当前位置:网站首页>用MLP代替掉Self-Attention
用MLP代替掉Self-Attention
2022-07-02 06:26:00 【MezereonXP】
用MLP代替掉Self-Attention
这次介绍的清华的一个工作 “Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks”
用两个线性层代替掉Self-Attention机制,最终实现了在保持精度的同时实现速度的提升。
这个工作让人意外的是,我们可以使用MLP代替掉Attention机制,这使我们应该重新好好考虑Attention带来的性能提升的本质。
Transformer中的Self-Attention机制
首先,如下图所示:

我们给出其形式化的结果:
A = softmax ( Q K T d k ) F o u t = A V A = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})\\ F_{out} = AV A=softmax(dkQKT)Fout=AV
其中, Q , K ∈ R N × d ′ Q,K \in \mathbb{R}^{N\times d'} Q,K∈RN×d′ 同时 V ∈ R N × d V\in \mathbb{R}^{N\times d} V∈RN×d
这里,我们给出一个简化版本,如下图所示:
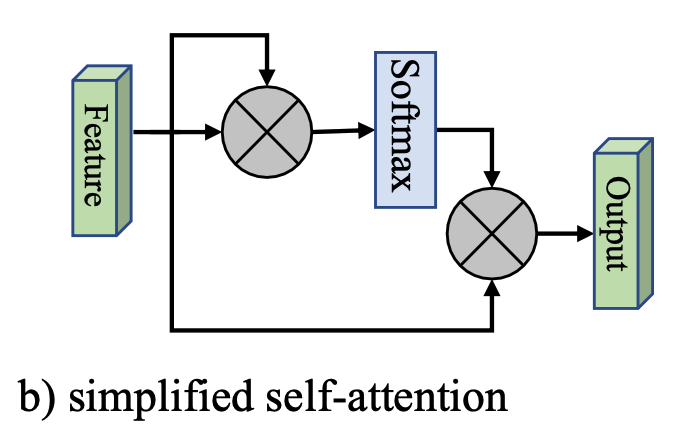
也就是将 Q , K , V Q,K,V Q,K,V 都以输入特征 F F F 代替掉,其形式化为:
A = softmax ( F F T ) F o u t = A F A = \text{softmax}(FF^T)\\ F_{out} = AF A=softmax(FFT)Fout=AF
然而,这里面的计算复杂度为 O ( d N 2 ) O(dN^2) O(dN2),这是Attention机制的一个较大的缺点。
外部注意力 (External Attention)
如下图所示:
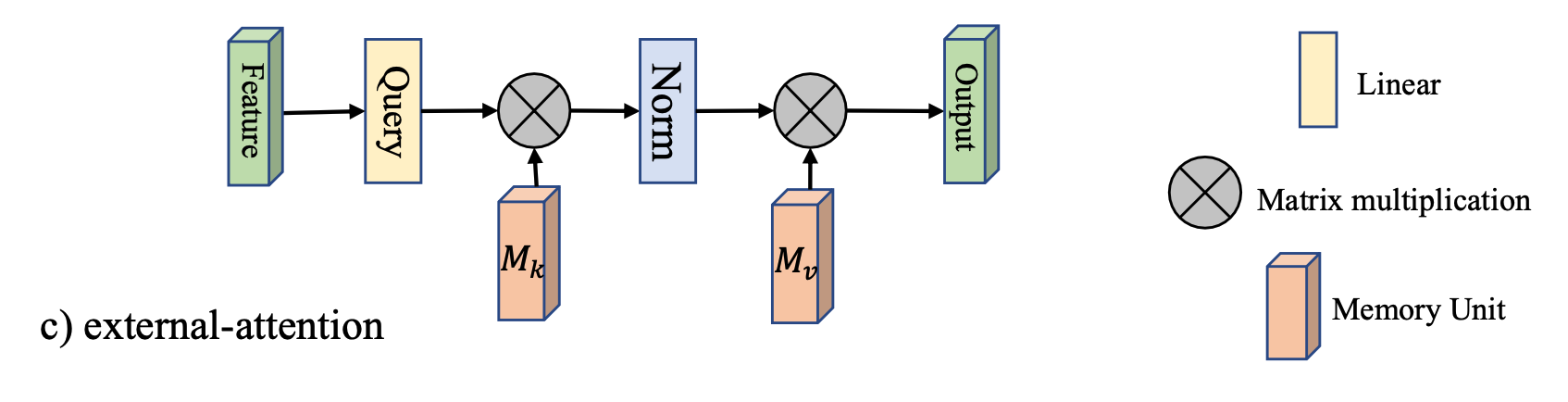
引入了两个矩阵 M k ∈ R S × d M_k\in \mathbb{R}^{S\times d} Mk∈RS×d 以及 $M_v \in\mathbb{R}^{S\times d} $, 代替掉原来的 K , V K,V K,V
这里直接给出其形式化:
A = Norm ( F M k T ) F o u t = A M v A = \text{Norm}(FM_k^T)\\ F_{out} = AM_v A=Norm(FMkT)Fout=AMv
这种设计,将复杂度降低到 O ( d S N ) O(dSN) O(dSN), 该工作发现,当 S ≪ N S\ll N S≪N 的时候,仍然能够保持足够的精度。
其中的 Norm ( ⋅ ) \text{Norm}(\cdot) Norm(⋅) 操作是先对列进行Softmax,然后对行进行归一化。
实验分析
首先,文章将Transformer中的Attention机制替换掉,然后在各类任务上进行测试,包括:
- 图像分类
- 语义分割
- 图像生成
- 点云分类
- 点云分割
这里只给出部分结果,简单说明一下替换后的精度损失情况。
图像分类

语义分割

图像生成

可以看到,在不同的任务上,基本上不会有精度损失。
边栏推荐
- [binocular vision] binocular stereo matching
- Mmdetection model fine tuning
- PPT的技巧
- Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations
- Huawei machine test questions-20190417
- Memory model of program
- Conversion of numerical amount into capital figures in PHP
- win10+vs2017+denseflow编译
- 【MobileNet V3】《Searching for MobileNetV3》
- A slide with two tables will help you quickly understand the target detection
猜你喜欢

Traditional target detection notes 1__ Viola Jones
![How do vision transformer work? [interpretation of the paper]](/img/93/5f967b876fbd63c07b8cfe8dd17263.png)
How do vision transformer work? [interpretation of the paper]

生成模型与判别模型的区别与理解

【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》
TimeCLR: A self-supervised contrastive learning framework for univariate time series representation
【MobileNet V3】《Searching for MobileNetV3》

【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
The difference and understanding between generative model and discriminant model
![[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video](/img/bc/c54f1f12867dc22592cadd5a43df60.png)
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video

Feature Engineering: summary of common feature transformation methods
随机推荐
基于onnxruntime的YOLOv5单张图片检测实现
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video
【TCDCN】《Facial landmark detection by deep multi-task learning》
【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
Calculate the total in the tree structure data in PHP
【双目视觉】双目矫正
PointNet理解(PointNet实现第4步)
【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
Using MATLAB to realize: power method, inverse power method (origin displacement)
【MnasNet】《MnasNet:Platform-Aware Neural Architecture Search for Mobile》
Sorting out dialectics of nature
论文tips
点云数据理解(PointNet实现第3步)
【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
Execution of procedures
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
PHP returns the corresponding key value according to the value in the two-dimensional array
ModuleNotFoundError: No module named ‘pytest‘
(15) Flick custom source
MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning