当前位置:网站首页>Zero foundation uses paddlepaddle to build lenet-5 network
Zero foundation uses paddlepaddle to build lenet-5 network
2022-07-05 03:13:00 【victor_ gx】
Convolutional neural networks (Convolutional Neural Networks, CNN) It is a kind of feedforward neural network including convolution calculation , It is based on the translation invariance of image task ( The object of image recognition has the same meaning in different positions ) The design of the , Good at image processing and other tasks .
One 、 A brief introduction of convolutional neural network
In image processing , Image data has a very high dimension ( High dimensional RGB The matrix represents ), So training a standard feedforward network to recognize images will require thousands of input neurons , Except for the obvious high computational complexity , It may also lead to many problems related to the dimension disaster in neural networks .
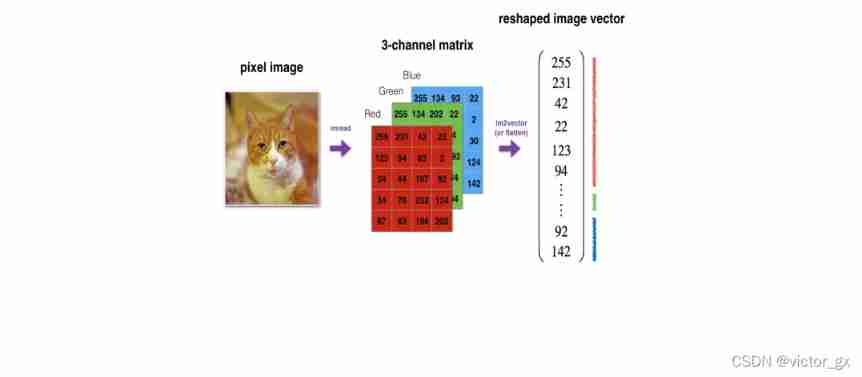
For high-dimensional image data , Convolution neural network uses convolution and pooling layer , It is important to extract images efficiently “ features ”, Then through the following full connection layer “ Compressed image information ” And output results . Compare standard fully connected networks , The model parameters of convolutional neural network are greatly reduced .
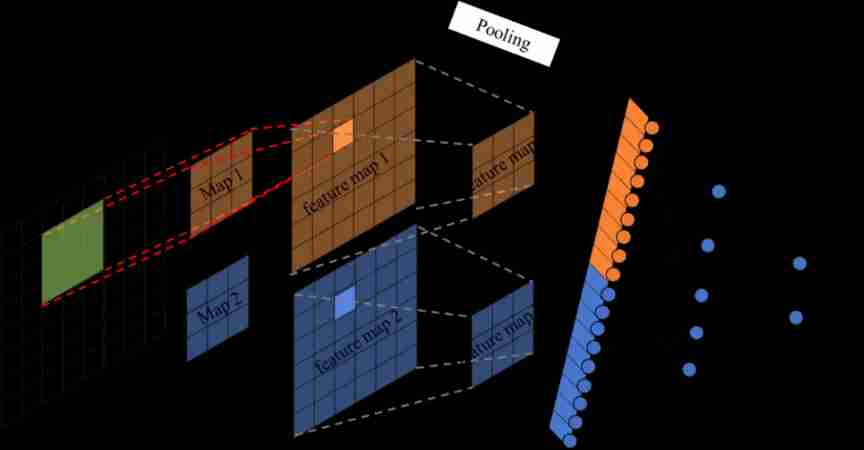
Two 、 Convolutional neural network “ Convolution ”
2.1 The principle of convolution
In signal processing 、 Image processing and other engineering / In the field of Science , Convolution is a widely used technique , Convolutional neural networks (CNN) This model architecture is named convolution computation . however , In the field of deep learning “ Convolution ” It's essentially a signal / Cross correlation in the field of image processing (cross-correlation), In fact, there are some differences between cross-correlation and convolution . Convolution It is an important operation in analytical mathematics . Simple definition f , g Is an integrable function , The convolution operation of the two is as follows :
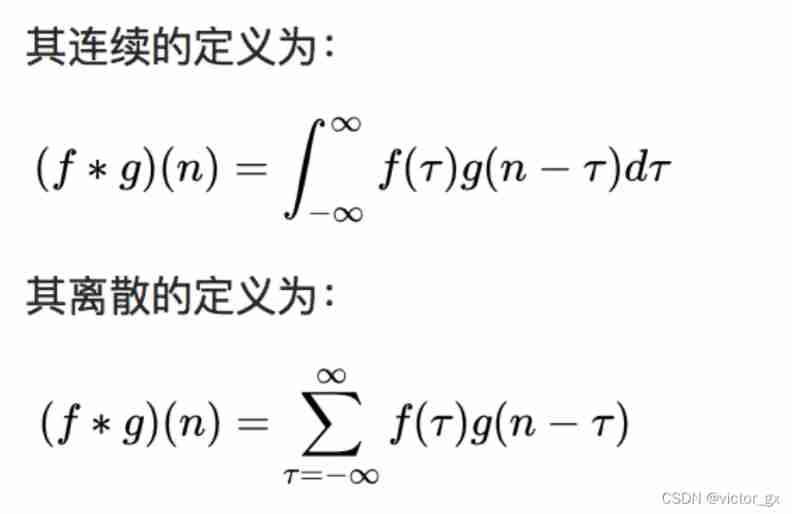
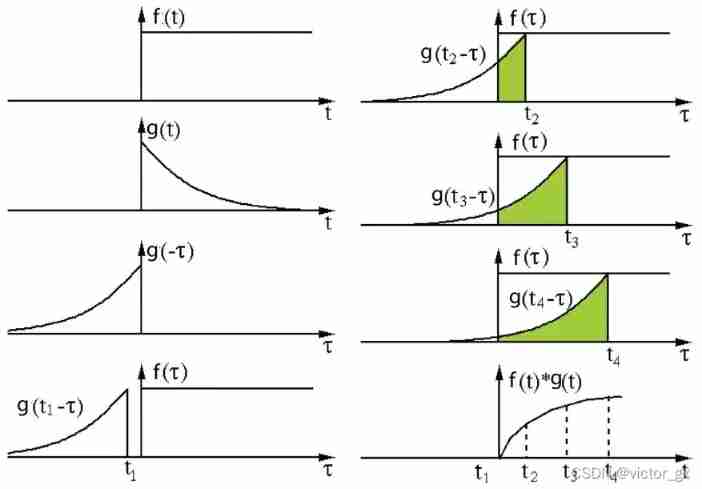
Its definition is one of two functions (g) The integral of the product obtained by multiplication after inversion and displacement . Here's the picture , function g It's the filter . It is reversed and then slides along the horizontal axis . In every position , We all calculate f And after reversal g The area of the intersection area between . The area of this intersecting region is the convolution value at a specific location .
Cross correlation Is the sliding point product or sliding inner product between two functions . Filters in correlation Without inversion , Instead, it slides directly over the function f,f And g The cross region between them is cross-correlation .

The following figure shows the operation process of convolution and cross-correlation , Difference in area change of intersecting areas :
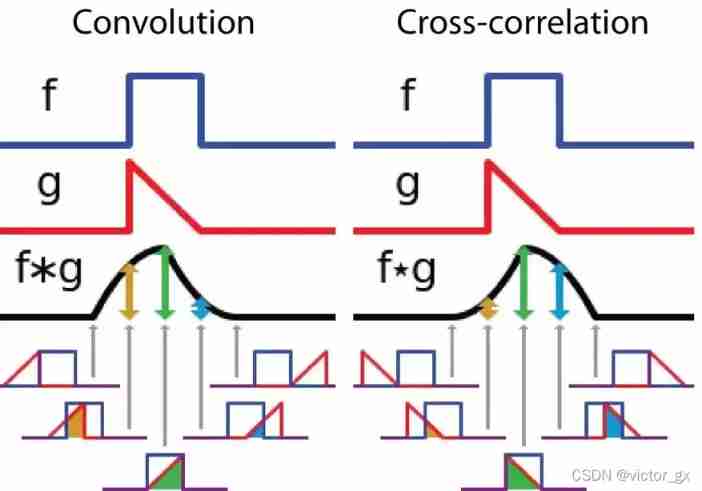
In a convolutional neural network , The filter in convolution is not inverted . Strictly speaking , This is a discrete form of cross-correlation operation , Essentially, it performs element by element multiplication and summation . But the effect of the two is the same , Because the weight parameters of the filter are learned in the training stage , After training , The learned filter will look like an inverted function .
2.2 The function of convolution
CNN By designing the convolution kernel (convolution filter, Also known as kernel) Convolution with the picture ( Shift the convolution kernel to do the product step by step and sum ).
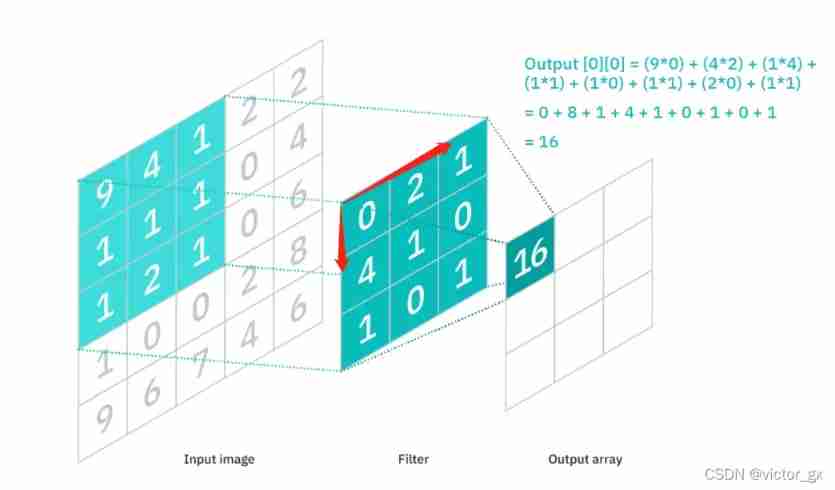
The following example designs a ( Specific parameters ) Of 3×3 Convolution kernel :
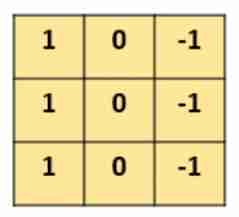
Let it convolute with the picture , The specific process of convolution is :
- Use this convolution kernel to cover the original picture ;
- After covering an area as large as the convolution kernel , Multiply the corresponding elements , Then sum it ;
- After calculating a region , Just move to other areas ( Suppose the step size is 1), Continue to calculate ;
- Until every corner of the original picture is covered ;
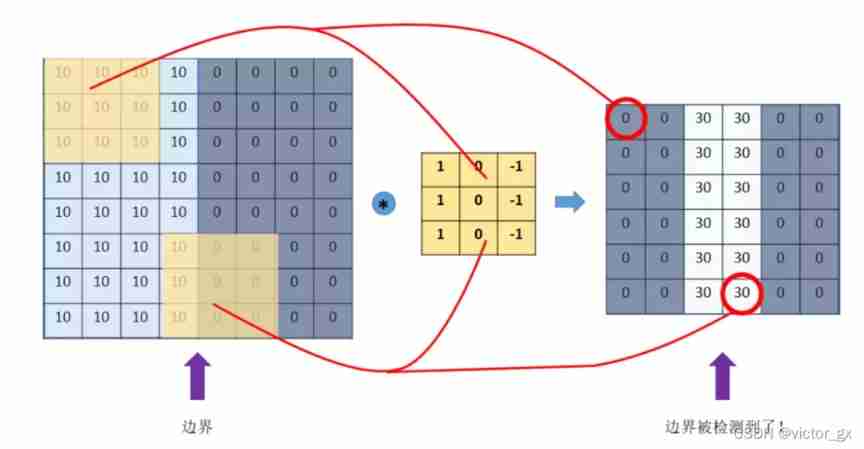
You can find , Through a specific filter, Let it convolute with the picture , You can extract some features from the picture , Such as boundary features .
further , We can use huge data , Deep enough neural network , The back propagation algorithm is used to let the machine automatically learn these convolution kernel parameters , The features extracted by convolution kernel with different parameters are also different , You can extract the local 、 Deeper and more global features to apply to decision making .

Essential summary of convolution operation : filter (g) Right picture (f) Perform step-by-step multiplication and sum , The process of extracting features . Convolution process visualization is accessible :https://github.com/vdumoulin/conv_arithmetic
3、 ... and 、 Convolutional neural networks
Convolutional neural networks are usually composed of 3 Parts make up : Convolution layer , Pooling layer , Fully connected layer . Simply speaking , The convolution layer is responsible for extracting local and global features in the image ; The pool layer is used to greatly reduce the parameter magnitude ( Dimension reduction ); The full connection layer is used to handle “ Compressed image information ” And output the result .
