- 日活跃用户数
- 注册成功人数
- 账号登陆成功人数
- 进入商品详情页人数
- 加入购物车人数
- 提交订单成功人数
分析思路
如何进行用户行为分析提高销售量销售额?
用户购物行为的整体分析(基础数据分析,提供数据支撑)
- PV、UV (按周期进行统计)
- 平均访问量 (按周期进行统计)
- 跳失率 (点击行为用户数/UV)
- 用户最活跃的日期及时间段 (每天、每周等)
商品购买情况分析 (用户偏好分析)
- 商品购买次数 (按周期进行统计)
- 商品点击次数 (按周期进行统计)
- 商品购买次数和点击次数总分析 (同一周期内进行汇总统计)
- 商品转化率 (购买量和点击量)
用户香味转化漏斗分析 (用户行文路径分析)
- 点击加购转化率 (购买人数/点击人数)
- 点击收藏转化率 (收藏人数/点击人数)
- 点击购买转化率 (购买人数/点击人数)
方法论(AARR Model)
数据分组,使用Pandas中的Groupby。(df.groupby(‘str1’,‘str2’).sum())
AARR Model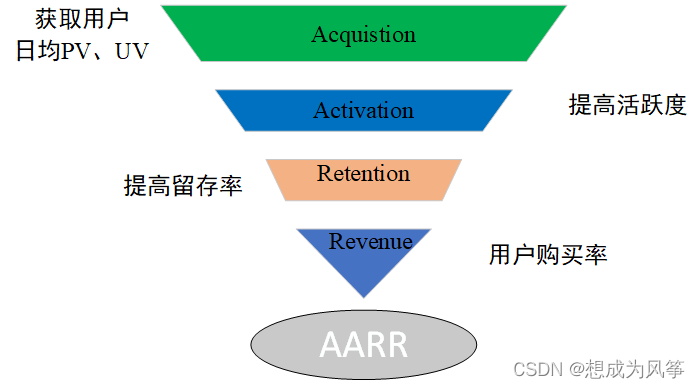
留存用户:在某段时间开始使用产品,经过一段时间后仍然继续使用产品的用户。
留存率:仍旧使用产品的用户量/最初的总用户量
复购率:是在某时间窗口内消费两次及以上在总消费用户中的占比
回购率:在某一时间窗口消费的用户,在下一个时间窗口仍旧消费的占比。
电商漏洞分析–节点 点击、加购、收藏、购买
项目实操
实操流程
- 数据探索
- 数据清洗
- 数据类型转化
- 构建模型
- 数据分析
- 结果解读
源代码
import time
from datetime import datetime,timedelta,date
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#导入数据
data = pd.read_csv(r"E:\customer_behavior.csv")
print(data.head())
del data['Unnamed: 0']
print(data.head())
#分析下双11活动
data1 = data[(data.buy_time>='2019-11-05')&(data.buy_time<='2019-11-13')]
print(data1['be_type'].drop_duplicates())
print(data1.isnull().any())#是否有缺失值
#数据处理
data1['day_id']=pd.to_datetime(data1['day_id'],format='%Y-%m-%d')
data1['month']=data1['day_id'].dt.month
data1['buy_time']=data1['day_id'].dt.date
data1['times']=data1['day_id'].dt.time
data1['hours']=data1['day_id'].dt.hour
data1['weekday']=data1['day_id'].dt.dayofweek+1
#查看处理后的数据
print(data1.head())
#AARR model
#用户行为分组统计
behavior_count = data1.groupby('be_type')['cust_id'].count()
PV=behavior_count['pv']
print("PV=%d"%PV)
UV=len(data['cust_id'].unique())
print("UV=%d"%UV)
print("平均访问量 PV/UV=%d"%(PV/UV))
data_pv=data1.loc[data1['be_type']=='pv',['cust_id']]
data_fav=data1.loc[data1['be_type']=='fav',['cust_id']]
data_cart=data1.loc[data1['be_type']=='cart',['cust_id']]
data_buy=data1.loc[data1['be_type']=='buy',['cust_id']]
#集合相减,获取只有点击行为的用户数
data_pv_only=set(data_pv['cust_id'])-set(data_fav['cust_id'])-set(data_cart['cust_id'])-set(data_buy['cust_id'])
pv_only=len(data_pv_only)
print('跳失率为:%.2f%%'%(pv_only/UV*100))
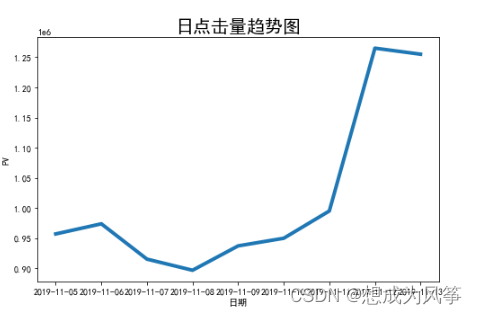
