当前位置:网站首页>Using super ball embedding to enhance confrontation training
Using super ball embedding to enhance confrontation training
2022-07-02 07:58:00 【MezereonXP】
Use super ball embedding to enhance confrontation training
This is an introduction NeurIPS2020 The job of ,“Boosting Adversarial Training with Hypersphere Embedding”, The first work is from Tsinghua University Tianyu Pang.
This work mainly introduces a technology , be called Hypersphere Embedding, In this paper, it is called hypersphere embedding .
This method is orthogonal to some existing variants of confrontation training , That is, they can integrate with each other to improve the effect .
The variants of confrontation training here are ALP, TRADE etc.
Confrontation training framework
First , As shown in the figure below , Let's list AT And its variants , Mark the differences of their training goals with pink
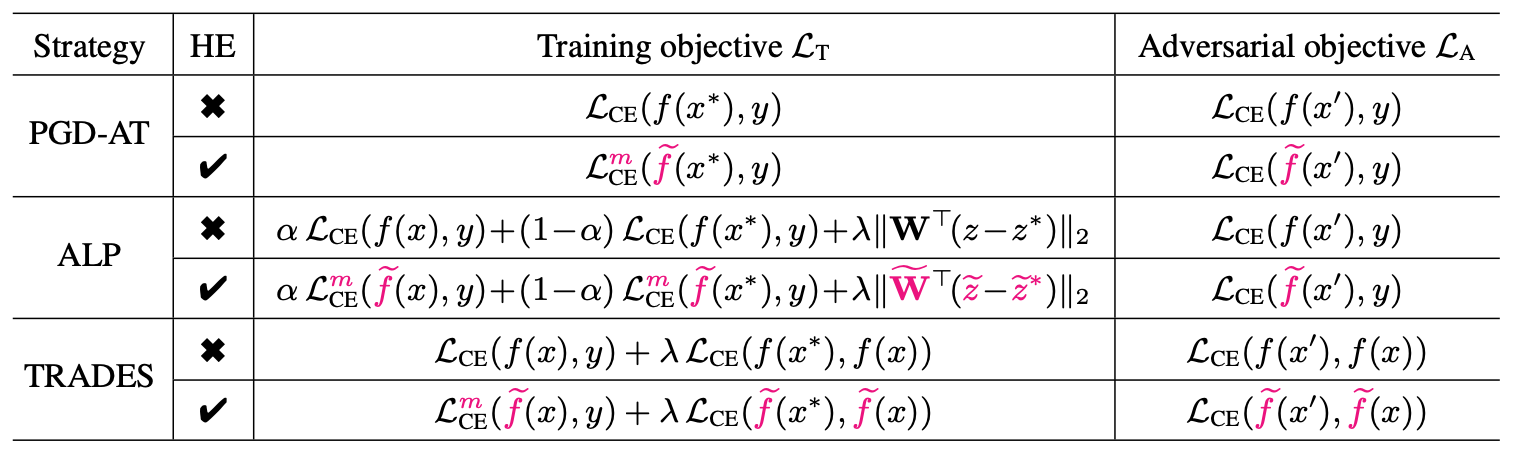
among , x ∗ x^* x∗ It's a countermeasure sample , The countermeasure target on the right can be understood as the error function used to generate countermeasure samples .
We can simply see the design of these variants :
- ALP Is the cross entropy error of normal samples , A regularization term is introduced , z z z In fact, that is f ( x ) f(x) f(x)
- TRADES After introducing the cross entropy error of normal samples , The error of the original countermeasure sample is modified , namely , From the original label y y y Change to the output of normal samples f ( x ) f(x) f(x)
HE There are two main parts to modify :
- In the model f f f above
- In the cross entropy error L C E \mathcal{L}_{CE} LCE above
Methods to introduce
Mark description
Here are some basic marks first , Convenient for later description
We consider classification tasks , Note that the number of labels is L L L, Record the model as :
f ( x ) = S ( W ⊤ z + b ) f(x) = \mathbb{S}(\mathbf{W}^\top z+b) f(x)=S(W⊤z+b)
among , z = z ( x ; ω ) z = z(x;\omega) z=z(x;ω) Represents based on model parameters ω \omega ω Extracted features , matrix W = ( W 1 , . . . , W L ) \mathbf{W} = (W_1,...,W_L) W=(W1,...,WL) And bias b b b It can be understood as the last linear layer , function S ( ⋅ ) \mathbb{S}(\cdot) S(⋅) yes softmax function .
