当前位置:网站首页>pytorch fine-tuning (funtune) : 镂空设计or 偷梁换柱
pytorch fine-tuning (funtune) : 镂空设计or 偷梁换柱
2022-07-05 01:28:00 【FakeOccupational】
偷梁换柱 or 貂尾续狗
# 导入包
import glob
import os
import torch
import matplotlib.pyplot as plt
import random #用于数据迭代器生成随机数据
# 生成数据集 x1类别0,x2类别1
n_data = torch.ones(50, 2) # 数据的基本形态
x1 = torch.normal(2 * n_data, 1) # shape=(50, 2)
y1 = torch.zeros(50) # 类型0 shape=(50, 1)
x2 = torch.normal(-2 * n_data, 1) # shape=(50, 2)
y2 = torch.ones(50) # 类型1 shape=(50, 1)
# 注意 x, y 数据的数据形式一定要像下面一样(torch.cat是合并数据)
x = torch.cat((x1, x2), 0).type(torch.FloatTensor)
y = torch.cat((y1, y2), 0).type(torch.FloatTensor)
# 数据集可视化
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
plt.show()
# 数据读取:
def data_iter(batch_size, x, y):
num_examples = len(x)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) #最后一次可能不足一个batch
yield x.index_select(0, j), y.index_select(0, j)
import torch.nn as nn
import torch.optim as optim
class net(nn.Module):
def __init__(self, **kwargs):
super(net, self).__init__(**kwargs)
self.net = nn.Sequential(
nn.Linear(2, 2),
nn.Linear(2, 2),
nn.Linear(2, 1),
nn.ReLU())
def forward(self, x):
return self.net(x)
def loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
def accuracy(y_hat, y): #@save
"""计算预测正确的数量。"""
cmp = y_hat.type(y.dtype) > 0.5 # 大于0.5类别1
result=cmp.type(y.dtype)
acc = 1-float(((result-y).sum())/ len(y))
return acc;
lr = 0.03
num_epochs = 3 # 迭代次数
batch_size = 10 # 批量大小
model = net()
params = list(model.parameters())
optimizer = torch.optim.Adam(params, 1e-4)
def loader(model_path):
state_dict = torch.load(model_path)
model_state_dict = state_dict["model_state_dict"]
optimizer_state_dict = state_dict["optimizer_state_dict"]
return model_state_dict, optimizer_state_dict
model_state_dict, optimizer_state_dict = loader("h1")
model.load_state_dict(model_state_dict)
optimizer.load_state_dict(optimizer_state_dict)
print('pretrained models loaded!')
# net(
# (net): Sequential(
# (0): Linear(in_features=2, out_features=1, bias=True)
# (1): Linear(in_features=1, out_features=2, bias=True)
# (2): Linear(in_features=2, out_features=1, bias=True)
# (3): ReLU()
# )
# )
for param in model.parameters():
param.requires_grad = False
print(model.net[2])
num_fc_in = model.net[2].in_features
print("fc层的输入维度",num_fc_in)
model.net[2] = nn.Linear(num_fc_in, 3) # 偷梁换柱 貂尾续狗
print(model)
aa = model.net[1]# 参数不可学习 Parameter containing:tensor([-0.0303, -0.9412])
aa = model.net[2]# 参数可学习 Parameter containing:tensor([0.4327, 0.1848, 0.3112], requires_grad=True)
镂空设计
# net(
# (net): Sequential(
# (0): Linear(in_features=2, out_features=1, bias=True)
# (1): Linear(in_features=1, out_features=2, bias=True)
# (2): Linear(in_features=2, out_features=1, bias=True)
# (3): ReLU()
# )
# )
================================》
# net(
# (net): Sequential(
# (0): Linear(in_features=2, out_features=2, bias=True)
# (1): Identity()
# (2): Linear(in_features=2, out_features=1, bias=True)
# (3): ReLU()
# )
# )
# https://discuss.pytorch.org/t/how-to-delete-layer-in-pretrained-model/17648/16
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
# 导入包
import glob
import os
import torch
import matplotlib.pyplot as plt
import random #用于数据迭代器生成随机数据
# 生成数据集 x1类别0,x2类别1
n_data = torch.ones(50, 2) # 数据的基本形态
x1 = torch.normal(2 * n_data, 1) # shape=(50, 2)
y1 = torch.zeros(50) # 类型0 shape=(50, 1)
x2 = torch.normal(-2 * n_data, 1) # shape=(50, 2)
y2 = torch.ones(50) # 类型1 shape=(50, 1)
# 注意 x, y 数据的数据形式一定要像下面一样(torch.cat是合并数据)
x = torch.cat((x1, x2), 0).type(torch.FloatTensor)
y = torch.cat((y1, y2), 0).type(torch.FloatTensor)
# 数据集可视化
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
plt.show()
# 数据读取:
def data_iter(batch_size, x, y):
num_examples = len(x)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) #最后一次可能不足一个batch
yield x.index_select(0, j), y.index_select(0, j)
import torch.nn as nn
import torch.optim as optim
class net(nn.Module):
def __init__(self, **kwargs):
super(net, self).__init__(**kwargs)
self.net = nn.Sequential(
nn.Linear(2, 2),
nn.Linear(2, 2),
nn.Linear(2, 1),
nn.ReLU())
def forward(self, x):
return self.net(x)
def loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
def accuracy(y_hat, y): #@save
"""计算预测正确的数量。"""
cmp = y_hat.type(y.dtype) > 0.5 # 大于0.5类别1
result=cmp.type(y.dtype)
acc = 1-float(((result-y).sum())/ len(y))
return acc;
lr = 0.03
num_epochs = 3 # 迭代次数
batch_size = 10 # 批量大小
model = net()
params = list(model.parameters())
optimizer = torch.optim.Adam(params, 1e-4)
def loader(model_path):
state_dict = torch.load(model_path)
model_state_dict = state_dict["model_state_dict"]
optimizer_state_dict = state_dict["optimizer_state_dict"]
return model_state_dict, optimizer_state_dict
model_state_dict, optimizer_state_dict = loader("h1")
model.load_state_dict(model_state_dict)
optimizer.load_state_dict(optimizer_state_dict)
print('pretrained models loaded!')
# for param in model.parameters():
# param.requires_grad = False
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
model.net[1] = Identity()
for epoch in range(num_epochs):
for X, y_train in data_iter(batch_size, x, y):
optimizer.zero_grad()
res = model(X)[:,0]
l = loss(res, y_train).sum() # l是有关小批量X和y的损失
l.backward(retain_graph=True)
optimizer.step()
print(l)
头部担当
# import some dependencies https://boscoj2008.github.io/customCNN/
import glob
import os
import torchvision
import torch
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
import torch.optim as optim
import time
import torch.nn as nn
import torch.nn.functional as F
torch.set_printoptions(linewidth=120)
class Network(nn.Module): # extend nn.Module class of nn
def __init__(self):
super().__init__() # super class constructor
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=(5, 5))
self.batchN1 = nn.BatchNorm2d(num_features=6)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=(5, 5))
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.batchN2 = nn.BatchNorm1d(num_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t): # implements the forward method (flow of tensors)
t = self.addconv1(t)# TODO 注意,再保存模型时注释掉这句
# hidden conv layer
t = self.conv1(t)
t = F.max_pool2d(input=t, kernel_size=2, stride=2)
t = F.relu(t)
t = self.batchN1(t)
# hidden conv layer
t = self.conv2(t)
t = F.max_pool2d(input=t, kernel_size=2, stride=2)
t = F.relu(t)
# flatten
t = t.reshape(-1, 12 * 4 * 4)
t = self.fc1(t)
t = F.relu(t)
t = self.batchN2(t)
t = self.fc2(t)
t = F.relu(t)
# output
t = self.out(t)
return t
cnn_model = Network() # init model
print(cnn_model)
mean = 0.2859; std = 0.3530 # calculated using standization from the MNIST itself which we skip in this blog
def saver(model_state_dict, optimizer_state_dict, model_path, epoch, max_to_save=30):
total_models = glob.glob(model_path + '*')
if len(total_models) >= max_to_save:
total_models.sort()
os.remove(total_models[0])
state_dict = {}
state_dict["model_state_dict"] = model_state_dict
state_dict["optimizer_state_dict"] = optimizer_state_dict
torch.save(state_dict, model_path + 'h' + str(epoch))
print('models {} save successfully!'.format(model_path + 'hahaha' + str(epoch)))
optimizer = optim.Adam(lr=0.01, params=cnn_model.parameters())
# for epoch in range(3):
# start_time = time.time()
# total_correct = 0
# total_loss = 0
# for batch in range(10):
# imgs, lbls = torch.rand(10,1,28,28),torch.tensor([0, 5, 3, 4, 4, 4, 7, 6, 2, 5])
# preds = cnn_model(imgs) # get preds
# loss = F.cross_entropy(preds, lbls) # compute loss
# optimizer.zero_grad() # zero grads
# loss.backward() # calculates gradients
# optimizer.step() # update the weights
# accuracy = total_correct / 10
# end_time = time.time() - start_time
# print("Epoch no.", epoch + 1, "|accuracy: ", round(accuracy, 3), "%", "|total_loss: ", total_loss,
# "| epoch_duration: ", round(end_time, 2), "sec")
# saver(cnn_model.state_dict(), optimizer.state_dict(), "./", epoch + 1, max_to_save=100)
def loader(model_path):
state_dict = torch.load(model_path)
model_state_dict = state_dict["model_state_dict"]
optimizer_state_dict = state_dict["optimizer_state_dict"]
return model_state_dict, optimizer_state_dict
model_state_dict, optimizer_state_dict = loader("h1")
cnn_model.load_state_dict(model_state_dict)
optimizer.load_state_dict(optimizer_state_dict)
print('pretrained models loaded!')