pv_day= data1[data1.be_type=='pv'].groupby('buy_time')['be_type'].count()
uv_day=data1[data1.be_type=='pv'].drop_duplicates(['cust_id','buy_time']).groupby('buy_time')['cust_id'].count()
attr = pv_day.index
v1 = pv_day.values
v2 = uv_day.values
#设置线宽
plt.figure(figsize=(8, 5))
plt.plot(attr,v1,linewidth=4)
#设置图表标题,并给坐标轴添加标签
plt.title("日点击量趋势图",fontsize=20)
plt.xlabel('日期',fontsize=10)
plt.ylabel('PV',fontsize=10)
plt.show()
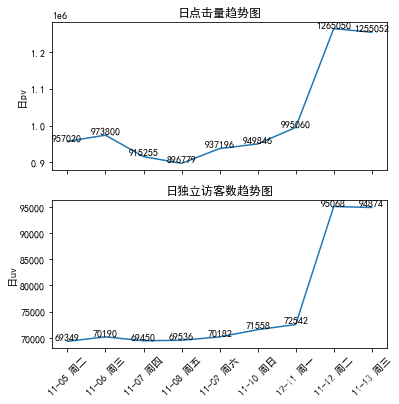
#折线图绘制
fig = plt.figure(figsize=(6,6))
plt.subplot(2,1,1)
xlabel=attr
plt.plot(range(len(xlabel)),v1)
plt.xticks(np.arange(9),'')
plt.title('日点击量趋势图')
plt.ylabel('日pv')
for a,b in zip(range(len(xlabel)),v1):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.subplot(2,1,2)
plt.plot(range(len(xlabel)),v2)
plt.xticks(np.arange(9),('11-05 周二','11-06 周三','11-07 周四','11-08 周五','11-09 周六','11-10 周日','12-11 周一','11-12 周二','11-13 周三'),rotation=45)
plt.title('日独立访客数趋势图')
plt.ylabel('日uv')
for a,b in zip(range(len(xlabel)),v2):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.show()
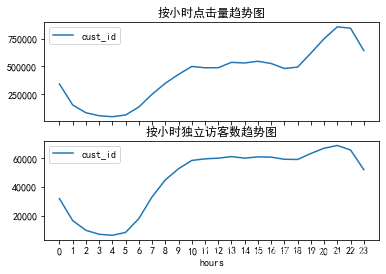
pv_hour=data1.groupby('hours')['cust_id'].count().reset_index().rename(columns={
'用户ID':'pv'})
uv_hour=data1.groupby('hours')['cust_id'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={
'用户ID':'时uv'})
fig,axes=plt.subplots(2,1,sharex=True)
pv_hour.plot(x='hours',y='cust_id',ax=axes[0])
uv_hour.plot(x='hours',y='cust_id',ax=axes[1])
plt.xticks(range(24),np.arange(24))
axes[0].set_title('按小时点击量趋势图')
axes[1].set_title('按小时独立访客数趋势图')
def cal_retention(data,n): #n为n日留存
user=[]
date=pd.Series(data.buy_time.unique()).sort_values()[:-n] #时间截取至最后一天的前n天
retention_rates=[]
for i in date:
new_user=set(data[data.buy_time==i].cust_id.unique())-set(user) #识别新用户,本案例中设初始用户量为零
user.extend(new_user) #将新用户加入用户群中
#第n天留存情况
user_nday=data[data.buy_time==i+timedelta(n)].cust_id.unique() #第n天登录的用户情况
a=0
for cust_id in user_nday:
if cust_id in new_user:
a+=1
retention_rate=a/len(new_user) #计算该天第n日留存率
retention_rates.append(retention_rate) #汇总n日留存数据
