当前位置:网站首页>程序员都应该知道的URI,一文帮你全面了解
程序员都应该知道的URI,一文帮你全面了解
2020-11-08 20:18:00 【好未来技术】

URI 是每个程序员都应该了解的概念,同时相关联的还有 URL, URN 等概念簇。了解这些概念,可以帮助我们更好地窥探万维网(WWW)的设计,同时也能帮我们在工作中有效解决跟 URI 相关概念的问题,更加理解 encode,decode 工作原理,更好地助力网络编程!
1.URI
URI(Uniform Resource Identifier) ,意为统一资源标识符,提供了一套简单可扩展的方式对资源进行标识。
1.1 URI 的前世今生
为什么会有 URI?
随着万维网的发展,需要有各种不同类型的资源被在网络上查找以及传输。因此,也就需要一种唯一的可在万维网上传播的标识,这样的统一资源标识就称为 URI。当然,资源在这里是一种笼统概念,或者抽象概念,可以泛指可以被标识的实体,就像一个网页,一本e-book, 一份 pdf 等等,只要有需要被呈现或者传输,都可以称为一种资源。
万维网奠基人Tim Berners-Lee关于超文本(hypertext)的提案中间接提出了用来标识超链接的想法–URL(Uniform Resource Locator)。因此,URL 也就最早被用来进行网络上可以提供访问的地址表示。随着HTTP, HTML 以及浏览器的逐步发展,越来越需要把标识资源可访问地址以及单出命名表示资源这两种方式分开,因此也就提出了 URN(Uniform Resource Name),并用来表示后者。

IETF(网络工程任务小组)主要负责 URI 相关标准制订。
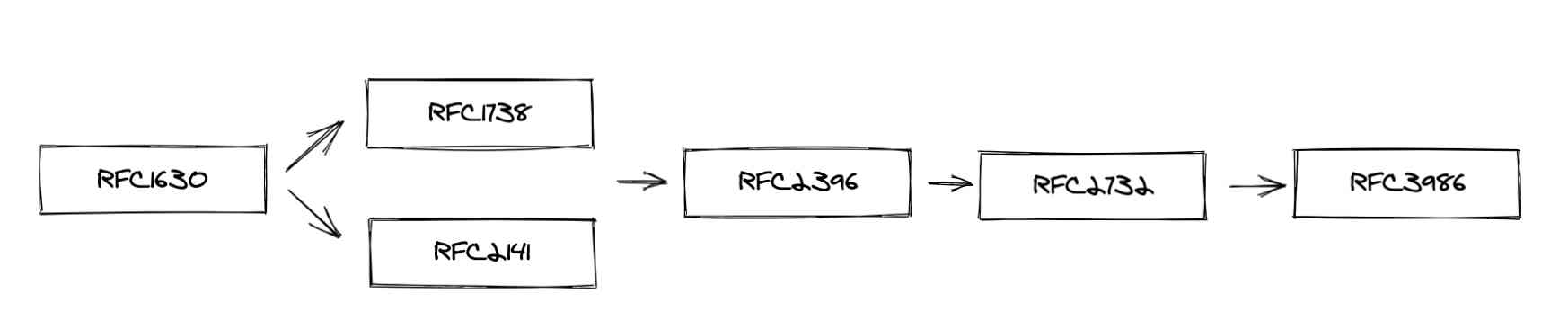
- 1994年发布RFC1630, 指出了 URL 和 URN 的存在,同时定义了 URI 的正式语法。
- 94年12月,RFC1738正式提出了 absolute 和relative URL, RFC2141则补充了URN 相关的文法和语法定义。
- 1999年的 RFC2732允许 URI 使用 IPv6地址
- 在2005年发布的RFC3986标准,解决了上述标准提出的一些短板,同时标志着URI 通用语法正式称为官方互联网协议
- RFC3305标准指出,虽然 URL 名词被广泛使用,但是其本身可能被逐渐废弃,并且只用来做为一些 URI 作为间接提供该资源访问地址的提示。并且指出资源标识符不需要表示该资源通过网络的访问地址,或者根本不需要隐含该资源是基于网络提供的。(这里相当矛盾,其实 URL 已经作为民间事实标准并被广泛使用,也不是标准想推翻就能立刻推翻的 - -)
1.2 URI 和 URL,URN 比较
了解到 URI 和 URL,URN 整体的历史,可以看出来最早 URI和 URL 其实是一脉相源的。后来为了兼容单纯通过命名或者名称来标识某个资源(并不是可被网络直接访达或者包含包含网络访问地址)的情况,提出了 URN标准。由此可见,这三个名称都可以表示对一项资源的定位标识。比较有意思的问题是,在平常的工作沟通中,如何区分,并且在什么样的场景下该使用哪个名称?

