当前位置:网站首页>【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
2022-07-02 07:44:00 【bryant_ meng】


ECCV-2018
List of articles
1 Background and Motivation
Semantic segmentation can be widely used in AR、 Autopilot 、 Monitoring and other scenes ,these applications have a high demand for efficient inference speed
for fast interaction or response.
At present, lightweight semantic segmentation network accelerates the network from the following three aspects ( chart 1-a)
1)restrict the input size, shortcoming , lost spatial details
2)prune the channels of the network, shortcoming , The author thinks it is lost spatial capacity( It's a little too much of a pushover , It can only be said that the ability of feature expression must be weak , After all, the resolution is still )
3)drop the last stage of the model, shortcoming , Lost feeling field
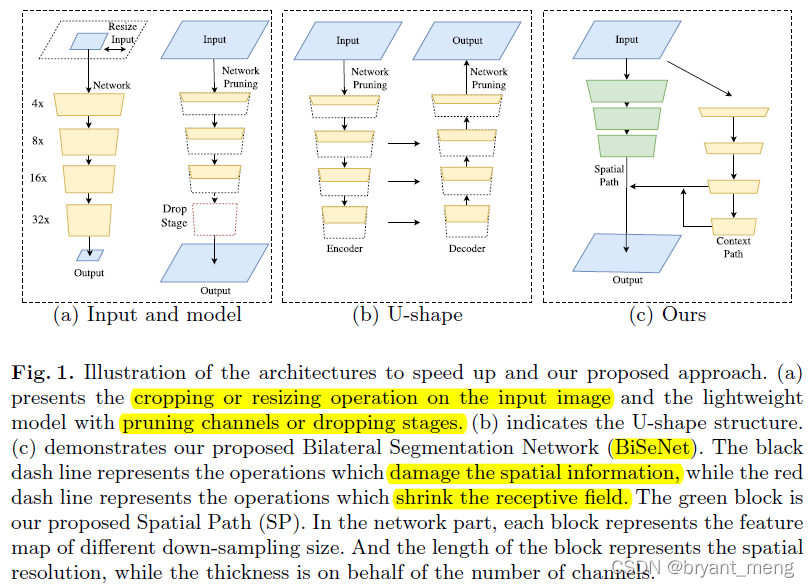
For relief spatial-detail The loss of , People proposed to adopt U-shape Structure ( representative U-Net), however U-shape The structure also has the following shortcomings :
1)reduce the speed( The fusion operation of high-resolution feature map is introduced )
2)most spatial information lost in the pruning or cropping cannot be easily recovered by involving the shallow layers
U-shape technique is better to regard as a relief, rather than an essential solution( The summary is very good )
The author proposes a lightweight semantic segmentation network Bilateral Segmentation Network (BiSeNet) with two parts: Spatial Path (SP) and Context Path (CP) To deal with the loss of spatial information in the existing lightweight semantic segmentation network 、 The problem of receptive field contraction .
2 Related Work
- Spatial information
- U-Shape method
- Context information
- Attention mechanism
- Real time segmentation
3 Advantages / Contributions
The design proposes BiSeNet Lightweight split network ,decouple the function of spatial information preservation and receptive field offering into two paths——Spatial Path and a Context Path.
Designed two path Feature fusion module Feature Fusion Module (FFM) Attention Refinement Module (ARM)
On the public dataset impressive results
4 Method

1)Spatial path
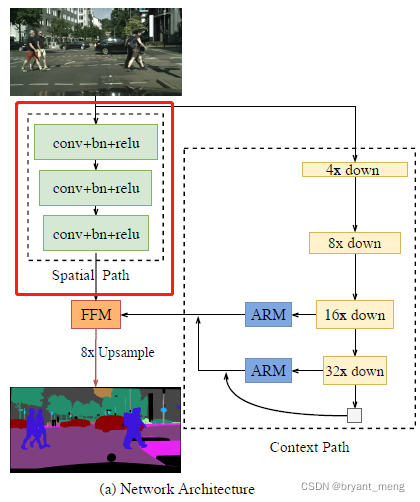
3 Steps are 2 Of conv, The resolution of the output characteristic image is 1/8——wide network to capture adequate spatial information
2)Context path
consideration of the large receptive field and efficient computation simultaneously
a lightweight model to provide sufficient receptive field
The trunk Xception39,down-sample rapidly, The last layer of feature map is followed by global average pooling To maximize the acquisition of receptive field
3)ARM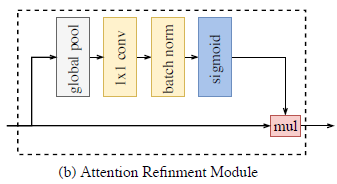
and SENet It's like
4)FFM
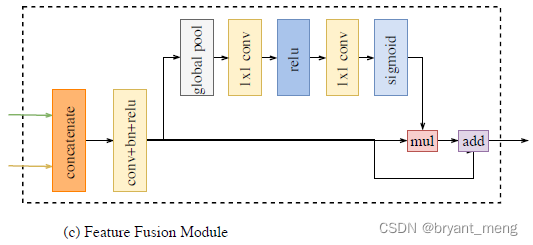
The features of the two paths are different in level of feature representation
You can't simply add
concat coordination BN, Wonderful ( because BN The parameters of each channel are different , As shown in the figure below )
utilize the batch normalization to balance the scales of the features.

