当前位置:网站首页>MIT-6874-Deep Learning in the Life Sciences Week 7
MIT-6874-Deep Learning in the Life Sciences Week 7
2022-07-05 06:00:00 【Wooden girl】
Lecture 05 Interpretable Deep Learning
- Interpretable deep learning
- One 、Intro to Interpretability
- 1a. Interpretability definition: Convert implicit NN information to human-interpretable information
- 1b. Motivation: Verify model works as intended; debug classifier; make discoveries; Right to explanation
- 1c. Ante-hoc (train interpretable model) vs. Post-hoc (interpret complex model; degree of “locality”)
- 2. Interpreting Deep Neural Networks
- Evaluating Attribution Methods
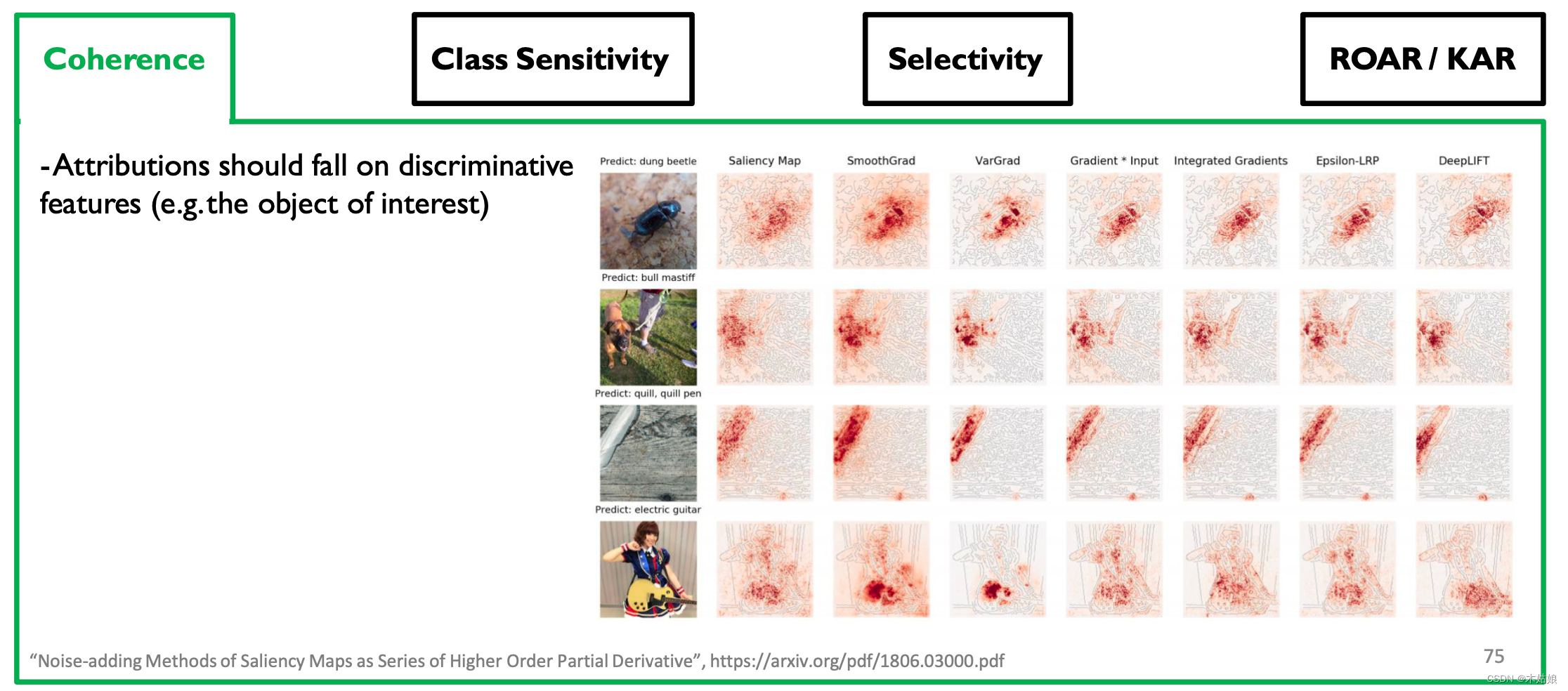
- 3a. Qualitative: Coherence: Attributions should highlight discriminative features / objects of interest
- 3b. Qualitative: Class Sensitivity: Attributions should be sensitive to class labels
- 3c. Quantitative: Sensitivity: Removing feature with high attribution --> large decrease in class probability
- 3d. Quantitative: ROAR & KAR. Low class prob cuz image unseen --> remove pixels, retrain, measure acc. drop
Interpretable deep learning
This section discusses the explicability of deep learning . Model itself means knowledge , Explicability is of great importance to people like deep learning “ Black box model ” for , It is the root of explaining the reason and method why he made such a judgment , It can help the model work in the direction of human expectations . In many scenes , If recommended 、 Medical and other scenarios have great application prospects .
The following is the outline of this class 
One 、Intro to Interpretability
1a. Interpretability definition: Convert implicit NN information to human-interpretable information
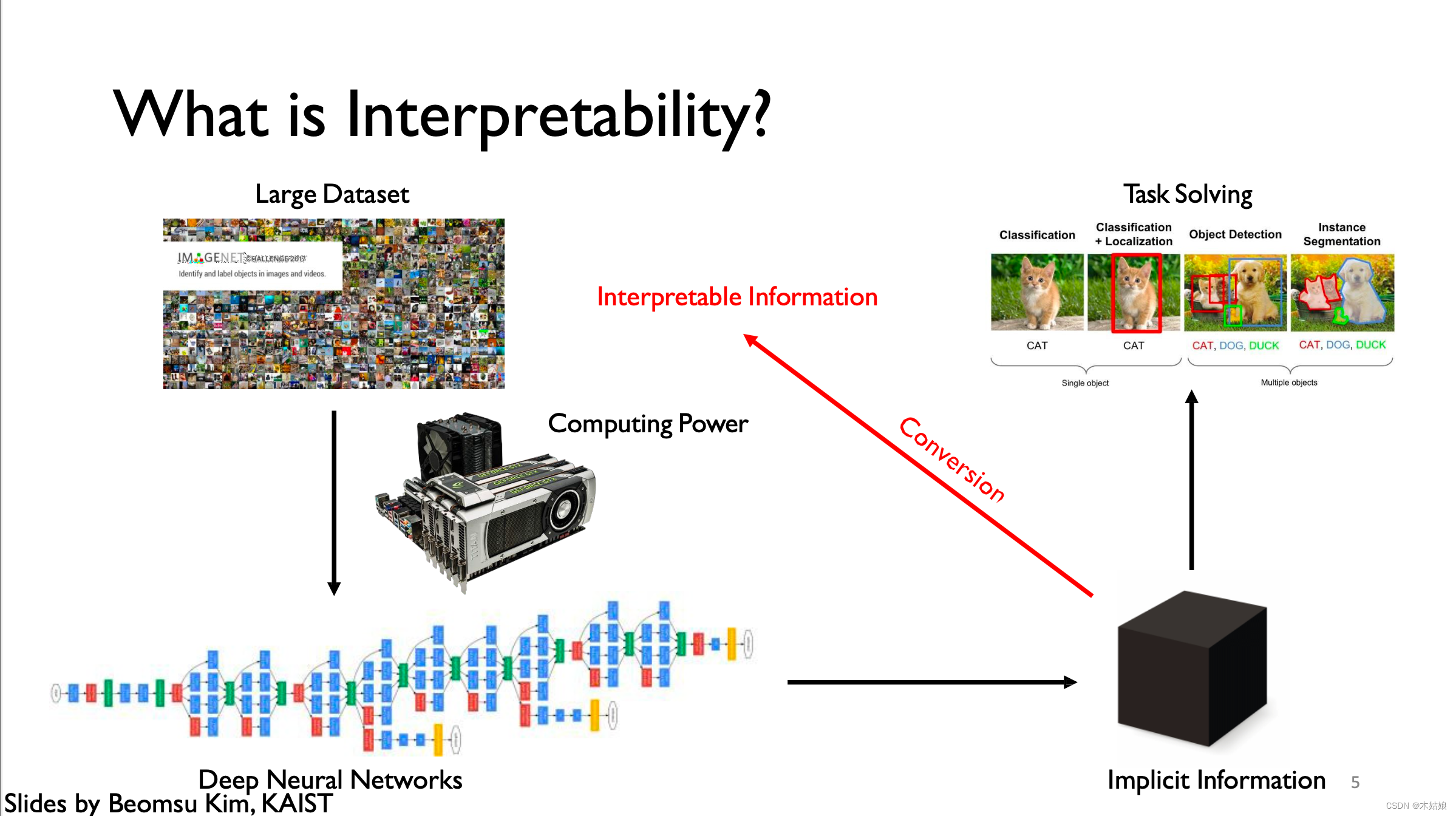
1b. Motivation: Verify model works as intended; debug classifier; make discoveries; Right to explanation
Why Interpretability?
- 1.Verify that model works as expected: Wrong decisions can be costly and dangerous
- 2. Improve / Debug classifier
- 3. Make new discoveries
- 4.Right to explanation
“Right to be given an explanation for an output of the algorithm”
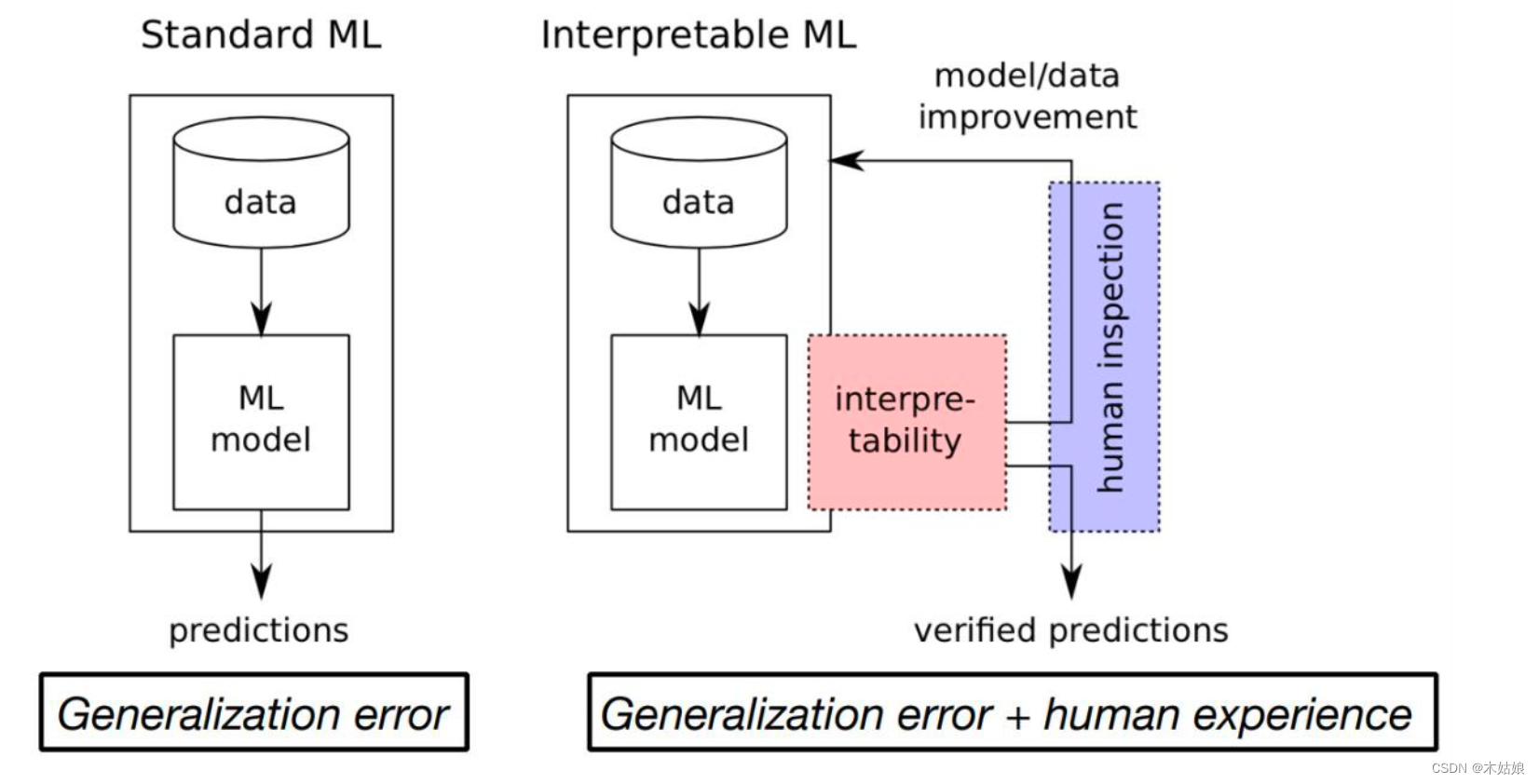
1c. Ante-hoc (train interpretable model) vs. Post-hoc (interpret complex model; degree of “locality”)
Know good writing : Explainable AI The research of
Ex post explanation VS Self explanation
There are two ways to obtain the interpretability of the model ( Interpretive classification )
- Ante-hoc & Post-hoc
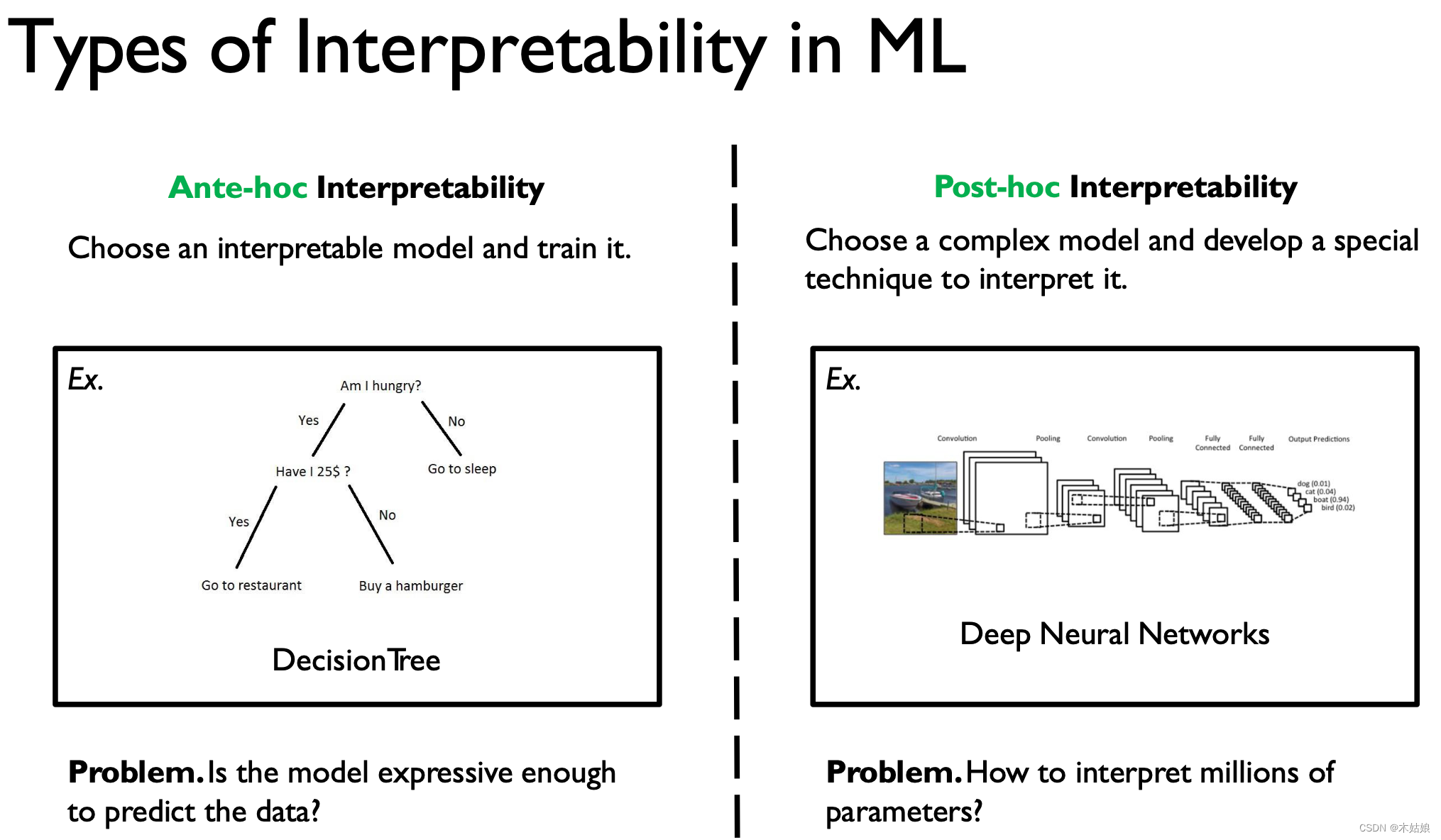
1. Ante-hoc Interpretability —— Prior interpretability ( Model built-in interpretability )
By training a self explanatory model , To get an explanation of the results .