1.2.1 基本概念
先具体了解每个名称的基本概念:
1.URI
统一资源标识符。
用来表示某个特定资源。设计出来可以进行任何实体或者非实体的标识,但是目前被经常用于在网络上可传输内容的标识。URI 是由一串特定字符集的字符组成,并且由 IETF 制订的标准定义了一组语法规则,用来保证某个资源的统一和唯一标识。
2.URL
统一资源定位符。
也可以被称为网络地址。在万维网上,每个资源都有可以有唯一地址指向该资源,同时,通过该地址可以进行资源的读写,这样的地址标识就称为 URL。URL 包含了目前网络上常见的格式,包括 web 站点地址 http, 文件传输协议ftp, emal 地址协议 mailto以及数据库访问地址 JDBC 等。
3.URN
统一资源名称。
URN用来通过名称标识在特定命名空间的某个资源,同时希望为资源可以提供一种较持久的,与位置和存取方式无关的表示方式。URN 并不关注这个表示名称里是否隐含了该资源的位置,或者如何获取它,也不一定代表该资源一定可用。
举个例子,在ISBN(Internal Standard Book Number)系统中,一个编号(类似9971-5-0210-0)代表了一个书本资源,该编号在 URN 中可以表示为 urn:isbn:9971-5-0210-0, 但是这个编号并没有给出在哪里或者如何找到这本书的信息,它只能唯一标识了这本书。
1.2.1 三者之间的关系
先上图来说明 URI,URL 和 URN 之间的关系。
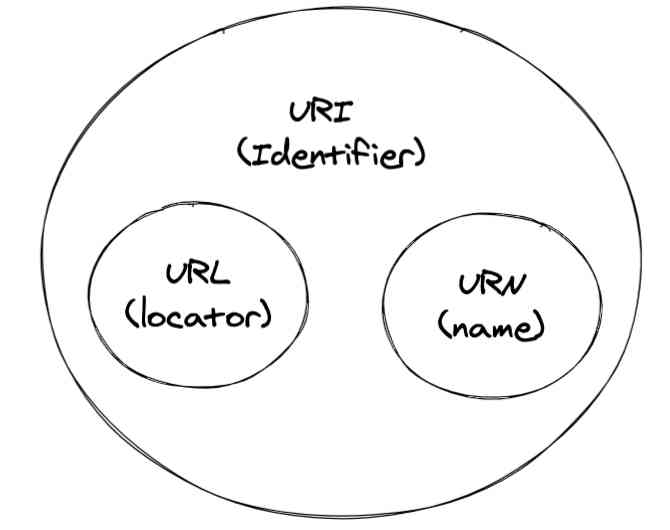
URI 可以认为是一个抽象的概念,所有的 URL 以及 URN 都是 URI。RFC3986标准中有这样一段:
A URI can be further classified as a locator, a name, or both. The term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network “location”).
rfc 3986, section 1.1.3
URI 可以被分类成 locator 或者对应的名称表示,也就是包含了 URL 和 URN 的概念。因此,平常我们在说 URL 的时候,它其实也可以被称为 URI。
同样,这里有个非常有意思的问题,URN 其实比较好区分开,在使用唯一标识资源名称时可以使用,但是 URI 和 URL 如何区分在哪个场景进行使用?
