当前位置:网站首页>【MobileNet V3】《Searching for MobileNetV3》
【MobileNet V3】《Searching for MobileNetV3》
2022-07-02 07:48:00 【bryant_ meng】

ICCV-2019
List of articles
1 Background and Motivation
【MobileNet】《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》(CVPR-2017)
【MobileNet V2】《MobileNetV2:Inverted Residuals and Linear Bottlenecks》(CVPR-2018)
deliver the next generation of high accuracy efficient neural network models to power on-device computer vision
2 Related Work
Manually design the network
reducing the number of parameters -> reducing the number of operations (MAdds) -> reducing the actual measured latencyNAS
cell level -> block levelQuantization
knowledge distillation
3 Advantages / Contributions
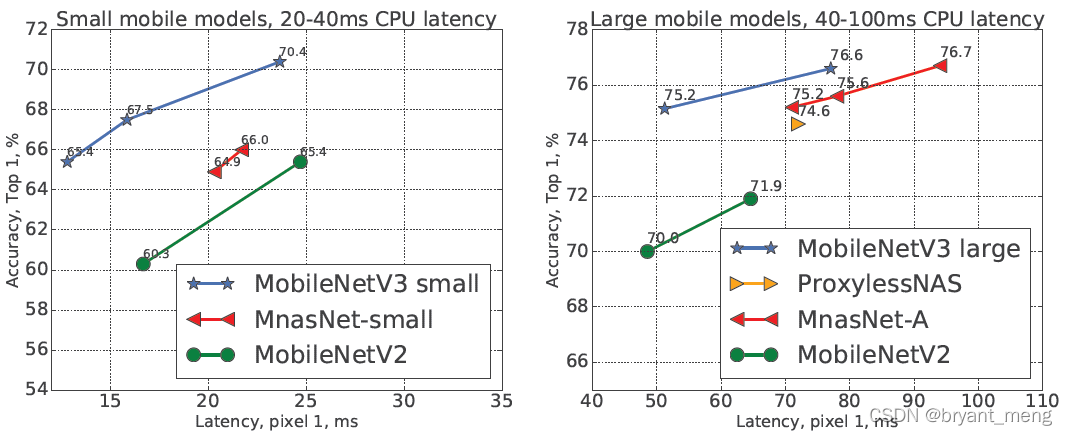
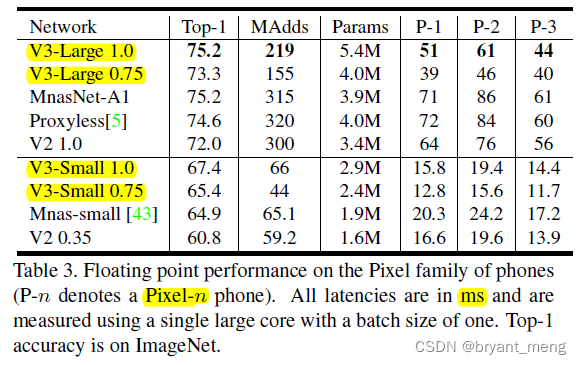
NAS + Manually design and assemble mobilenet v3 backbone, Put forward hard swish Activation function (swish Improved version ), Put forward Lite R-ASPP Split head (R-ASPP Improved version ), In the classification 、 object detection 、 The speed and accuracy of segmented data sets are improved
4 Method
1)Network Search
Platform-Aware NAS for Blockwise Search( come from MnastNet, A little modification reward design The weight of )
NetAdapt for Layerwise Search
search per layer for the number of filters
maximizes △ A c c △ l a t e n c y \frac{\bigtriangleup Acc}{\bigtriangleup latency} △latency△Acc
2)Network Improvements
Redesigning Expensive Layers
search The back of the network is heavy , optimized
Head
channels 32 + ReLU or swish Reduced to channels 16 + hard swish
The tail