Common interpretable models :
- Naive Bayes
- Linear regression
- Decision tree
- Rule based models
But the complexity of this kind of model is limited , As a result, its fundamental performance is limited
2. Post-hoc Interpretability—— Ex post interpretability
Refers to the black box model , By some means , Reflect his decision logic
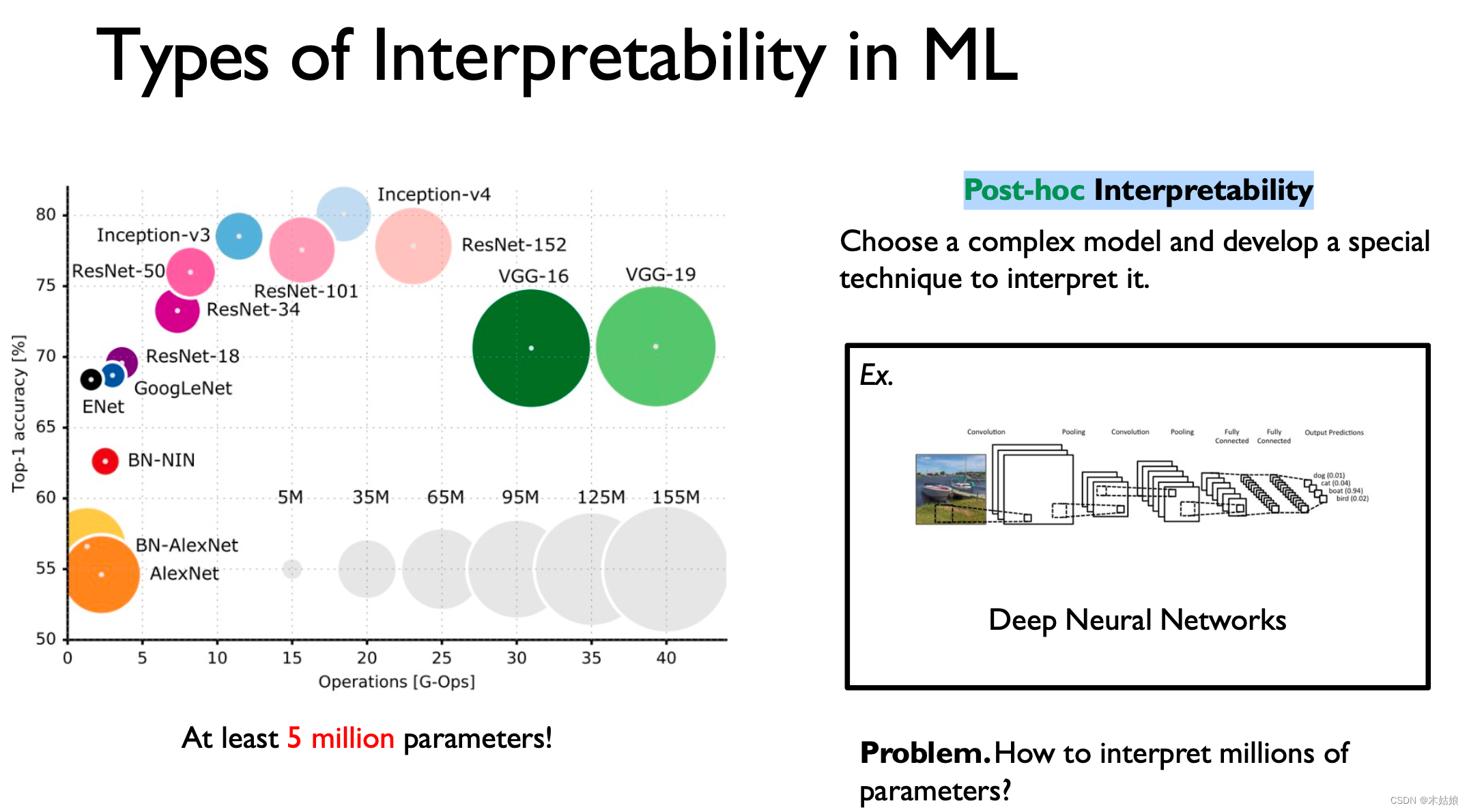
Several levels of interpretability :
- Model level explicability :DNN Why does the model decide the decision boundary so
- Interpretability of features : Which features can maximize the activation of the current model
- Towards individual explicability : Explain why this input is so classified

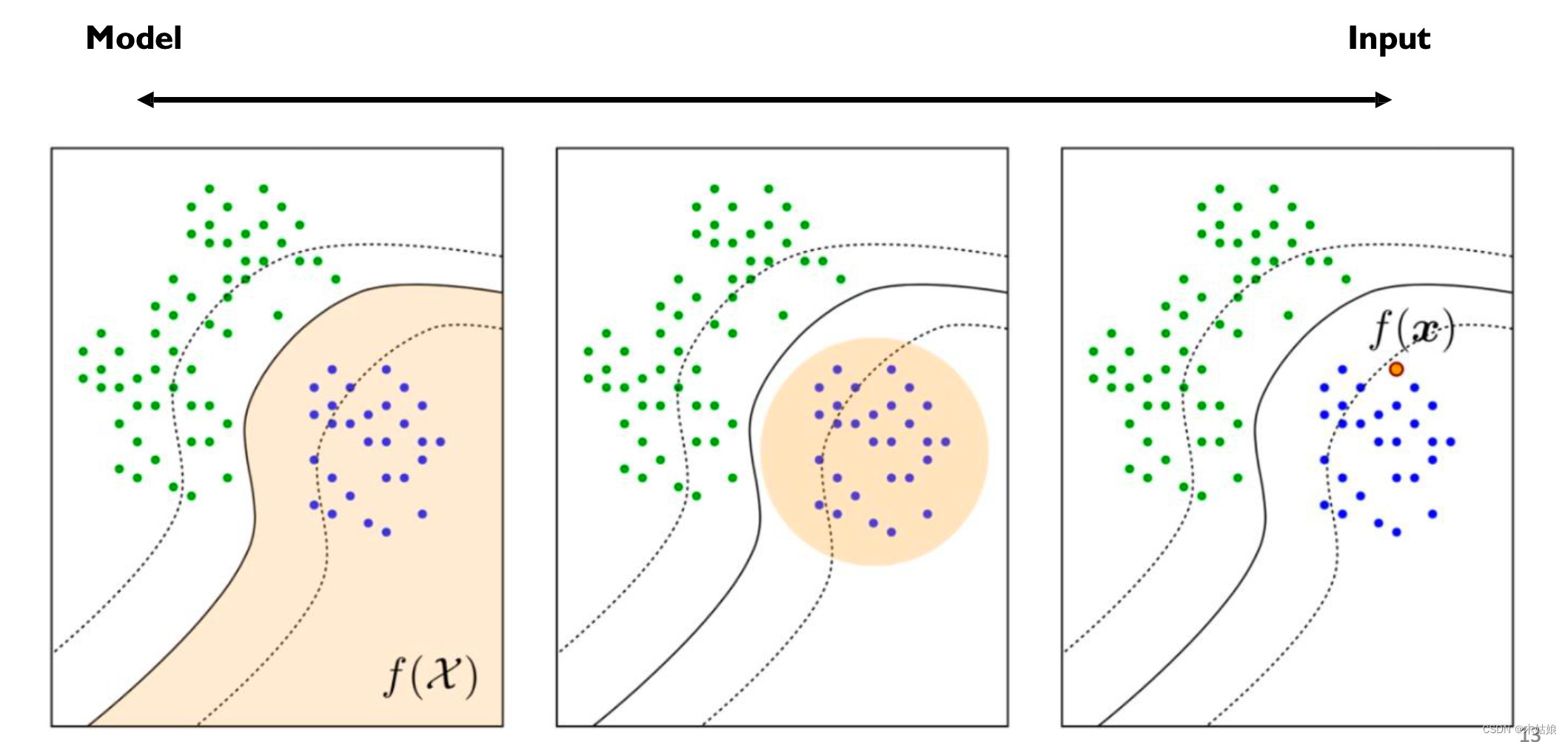
2. Interpreting Deep Neural Networks