We remember that the cross entropy error is :
L C E ( f ( x ) , y ) = − 1 y ⊤ log f ( x ) \mathcal{L}_{CE}(f(x),y)=-1^\top_y \log f(x) LCE(f(x),y)=−1y⊤logf(x)
among , 1 y 1_y 1y It's the label y y y Of one-hot code , That is to say y y y The position is 1, The rest are 0.
We use ∠ ( u , v ) \angle(u,v) ∠(u,v) It's a vector u u u and v v v The Angle between
The fusion HE Confrontation training framework
First , Most of the confrontation training can be written in the following two-stage framework :
min ω , W E [ L T ( ω , W ∣ x , x ∗ , y ) ] , where x ∗ = arg max x ′ ∈ B ( x ) L A ( x ′ ∣ x , y , ω , W ) \min_{\omega,\mathbf{W}}\mathbb{E}[\mathcal{L}_T(\omega,\mathbf{W}|x,x^*,y)], \text{where } x^*=\arg\max_{x'\in\mathbf{B}(x)} \mathcal{L}_A(x'|x,y,\omega,\mathbf{W}) ω,WminE[LT(ω,W∣x,x∗,y)],where x∗=argx′∈B(x)maxLA(x′∣x,y,ω,W)
In fact, that is , Sir, become a confrontation sample , Then optimize the training objectives .
After many iterations , W \mathbf{W} W as well as ω \omega ω Will gradually converge , In order to improve the performance of this confrontation training , Some work will metric learning Introduce into confrontation learning , However, the calculation cost of these works is relatively high , It will lead to some category bias , It is still fragile under the stronger counter attack .
Related materials :
- NeurIPS 2019: Metric learning for adversarial robustness.
- IWSBPR 2015: Deep metric learning using triplet network.
- Stronger resistance to attack :https://github.com/Line290/FeatureAttack
In fact, the motivation Not enough , The reason given is still not strong enough
Next , Give directly HE In the form of , In fact, it's about characteristics z z z And weight W \mathbf{W} W Standardize
W ⊤ z = ( W 1 ⊤ z , W 2 ⊤ z , . . . , W L ⊤ z ) \mathbf{W}^\top z=(W_1^\top z, W_2^\top z,...,W_L^\top z) W⊤z=(W1⊤z,W2⊤z,...,WL⊤z)
among W i ⊤ z = ∥ W i ∥ ∥ z ∥ cos θ i W_i^\top z=\Vert W_i\Vert\Vert z\Vert \cos\theta_i Wi⊤z=∥Wi∥∥z∥cosθi, θ i = ∠ ( W i , z ) \theta_i = \angle(W_i,z) θi=∠(Wi,z)
We make
W i ~ = W i ∥ W i ∥ , z ~ = z ∥ z ∥ \widetilde{W_i}=\frac{W_i}{\Vert W_i\Vert}, \widetilde{z}=\frac{z}{\Vert z\Vert} Wi=∥Wi∥Wi,z=∥z∥z
Thus there are
f ~ ( x ) = S ( W ~ ⊤ z ~ ) = cos θ θ = ( cos θ 1 , cos θ 2 , . . . , cos θ L ) \widetilde{f}(x) = \mathbb{S}(\widetilde{\mathbf{W}}^\top \widetilde{z}) = \cos\theta\\ \theta = (\cos\theta_1,\cos\theta_2,...,\cos\theta_L) f(x)=S(W⊤z)=cosθθ=(cosθ1,cosθ2,...,cosθL)
When calculating the cross entropy function , Introduce a variable m m m, remember :