这个问题其实和 RFC3986标准定义的不够清楚有关,请再看下面这一段:
The URI itself only provides identification; access to the resource is neither guaranteed nor implied by the presence of a URI.
rfc 3986, section 1.2.2
URI 不保证提供该资源的访问方式,或者隐含保证该资源是否存在(其实语义就是该 URI 就是一个名称表示),但是在上一段中又声明了URI 会被分类成name 或者 locator,表示 URI 应该包含locator 这种访问方式。再看下面这一段:
Each URI begins with a scheme name, as defined in Section 3.1, that refers to a specification for assigning identifiers within that scheme.
rfc 3986, section 1.1.1
每个 URI 都需要包含有起始 scheme 名称。比如:https://www.example.com,这样的一串字符串就可以称为 URI,但是明确标识了应该如何去访问这个资源,同时它也是 URL,因为 URL 是用来告知接收方获取该资源的方式。
IETF在RFC3986中也有一段关于 URI 和 URL 使用方式的说明:
Future specifications and related documentation should use the general term “URI” rather than the more restrictive terms “URL” and “URN”
rfc 3986, section 1.1.3
这样看来,好像IETF 更支持使用 URI 来代替 URL 这个称呼。但是考虑到 URL 目前已经成为用来描述网络上资源定位的事实名称,而且 RFC3986已经诞生超过15年了(有些条目确实跟不上时代发展速度),所以在针对互联网资源定位(即网络地址)的时候,URL 可以算是更贴切的名称。当然,如果对方跟你谈 URI等等,这也没问题,因为 URI 算是超类,并且也可以代表该资源。
下面是这个问题结论:
- URI 是一种标记符
- URL 是可以告诉你如何去访问或者获取该资源的一种标记符
- 在描述网络资源地址的时候,用哪种都没问题,需要明确的原则就是最好和你的信息接收方用同样的称呼,方便理解
- 如果觉得不好拿捏属于 URL 或者 URN,那就可以直接使用 URI 描述
2.URI 字符集
2.1 URI的设计点
URI 需要提供一种简单,可扩展的方式来唯一标识资源。同时,又需要考虑到在不同媒介上进行传播的表示形式。因此,URI 在设计时需要考虑到以下几点:
- URI 需要是可移植的。
不同的系统,或者不同的接收方之间都可以使用 URI 协议来标识资源。URI 可以被表示成多种形式,比如说在纸上书写的字符串,或者屏幕上的像素,或者一系列通过编码的二进制流等。URI 的解析只跟这些呈现方式所关联的字符串有关,而跟具体表现方式,载体无关。
考虑到 URI 更多需要在网络场景传输,因此:
- URI 是由一串字符序列组成
- URI 可能会从非网络环境中移植到网络环境下,但是网络环境的输入一般受制于键盘,鼠标等输入载体,因此最好由可以被这些物理载体方便输入的字符呈现
- URI 一般需要被人们记住并使用,所以这些字符最好是人们经常使用并且熟悉的内容
基于上述考虑,URI 为一串受限的字符所组成的字符串,并选择 US-ASCII 作为字符集。US-ASCII 字符集基本上被所有系统支持,而且兼容性良好,能够支持 URI 所需要的移植性。
- URI 需要将标识和动作分开
这一层思想其实是需要将表示和表现分开。URI 只关注某个资源的标识,如果进行这个资源的存取或者访问不做任何方式的保证。同资源相关的动作,引用等,在设计时被交给具体实现 URI 下 scheme 的协议来制订,例如,http 协议会具体关心一个用’http’ scheme 表示的资源如何进行’get’, ‘update’,'delete’等一系列操作等。
这样可以保证 URI 协议的相对稳定,以及比较好的扩展性
- 层级标识
由于资源经常具有层级关系,比如在一个 example.com 站点下可能会挂有多个资源,或者下面会有一个目录’dir’, 该目录下会包含多个资源,这就意味着URI 需要有一种层级的组织方式。
在设计中也考虑到了这样类型的资源组织方式,允许 URI 按照层级组织,并且在字符串上按照从左到右的顺序拆分组件。
类似于常用操作系统的文件系统一样,URI 可以用来还原具有层级关系的资源系统的组织结构。
2.2 URI 所选择的字符集
如上所属,URI 选择 通过US-ASCII 字符集来进行表示,并限制使用从其中所挑选的一部分字符,数字以及符号。而且,由于需要支持层级结构,以及 URI 自身包含了不同的部分,因此也需要保留一些字符用来做这些有语义的部分的分隔。
Note: 由于需要对字符集或者语法进行描述,下文都是用 IETF使用的通用描述系统ABNF(Augmented Backus-Naur form), 即增强巴科斯范式。
增强巴科斯范式所定义的语法结构一般如下:
rule = definition / definition; comment CR LF
rule = <a>*<b>element
表示一组规则由一系列字符串组成的定义来描述,第一组 rule通过’/‘来表示定义中’或者’的关系。如果该条规则需要增加注释,那么需要通过’;'来标识注释的开始
第二组 rule 表示重复规则,其中 a标识最少重复次数,b 标识最多重复次数。例如,2*3element标识 element 最少出现两次,最多出现三次
关于增强巴科斯范式的具体内容请参照:
https://en.wikipedia.org/wiki/Augmented_Backus%E2%80%93Naur_form
2.2.1 Percent-Encoding
由于 URI 在协议中只挑选了部分ASCII 字符,数字以及符号,那么当需要表示不在这个范围之内的符号,字符,或者该字符在 URI 中被用来分隔符等特殊用途时,就需要对这个字符进行%编码。百分号编码也可以叫做URLEncode,其一般格式为:
pct-encoded = "%" HEXDIG HEXDIG
将不能直接使用的字符先转为字节流表示(一般为 utf-8编码,需要具体看上下文和 URI scheme 协议制订),然后每个字节转换为%加两个十六进制字符来表示。例如:
“00101011” 该字节需要编码为 “%2B” ,在 ASCII 码表中表示为 "+"号
Note: 百分号编码不关心大小写,但是为了统一和一致,最好应该使用大写字符
2.2.2 Reserved Characters
URI 保留字符集。
URI 自身定义时包含了 components以及 subcomponents,那么这些不同的 components 就需要通过分隔符来进行标识。这些被用来进行表示分隔的字符就成为保留字符集,这些字符集可能会被用作(或者将来会被用作)URI 不同部分的分隔符。
以下为 reserved character 所涉及的字符集表示:
reserved = gen-delims / sub-delims
gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
sub-delims = "!" / "$" / "&" / "'" / "(" / ")"
/ "*" / "+" / "," / ";" / "="
gen-delims 字符集用来表示 URI component 之间的分隔符,考虑到 component 内会由不同的 subcomponents 组成,因此需要 sub-delims 字符集来定义 subcomponents之间的分隔符。
Note:这些字符在 URI 中一般具有特殊语义,因此不能被编码。同时,如果在进行两个 URI 相等性比较时,如果其中一个对协议中component 部分不能编码的保留字符进行编码,即使解码后两个 URI 字符相同,也会被认为是两个不同的 URI
2.2.3 Unreserved Characters
允许出现在URI 中,并且不会被拿来用作保留字符集的字符集合成为 Unreserved Characters。所涉及到字符ABNF 表示为:
unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
ALPHA = a-z / A-Z
DIGIT = 0-9
这些字符为非保留字符,在 URI 使用过程中是不需要进行编码的。
Note: 如果在 URI 比较中包含这些字符,那么该字符本身或者其编码格式都应该认为是相等的,即这些字符编码不编码不会影响相等性。另外,这些字符在使用时最好不要编码,即使已经被编码,那么在使用时也应该先对这些字符进行解码。
2.2.4 总结
一图来表示在 URI 中所涉及到的保留和非保留字符,需要注意的是保留字符在不做分隔符或者具有特殊含义的时候是需要编码的。

3.URI Component
URI 语法规则由一系列 component 组成,并且在设计时需要考虑到扩展性以及对各个资源定位类型的兼容,因此在其起始都会有一个 scheme 头来特定标识这个 URI 所定义的资源类型标识符。另外,URI 由于是所有资源类型的超集(会细分为 URL 和 URN),所以 URI 所涉及的定义都是需要被遵守的基本定义。