2a. Interpreting Models (macroscopic, understand internals) vs. decisions (microscopic, practical applications)
( Course trend ) Several classifications of model interpretability
- Interpreting decisions:
- Attribution method: What attributes determine the current output of the model
- Example-based: What special case leads to the current output of the model
- Interpreting models:
- Representation analysis: The model represents itself
- Data generation: How to use models to generate data
- Example-based: Related cases
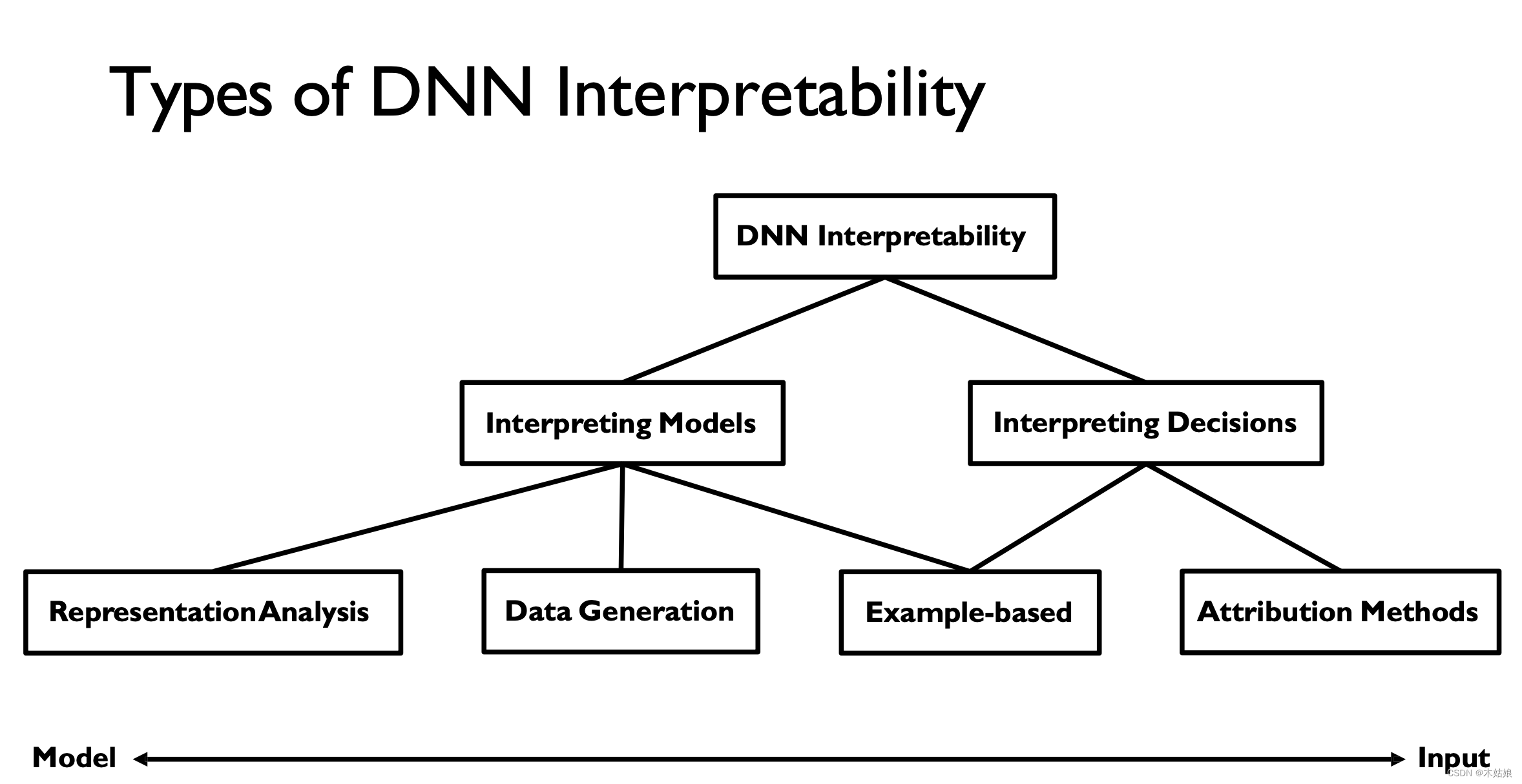
DNN interpretability It can be divided into macro and micro levels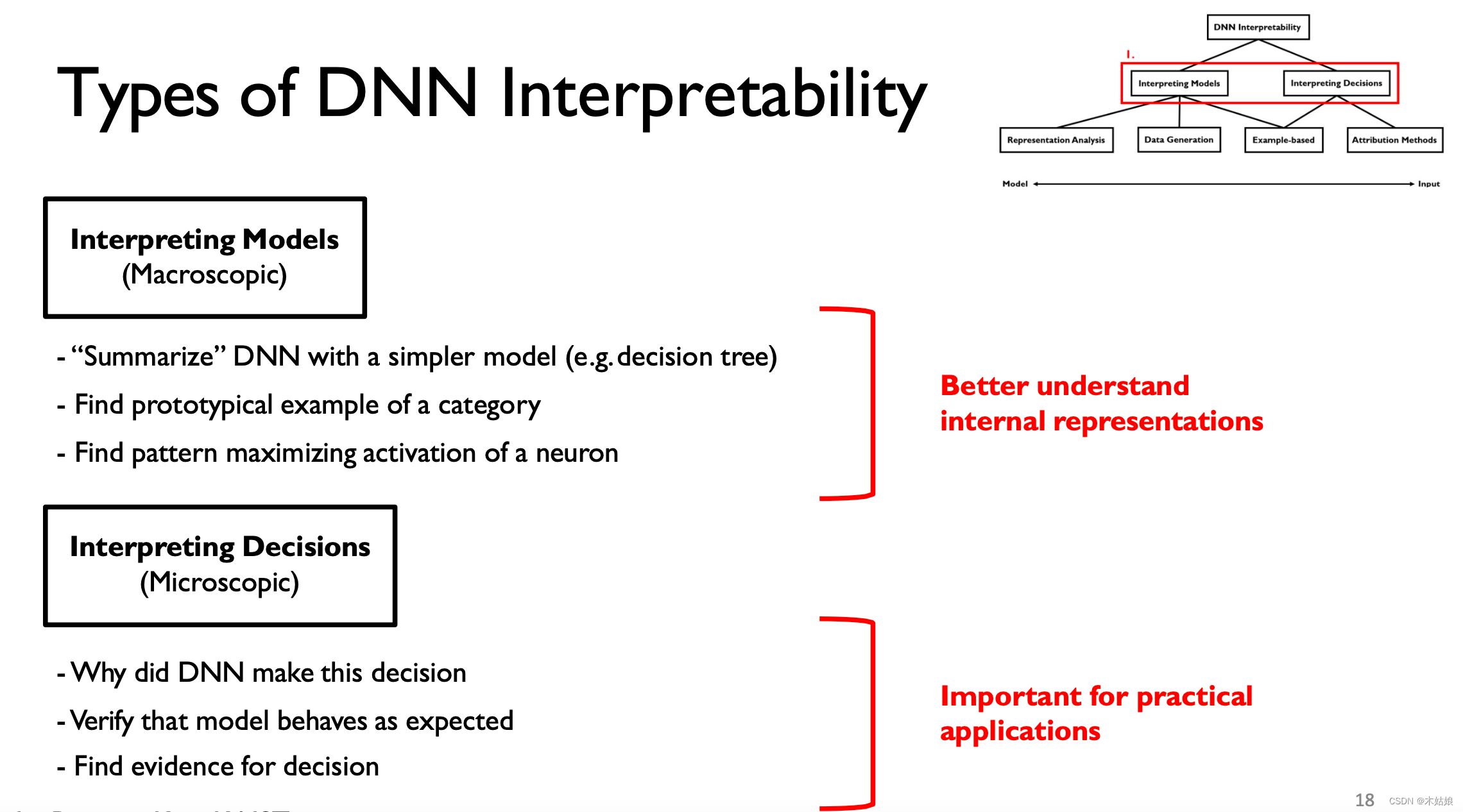
Interpreting models It can be divided into the following four aspects , among The analysis of representation can be divided into weight visualization and proxy model