data_retention=pd.Series(retention_rates,index=date)
return data_retention
data_retention=cal_retention(data1,3) #求用户的3日留存情况
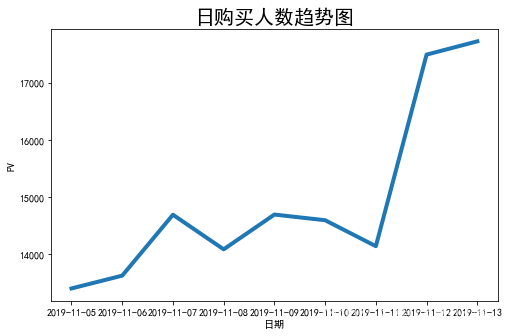
day_buy_user_num = data1[data1.be_type == 'buy'].drop_duplicates(['cust_id', 'buy_time']).groupby('buy_time')['cust_id'].count()
day_active_user_num = data1.drop_duplicates(['cust_id', 'buy_time']).groupby('buy_time')['cust_id'].count()
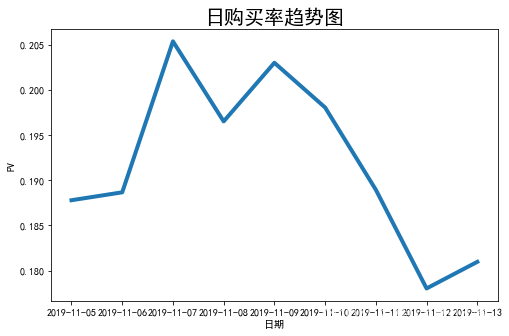
day_buy_rate = day_buy_user_num / day_active_user_num
attr = day_buy_user_num.index
v1 = day_buy_user_num.values
v2 = day_buy_rate.values
#设置线宽
plt.figure(figsize=(8, 5))
plt.plot(attr,v1,linewidth=4)
#设置图表标题,并给坐标轴添加标签
plt.title("日购买人数趋势图",fontsize=20)
plt.xlabel('日期',fontsize=10)
plt.ylabel('PV',fontsize=10)
#设置线宽
plt.figure(figsize=(8, 5))
plt.plot(attr,v2,linewidth=4)
#设置图表标题,并给坐标轴添加标签
plt.title("日购买率趋势图",fontsize=20)
plt.xlabel('日期',fontsize=10)
plt.ylabel('PV',fontsize=10)
df_rebuy = data1[data1.be_type == 'buy'].drop_duplicates(['cust_id', 'day_id']).groupby('cust_id')['day_id'].count()
df_rebuy[df_rebuy >= 2].count() / df_rebuy.count()
data_AARR=data1.groupby('be_type')['cust_id'].count()
#点击量
pv_value=data_AARR['pv']
#收藏量
fav_value=data_AARR['fav']
#加购量
cart_value=data_AARR['cart']
#购买量
buy_value=data_AARR['buy']
##计算转化率,此处由于实际业务中用户收藏和加购没有先后顺序,所以二者合并后计算转化率
#收藏加购转化率
f_c_value=fav_value+cart_value
f_c_ratio=f_c_value/pv_value
print('收藏加购转化率为:%.2f%%'%(f_c_ratio*100))
#购买转化率
buy_ratio=buy_value/pv_value
print('购买转化率为:%.2f%%'%(buy_ratio*100))
pv_users = data1[data1.be_type == 'pv']['cust_id'].count()
fav_users = data1[data1.be_type == 'fav']['cust_id'].count()
cart_users =data1[data1.be_type == 'cart']['cust_id'].count()
buy_users = data1[data1.be_type == 'buy']['cust_id'].count()
attr = ['点击', '加入购物车', '收藏', '购买']
values = [np.around((pv_users / pv_users * 100), 2),
np.around((cart_users / pv_users * 100), 2),
np.around((fav_users / pv_users * 100), 2),
np.around((buy_users / pv_users * 100), 2)]
from pyecharts.charts import Funnel
funnel1 = Funnel("总体转化漏斗图",width=800, height=400, title_pos='center')