URI component 一般由以下 component 组成(使用 ABNF 描述):
URI = scheme ":" [ //authority ] path [ "?" query ] [ "#" fragment ]
authority = [ userinfo@ ] host [ :port ]
Note:
schme 和 path 为 required
有了上述语法规则的定义,举个例子来说明 URI 下两种不同的标识符所定义的各个 component 部分
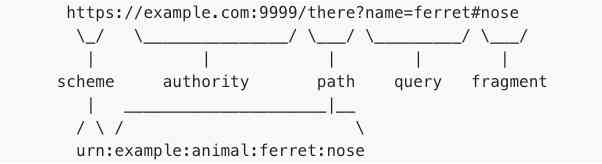
下文将详细介绍各个组件部分,以及相应的语法规则。
3.1 URI component
3.1.1 Scheme
| component | scheme |
|---|---|
| 允许字符集 | a-z A-Z 0-9 + . - |
| 是否 case-sensitive | 否 |
| component 结束标识符 | : |
Note:
- 表中字符集为了呈现清晰,因此正则中通过非必要空格进行分隔,并且表或者关系
- 结束标识符表示语法解析时该 component 解析结束符
scheme用来标识URI 所对应的具体协议。每个 URI 都必须以 scheme 开头。URI 的语法规则如下(使用 ABNF 描述):
scheme = ALPHA *( ALPHA / DIGIT / "+" / "-" / "." )
如上文所说,URI 定义通用的语法规则,scheme 所标识的具体协议会定义通用规则外的具体语法规则。例如,以 geo 为scheme 的协议 URI,表示特定地理位置标识,其语法规则如下:
geo:<lat>,<lon>[<alt>][u=<uncertainty>]
参考自 RFC 5870
URI scheme 的官方注册信息目前由 IANA(Internet Assigned Numbers Authority) 组织进行添加和维护,目前约包含了335种不同协议 scheme,具体可参考https://www.iana.org/assignments/uri-schemes/uri-schemes.xhtml
3.1.2 Authority
| component | Authority |
|---|---|
| component 开始标识符 | // |
| component 结束标识符 | / ? # |
authority component 设计的目的为设定一个命名空间,并且标识这个命名空间被哪个机构所管理,例如 baidu.com, google.com 等等。authority 一般由三部分组成,包含了可选的 userinfo, port 以及必选的 host 部分。
关于为什么 Authority 部分会选择 // 作为起始符号的原因,Tim Berners-Lee 曾回答过:
- 需要选择一个命名系统来进行资源的层级化命名,/ 作为 unix 系统通用的分隔符可以在 URI 的设计中得到复用,因此使用 / 来作为 relative URI 的分隔符
- 需要有符号将 host 部分(类似 www.example.com)同URI 的其他部分进行区分,这部分设计参考了当时 Apollo domain system (其使用//computername/file/path进行命名)的设计方式
- 现在来看,他认为这个语法是比较冗余的,更喜欢直接通过:来进行域名分隔,例如 http://www.example.com/foo/bar 转写为 http:www.example.com/foo/bar, 这样写同样可以识别到server 并且更为简化
由此可见,标准的设计也是需要再不断地迭代和试验中前进 :)
3.1.2.1 Userinfo
| component | Userinfo |
|---|---|
| 允许字符集 | pct-encode字符集 unreserved字符集 sub-delims字符集 : |
| 是否 case-sensitive | 是 |
| component 结束标识符 | @ |
userinfo 包含了用户相关信息(一般为名称,旧式格式 user:password 由于涉及安全风险已被弃用),同时需要通过@符合和 host 进行分隔。Userinfo 部分的语法规则如下(使用 ABNF 描述):
userinfo = *( unreserved / pct-encoded / sub-delims / ":" )
3.1.2.2 Host
| component | Host |
|---|---|
| 允许字符集 | pct-encode字符集 unreserved字符集 sub-delims字符集 |
| 是否 case-sensitive | 否 |
| component 结束标识符 | / : |