【BN】《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
5)Loss function
All losses are Multi class cross entropy loss
Besides , The author also introduces auxiliary loss
l p l_p lp:principal loss of the concatenated output, That is to say FFM After sampling and GT Calculated loss
l i l_i li: the auxiliary loss for stage i i i, K = 3 K = 3 K=3, That is, the backbone network stage2 and stage3 Supervision is introduced in
α \alpha α Set in the article as 1
6)“poly” learning rate strategy
l r = b a s e _ l r ⋅ ( 1 − i t e r m a x _ i t e r ) p o w e r lr = base\_lr \cdot (1- \frac{iter}{max\_iter})^{power} lr=base_lr⋅(1−max_iteriter)power
p o w e r power power What is set in the text is 0.9
Initial learning rate b a s e _ l r base\_lr base_lr by 2.5 e − 2 2.5e^{−2} 2.5e−2
5 Experiments
5.1 Datasets
- Cityscapes:19 classes(test)
- CamVid:11 semantic categories
- COCO-Stuff: Yes COCO All in the dataset 164K The picture is marked at pixel level ,91 stuff classes and 1 class ’unlabeled’
5.2 Ablation study
1) The trunk 
2)Ablation for U-shape
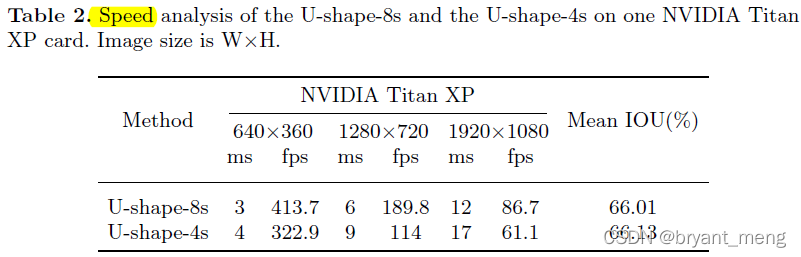
4 and 8 The meaning of :
The number represents the down-sampling factor of the output feature
3)Ablation for spatial path / attention refinement module / feature fusion module / global average pooling
5.3 Speed and Accuracy Analysis