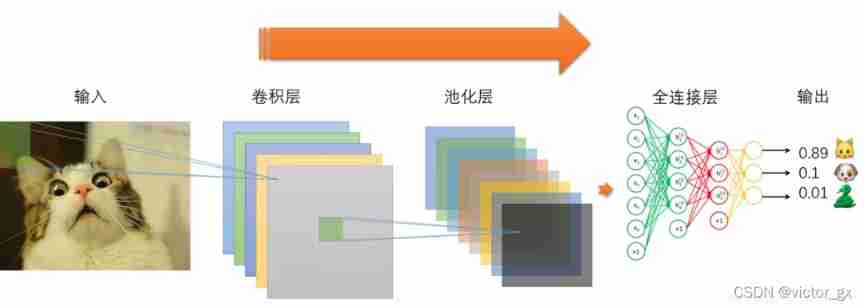
3.1 Convolution layer (CONV)
3.1.1 Basic properties of convolution layer
The main function of convolution layer is to dynamically extract image features , By filter filters And the activation function . The general parameters to be set include filters The number of 、 size 、 step , Activate function type , as well as padding yes “valid” still “same”.
- The main function of convolution layer is to dynamically extract image features , By filter filters And the activation function . The general parameters to be set include filters The number of 、 size 、 step , Activate function type , as well as padding yes “valid” still “same”.
- Number of convolution kernels : It is mainly adjusted according to the actual situation , Generally, they take 2 Integer power of , The greater the number, the greater the amount of calculation , The stronger the fitting ability of the corresponding model .
- step (Stride): The pixels moved in each step when the convolution kernel traverses the feature map , If the step size is 1 Then every time you move 1 Pixel , In steps of 2 Then every time you move 2 Pixel ( That is, skip 1 Pixel ), And so on . The smaller the step , The extracted features will be more refined .
- fill (Padding): How to deal with the boundary of characteristic graph , There are generally two kinds of , One is “valid”, No filling at all outside the boundary , Convolution is performed only on input pixels , This will make the size of the output feature image smaller , And the edge information is easy to lose ; The other is still “same”, Fill outside the boundary ( Generally filled with 0), Then perform the convolution operation , In this way, the size of the output feature map can be consistent with the size of the input feature map , Edge information can also be calculated multiple times .
- passageway (Channel): Number of channels in convolution layer ( The layer number ). Such as color images are generally RGB Three channels (channel).
- Activation function : Mainly based on the actual verification , Usually choose Relu.
additional , The type of convolution except the standard convolution , It also evolved deconvolution 、 Separable convolution 、 Various types such as packet convolution , Can self verify .
3.1.2 Characteristics of convolution layer
Through the introduction of convolution operation , It can be found that the accretion layer has two main characteristics : Local connection ( Sparse connection ) And weight sharing .
- Local connection , That is, the nodes of the convolution layer are only connected with some nodes of the previous layer , Only used to learn local regional features .( The concept of local connection perceptual structure comes from the cortical structure of animal vision , It refers to that only a part of the neurons of animal vision play a role in the process of perceiving external objects .)
- Weight sharing , The same convolution kernel will convolute with different regions of the input picture , To detect the same features , The weight parameters above the convolution kernel are spatially shared , The amount of parameters is greatly reduced .
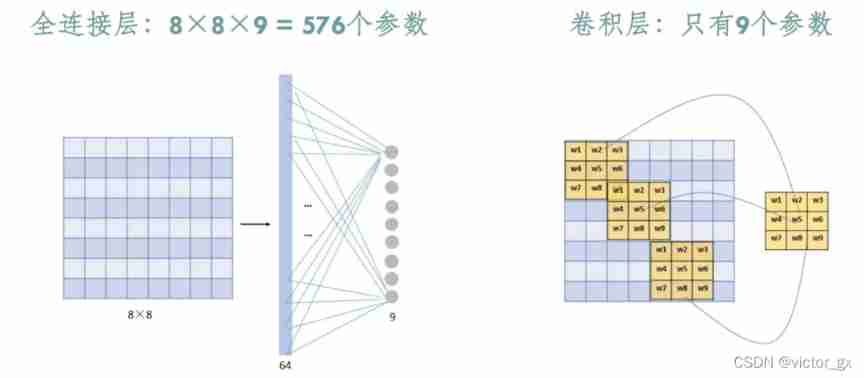
Due to local connection ( Sparse connection ) And weight sharing , bring CNN have Affine invariance ( translation 、 Linear transformation such as scaling )
3.2 Pooling layer (Pooling)
Pooling layer can reduce the dimension of extracted feature information , On the one hand, make the feature map smaller , Simplify network computing complexity ; On the other hand, feature compression , Extract the main features , Increase translation invariance , Reduce the risk of overfitting . But in fact, pooling is more a compromise of computing performance , The feature is strongly compressed and some information is lost , Therefore, the current network uses less pooling layer or optimized layer, such as SoftPool.
Super parameters set by the pool layer , The type of pool layer included is Max still Average(Average Keep the background better ,Max Better texture extraction ), Window size, step size, etc . As follows MaxPooling, A 2×2 The window of , And take the step stride=2, Extract the of each window max Value characteristics (AveragePooling It's the average ):
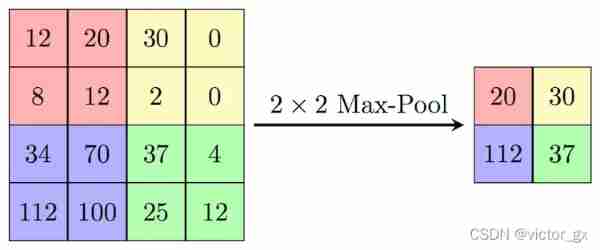
3.3 Fully connected layer (FC)
After several convolutions and pooling , Finally, we will compress the multi-dimensional image data first “ flat ”, That is the (height,width,channel) The data is compressed to a length of height × width × channel One dimensional array of , Then connect with the full connection layer ( This is the traditional fully connected network layer , Each unit is connected to each unit of the previous layer , The superparameter to be set is mainly the number of neurons , And the type of activation function ), Through the full connection layer “ Compressed image information ” And output the result .
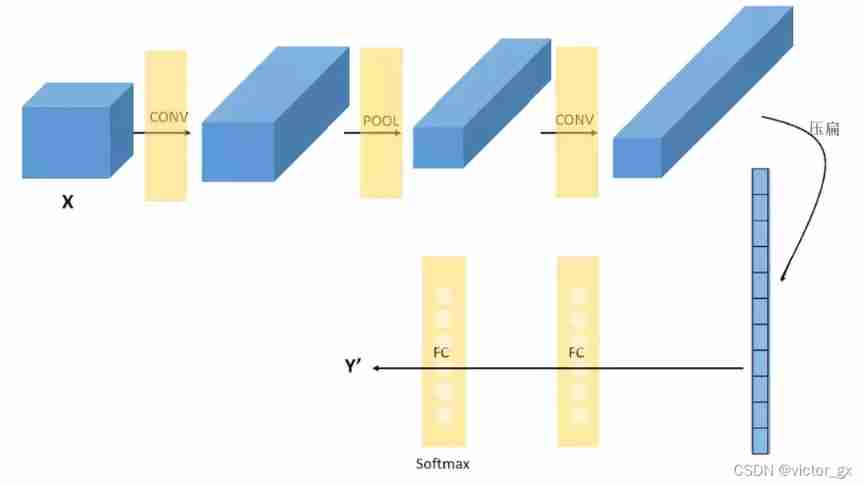
3.4 Example : classic CNN The construction of (Lenet-5)
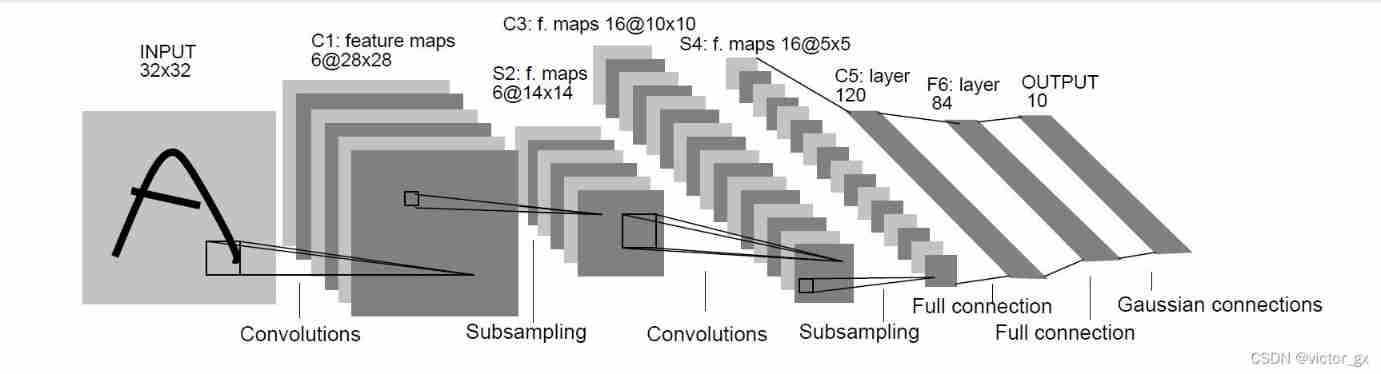
LeNet-5 from Yann LeCun Designed in 1998 year , It is one of the earliest convolutional neural networks . It is trained for gray images , The input image size is 32321, There are... In the case of no input layer 7 layer . The following is a layer by layer introduction LeNet-5 Structure :
- 1、C1- Convolution layer
The first layer is the convolution layer , Used to filter noise , Extract key features . Use 5 * 5 Size filter 6 individual , step s = 1,padding = 0.