服务提供商通过 host来提供服务,同时基于 dns 域名解析, server 和 host 之间可以做到非一一对应。host 部分可以有三种表示方式,IPv6, IPv4或者 registered name。registered name host的语法规则如下(通过 ABNF 描述):
host = IPv6address / IPv4address / reg-name
IPv6address = [ HEXDIG *( :: HEXDIG ) ]
IPv4address = DIGIT "." DIGIT "." DIGIT "." DIGIT
reg-name = *( unreserved / pct-encoded / sub-delims )
3.1.2.2 Port
| component | Port |
|---|---|
| 允许字符集 | 0-9 |
| component 结束标识符 | / |
port 为可选项,同时通过十进制进行表示。在URI语法中,port 需要跟在 : 后。port 的语法规则如下(使用 ABNF 描述):
port = *DIGIT
每种 scheme 一般会定义一个默认端口。例如, http 定义80默认端口,https 定义443默认端口等。
3.1.3 Path
| component | Path |
|---|---|
| 允许字符集 | pct-encode字符集 unreserved字符集 sub-delims字符集 @ : |
| component 结束标识符 | ? # EOF |
path标识了 host 下特定的资源路径,包含了一系列通过 / 分隔的 segments。需要注意的是,如果URI已经包含了 authority 部分,那么 path部分或者为空,或者需要以 / 来开头。另外,URI还允许 relative-path 的使用方式,这样的方式第一段 path segment 不能包含 :(如果包含,会被 parser 认为是 authority 部分)。以下是简化的 path 语法规则(使用 ABNF 描述):
path = path-abempty / path-relative
path-abempty = *( "/" segment )
path-relative = segment-nocolon *( "/" segment )
segment = *pchar
pchar = unreserved / pct-encoded / sub-delims / ":" / "@"
segment-nocolon = unreserved / pct-encoded / sub-delims / "@"
3.1.4 Query
| component | Query |
|---|---|
| 允许字符集 | pct-encode字符集 unreserved字符集 sub-delims字符集 @ : |
| component 开始标识符 | ? |
| component 结束标识符 | # EOF |
query 部分提供了定位资源的辅助信息,query其内部语法并没有明确定义,但是一般由name-value 键值对组成的字符串组成,中间通过分隔符 & 进行分隔。例如:name1=value1&name2=value2。query 的语法规则如下(使用 ABNF 描述):
query = *( pchar / "/" / "?" )
pchar = unreserved / pct-encoded / sub-delims / ":" / "@"
3.1.5 Fragment
| component | Query |
|---|---|
| 允许字符集 | pct-encode字符集 unreserved字符集 sub-delims字符集 @ : / ? |
| component 开始标识符 | # |
| component 结束标识符 | EOF |
fragment 为段落标识符,一般用来标识一个 resource 的特定部分(一个资源子集或者一部分,或者通过这个资源来描述的一些其他资源)。 fragment 以 # 作为起始标识符,其语法规则如下(通过 ABNF 描述):
fragment = *( pchar / "/" / "?" )
pchar = unreserved / pct-encoded / sub-delims / ":" / "@"
3.1.6 小结
各个component 允许的字符集部分是我们需要特别关注的,需要注意在五个 component 之间允许使用 gen-delims 字符集,在每个 component 内(即小组件间)允许使用 sub-delims 字符集。
3.2 解析 URI
如何通过程序来解析 URI, 并得到 URI 各个 component?