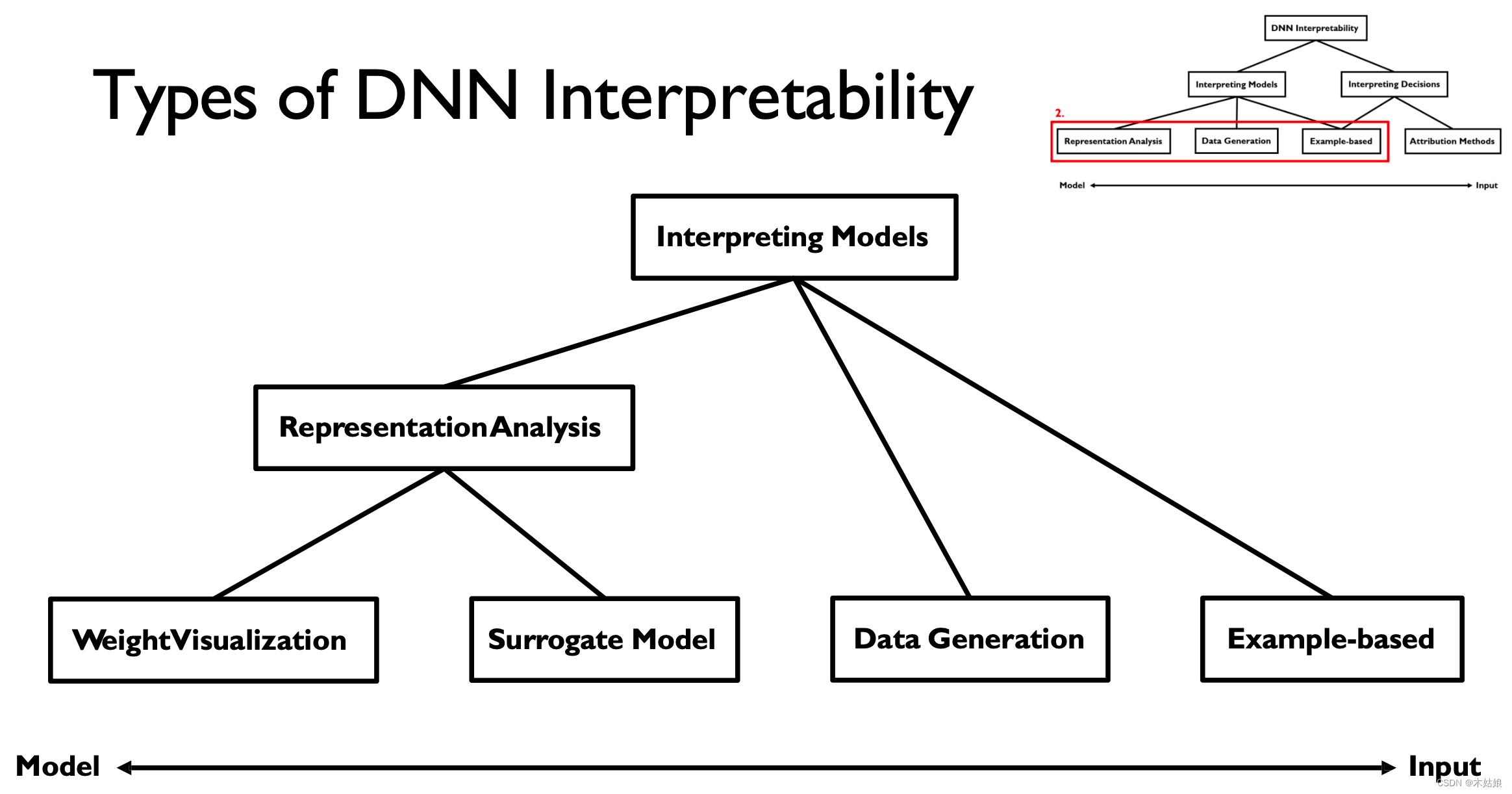
2b. Interpreting Models: Weight visualization, Surrogate model, Activation maximization, Example-based
1. Weight visualization Weight Visualization
Yes CNN Each layer of filter is visualized , To understand what the model is learning at the current level 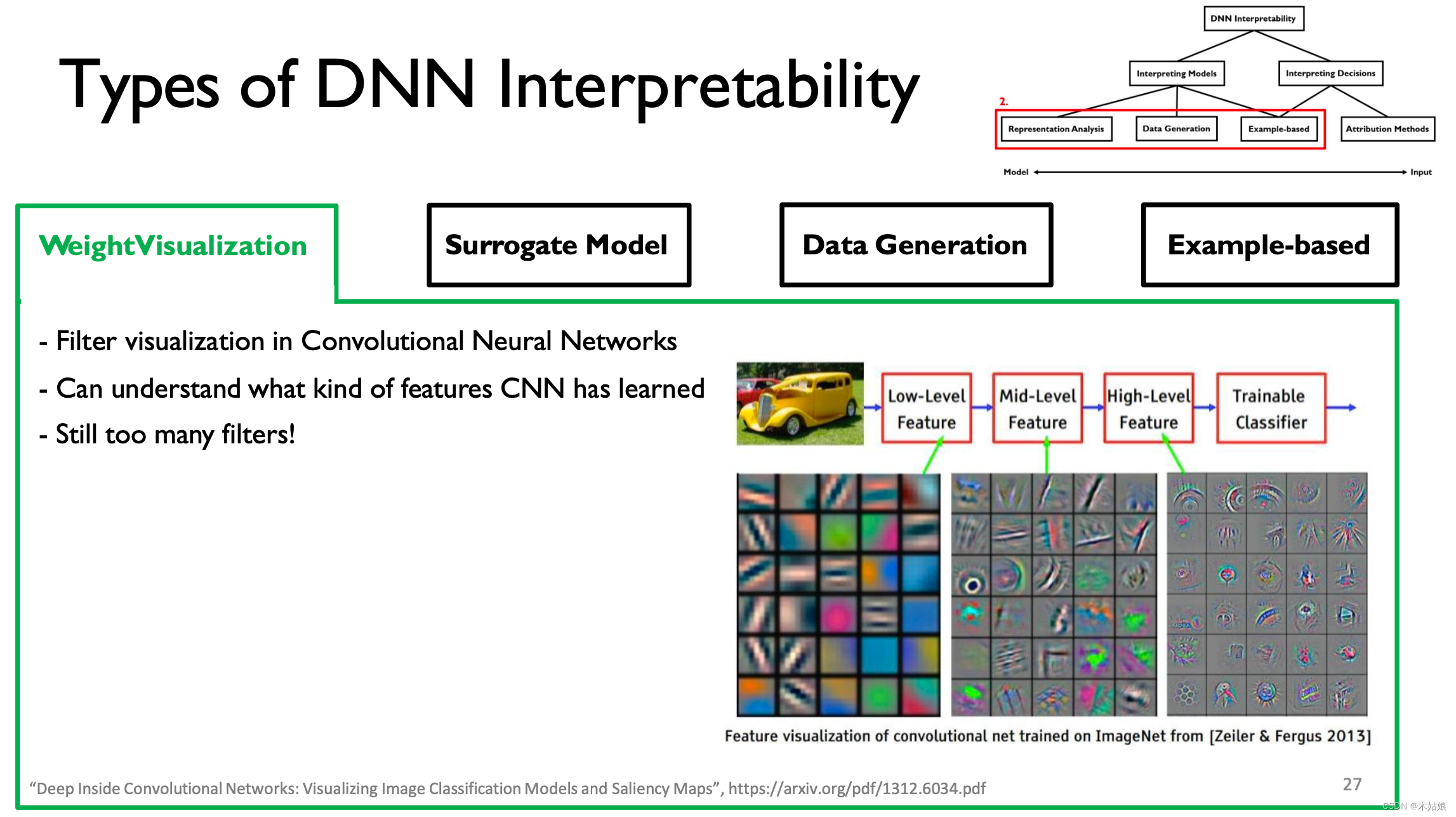
2. Surrogate model Agent model
Use a simple ,“ Explicable ” Model to “summarize” Model Output , Try to explain “black box” Output .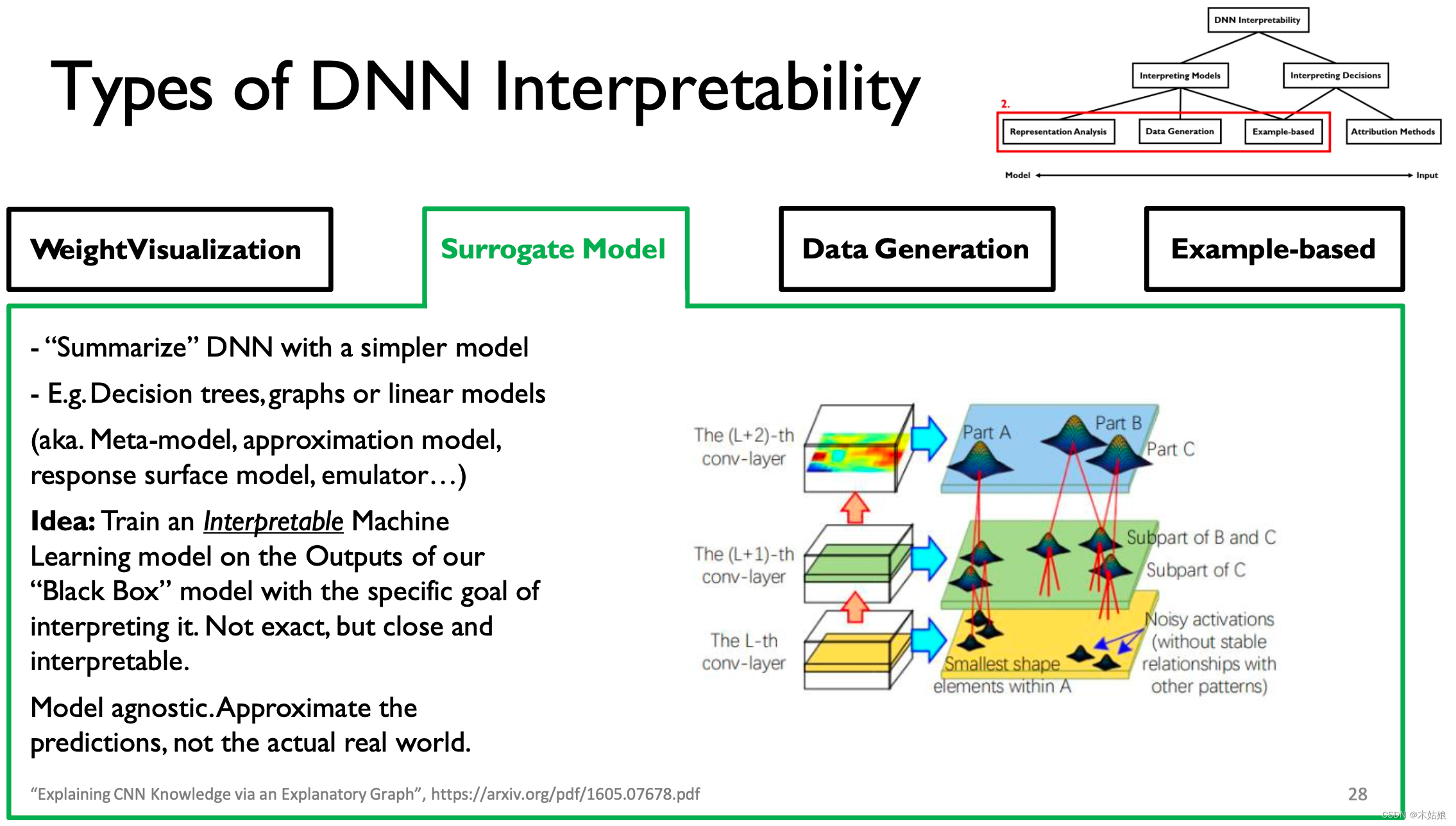
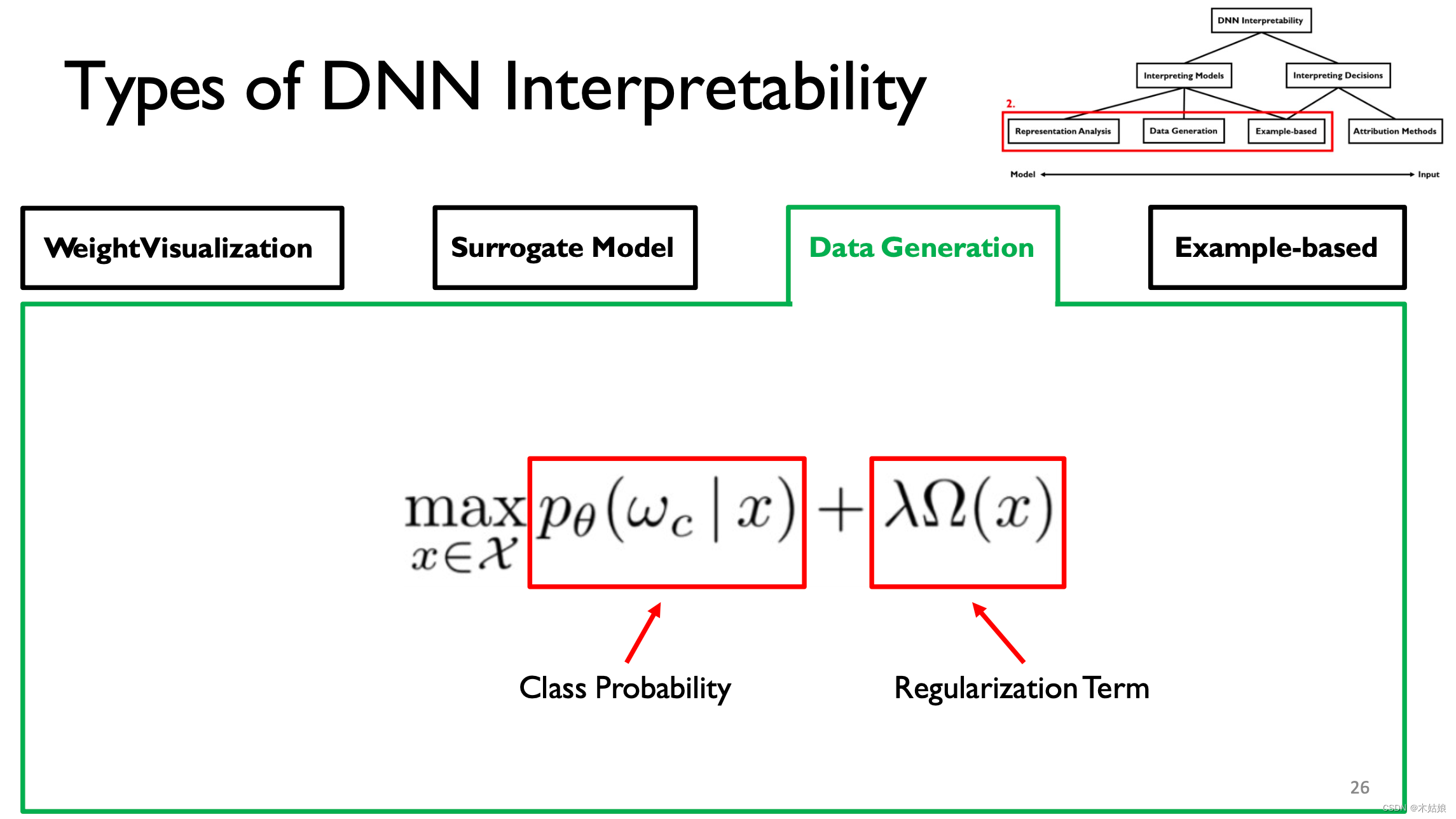
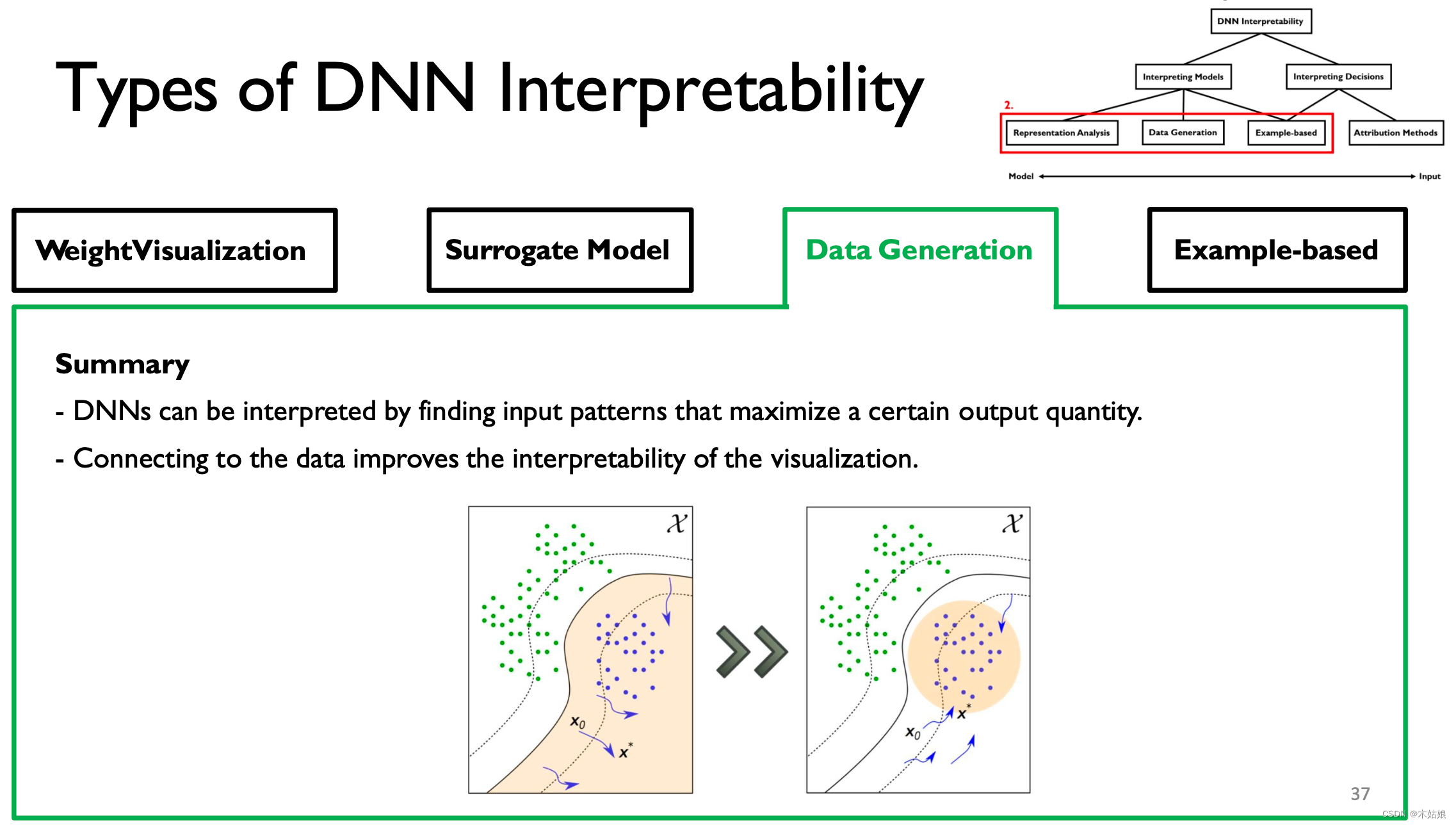
3. Data Generation / Activation maximization The data generated / Activate maximize
Activate maximize : Find the way to maximize the activation of neurons , Find the input X, Maximize the probability of the model under the current category 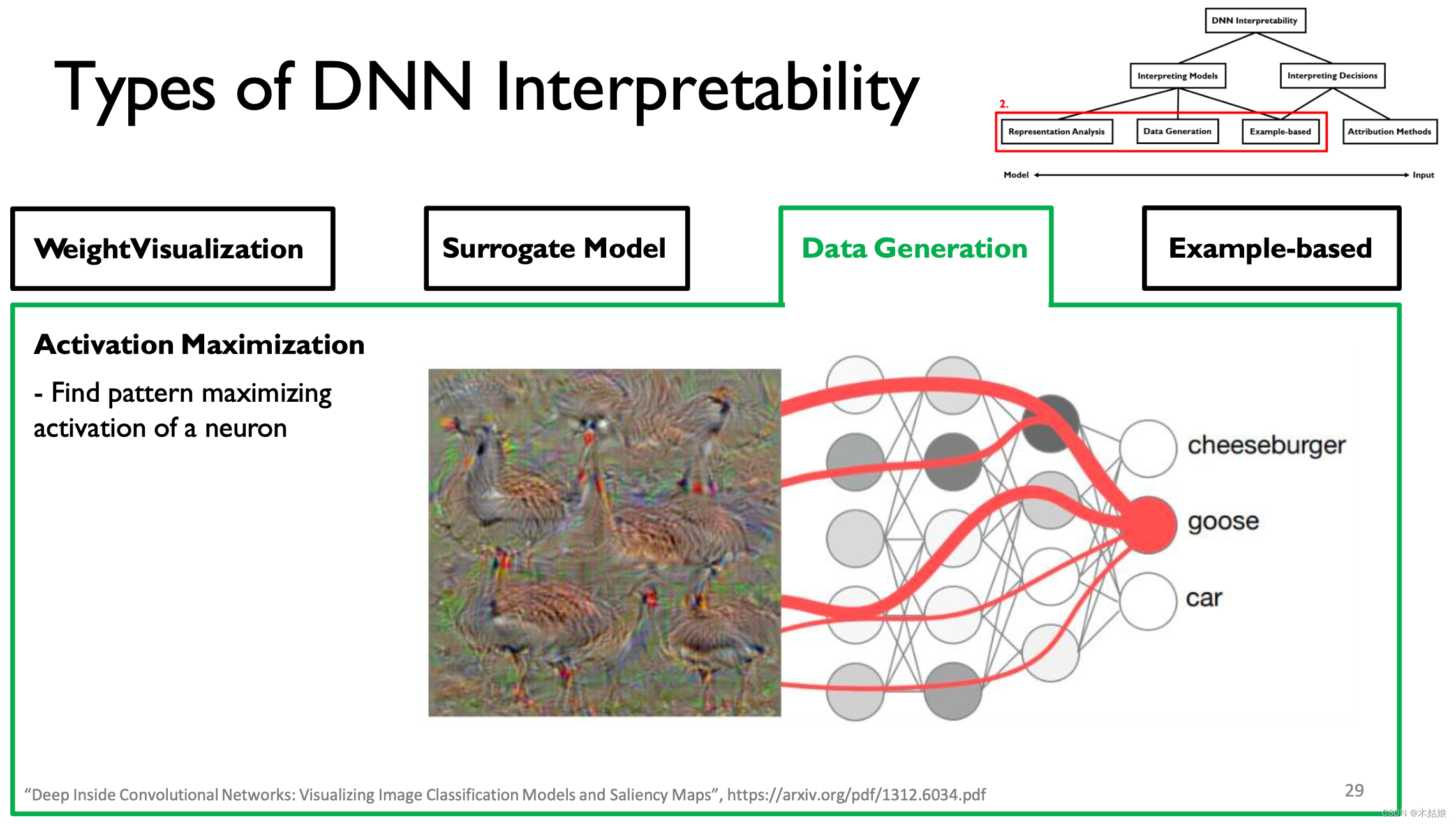