Nonlinearities

s w i s h ( x ) = x ⋅ σ ( x ) swish(x) = x \cdot \sigma(x) swish(x)=x⋅σ(x)
swish activation function Although it improves the accuracy of the network , But it is not friendly to hardware deployment , Increased computing time , The author adopts the following improvements (piece-wise linear)
h − s w i s h ( x ) = x R e L U 6 ( x + 3 ) 6 h-swish(x) = x \frac{ReLU6(x+3)}{6} h−swish(x)=x6ReLU6(x+3)
Than relu Slow
only use h-swish at the second half of the model(we find that most of the benefits swish are realized by using them only in the deeper layers)
Large squeeze-and-excite
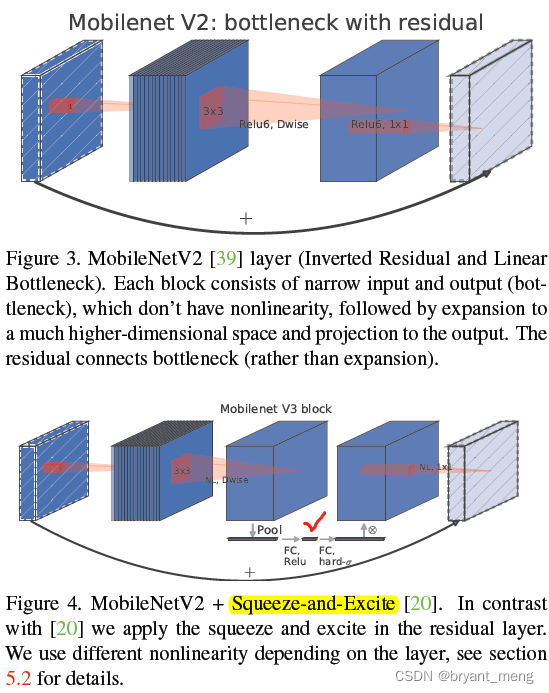
v3 Compared with v2, Adopted SE modular ,SE Inside sigmoid It's also used hard form , That is to say R e L U 6 ( x + 3 ) 6 \frac{ReLU6(x+3)}{6} 6ReLU6(x+3)

The author put SE Module squeeze fc Fixed to block in expand Of channels 1/4( chart 4 red √ It's about )
no discernible latency cost
MobileNetV3 Definitions

The picture is from Lightweight skeleton preferred :MobileNetV3 Complete resolution 

5 Experiments
use single-threaded large core in all our measurements
5.1 Datasets
- ImageNet
- COCO
- Cityscapes
5.2 Classification

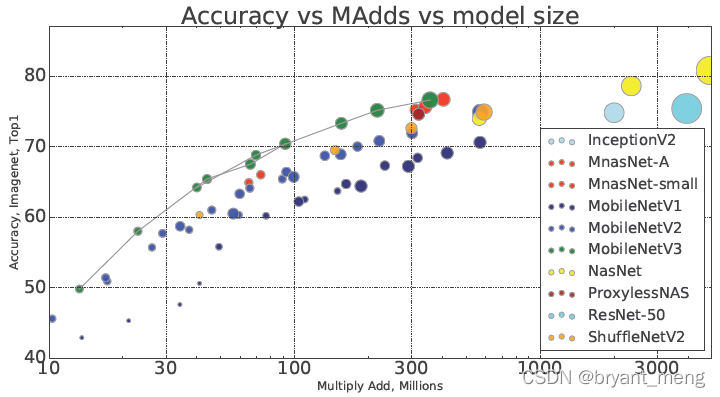
The upper left corner is best
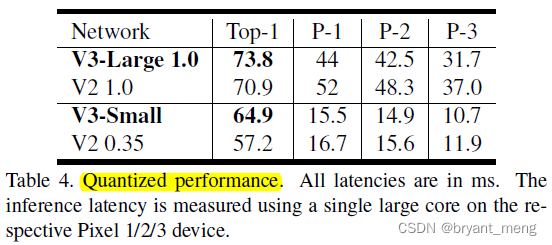
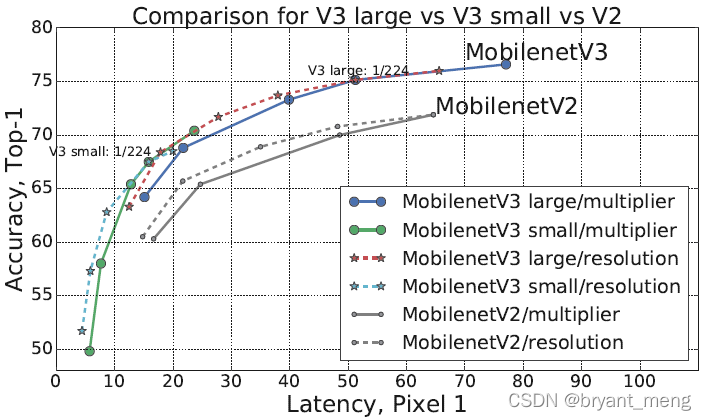