L C E m ( f ~ ( x ) , y ) = − 1 y ⊤ log ( S ( s ⋅ ( cos θ − m ⋅ 1 y ) ) ) \mathcal{L}_{CE}^{m}(\widetilde{f}(x),y)=-1^\top_y\log(\mathbb{S}(s\cdot(\cos\theta-m\cdot 1_y))) LCEm(f(x),y)=−1y⊤log(S(s⋅(cosθ−m⋅1y)))
among s > 0 s > 0 s>0 It's a coefficient , Used to improve the stability of values during training
This m m m The introduction of is a reference CVPR2018 An article from ,Cosface: Large margin cosine loss for deep face recognition
The theoretical analysis
First, we define a vector function U p \mathbb{U}_p Up
U p ( u ) = arg max ∥ v ∥ p ≤ 1 u ⊤ v , where u ⊤ U p ( u ) = ∥ u ∥ q \mathbb{U}_p(u)=\arg\max_{\Vert v\Vert_p\leq 1}u^\top v,\text{where } u^\top\mathbb{U}_p(u)=\Vert u\Vert_q Up(u)=arg∥v∥p≤1maxu⊤v,where u⊤Up(u)=∥u∥q
among 1 p + 1 q = 1 \frac{1}{p}+\frac{1}{q}=1 p1+q1=1
lemma 1: Given a counter target error function L A \mathcal{L}_A LA, Make B ( x ) = { x ′ ∣ ∥ x − x ′ ∥ p ≤ ε } \mathbf{B}(x)=\{x'|\Vert x-x'\Vert_p\leq\varepsilon\} B(x)={ x′∣∥x−x′∥p≤ε}, Using the first-order Taylor expansion , Available max x ′ ∈ B ( x ) L A ( x ′ ) \max_{x'\in \mathbf{B}(x)}\mathcal{L}_A(x') maxx′∈B(x)LA(x′) The solution of is x ∗ = x + ε U p ( ∇ x L A ) x^*=x+\varepsilon \mathbb{U}_p(\nabla_x\mathcal{L}_A) x∗=x+εUp(∇xLA). further , L A ( x ∗ ) = L A ( x ) + ε ∥ ∇ x L A ( x ) ∥ q \mathcal{L}_A(x^*) = \mathcal{L}_A(x) + \varepsilon \Vert \nabla_x\mathcal{L}_A(x) \Vert_q LA(x∗)=LA(x)+ε∥∇xLA(x)∥q
prove :
You may as well make x ′ = x + ε v x'=x+\varepsilon v x′=x+εv, among ∥ v ∥ p ≤ 1 \Vert v\Vert_p\leq1 ∥v∥p≤1
thus , L A ( x ′ ) = L A ( x + ε v ) \mathcal{L}_A(x')=\mathcal{L}_A(x + \varepsilon v) LA(x′)=LA(x+εv)
stay x = x − ε v x = x - \varepsilon v x=x−εv We're going to do a Taylor expansion at , obtain L A ( x + ε v ) ≈ L A ( x ) + ε v ⊤ ( ∇ x L A ) \mathcal{L}_A(x+\varepsilon v) \approx \mathcal{L}_A(x) + \varepsilon v^\top (\nabla_x\mathcal{L}_A) LA(x+εv)≈LA(x)+εv⊤(∇xLA)
so max x ′ ∈ B ( x ) L A ( x ′ ) = L A ( x ) + ε max ∥ v ∥ p ≤ 1 v ⊤ ∇ x L A ( x ) \max_{x'\in \mathbf{B}(x)}\mathcal{L}_A(x') = \mathcal{L}_A(x) + \varepsilon \max_{\Vert v\Vert_p\leq 1} v^\top\nabla_x \mathcal{L}_A(x) maxx′∈B(x)LA(x′)=LA(x)+εmax∥v∥p≤1v⊤∇xLA(x)
I need to use ICML2019 First-order Adversarial Vulnerability of Neural Networks and Input Dimension A knot of On , namely max δ : ∥ δ ∥ p ≤ ϵ ∣ ∂ x L ⋅ δ ∣ = ϵ ∥ ∂ x L ∥ q , 1 p + 1 q = 1 \max_{\delta:\Vert \delta\Vert_p\leq\epsilon} |\partial_x\mathcal{L}\cdot \delta| = \epsilon\Vert\partial_x\mathcal{L} \Vert_q,\frac{1}{p}+\frac{1}{q}=1 maxδ:∥δ∥p≤ϵ∣∂xL⋅δ∣=ϵ∥∂xL∥q,p1+q1=1
Through lemma 1, We got the confrontation sample x ′ x' x′ For the loss function L A \mathcal{L}_A LA Influence , At the same time x x x Yes x ′ x' x′ The direction of .
lemma 2: Make W i j = W i − W j W_{ij} = W_i-W_j Wij=Wi−Wj Is the difference between the two weights , z ′ = z ( x ′ ; ω ) z' = z(x';\omega) z′=z(x′;ω) by x ′ x' x′ Eigenvector of , Then there is
∇ x ′ L C E ( f ( x ′ ) , f ( x ) ) = − ∑ i ≠ j f ( x ) i f ( x ′ ) j ∇ x ′ ( W i j ⊤ z ′ ) \nabla_{x'}\mathcal{L}_{CE}(f(x'),f(x)) = -\sum_{i\neq j}f(x)_if(x')_j\nabla_{x'}(W_{ij}^\top z') ∇x′LCE(f(x′),f(x))=−i=j∑f(x)if(x′)j∇x′(Wij⊤z′)
prove :
− ∇ x ′ L C E ( f ( x ′ ) , f ( x ) ) = ∇ x ′ ( f ( x ) ⊤ log f ( x ′ ) ) = ∑ i ∈ [ L ] f ( x ) i ∇ x ′ ( log f ( x ′ ) i ) = ∑ i ∈ [ L ] f ( x ) i ∇ x ′ ( log [ exp ( W i ⊤ z ′ ) ∑ j ∈ [ L ] exp ( W j ⊤ z ′ ) ] ) = ∑ i ∈ [ L ] f ( x ) i ∇ x ′ ( W i ⊤ z ′ − log ( ∑ j ∈ [ L ] exp ( W j ⊤ z ′ ) ) ) = ∑ i ∈ [ L ] f ( x ) i ( ∇ x ′ W i ⊤ z ′ − ∇ x ′ log ( ∑ j ∈ [ L ] exp ( W j ⊤ z ′ ) ) ) = ∑ i ∈ [ L ] f ( x ) i ( ∇ x ′ W i ⊤ z ′ − 1 ∑ j ∈ [ L ] exp ( W j ⊤ z ′ ) ∇ x ′ ( ∑ j ∈ [ L ] exp ( W j ⊤ z ′ ) ) ) = ∑ i ∈ [ L ] f ( x ) i ( ∇ x ′ W i ⊤ z ′ − 1 ∑ j ∈ [ L ] exp ( W j ⊤ z ′ ) ( ∑ j ∈ [ L ] exp ( W j ⊤ z ′ ) ∇ x ′ ( W j ⊤ z ′ ) ) ) = ∑ i ∈ [ L ] f ( x ) i ( ∇ x ′ W i ⊤ z ′ − ∑ j ∈ [ L ] f ( x ′ ) j ∇ x ′ ( W j ⊤ z ′ ) ) = ∑ i ∈ [ L ] f ( x ) i ( ( 1 − f ( x ′ ) i ) ∇ x ′ W i ⊤ z ′ − ∑ j ≠ i f ( x ′ ) j ∇ x ′ ( W j ⊤ z ′ ) ) = ∑ i ∈ [ L ] f ( x ) i ( ( ∑ i ≠ j exp ( W j ⊤ z ′ ) ∑ t ∈ [ L ] exp ( W t ⊤ z ′ ) ) ∇ x ′ W i ⊤ z ′ − ∑ j ≠ i f ( x ′ ) j ∇ x ′ ( W j ⊤ z ′ ) ) = ∑ i ∈ [ L ] f ( x ) i ( ( ∑ i ≠ j exp ( W j ⊤ z ′ ) ∑ t ∈ [ L ] exp ( W t ⊤ z ′ ) ) ∇ x ′ W i ⊤ z ′ − ∑ j ≠ i exp ( W j ⊤ z ′ ) ∑ t ∈ [ L ] exp ( W t ⊤ z ′ ) ∇ x ′ ( W j ⊤ z ′ ) ) = ∑ i ∈ [ L ] f ( x ) i ( ∑ i ≠ j f ( x ′ ) j ∇ x ′ ( W i j ⊤ z ′ ) ) = ∑ i ≠ j f ( x ) i f ( x ′ ) j ∇ x ′ ( W i j ⊤ z ′ ) \begin{aligned} -\nabla_{x'}\mathcal{L}_{CE}(f(x'),f(x))&=\nabla_{x'}(f(x)^\top\log f(x'))\\ &=\sum_{i\in [L]} f(x)_i\nabla_{x'}(\log f(x')_i)\\ &=\sum_{i\in [L]}f(x)_i\nabla_{x'}(\log [\frac{\exp(W_i^\top z')}{\sum_{j\in [L]}\exp(W_j^\top z')}])\\ &=\sum_{i\in [L]}f(x)_i\nabla_{x'}(W_i^\top z' - \log(\sum_{j\in [L]}\exp(W_j^\top z')))\\ &=\sum_{i\in [L]}f(x)_i(\nabla_{x'}W_i^\top z' - \nabla_{x'}\log(\sum_{j\in [L]}\exp(W_j^\top z')))\\ &=\sum_{i\in [L]}f(x)_i(\nabla_{x'}W_i^\top z' - \frac{1}{\sum_{j\in [L]}\exp(W_j^\top z')}\nabla_{x'}(\sum_{j\in [L]}\exp(W_j^\top z')))\\ &=\sum_{i\in [L]}f(x)_i(\nabla_{x'}W_i^\top z' - \frac{1}{\sum_{j\in [L]}\exp(W_j^\top z')}(\sum_{j\in [L]}\exp(W_j^\top z')\nabla_{x'}(W_j^\top z')))\\ &=\sum_{i\in [L]}f(x)_i(\nabla_{x'}W_i^\top z' - \sum_{j\in [L]}f(x')_j\nabla_{x'}(W_j^\top z'))\\ &=\sum_{i\in [L]}f(x)_i((1-f(x')_i)\nabla_{x'}W_i^\top z' - \sum_{j\neq i}f(x')_j\nabla_{x'}(W_j^\top z'))\\ &=\sum_{i\in [L]}f(x)_i((\frac{\sum_{i\neq j}\exp(W_j^\top z')}{\sum_{t\in [L]}\exp(W_t^\top z')})\nabla_{x'}W_i^\top z' - \sum_{j\neq i}f(x')_j\nabla_{x'}(W_j^\top z'))\\ &=\sum_{i\in [L]}f(x)_i((\frac{\sum_{i\neq j}\exp(W_j^\top z')}{\sum_{t\in [L]}\exp(W_t^\top z')})\nabla_{x'}W_i^\top z' - \sum_{j\neq i}\frac{\exp(W_j^\top z')}{\sum_{t\in [L]}\exp(W_t^\top z')}\nabla_{x'}(W_j^\top z'))\\ &=\sum_{i\in [L]}f(x)_i(\sum_{i\neq j}f(x')_j\nabla_{x'}(W_{ij}^\top z'))\\ &=\sum_{i\neq j}f(x)_if(x')_j\nabla_{x'}(W_{ij}^\top z') \end{aligned} −∇x′LCE(f(x′),f(x))=∇x′(f(x)⊤logf(x′))=i∈[L]∑f(x)i∇x′(logf(x′)i)=i∈[L]∑f(x)i∇x′(log[∑j∈[L]exp(Wj⊤z′)exp(Wi⊤z′)])=i∈[L]∑f(x)i∇x′(Wi⊤z′−log(j∈[L]∑exp(Wj⊤z′)))=i∈[L]∑f(x)i(∇x′Wi⊤z′−∇x′log(j∈[L]∑exp(Wj⊤z′)))=i∈[L]∑f(x)i(∇x′Wi⊤z′−∑j∈[L]exp(Wj⊤z′)1∇x′(j∈[L]∑exp(Wj⊤z′)))=i∈[L]∑f(x)i(∇x′Wi⊤z′−∑j∈[L]exp(Wj⊤z′)1(j∈[L]∑exp(Wj⊤z′)∇x′(Wj⊤z′)))=i∈[L]∑f(x)i(∇x′Wi⊤z′−j∈[L]∑f(x′)j∇x′(Wj⊤z′))=i∈[L]∑f(x)i((1−f(x′)i)∇x′Wi⊤z′−j=i∑f(x′)j∇x′(Wj⊤z′))=i∈[L]∑f(x)i((∑t∈[L]exp(Wt⊤z′)∑i=jexp(Wj⊤z′))∇x′Wi⊤z′−j=i∑f(x′)j∇x′(Wj⊤z′))=i∈[L]∑f(x)i((∑t∈[L]exp(Wt⊤z′)∑i=jexp(Wj⊤z′))∇x′Wi⊤z′−j=i∑∑t∈[L]exp(Wt⊤z′)exp(Wj⊤z′)∇x′(Wj⊤z′))=i∈[L]∑f(x)i(i=j∑f(x′)j∇x′(Wij⊤z′))=i=j∑f(x)if(x′)j∇x′(Wij⊤z′)
In lemma 2 above , remember y ∗ y^* y∗ It's a countermeasure sample x ∗ x^* x∗ Prediction output of , among y ≠ y ∗ y\neq y^* y=y∗
Based on some prior observations , Usually, the probability value of the output tag is predicted (Top1 Probability ) It is much larger than the probability value of other tags
So there is
∇ x ′ L C E ( f ( x ′ ) , f ( x ) ) ≈ − f ( x ) y f ( x ′ ) y ∗ ∇ x ′ ( W y y ∗ ⊤ z ′ ) \nabla_{x'}\mathcal{L}_{CE}(f(x'),f(x))\approx -f(x)_yf(x')_{y^*}\nabla_{x'}(W_{yy^*}^\top z') ∇x′LCE(f(x′),f(x))≈−f(x)yf(x′)y∗∇x′(Wyy∗⊤z′)
among W y y ∗ = W y − W y ∗ W_{yy^*}=W_y-W_{y^*} Wyy∗=Wy−Wy∗