Convolution and deconvolution of the model 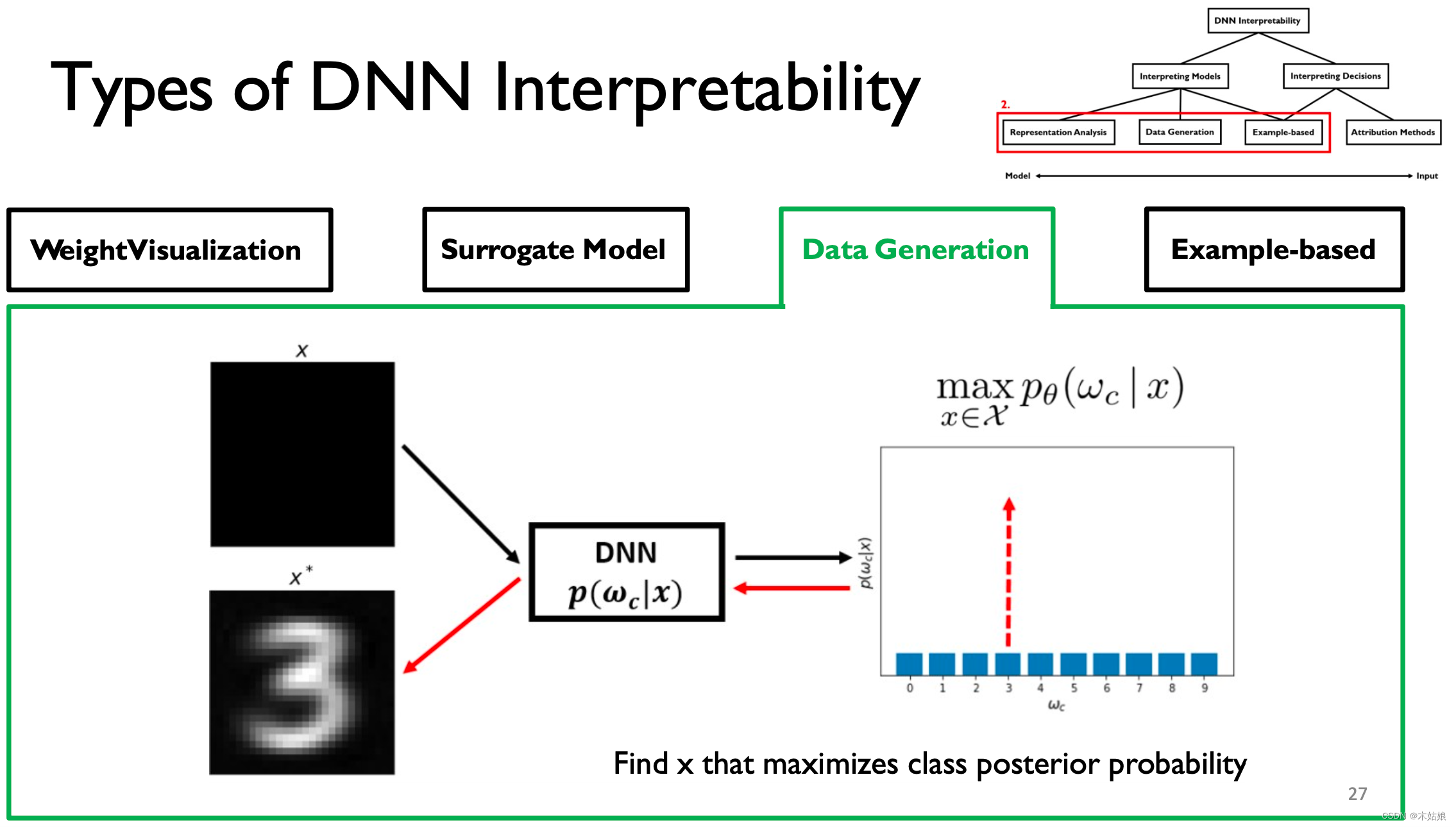
The initial input is chaotic , With the increase of training layers , Gradually, we can distinguish the characteristics between numbers 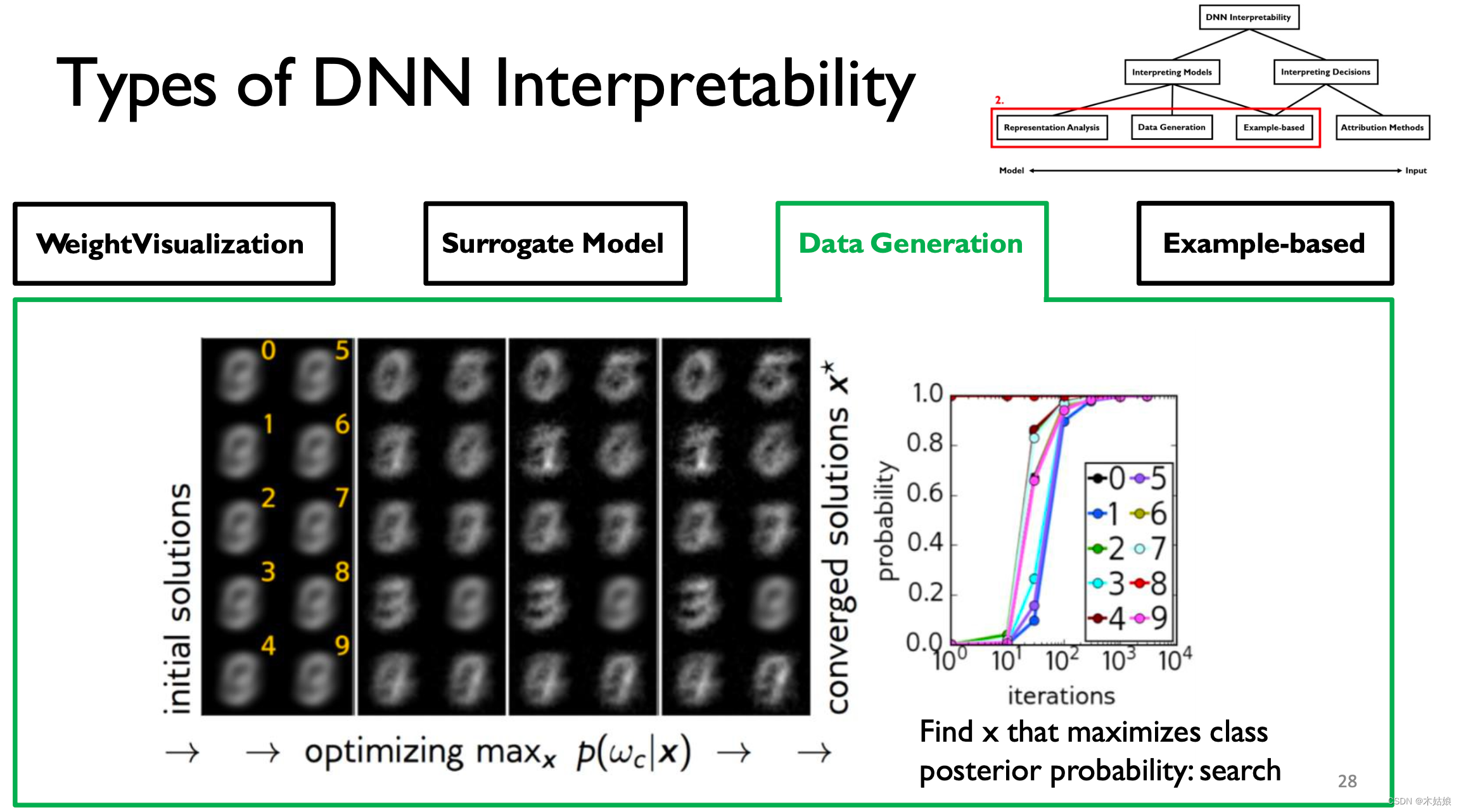
advantage : The advantages and disadvantages of this approach 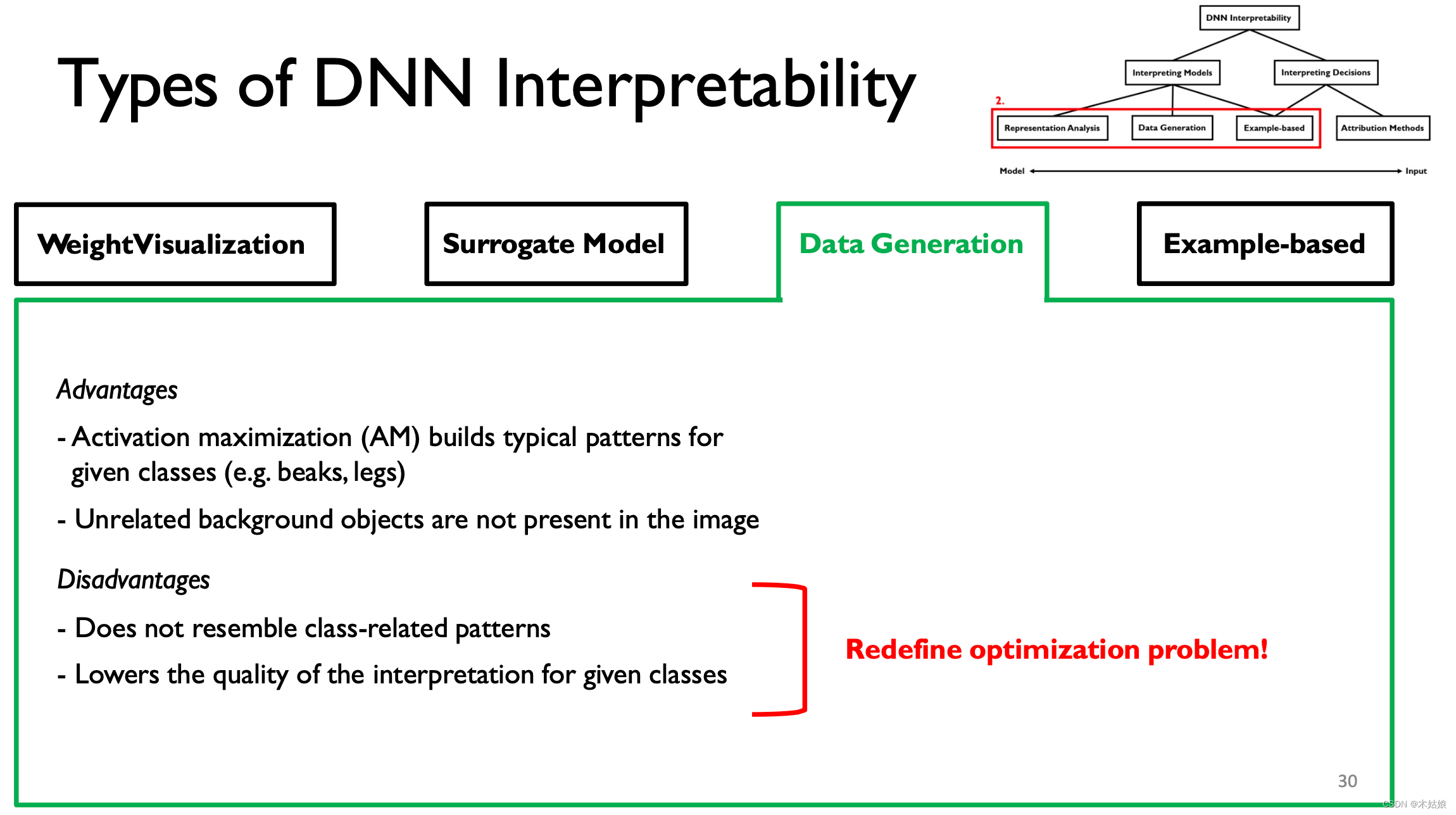
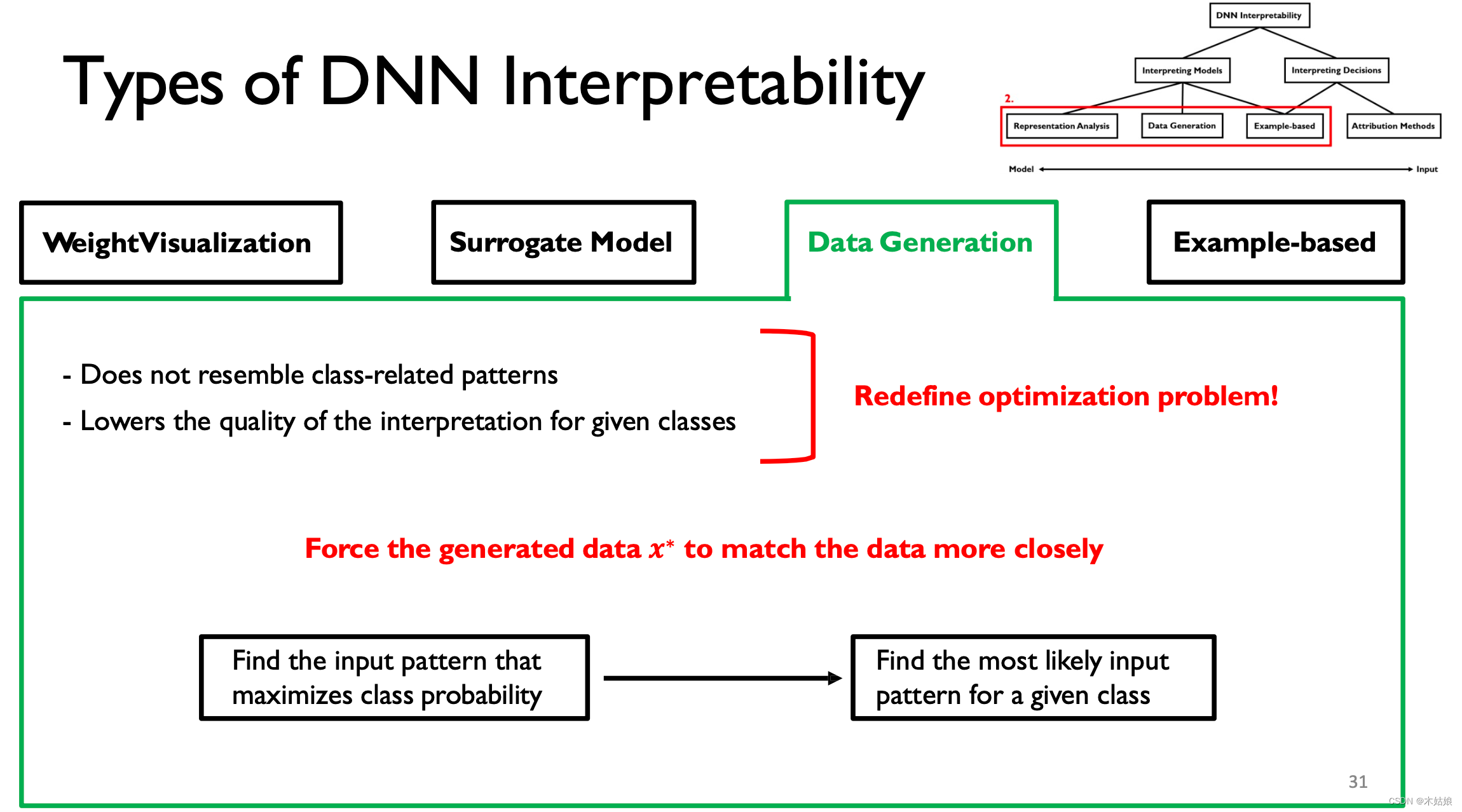
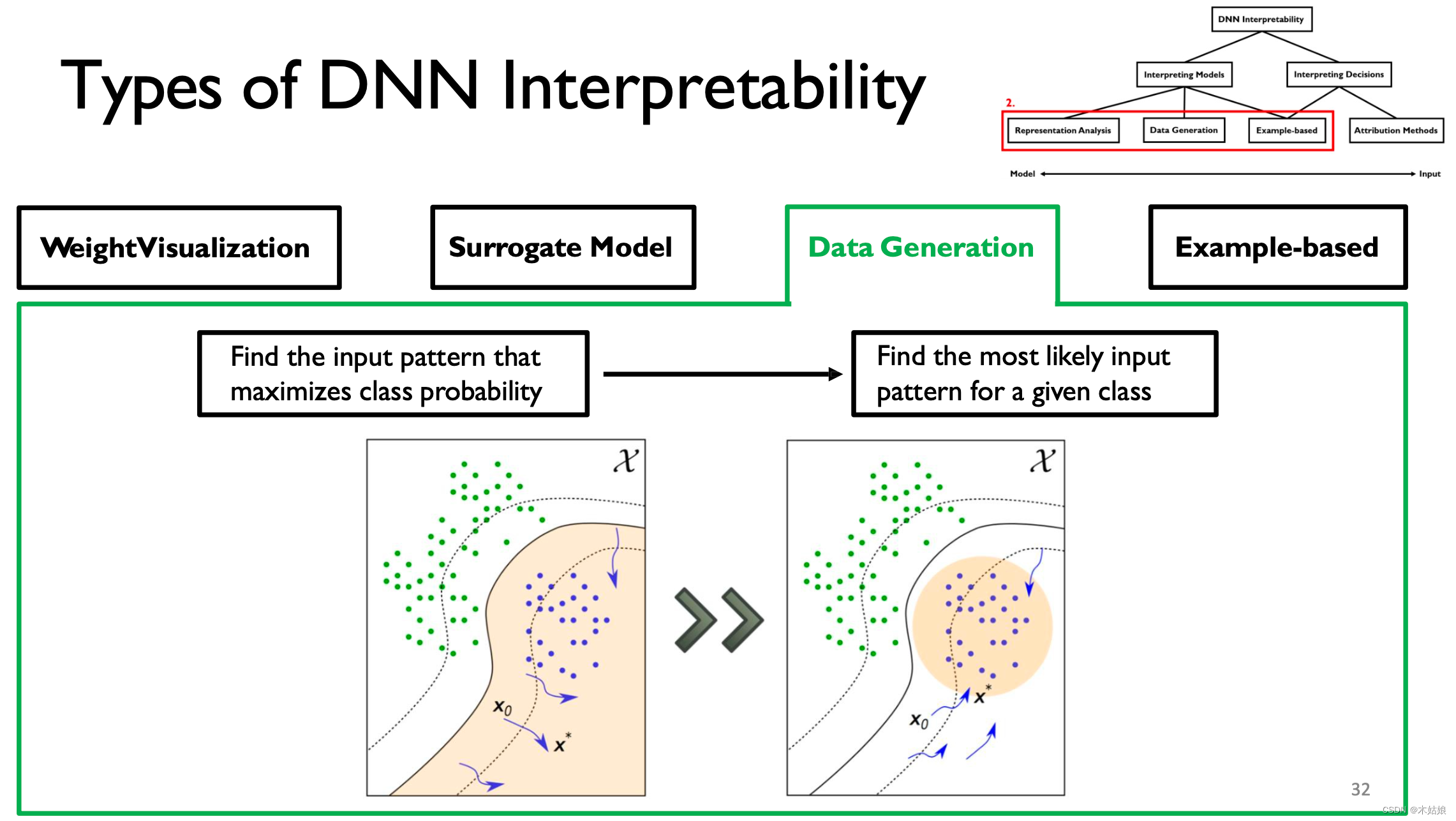
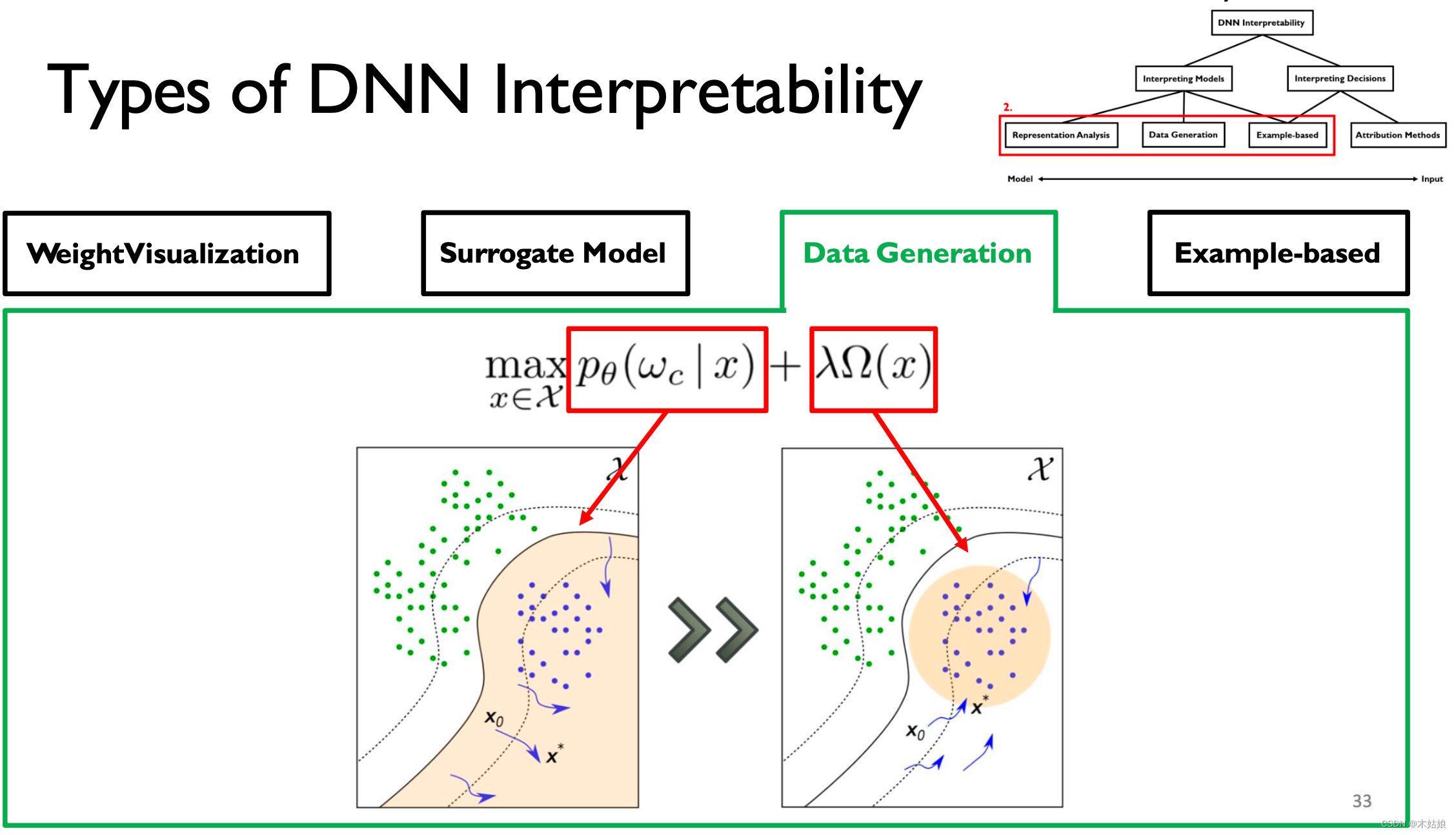
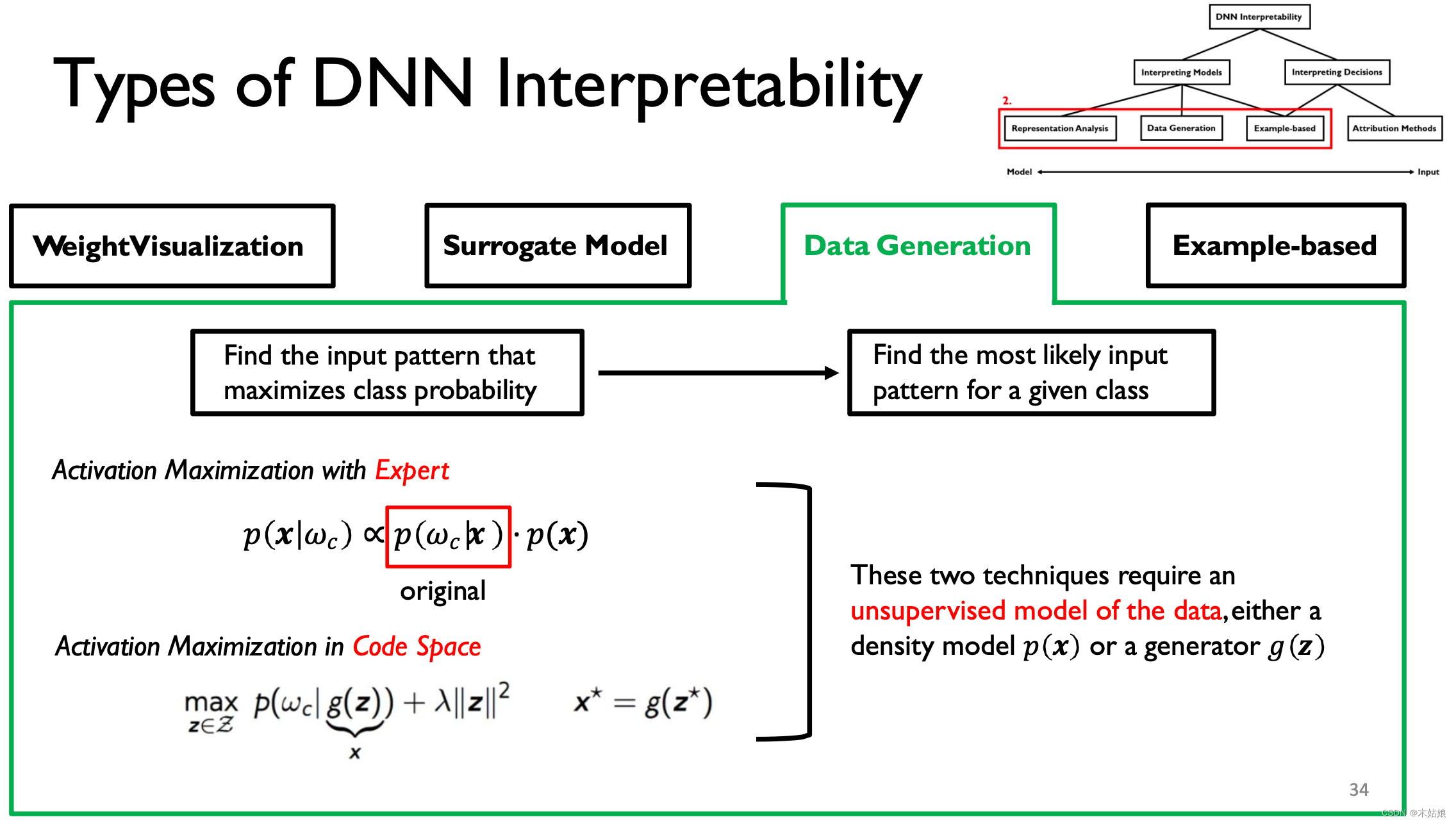
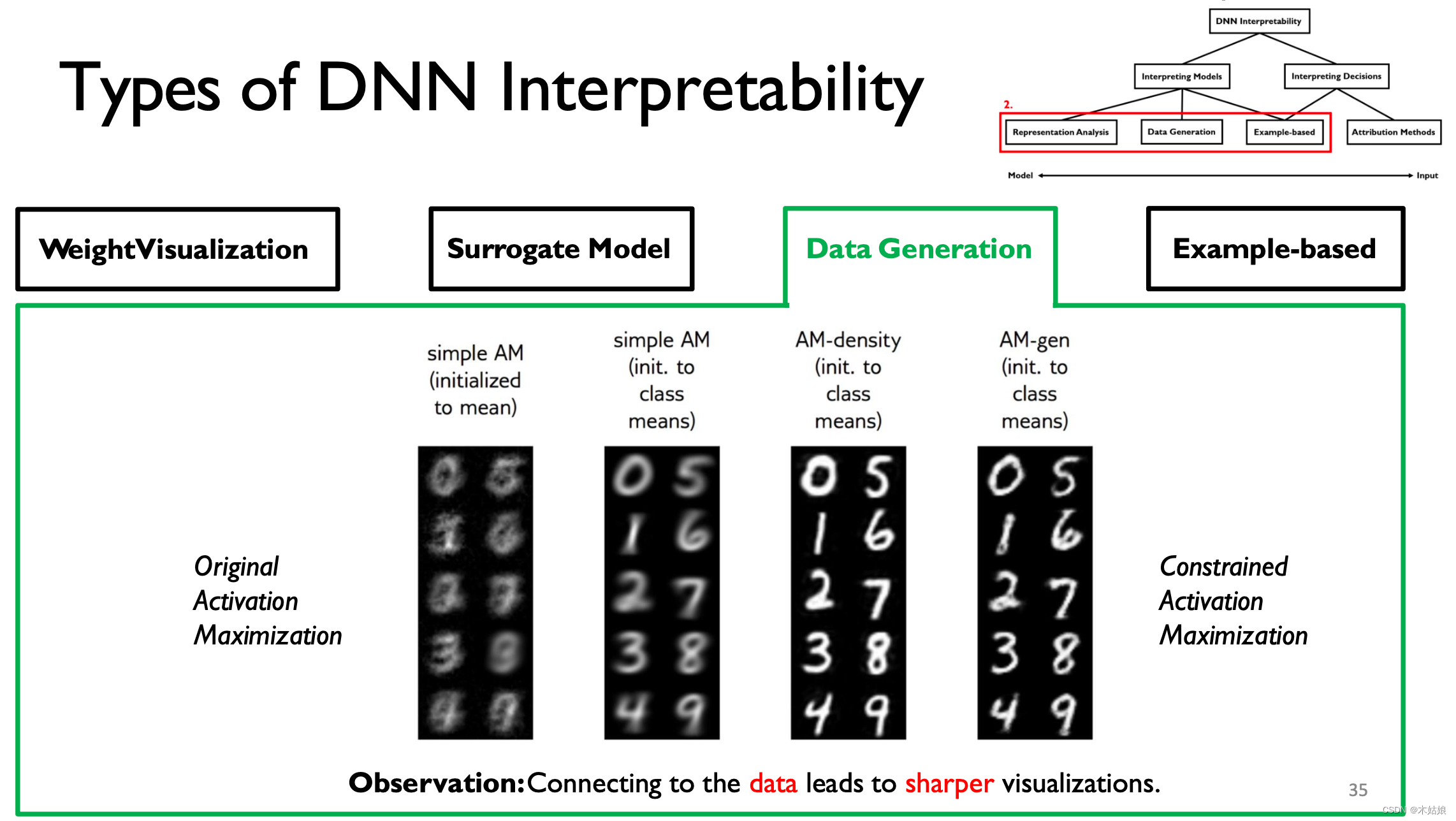
- DNN It can be explained by looking for the input mode that maximizes the output .
- Connecting with data can improve the interpretability of visualization .