1)Impact of non-linearities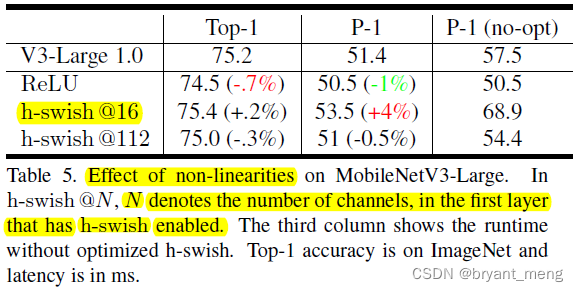
there 112 What you read is not particularly understood ,N The bigger it is, the more reasonable it is h-swish The more , It's slower , How fast
2)Impact of other components
5.3 Detection

mAP Out of line , ha-ha
5.4 Segmentation
R-ASPP Improve on the basis of 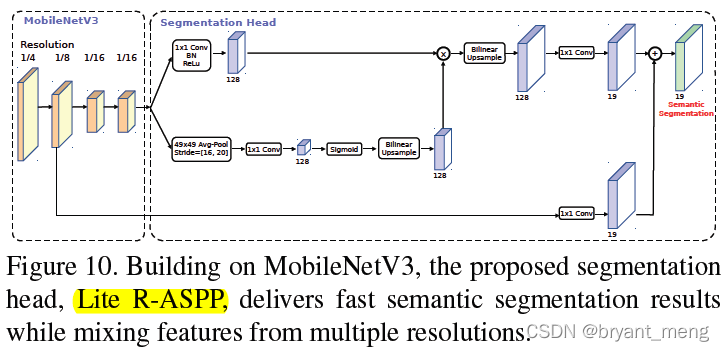


6 Conclusion(own) / Future work
Pareto-optimal, Pareto is the best ( From Baidu Encyclopedia )
Pareto is the best (Pareto Optimality), Also known as Pareto efficiency (Pareto efficiency), It refers to an ideal state of resource allocation , Suppose there is an inherent group of people and distributable resources , The change from one allocation state to another , Without making anyone worse , Make at least one person better , This is Pareto improvement or Pareto optimization .
Pareto optimal state It is impossible to have more room for Pareto improvement ; let me put it another way , Pareto improvement is the path and method to achieve Pareto optimality . Pareto optimality is fair and efficient “ Ideal kingdom ”. It was proposed by Pareto .MobileNet V3 = MobileNet v2 + SE + hard-swish activation + half initial layers channel & last block do global average pooling first( come from Gai Rou is in a panic )
边栏推荐
- 【双目视觉】双目矫正
- Execution of procedures
- 【MobileNet V3】《Searching for MobileNetV3》
- 基于onnxruntime的YOLOv5单张图片检测实现
- Apple added the first iPad with lightning interface to the list of retro products
- 【Random Erasing】《Random Erasing Data Augmentation》
- Using MATLAB to realize: Jacobi, Gauss Seidel iteration
- Thesis writing tip2
- open3d环境错误汇总
- PHP returns the corresponding key value according to the value in the two-dimensional array
猜你喜欢

Faster-ILOD、maskrcnn_benchmark训练coco数据集及问题汇总
TimeCLR: A self-supervised contrastive learning framework for univariate time series representation

【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》

【TCDCN】《Facial landmark detection by deep multi-task learning》
Alpha Beta Pruning in Adversarial Search
Point cloud data understanding (step 3 of pointnet Implementation)

【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》

What if a new window always pops up when opening a folder on a laptop
![[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video](/img/bc/c54f1f12867dc22592cadd5a43df60.png)
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video
随机推荐
Implementation of yolov5 single image detection based on pytorch
Two dimensional array de duplication in PHP
【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
[introduction to information retrieval] Chapter 3 fault tolerant retrieval
[introduction to information retrieval] Chapter 6 term weight and vector space model
MMDetection模型微调
ABM论文翻译
Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations
【MnasNet】《MnasNet:Platform-Aware Neural Architecture Search for Mobile》
【Batch】learning notes
PPT的技巧
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
论文tips
【Paper Reading】
Common CNN network innovations
[paper introduction] r-drop: regulated dropout for neural networks
【Random Erasing】《Random Erasing Data Augmentation》
Use Baidu network disk to upload data to the server
[Sparse to Dense] Sparse to Dense: Depth Prediction from Sparse Depth samples and a Single Image
Tencent machine test questions