Make θ y y ∗ ′ = ∠ ( W y y ∗ , z ′ ) \theta_{yy^*}'=\angle(W_{y y^*},z') θyy∗′=∠(Wyy∗,z′), W y y ∗ ⊤ z ′ = ∥ W y y ∗ ∥ ∥ z ′ ∥ cos ( θ y y ∗ ′ ) W_{y y^*}^\top z'=\Vert W_{y y^*}\Vert\Vert z'\Vert \cos(\theta_{y y^*}') Wyy∗⊤z′=∥Wyy∗∥∥z′∥cos(θyy∗′) also W y y ∗ W_{y y^*} Wyy∗ Don't depend on x ′ x' x′
thus , Iteration of each attack , x x x The increment of is
U p [ ∇ x ′ L C E ( f ( x ′ ) , f ( x ) ) ] ≈ − U p [ ∇ x ′ ( ∥ z ′ ∥ cos ( θ y y ∗ ′ ) ) ] \mathbb{U}_p[\nabla_{x'}\mathcal{L}_{CE}(f(x'),f(x))]\approx-\mathbb{U}_p[\nabla_{x'}(\Vert z'\Vert \cos(\theta_{y y^*}'))] Up[∇x′LCE(f(x′),f(x))]≈−Up[∇x′(∥z′∥cos(θyy∗′))]
And the method previously introduced , Will make ∥ z ′ ∥ = 1 \Vert z'\Vert = 1 ∥z′∥=1, Thus, the attack samples are closer to the classification boundary
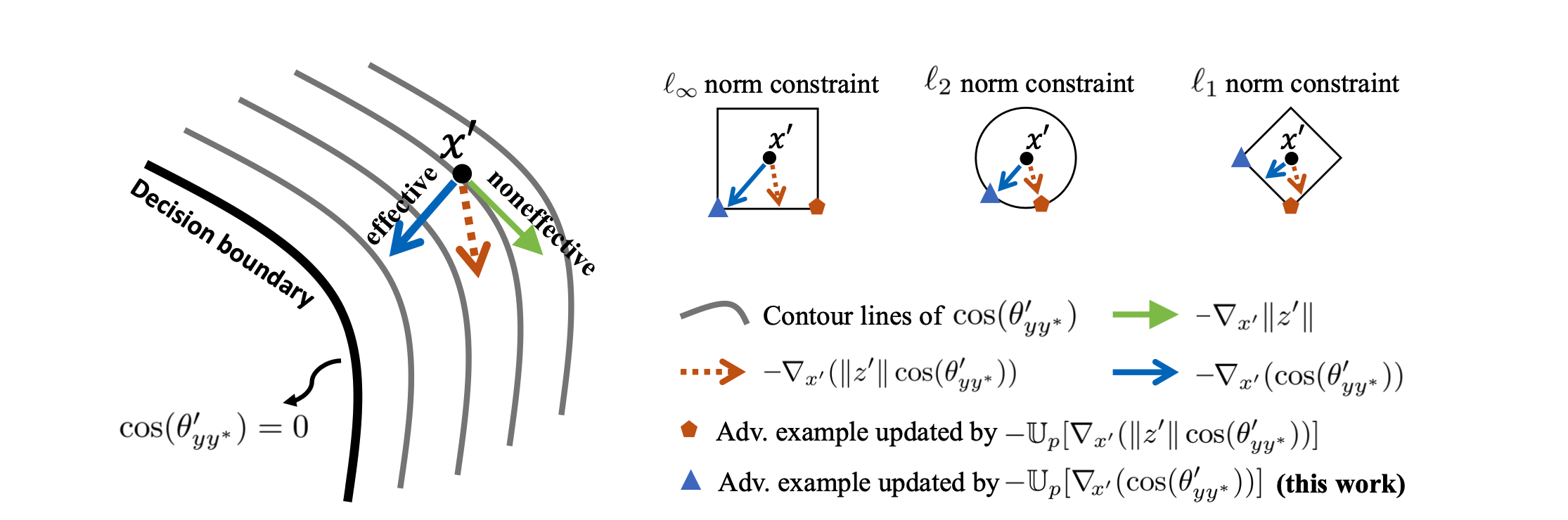
As shown in the figure above , ∥ z ′ ∥ \Vert z'\Vert ∥z′∥ Will affect the direction of descent , The effect of the generated countermeasure samples is relatively poor , And then inhibit the efficiency of confrontation training
experimental analysis
First of all CIFAR-10 White box attack test on
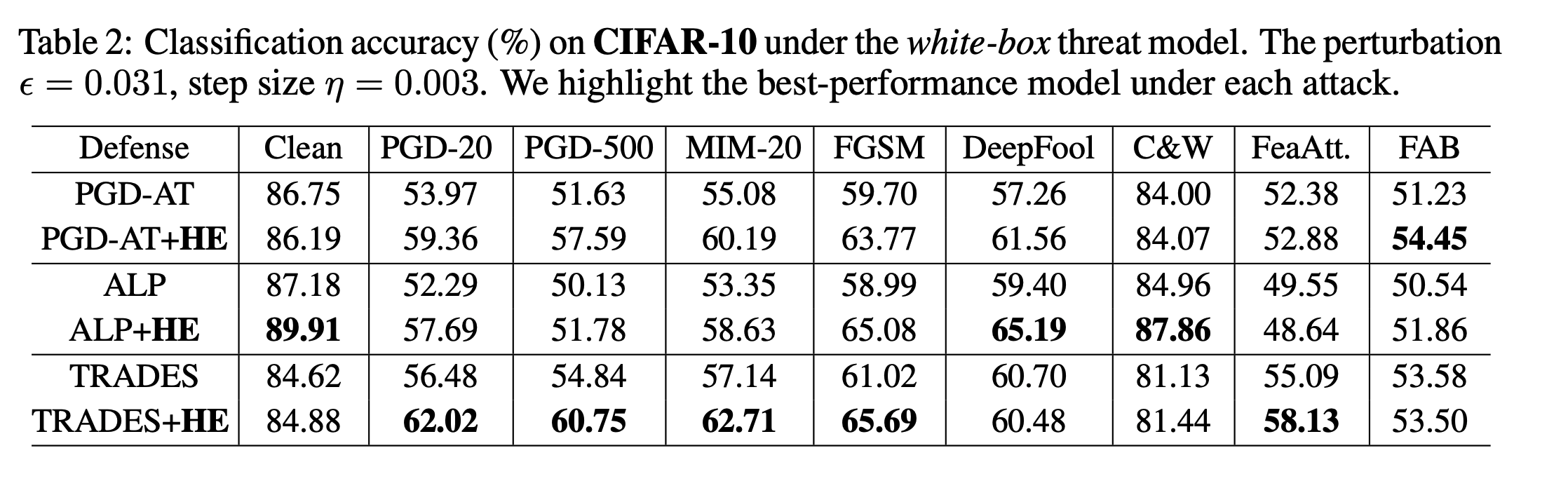
You can see , added HE After that, the defense effect will be improved , In a few cases, it will decline
And then there was ImageNet Test on

comparison FreeAT, The defense effect will be obvious
边栏推荐
- 【Programming】
- How to turn on night mode on laptop
- 【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》
- EKLAVYA -- 利用神经网络推断二进制文件中函数的参数
- 将恶意软件嵌入到神经网络中
- Gensim如何冻结某些词向量进行增量训练
- Income in the first month of naked resignation