4. Example-based
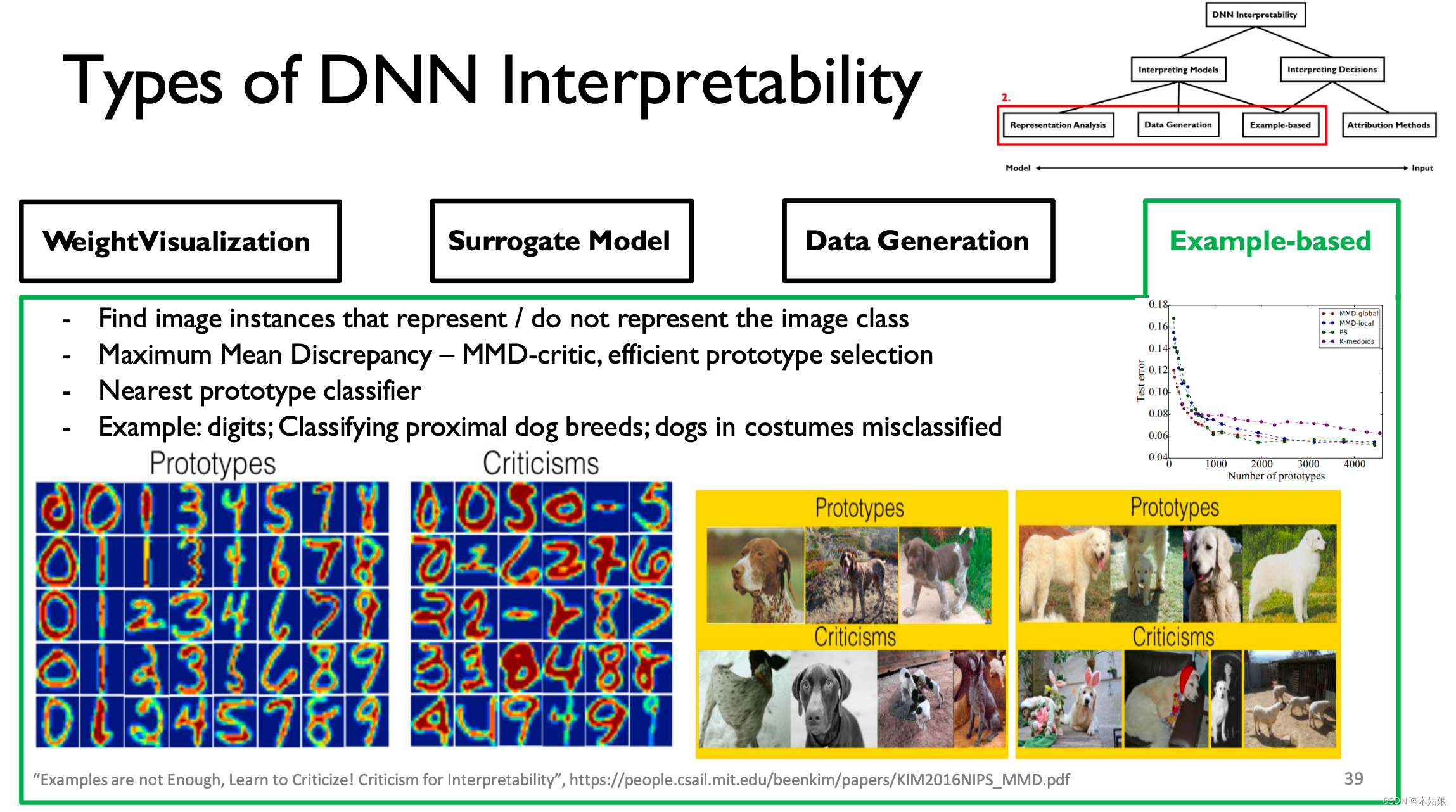
Summary :
- By visualizing the weight of each layer
- Replace models with low accuracy but strong interpretability
- To some extent, we can obtain useful features by maximizing the activation function / Information
- Through effective construction prototype and criticism, Guide model learning to obtain the most useful , Information for distinguishing
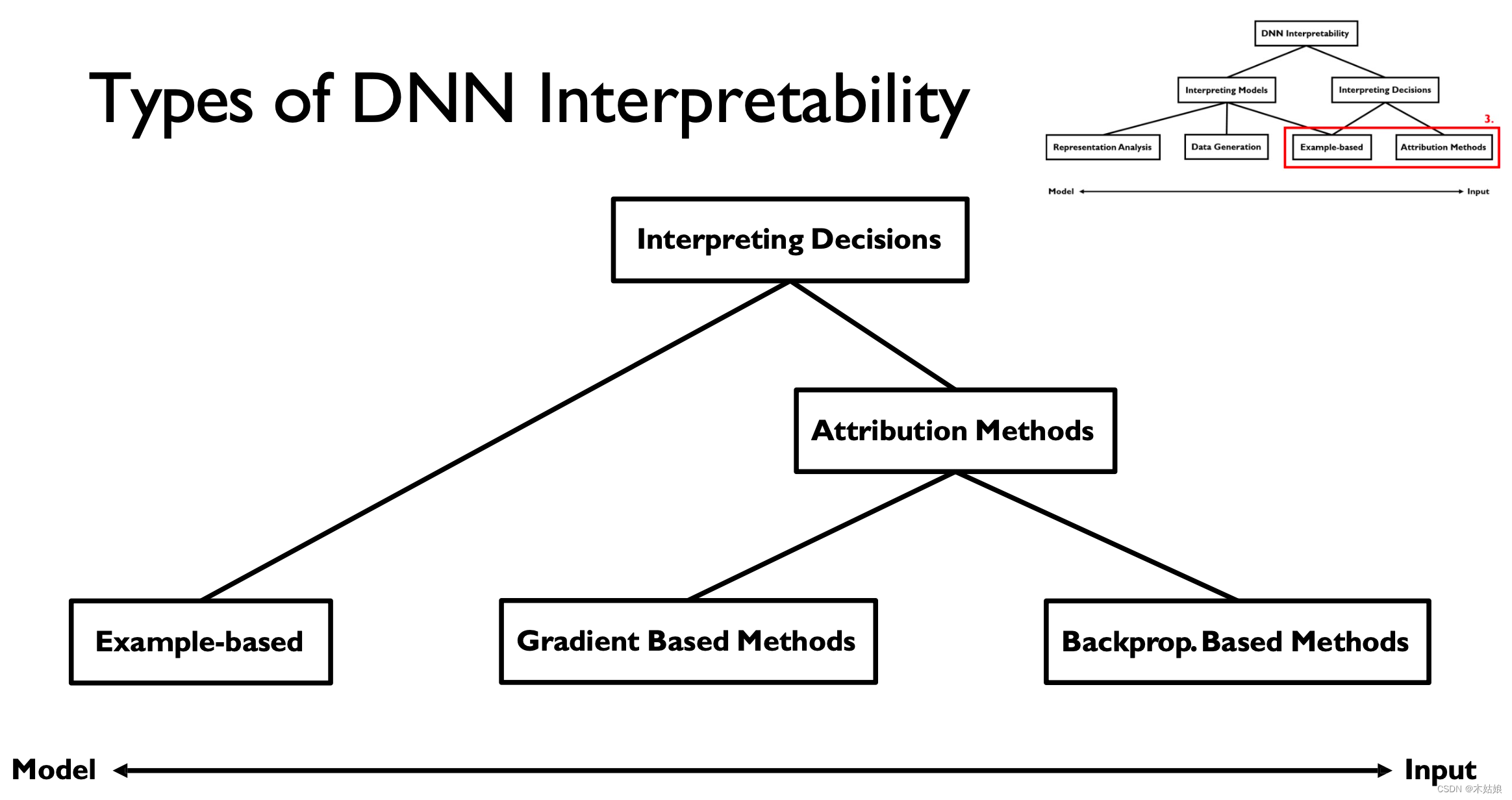
2c. Interpreting Decisions:

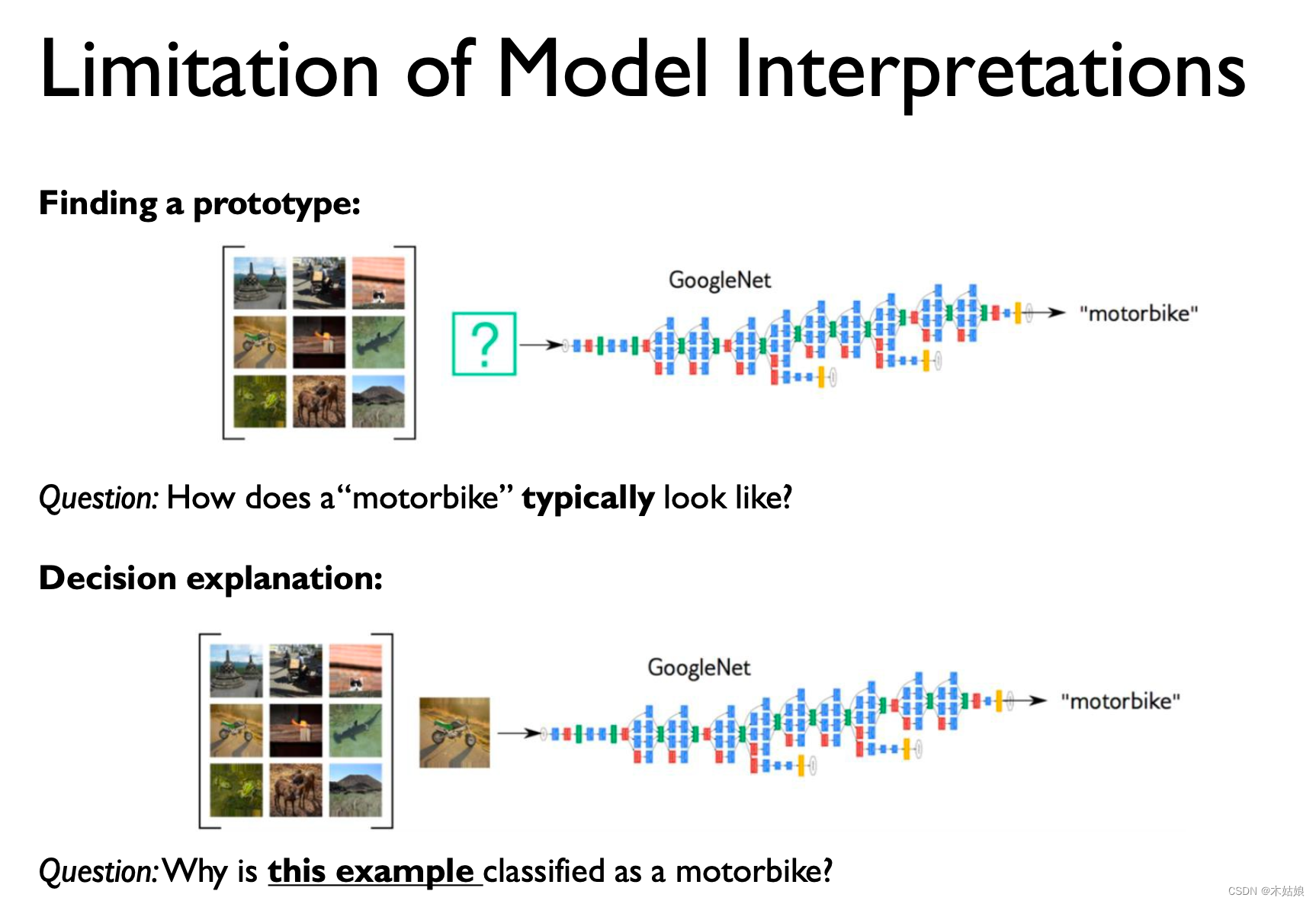
Example-based
The input training samples have a decisive impact on the results of the model 
Attribution Methods: why are gradients noisy?
Give each pixel a causal score , That is, how much the current pixel contributes to the model to this result .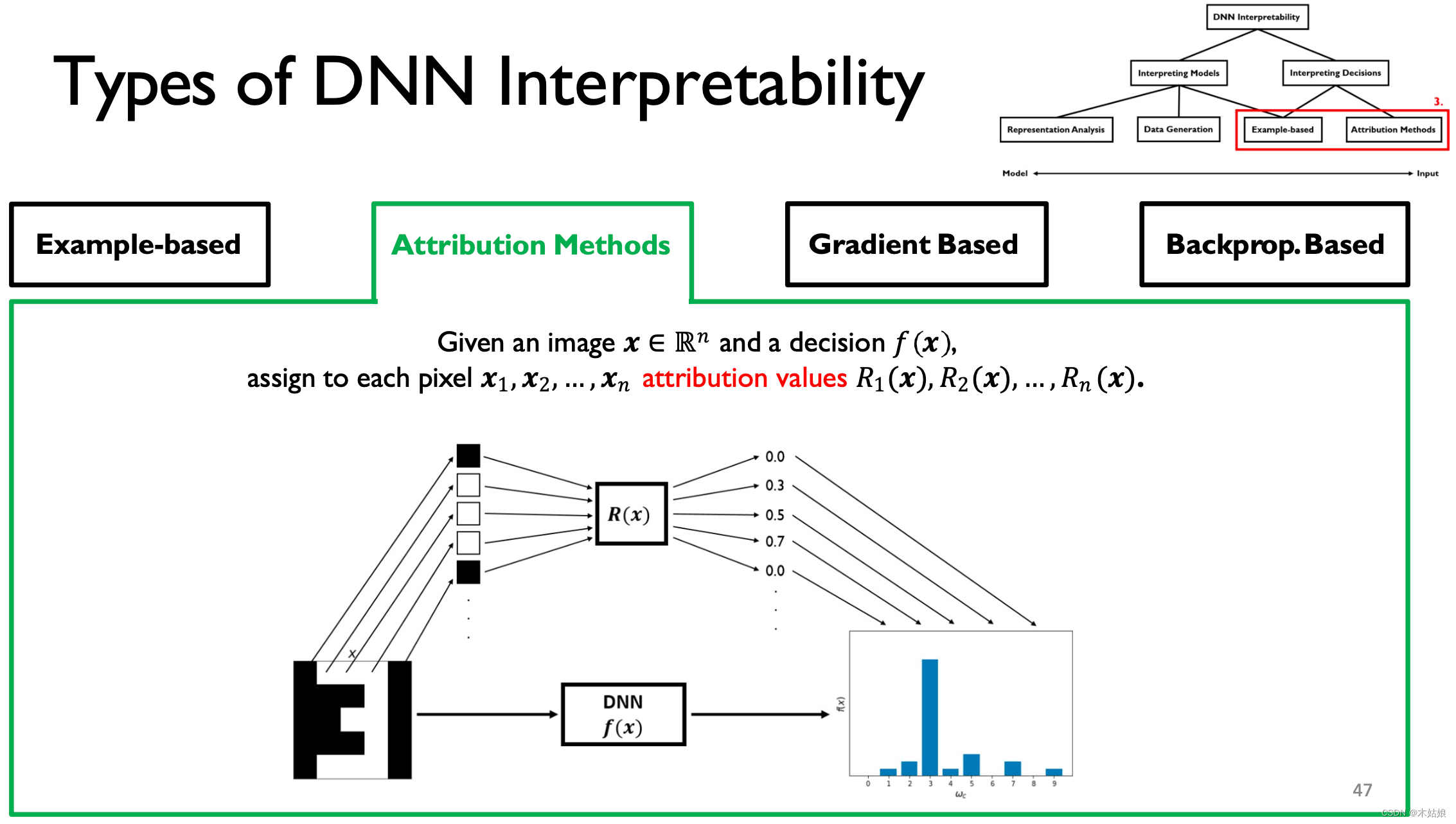
The result of visualizing attribution 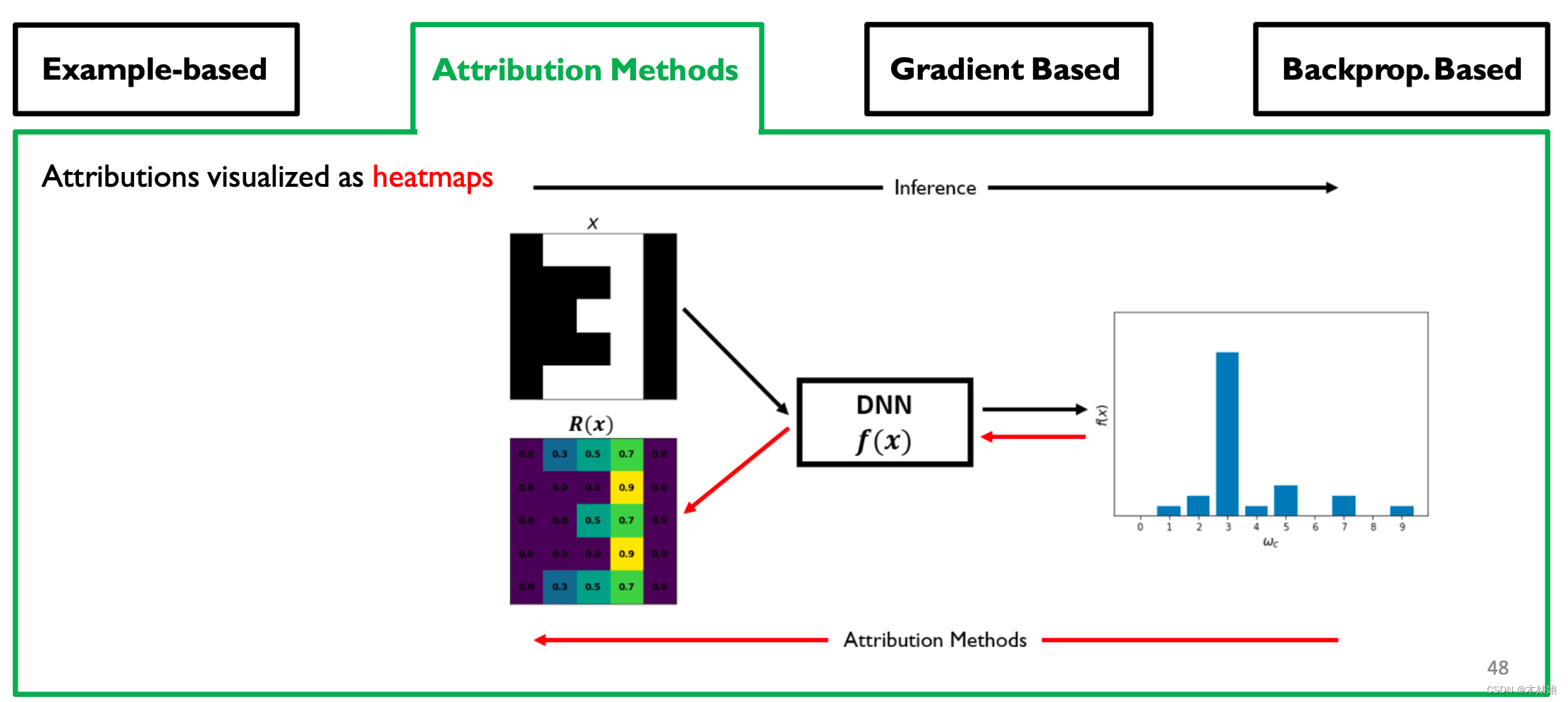
The key is , structure ( features ) Saliency map (Saliency Map)
promote saliency map Methods , First : Change of thinking 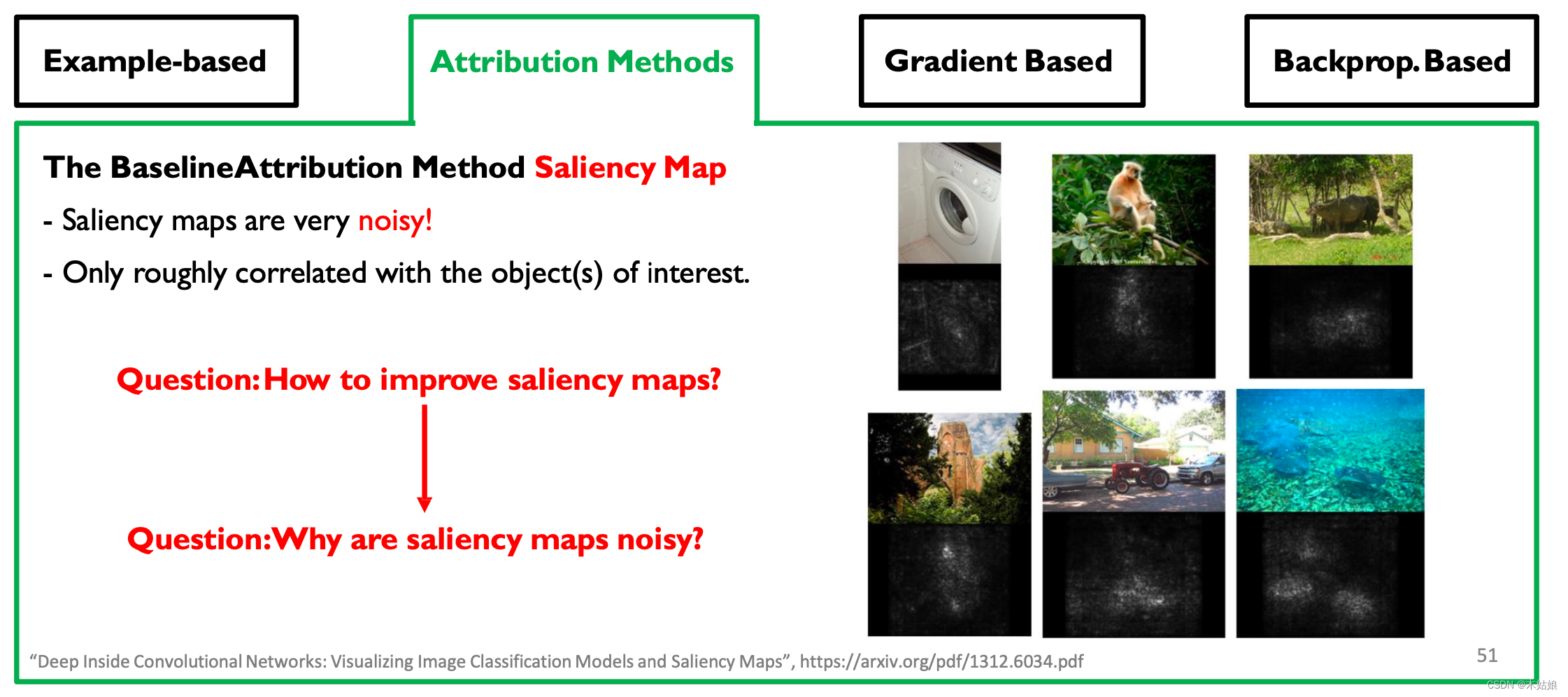
hypothesis 1: saliency map Is real
- Some pixels randomly distributed in the image are crucial to how the network makes decisions .