如上一节 ABNF 语法规则描述,URI 满足上下文无关文法。因此,我们可以通过语法图来呈现整体 URI 的解析规则,如下:

有了上图,使用递归下降,解析的伪代码就非常好写了:
/** * 读取下一个字符 **/ function next() { skip space; read next char and return; } /** * 预扫描,查看对应的 input 字符串是否包含有 special_char, * 以及其位置 **/ function contains(input, special_char) { start = input.start, end = input.end; while (start < end) then if special_char equals start then return; end return start } /** * 对 uri 的解析函数 * 具体的解析 component 方法为 parse_*, 需要匹配的字符集以及语法规则可参照上文中各个 ABNF **/ function parse(string uri) { parse_scheme; skip next ';' ; if next() == "//" then if contains(substring_uri(// until path), '@') then parse_userinfo; end parse_host; if next() == ':' then parse_port; end end parse_path; if next() == '?' then parse_query; end if next() == '#' then parse_fragment; end }
5.再论Encode 和 Decode
什么时候该 encode 或者 decode?
先说 URI 的设计目的,URI 被设计出并可在万维网上进行广泛传播,因此对各个子系统,浏览器等媒介的兼容性是最重要的,因此被设计使用被广泛使用的 ASCII 码进行承载。
因此,在生成 URI 过程中,应该先完成各个 componet 部分的编码,然后在联合 gen-delimiter 拼接成 URI。由于各个 scheme 的具体协议不同,因此只有在生成 URI 的过程中,才可以知道具体哪些 delimiter 会需要被编码,或者会被使用作为真正的 delimiter。一旦 URI 被生成,该 URI 在传播时就应该保持其 百分号 encode 的格式。
当百分号编码的 URI 在解码时,应该先通过 gen-delimiter 以及 sub-delimiter 将各个 component 进行分离,然后再对各个 component 进行分别解码。这样可以保证按照生成的 URI 被完整解码。
另外,需要注意的是,2.2.3中提到的 unreserved 字符集可以在任意时刻被编码和解码,但是推荐在生成 URI 时不对这些字符集进行编码,同时在解码时应该优先对这些字符集的百分号编码格式进行解码。
Note: 不应该对同一个 URI 重复次编码或者解码,这样会导致 URI所代表的语义失效。例如,对已经进行百分号编码的 URI 再进行编码时,又会再次对其中的百分号进行二次编码,从而导致 URI 在进行解码时含义错误。
5.1 实现 encode 和 decode
按照上文的说法,encode 需要先根据对应的 component 部分来组成不需要进行 escape(即不需要编码) 字符的规则,然后再进行逐一的判断和编码,之后再将编码过后的 component 拼接称为 URI(当然,如果所有的 delimiter 都不需要进行编码,那可以直接对整个 URI 进行编码,不需要 escape 的字符集直接包含这些 delimiter 字符)。 decode 则需要先将各个 component 按照 delimiter 进行拆分,然后分别对各个 component 在需要解码的字符规则下进行解码。
Note: 在标识 ASCII 以外的字符集时,一般是用 Unicode 字符集,编码方式为 UTF-8。
因此,在编码和解码过程中,如果编程语言层面使用 UTF-16进行字符编码(类似于 Java 和 JavaScript),那么需要将其转为 UTF-8编码,同时需要针对 UTF-16带来的 surrogate pair 进行额外处理。
关于surrogate pair 描述,可以参考
https://stackoverflow.com/questions/5903008/what-is-a-surrogate-pair-in-java#:~:text=The%20term%20%22surrogate%20pair%22%20refers,values%20between%200x0%20and%200x10FFFF.&text=This%20is%20done%20using%20pairs%20of%20code%20units%20known%20as%20surrogates.