cnn_model.addconv1 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(1, 1))
for epoch in range(3):
start_time = time.time()
total_correct = 0
total_loss = 0
for batch in range(10):
imgs, lbls = torch.rand(10,1,28,28),torch.tensor([0, 5, 3, 4, 4, 4, 7, 6, 2, 5])
preds = cnn_model(imgs) # get preds
loss = F.cross_entropy(preds, lbls) # compute loss
optimizer.zero_grad() # zero grads
loss.backward() # calculates gradients
optimizer.step() # update the weights
accuracy = total_correct / 10
end_time = time.time() - start_time
print("Epoch no.", epoch + 1, "|accuracy: ", round(accuracy, 3), "%", "|total_loss: ", total_loss,
"| epoch_duration: ", round(end_time, 2), "sec")
saver(cnn_model.state_dict(), optimizer.state_dict(), "./", epoch + 1, max_to_save=100)
边栏推荐
- DOM basic syntax
- Is there a sudden failure on the line? How to make emergency diagnosis, troubleshooting and recovery
- PHP 约瑟夫环问题
- PHP 基础篇 - PHP 中 DES 加解密详解
- Global and Chinese market of portable CNC cutting machines 2022-2028: Research Report on technology, participants, trends, market size and share
- 【海浪建模3】三维随机真实海浪建模以及海浪发电机建模matlab仿真
- Database postragesq role membership
- Basic operation of database and table ----- the concept of index
- Research Report on the overall scale, major producers, major regions, products and application segmentation of agricultural automatic steering system in the global market in 2022
- phpstrom设置函数注释说明
猜你喜欢

Async/await you can use it, but do you know how to deal with errors?

【LeetCode】88. Merge two ordered arrays

Poap: the adoption entrance of NFT?
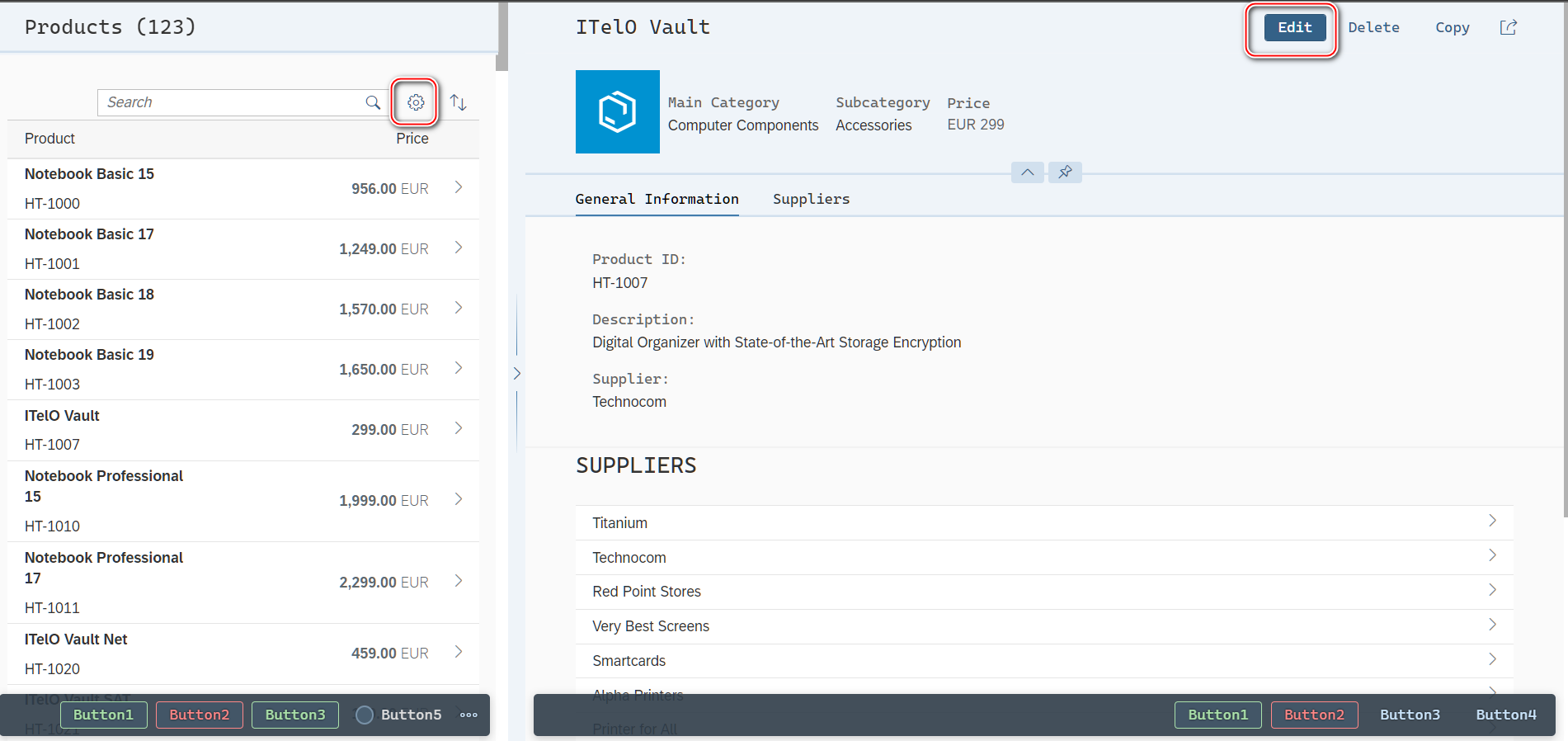