- Noise is very important

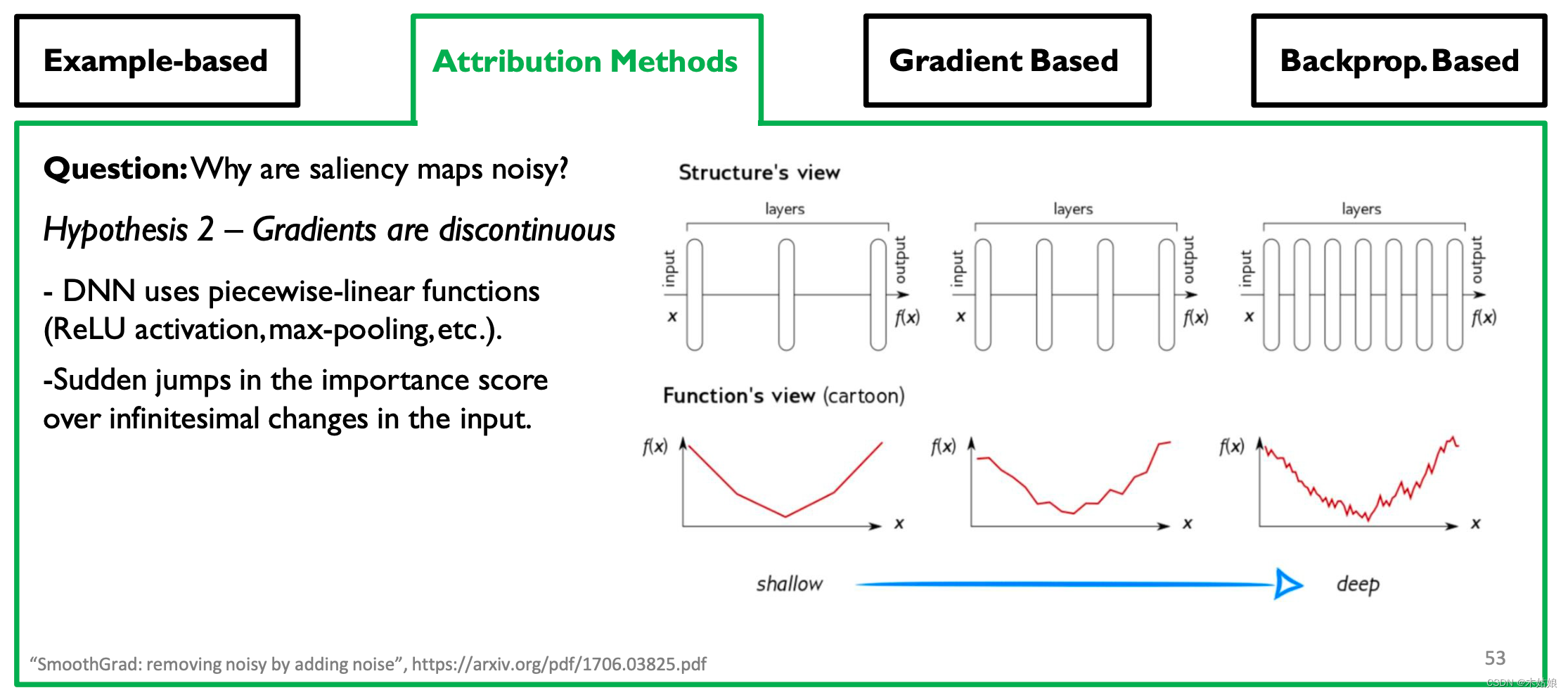
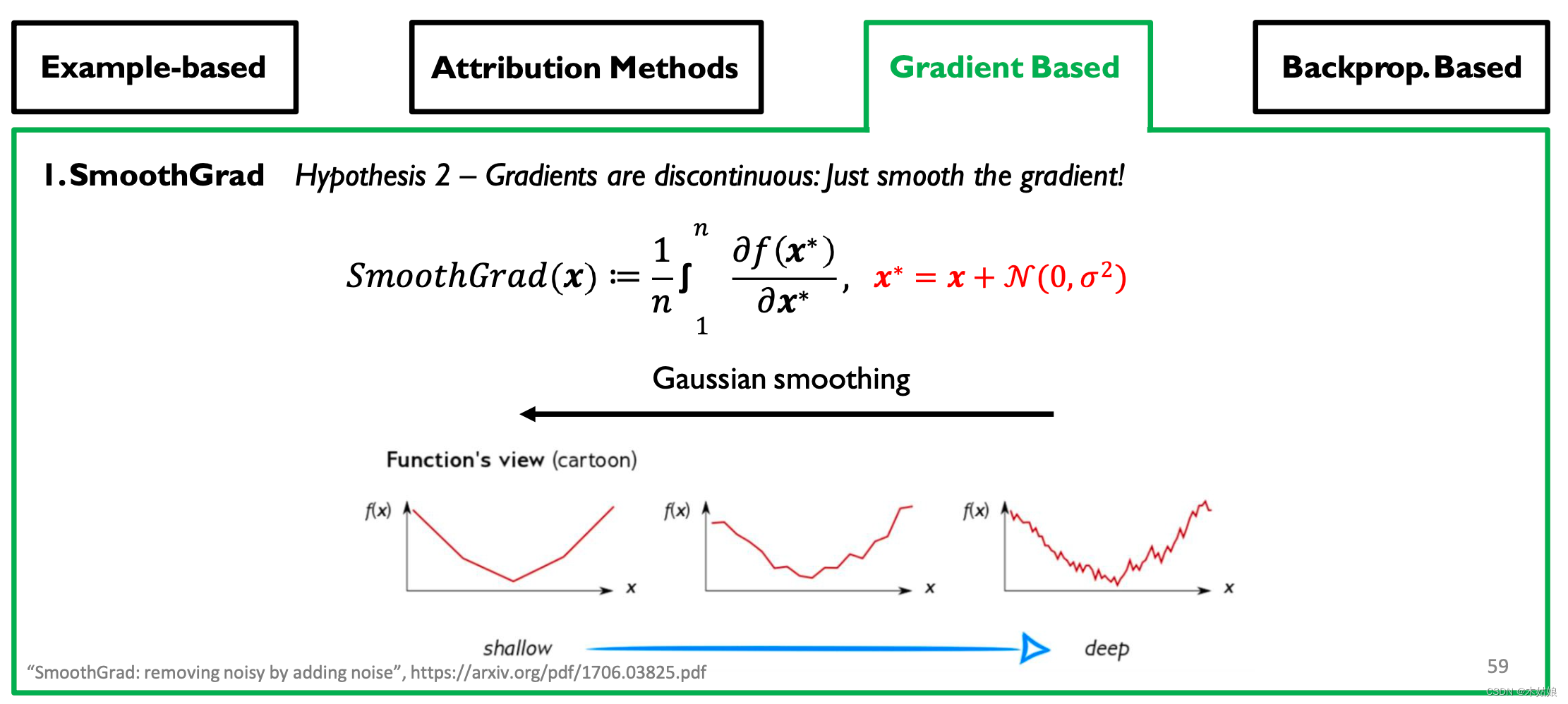
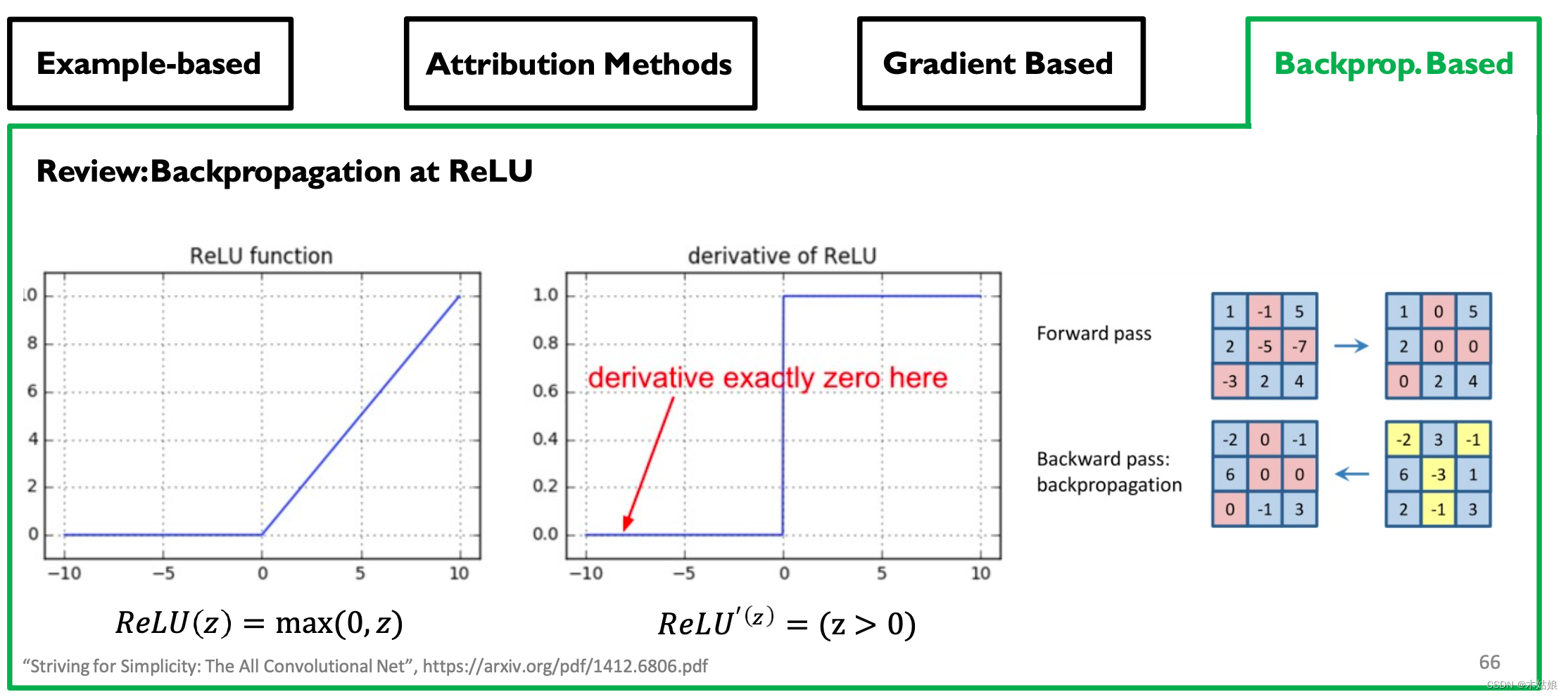
hypothesis 2: The gradient is discontinuous - DNN Use piecewise linear functions (ReLU Activate ,max-pooling etc. ).
- The mutation jump of importance score on the infinitesimal change of input .
hypothesis 3: - A feature may have a strong impact on a global scale , But it will have a small impact locally
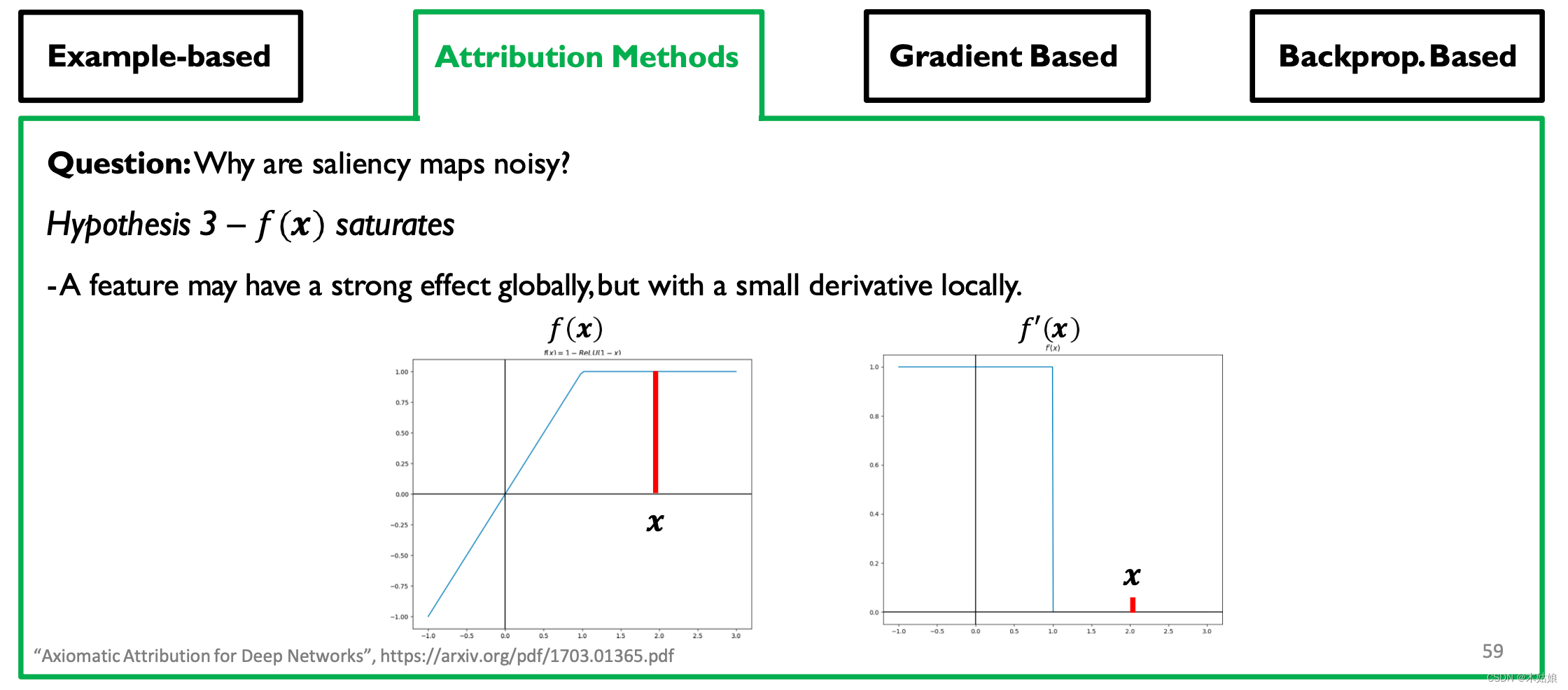
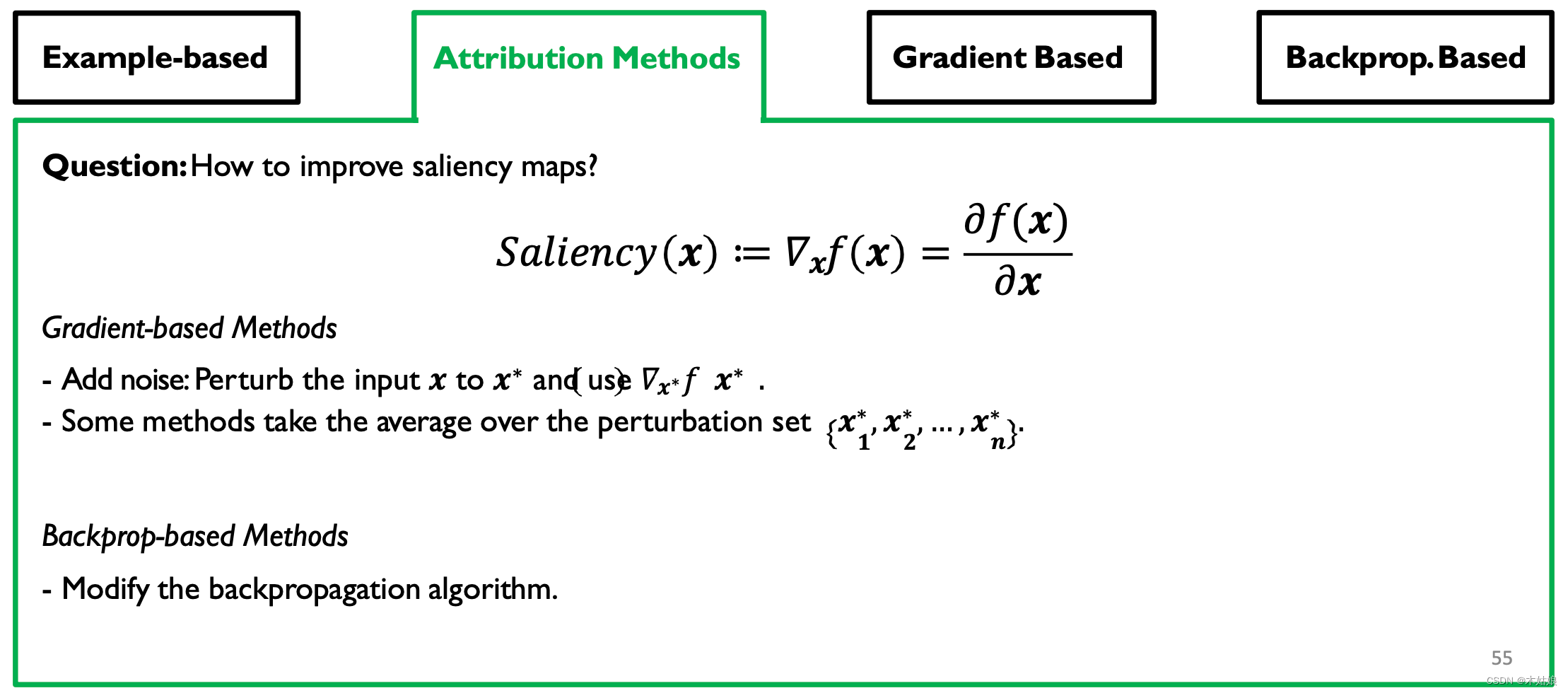

Other attribution methods
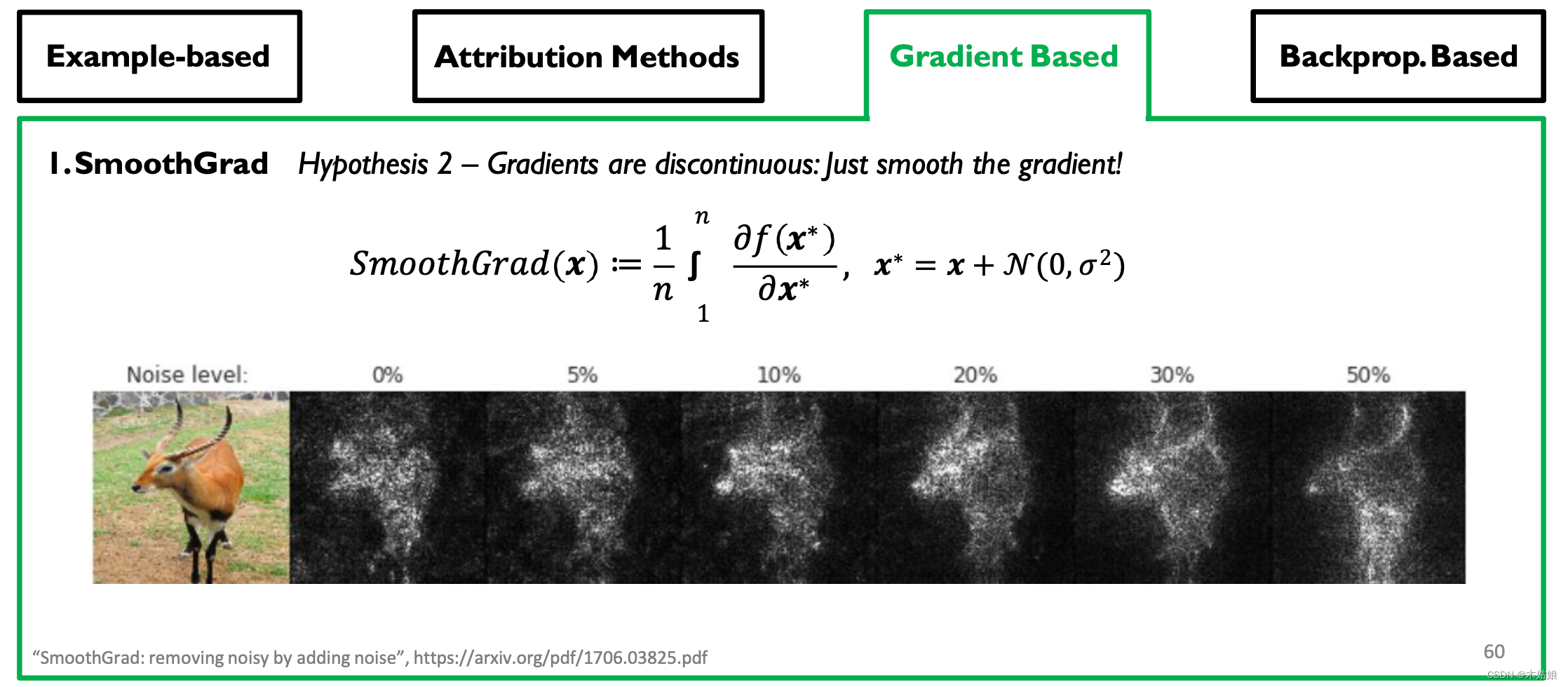
Gradient-based Attribution: SmoothGrad, Interior Gradient
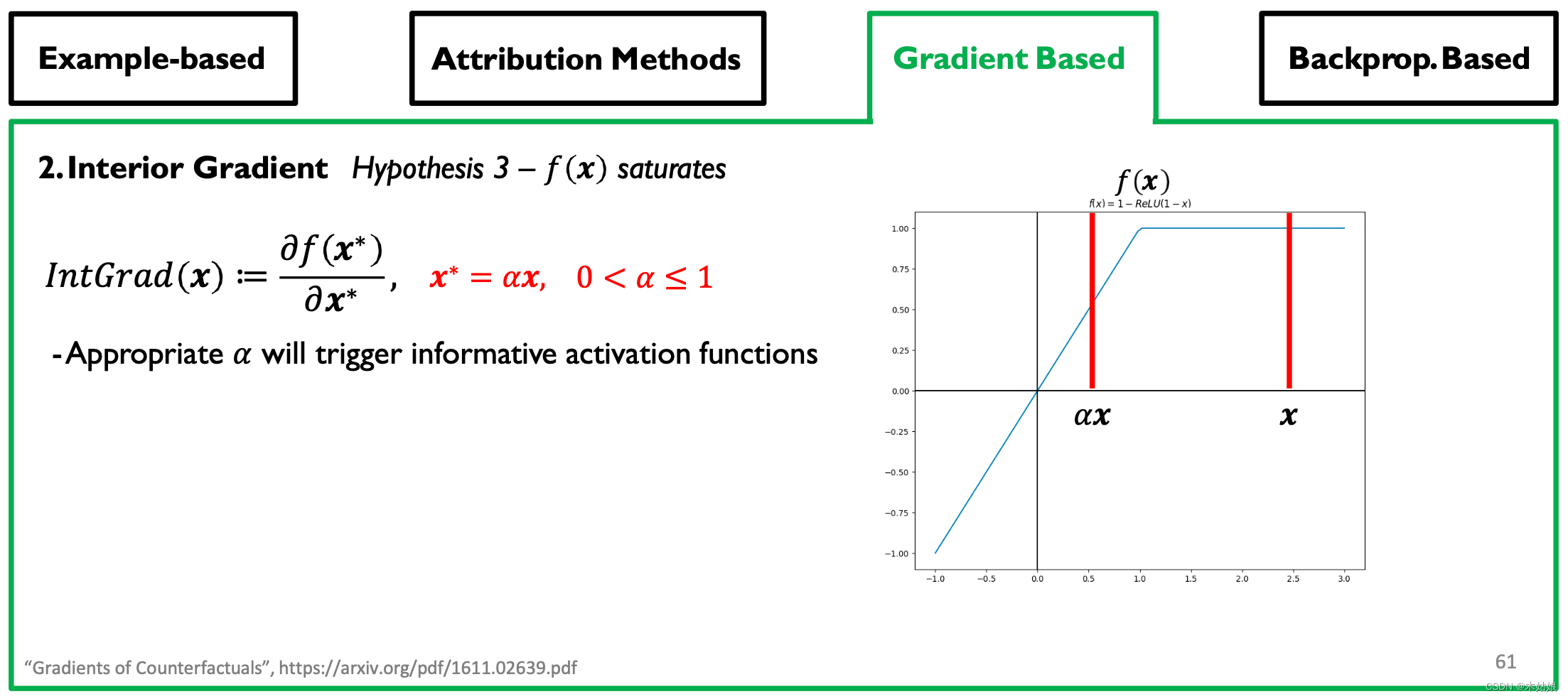

Backprop-based Attribution: Deconvolution, Guided Backpropagation
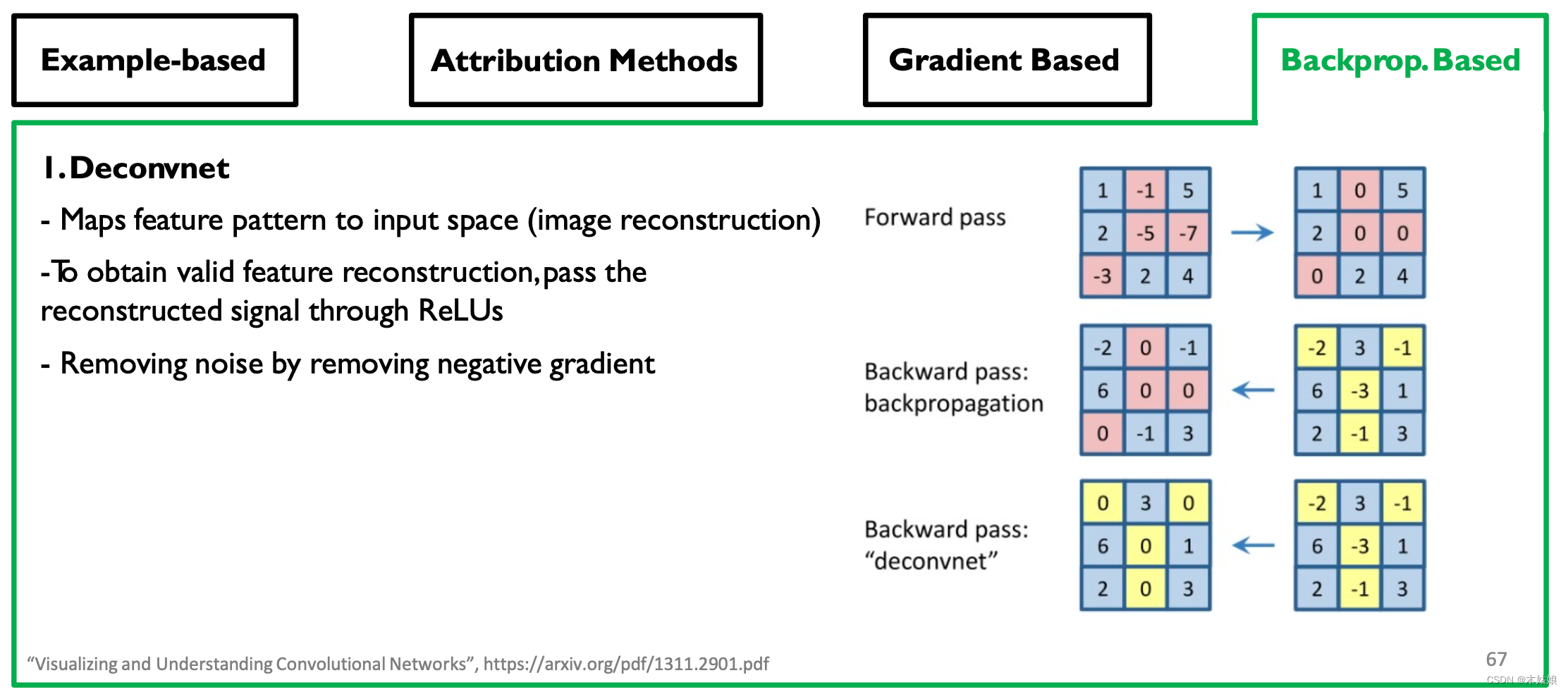
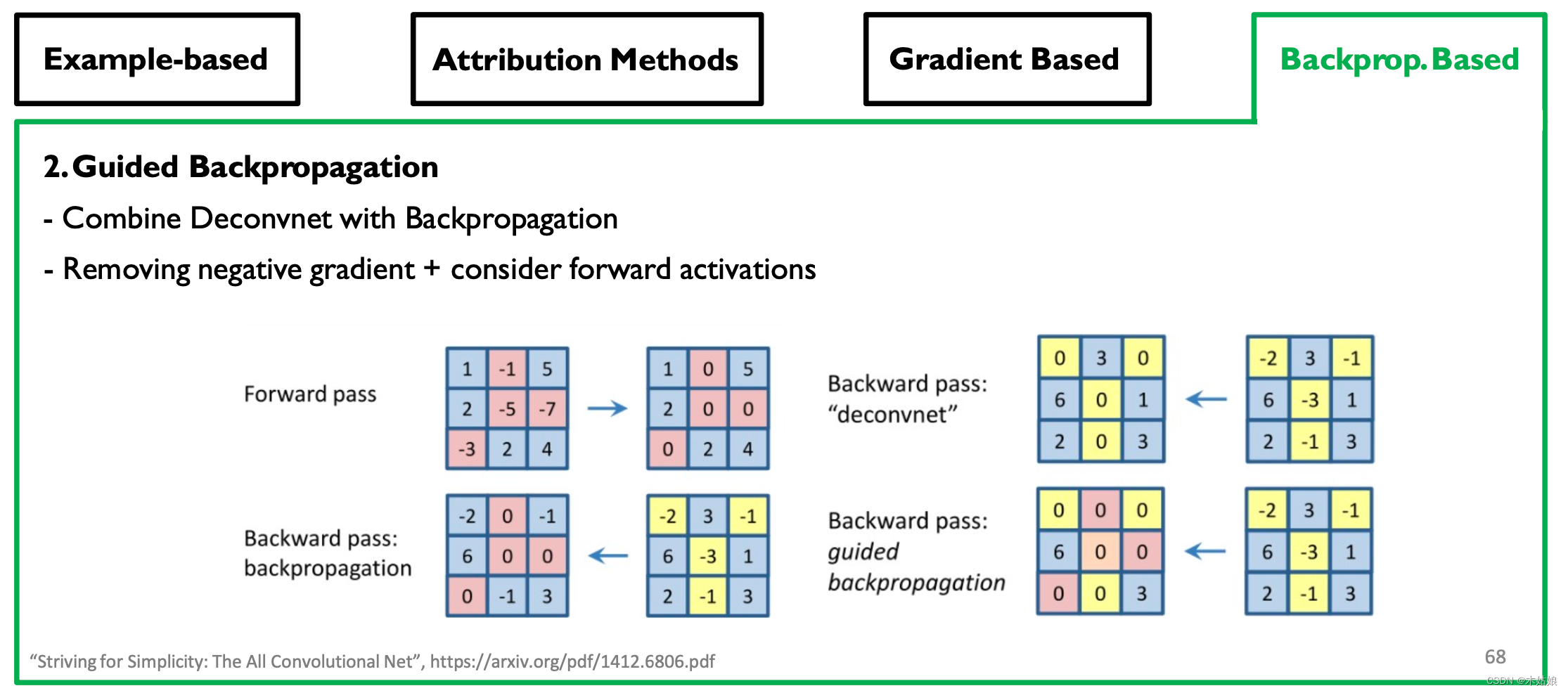
- Observe : Removing more gradients will bring a clearer visual effect

Evaluating Attribution Methods
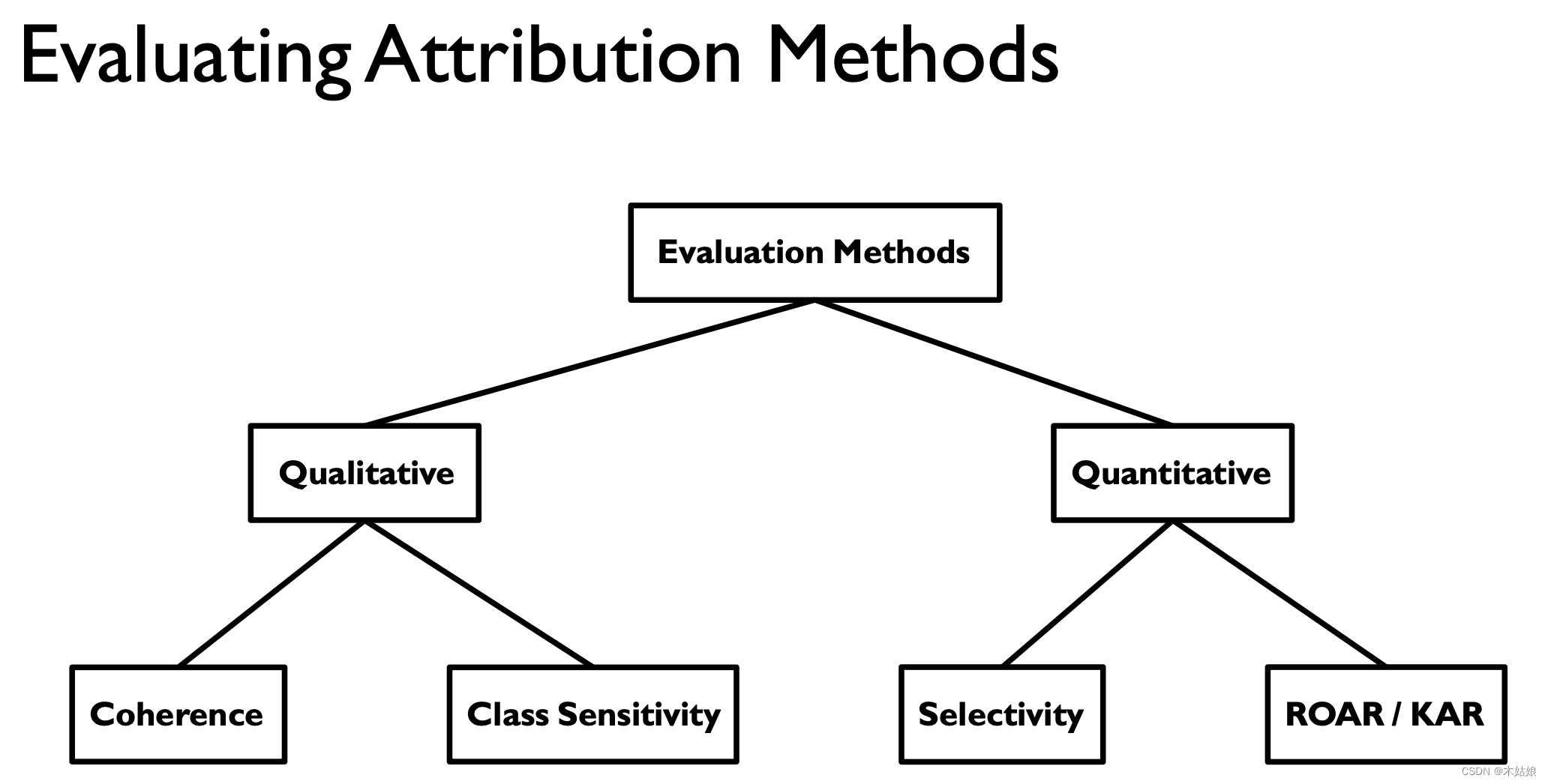
3a. Qualitative: Coherence: Attributions should highlight discriminative features / objects of interest
- Attribution should be based on distinctive characteristics
3b. Qualitative: Class Sensitivity: Attributions should be sensitive to class labels
- Attribution should be category sensitive

3c. Quantitative: Sensitivity: Removing feature with high attribution --> large decrease in class probability
- Removing features with high attributes will lead to a significant reduction in class probability

3d. Quantitative: ROAR & KAR. Low class prob cuz image unseen --> remove pixels, retrain, measure acc. drop

边栏推荐
- Sword finger offer 05 Replace spaces
- Sword finger offer 04 Search in two-dimensional array
- 剑指 Offer 09. 用两个栈实现队列
- ALU逻辑运算单元
- 【Rust 笔记】13-迭代器(中)
- 剑指 Offer 05. 替换空格
- Dynamic planning solution ideas and summary (30000 words)
- [practical skills] technical management of managers with non-technical background
- Over fitting and regularization
- 6. Logistic model
猜你喜欢

数据可视化图表总结(二)
![[jailhouse article] jailhouse hypervisor](/img/f4/4809b236067d3007fa5835bbfe5f48.png)
[jailhouse article] jailhouse hypervisor
Sword finger offer 09 Implementing queues with two stacks

CCPC Weihai 2021m eight hundred and ten thousand nine hundred and seventy-five
1.14 - 流水线
Sword finger offer 05 Replace spaces

CF1637E Best Pair
【Jailhouse 文章】Jailhouse Hypervisor
leetcode-6110:网格图中递增路径的数目
Sword finger offer 35 Replication of complex linked list
随机推荐
One question per day 2047 Number of valid words in the sentence
How many checks does kubedm series-01-preflight have
【Rust 笔记】17-并发(下)
[jailhouse article] performance measurements for hypervisors on embedded ARM processors
PC register
QT判断界面当前点击的按钮和当前鼠标坐标
YOLOv5-Shufflenetv2
Sword finger offer 05 Replace spaces
Brief introduction to tcp/ip protocol stack
Codeforces Round #732 (Div. 2) D. AquaMoon and Chess
Implement an iterative stack
Time of process
js快速将json数据转换为url参数
shared_ Repeated release heap object of PTR hidden danger
剑指 Offer 53 - I. 在排序数组中查找数字 I
Fried chicken nuggets and fifa22
Control unit
Pointnet++ learning
智慧工地“水电能耗在线监测系统”
CF1634E Fair Share