funnel1.add(name='环节', # 指定图例名称
attr=attr, # 指定属性名称
value=values, # 指定属性所对应的值
is_label_show=True, # 确认显示标签
label_formatter='{c}'+'%', # 指定标签显示的方式
legend_top='bottom', # 指定图例位置,为避免遮盖选择右下展示
# pyecharts包的文档中指出,当label_formatter='{d}'时,标签以百分比的形式显示.
# 但我这样做的时候,发现显示的百分比与原始数据对应不上,只好用上面那种显示形式
label_pos='outside', # 指定标签的位置,inside,outside
legend_orient='vertical', # 指定图例显示的方向
legend_pos='right') # 指定图例的位置
funnel1.render_notebook()
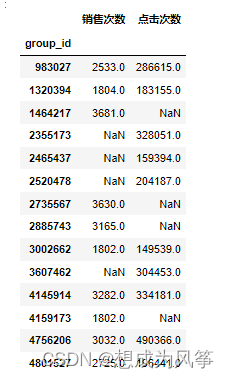
product_buy=data1.loc[data1['be_type']=='buy',['cust_id','group_id']]
product_buy_count=product_buy.groupby('group_id')['cust_id'].count().rename('销售次数')
product_buy_count=pd.DataFrame(product_buy_count)
product_buy_count=product_buy_count.sort_values(by='销售次数',axis=0,ascending = False)
product_buy_count=product_buy_count.iloc[:10,:]
product_buy_count

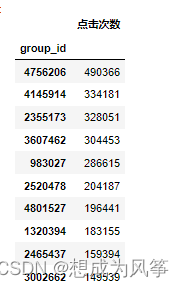
product_pv=data1.loc[data1['be_type']=='pv',['cust_id','group_id']]
product_pv_count=product_pv.groupby('group_id')['cust_id'].count().rename('点击次数')
product_pv_count=pd.DataFrame(product_pv_count)
product_pv_count=product_pv_count.sort_values(by='点击次数',axis=0,ascending = False)
product_pv_count=product_pv_count.iloc[:10,:]
product_pv_count
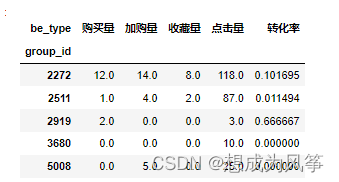
item_behavior=data.groupby(['group_id','be_type'])['cust_id'].count().unstack(1).rename(columns={
'pv':'点击量','fav':'收藏量','cart':'加购量','buy':'购买量'}).fillna(0)
item_behavior.head()
item_behavior['转化率']=item_behavior['购买量']/item_behavior['点击量']
item_behavior.head()
top=pd.concat([product_buy_count,product_pv_count],axis=1,sort=False)
top
分析报告:从以上结果中分析即可。
例如:
1、每天凌晨点击量最少的时间段,用户访问量最少的情况。用户活跃高峰期,针对这个高峰期应该做些什么。
2、用户回购率的情况及分析。
3、订单分析
4、漏斗分析
边栏推荐
- 2020 WANGDING cup_ Rosefinch formation_ Web_ nmap
- L2-001 紧急救援 (25 分)
- Word排版(小計)
- 2019 Tencent summer intern formal written examination
- Matlab learning and actual combat notes
- MTCNN人脸检测
- XML文件详解:XML是什么、XML配置文件、XML数据文件、XML文件解析教程
- Vs2019 desktop app quick start
- [NPUCTF2020]ReadlezPHP
- Antlr4 uses keywords as identifiers
猜你喜欢

分布式节点免密登录
FTP file upload file implementation, regularly scan folders to upload files in the specified format to the server, C language to realize FTP file upload details and code case implementation
Password free login of distributed nodes
Word typesetting (subtotal)

快来走进JVM吧
Vs2019 use wizard to generate an MFC Application
STM32型号与Contex m对应关系
error C4996: ‘strcpy‘: This function or variable may be unsafe. Consider using strcpy_ s instead
double转int精度丢失问题
Word排版(小計)
随机推荐
天梯赛练习集题解LV1(all)
B tree and b+ tree of MySQL index implementation
5G工作原理详解(解释&图解)
Valentine's Day flirting with girls to force a small way, one can learn
分布式事务的实现方案
{一周总结}带你走进js知识的海洋
Mtcnn face detection
Case analysis of data inconsistency caused by Pt OSC table change
【presto】presto 参数配置优化
vs2019 第一个MFC应用程序
Internet protocol details
Encodermappreduce notes
Composition des mots (sous - total)
快来走进JVM吧
Codeforces Round #753 (Div. 3)
AcWing 1298. Solution to Cao Chong's pig raising problem
encoderMapReduce 随手记
MySQL and C language connection (vs2019 version)
L2-001 emergency rescue (25 points)
MongoDB