SAP ui5 application development tutorial 107 - trial version of SAP ui5 overflow toolbar container control introduction
![[untitled]](/img/d1/85550f58ce47e3609abe838b58c79e.jpg)
[untitled]
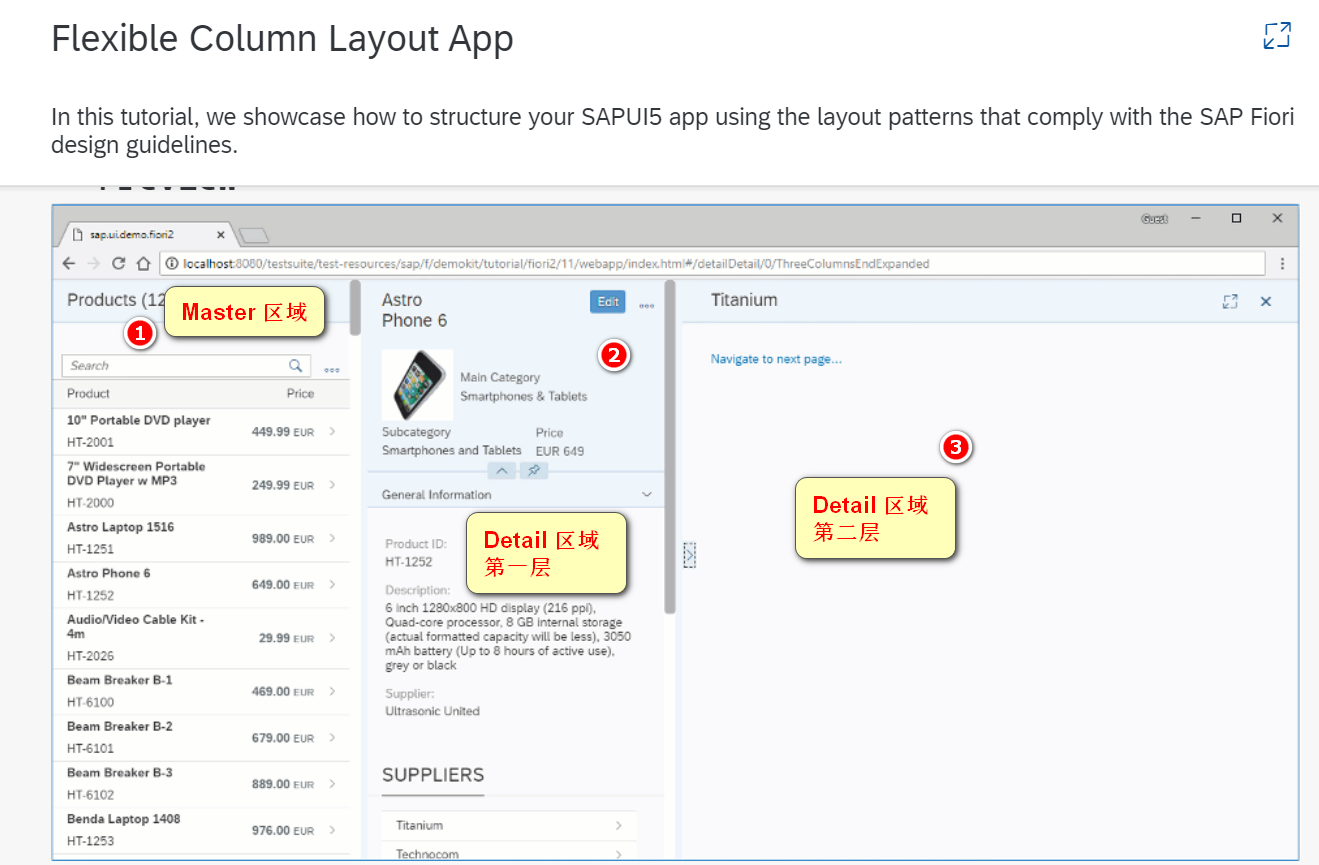
Implementation steps of master detail detail layout mode of SAP ui5 application
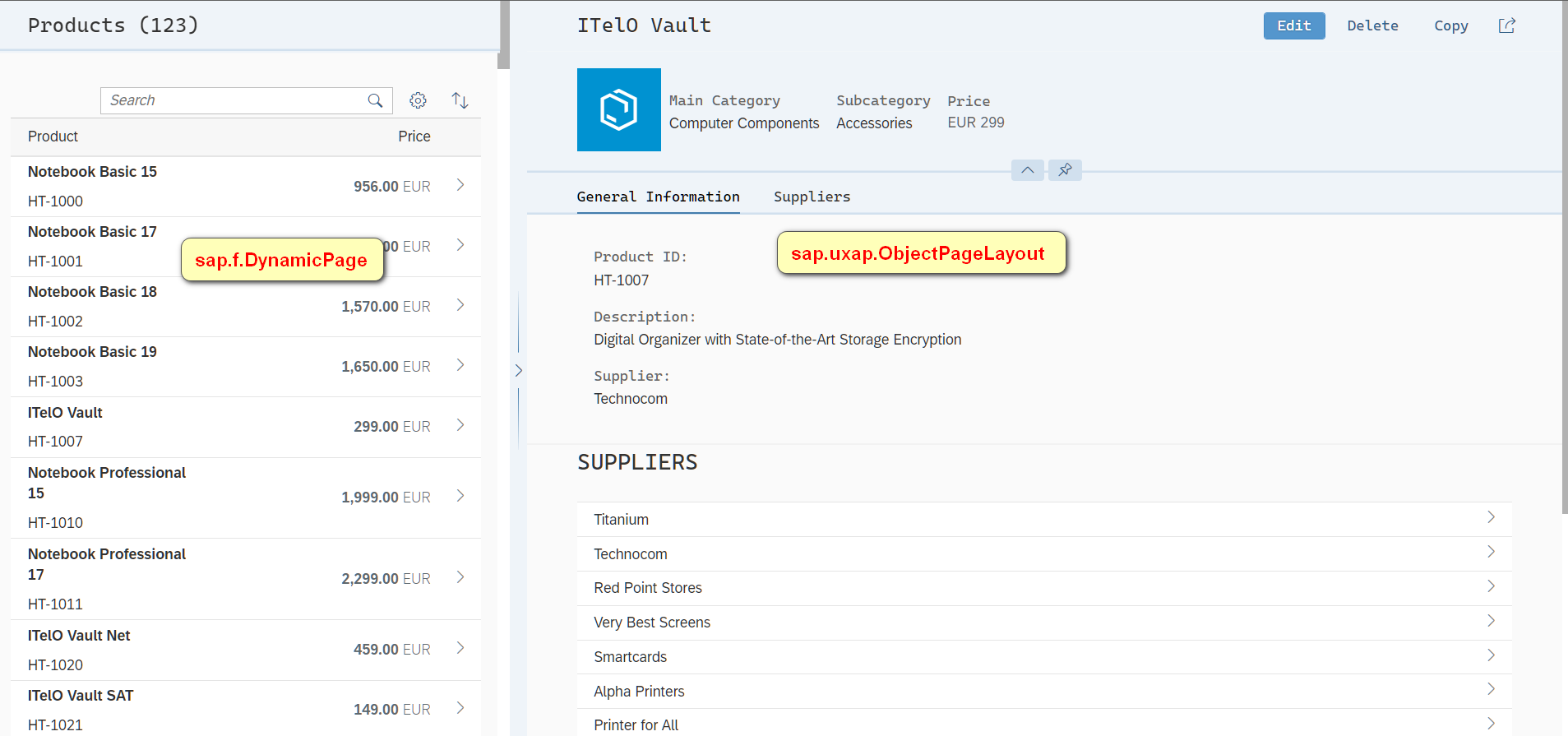
107. Some details of SAP ui5 overflow toolbar container control and resize event processing
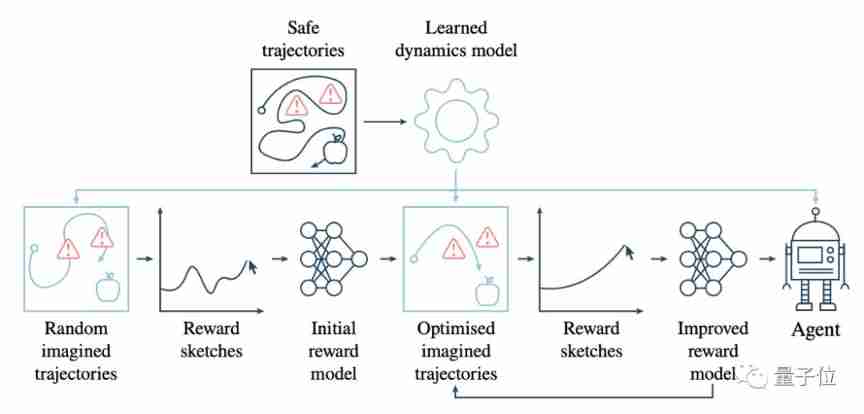
How to safely eat apples on the edge of a cliff? Deepmind & openai gives the answer of 3D security reinforcement learning

Inventory of more than 17 typical security incidents in January 2022

Wechat applet; Gibberish generator
随机推荐
Behind the cluster listing, to what extent is the Chinese restaurant chain "rolled"?
I was beaten by the interviewer because I didn't understand the sorting
微信小程序:星宿UI V1.5 wordpress系统资讯资源博客下载小程序微信QQ双端源码支持wordpress二级分类 加载动画优化
【大型电商项目开发】性能压测-优化-中间件对性能的影响-40
Redis(1)之Redis简介
Database postragesql client connection default
PHP 基础篇 - PHP 中 DES 加解密详解
Discrete mathematics: Main Normal Form (main disjunctive normal form, main conjunctive normal form)
流批一體在京東的探索與實踐
LeetCode周赛 + AcWing周赛(T4/T3)分析对比
FEG founder rox:smartdefi will be the benchmark of the entire decentralized financial market
PHP 约瑟夫环问题
如果消费互联网比喻成「湖泊」的话,产业互联网则是广阔的「海洋」
Hedhat firewall
[untitled]
Global and Chinese market of portable CNC cutting machines 2022-2028: Research Report on technology, participants, trends, market size and share
流批一体在京东的探索与实践
微信小程序:最新wordpress黑金壁纸微信小程序 二开修复版源码下载支持流量主收益
微信小程序:全新独立后台月老办事处一元交友盲盒
C basic knowledge review (Part 3 of 4)