- 2、S2- The sample layer ( Average pooling layer )
The second layer is the average pool layer , Using the principle of image local correlation , Subsampling the image , Can reduce the amount of data processing while retaining useful information , Reduce the over fitting degree of network training parameters and models . Use 2 * 2 Size filter , step s = 2,padding = 0. The pool layer has only one set of super parameters pool_size and step strides, There are no model parameters to learn .
- 3、C3- Convolution layer
The third layer uses 5 * 5 Size filter 16 individual , step s = 1,padding = 0.
- 4、S4- The sample layer ( Average pooling layer )
The fourth layer uses 2 * 2 Size filter , step s = 2,padding = 0. There are no parameters to learn .
- 5、F5- Fully connected layer
The fifth layer is the full connection layer , Its input size is one dimension , So we need to L4 The output data size of the layer is re divided ,S4 The output shape size of the layer is 16×5×5, be L5 The size of the one-dimensional input shape of the layer is 16×5×5, Output shape size is 120.
- 6、F6- Fully connected layer
Yes 84 A unit . Each unit is associated with F5 All of the layers 120 Full connection between units .
- 7、F7- Fully connected layer
F7 It is also a full connection layer , use RBF How to connect the network , share 10 Nodes , They represent numbers 0 To 9( because Lenet For outputting identification numbers ), If node i The output value of is 0, The result of network identification is number i.
The code is as follows
import paddle
from paddle.nn import Conv2D, MaxPool2D, Linear, Flatten, Sequential
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.model = Sequential(
Conv2D(in_channels = 1, out_channels = 6, kernel_size = 5, stride = 1),
MaxPool2D(kernel_size = 2, stride = 2),
Conv2D(in_channels = 6, out_channels = 16, kernel_size = 5, stride = 1),
MaxPool2D(kernel_size = 2, stride = 2),
Flatten(),
Linear(16 * 5 * 5, 120),
Linear(120, 84),
Linear(84, 10)
)
# self.conv1 = Conv2D(in_channels = 1, out_channels = 6, kernel_size = 5, stride = 1)
# self.maxpool1 = MaxPool2D(kernel_size = 2, stride = 2)
# self.conv2 = Conv2D(in_channels = 6, out_channels = 16, kernel_size = 5, stride = 1)
# self.maxpool2 = MaxPool2D(kernel_size = 2, stride = 2)
# self.flatten = Flatten()
# self.linear1 = Linear(16 * 5 * 5, 120)
# self.linear2 = Linear(120, 84)
# self.linear3 = Linear(84, 10)
def forward(self, x):
x = self.model(x)
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
# x = self.linear3(x)
return x
lenet = LeNet()
print(lenet)
input1 = paddle.ones((64, 1, 32, 32))
output = lenet(input1)
print(output.shape)
Four 、 Use LeNet-5 Model development MNIST Classification of handwritten Numbers
import paddle
import paddle.nn.functional as F
from paddle.nn import Conv2D, MaxPool2D, Linear, Flatten
from paddle.vision.transforms import Compose, Normalize
transform = Compose([Normalize(mean=[127.5], std=[127.5], data_format='CHW')])
# Import MNIST data
train_dataset=paddle.vision.datasets.MNIST(mode="train", transform=transform)
val_dataset=paddle.vision.datasets.MNIST(mode="test", transform=transform)
# Defining models
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = Conv2D(in_channels = 1, out_channels = 6, kernel_size = 5, stride = 1)
self.maxpool1 = MaxPool2D(kernel_size = 2, stride = 2)
self.conv2 = Conv2D(in_channels = 6, out_channels = 16, kernel_size = 5, stride = 1)
self.maxpool2 = MaxPool2D(kernel_size = 2, stride = 2)
self.flatten = Flatten()
self.linear1 = Linear(256, 120) # Change the image size according to the specific input
self.linear2 = Linear(120, 84)
self.linear3 = Linear(84, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = F.relu(x)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return x
model = paddle.Model(LeNet())
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
model.fit(train_dataset, epochs=50, batch_size=1024, verbose=1)
model.evaluate(val_dataset,verbose=1)
边栏推荐
- Apache build web host
- Azkaban installation and deployment
- Ubantu disk expansion (VMware)
- 1. Five layer network model
- Talk about the SQL server version of DTM sub transaction barrier function
- Tencent cloud, realize image upload
- IPv6 experiment
- Kuboard
- How can we truncate the float64 type to a specific precision- How can we truncate float64 type to a particular precision?