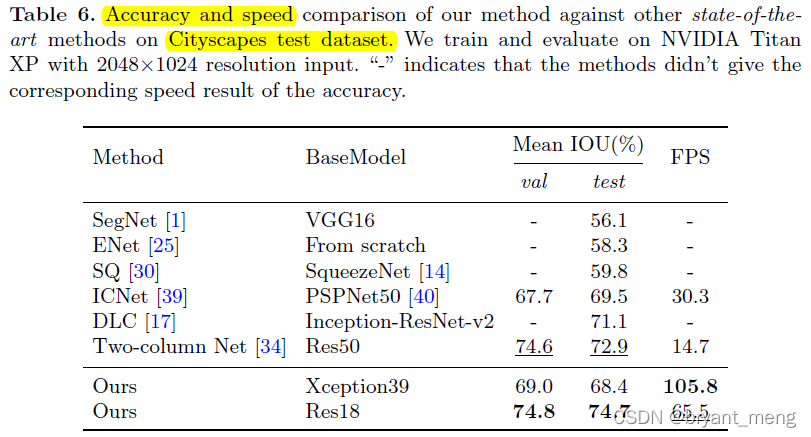
2048×1024 resize To 1536×768 resolution for testing the speed and accuracy
Let's look at the performance on public data sets
Cityspaces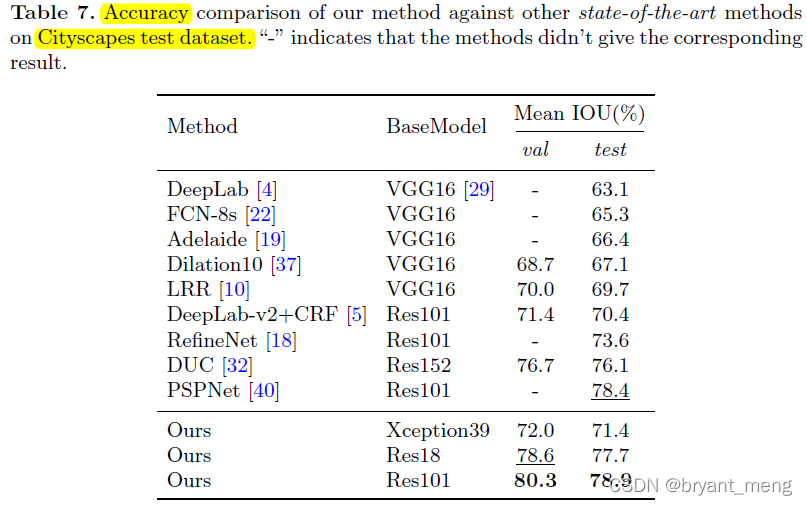
and table6 The result is a little different ,we take randomly take 1024×1024 crop as input
CamVid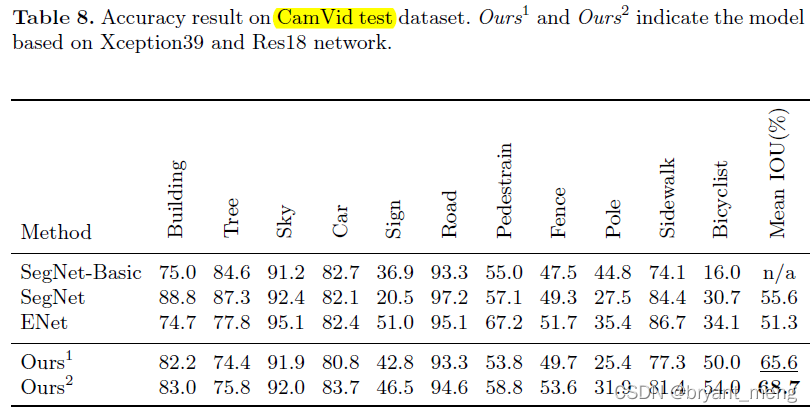
COCO-Stuff
6 Conclusion(own) / Future work
the spatial information of the image is crucial to predicting the detailed output
Semantic segmentation requires context information to generate a high-quality result
“ASPP” module is proposed to capture context information of different receptive field.
Context Feel the field
try to capture sufficient receptive field with pyramid pooling module, atrous spatial pyramid pooling or “large kernel”
the lightweight model damages spatial information with the channel pruning.
The scales contains { 0.75, 1.0, 1.5, 1.75, 2.0}. Finally, we randomly crop the image into fix size for training.
边栏推荐
- Common machine learning related evaluation indicators
- yolov3训练自己的数据集(MMDetection)
- 【Mixed Pooling】《Mixed Pooling for Convolutional Neural Networks》
- Implementation of yolov5 single image detection based on onnxruntime
- Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations
- MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning
- Solve the problem of latex picture floating
- Machine learning theory learning: perceptron
- Faster-ILOD、maskrcnn_benchmark训练coco数据集及问题汇总
- 【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
猜你喜欢

Interpretation of ernie1.0 and ernie2.0 papers

Deep learning classification Optimization Practice

Machine learning theory learning: perceptron

Label propagation
Installation and use of image data crawling tool Image Downloader
![[multimodal] clip model](/img/45/8501269190d922056ea0aad2e69fb7.png)
[multimodal] clip model

【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》
SSM personnel management system

How do vision transformer work?【论文解读】
![[model distillation] tinybert: distilling Bert for natural language understanding](/img/c1/e1c1a3cf039c4df1b59ef4b4afbcb2.png)
[model distillation] tinybert: distilling Bert for natural language understanding
随机推荐
CONDA common commands
MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
[tricks] whiteningbert: an easy unsupervised sentence embedding approach
Thesis tips
Jordan decomposition example of matrix
How to efficiently develop a wechat applet
MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning
Transform the tree structure into array in PHP (flatten the tree structure and keep the sorting of upper and lower levels)
MMDetection模型微调
Regular expressions in MySQL
程序的执行
Faster-ILOD、maskrcnn_ Benchmark installation process and problems encountered
Calculate the difference in days, months, and years between two dates in PHP
Drawing mechanism of view (I)
What if a new window always pops up when opening a folder on a laptop
PHP returns the abbreviation of the month according to the numerical month
ABM论文翻译
【深度学习系列(八)】:Transoform原理及实战之原理篇