5.1.1 encode
encode 的实现中需要注意的就是对需要编码的字节进行%编码,伪代码如下:
/** * 对某一段 string s 进行 URI encode 编码 * 传入 s 以及不需要编码的字符集 dontNeedEncodingSet, 返回 URI encode后的string * * dontNeedEncodingSet 字符集需要根据3.1中的 component描述来定,例如 Path 中的不需要编码字符集 * 一般为 unreserved字符集 sub-delims字符集 @ :(sub-delims 字符集以及@ : 如果其本身需要出现在 * component 中而不是用来做分隔语义,那么同样需要进行 encode),另外不同的语言实现在不需要编码字符集 * 上可能会有不同的选择 **/ function encode(s, dontNeedEncodingSet) { // 声明 R 为结果字符串 def R, index = 0, strLen = s.length(); while index < strLen then def c 为 s 在 index 下的字符表示; if c 包含在 dontNeedEncodingSet 里 then R += c; else def 临时结果 out; /** * 这里需要考虑如果是 utf-16字符编码,那么需要判断 surrogate pair **/ if c 在 surrogate pair中的第一个字符所表示的范围内 then def c2 为 ++index 位置字符; 将 c c2两个字符组成 utf-16并进行 utf-8编码; 将上述结果赋值给 out; else 如果 c 为 utf-16编码,需要转为 utf-8编码; out = c; end // 核心百分号 encode 取 out 中每一个字节 out_byte; R += '%' + ((out_byte >> 4) & 0xF)转为16进制大写表示 + ((out_byte) & 0xF)转为16进制大写表示; end ++index; end return R; }
5.1.2 decode
decode 的实现中需要注意在遇到%号时读取后续字符进行解码,同时如果语言实现使用 utf-16编码那么需要对 surrogate pair 进行还原(这部分语言本身一般都提供方法来对 utf-8进行转换),伪代码如下:
/** * 对 s 进行解码,返回解码后的 string **/ function decode(s) { // 声明 R 为结果 string def R, index = 0, lenStr = s.length(); while index < lenStr then def c 为 s 在 index 下的字符表示; if c == '%' then def 中间临时结果 out; while c == '%' && index + 2 < lenStr then 读取index+1, index+2 字符 c1, c2; // 核心 decode out += (字符转为 hex 表示(c1)) << 4 | (字符转为 hex 表示(c2)); index += 3; end // 异常情况报错 if c == '%' && index < lenStr then 抛出错误; // 注意:如果语言实现需要 utf-16编码,那么需要先行将 out 转为 utf-16编码 R += out; else R += c; ++index; end end return R; }
5.1.3 小结
相信各位已经对 URI 有了一个相对全面的了解,在实际工作的使用中,还需要根据语言所提供的对应 encode,decode 方法文档来进一步了解其编解码所定义的 component 部分特殊保留字符,这样会对所使用语言提供的 encode/decode 有更深入的了解 :)
**
Enjoy your coding trip~
作者:王阳(好未来Java开发专家)
版权声明
本文为[好未来技术]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4471526/blog/4708313
边栏推荐
- python开发qt程序读取图片的简单流程
- 第一部分——第1章概述
- iptables从入门到掌握
- 使用基于GAN的过采样技术提高非平衡COVID-19死亡率预测的模型准确性
- 构造回文的最小插入次数
- C / C + + learning diary: original code, inverse code and complement code
- Problem solving templates for subsequence problems in dynamic programming
- AI perfume is coming. Will you buy it?
- Array acquaintance
- Introduction and application of swagger
猜你喜欢
随机推荐
Array acquaintance
如果把编程语言当武功绝学!C++是九阴真经,那程序员呢?
abp(net core)+easyui+efcore实现仓储管理系统——出库管理之五(五十四)
Suffix expression to infix expression
[elastic search technology sharing] - ten pictures to show you the principle of ES! Understand why to say: ES is quasi real time!
Use markdown
The interface testing tool eolinker makes post request
latex入门
Process thread coroutine
Mongodb add delete modify query operation
使用Fastai开发和部署图像分类器应用
When to write disk IO after one byte of write file
寻找性能更优秀的不可变小字典
给大家介绍下,这是我的流程图软件 —— draw.io
opencv 解决ippicv下载失败问题ippicv_2019_lnx_intel64_general_20180723.tgz离线下载
进程 线程 协程
Leetcode 45 jumping game II
The minimum insertion times of palindrome
【Elasticsearch 技术分享】—— 十张图带大家看懂 ES 原理 !明白为什么说:ES 是准实时的!
What is forsage Ethereum smart contract? What is the global decline of Ethereum