- 【学习笔记】Matlab自编图像卷积函数
- 【C#笔记】winform中保存DataGridView中的数据为Excel和CSV
- 【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
猜你喜欢
What if the laptop can't search the wireless network signal
![Open3d learning note 3 [sampling and voxelization]](/img/71/0b2ac5dfd538017de639e5651c7f46.png)
Open3d learning note 3 [sampling and voxelization]

The difference and understanding between generative model and discriminant model

【双目视觉】双目矫正

针对tqdm和print的顺序问题
Implementation of yolov5 single image detection based on onnxruntime
【MobileNet V3】《Searching for MobileNetV3》

【MagNet】《Progressive Semantic Segmentation》
服务器的内网可以访问,外网却不能访问的问题

【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》
随机推荐
Execution of procedures
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
Deep learning classification Optimization Practice
【Paper Reading】
Graph Pooling 简析
【Cutout】《Improved Regularization of Convolutional Neural Networks with Cutout》
【Programming】
Replace convolution with full connection layer -- repmlp
【Mixed Pooling】《Mixed Pooling for Convolutional Neural Networks》
将恶意软件嵌入到神经网络中
Where do you find the materials for those articles that have read 10000?
[mixup] mixup: Beyond Imperial Risk Minimization
【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》
用全连接层替代掉卷积 -- RepMLP
Machine learning theory learning: perceptron
【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
【MagNet】《Progressive Semantic Segmentation》
【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
WCF更新服务引用报错的原因之一
图像增强的几个方法以及Matlab代码