- Voice chip wt2003h4 B008 single chip to realize the quick design of intelligent doorbell scheme
猜你喜欢
Three line by line explanations of the source code of anchor free series network yolox (a total of ten articles, which are guaranteed to be explained line by line. After reading it, you can change the
Sqoop命令
Azkaban actual combat
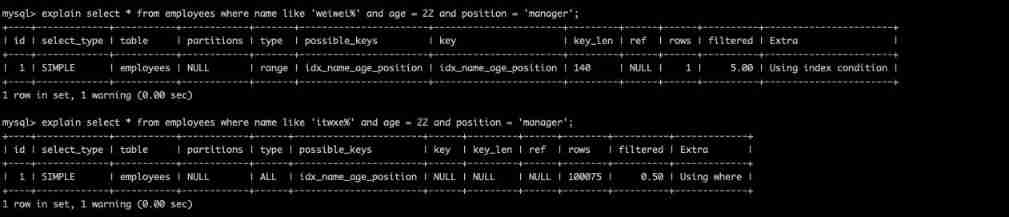
SQL performance optimization skills
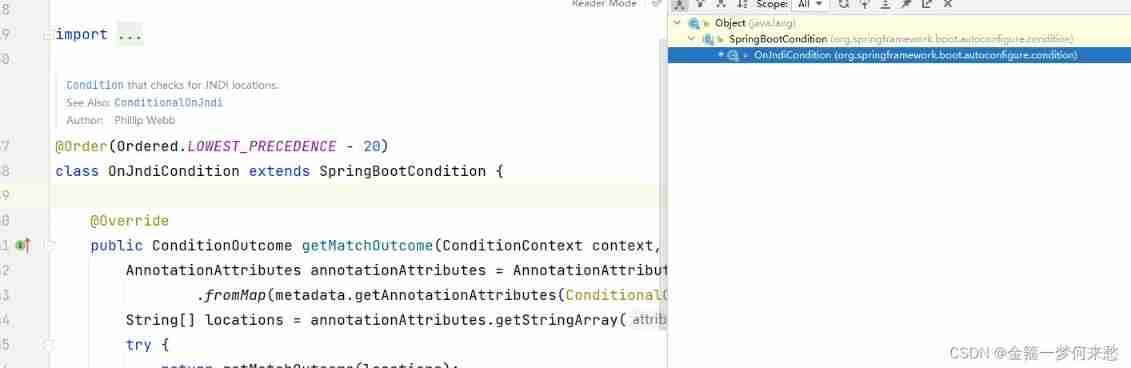
Idea inheritance relationship
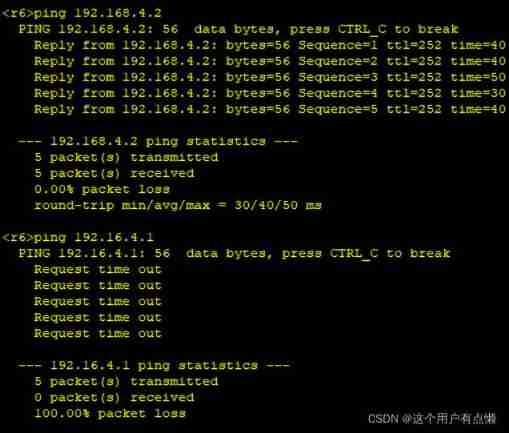
Huawei MPLS experiment
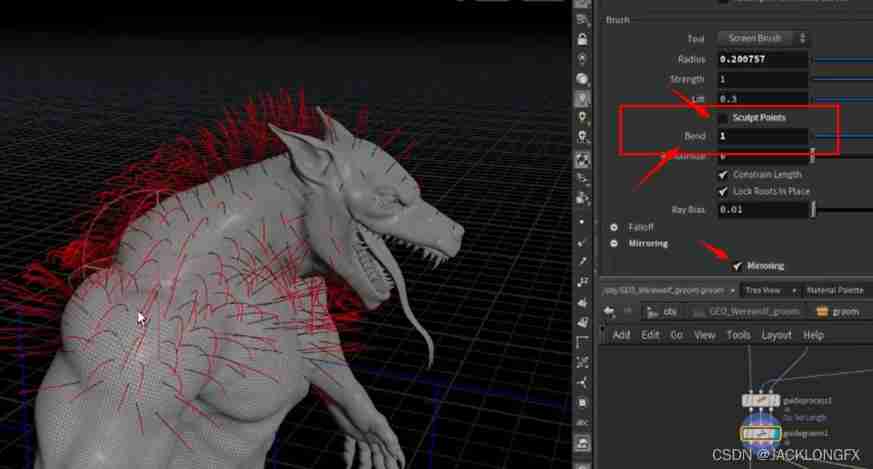
Master Fur
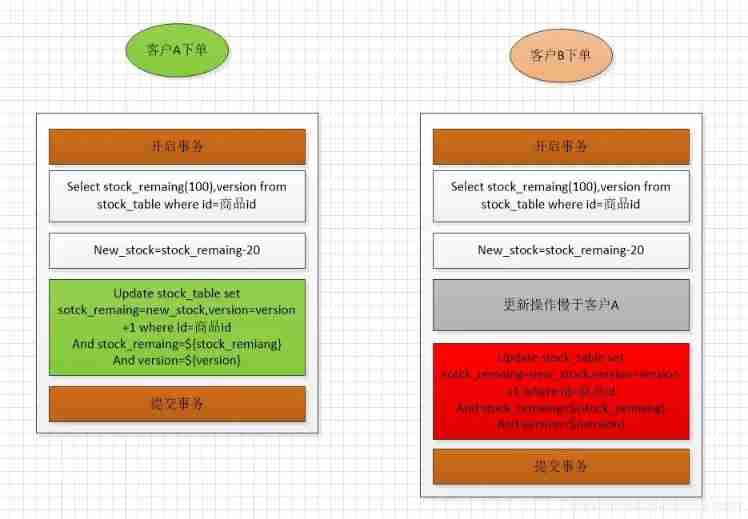
Jd.com 2: how to prevent oversold in the deduction process of commodity inventory?
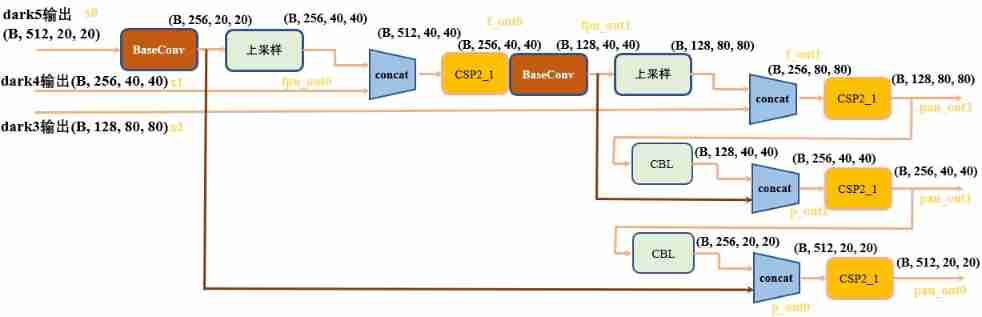
Anchor free series network yolox source code line by line explanation Part 2 (a total of 10, ensure to explain line by line, after reading, you can change the network at will, not just as a participan

Apache build web host
随机推荐
问下,这个ADB mysql支持sqlserver吗?
Sqoop installation
Share the newly released web application development framework based on blazor Technology
Azkaban overview
端口,域名,协议。
GFS分布式文件系统
el-select,el-option下拉选择框
D3js notes
Qrcode: generate QR code from text
ELK日志分析系统
Bumblebee: build, deliver, and run ebpf programs smoothly like silk
Elk log analysis system
College Students' innovation project management system
The database and recharge are gone
Usage scenarios and solutions of ledger sharing
SQL performance optimization skills
040. (2.9) relieved
Last words record
Cut! 39 year old Ali P9, saved 150million
Daily question 2 12