01 Penser globalement
Mention de l'intégration des lots de flux,Il faut mentionner la traditionBig DataPlate - forme —— Lambda Architecture.Il peut soutenir efficacement les besoins de développement de données hors ligne et en temps réel,Mais le coût élevé du développement et de l'entretien et l'incohérence de l'ouverture des données causées par la rupture des deux liens de données entre le flux et le lot ne peuvent être ignorés.
Il est idéal de satisfaire simultanément les besoins de traitement des données des flux et des lots au moyen d'un ensemble de liaisons de données,C'est - à - dire:Flow Batch one.En outre, nous pensons qu'il y a quelques étapes intermédiaires dans l'intégration des lots de flux,Par exemple, il est important de réaliser l'unité de calcul seulement ou l'unité de stockage seulement.
Prenons l'exemple de la réalisation de l'unité de calcul seulement,Certaines applications de données nécessitent des exigences élevées en temps réel,.Par exemple, le traitement de bout en bout des données ne devrait pas être retardé de plus d'une seconde,C'est une paire de、S'adapter à un stockage unifié en tant que Lot de flux est un grand défi.Prenons l'exemple du lac Data,La visibilité de ses données est commit L'intervalle entre,Et puis Flink Fais - le. checkpoint L'intervalle de temps entre,Cette fonctionnalité combine la longueur de la liaison informatique,Il est évident que le traitement de bout en bout d'une seconde n'est pas facile.Donc pour ce genre de demande,Il est également possible de réaliser uniquement l'unité de calcul.Réduire les coûts de développement et d'entretien des utilisateurs en calculant uniformément,Résoudre le problème de l'incohérence du calibre des données.

Dans le processus de mise à la terre de la technologie Flow Batch , Les défis à relever peuvent se résumer comme suit: 4 Aspects:
- Le premier est le temps réel des données . Comment réduire le délai de données de bout en bout au niveau des secondes est un grand défi , Parce qu'il s'agit à la fois du moteur informatique et de la technologie de stockage . Il s'agit essentiellement d'un problème de performance , Et un objectif à long terme .
- Le deuxième défi consiste à assurer la compatibilité avec les capacités de traitement par lots hors ligne qui ont été largement utilisées dans le domaine du traitement des données. . Il s'agit ici de questions de développement et d'ordonnancement. , Le niveau de développement est principalement un problème de réutilisation , Comme comment réutiliser un modèle de données d'une table hors ligne existante , Comment réutiliser un développement personnalisé que l'utilisateur utilise déjà Hive UDF Attendez.. Le problème au niveau de l'ordonnancement est de savoir comment s'intégrer raisonnablement au système d'ordonnancement. .
- Le troisième défi est la question des ressources et du déploiement. . Par exemple, à travers différents types de flux 、 Déploiement hybride d'applications par lots pour améliorer l'utilisation des ressources ,Et comment metrics Pour construire une élasticité , Améliorer encore l'utilisation des ressources .
- Le dernier défi est le plus difficile. : Perception de l'utilisateur . La plupart des utilisateurs se limitent généralement à la communication ou à la validation de technologies relativement nouvelles. , Même si, après vérification, il semble que le problème réel peut être résolu , Il faut aussi attendre les bonnes affaires pour tester l'eau. . Cette question a également suscité quelques réflexions , Le côté plate - forme doit être plus du point de vue de l'utilisateur , Évaluer raisonnablement le coût des modifications apportées à l'architecture technique existante de l'utilisateur et les avantages pour l'utilisateur 、 Risque potentiel de migration des entreprises, etc. .
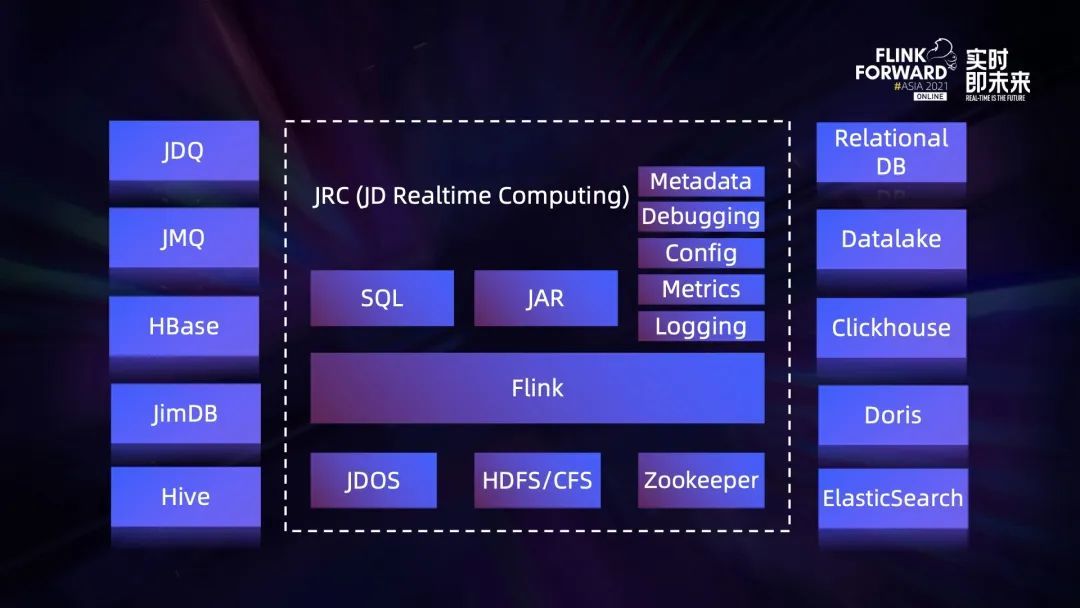
La figure ci - dessus est une vue d'ensemble de la plate - forme de calcul en temps réel de JD , C'est aussi notre vecteur pour réaliser la capacité d'intégration des lots de flux .Intermédiaire Flink Personnalisation approfondie basée sur la version communautaire Open Source . Cluster construit à partir de cette version , Les dépendances externes se composent de trois parties ,JDOS、HDFS/CFS Et Zookeeper.
- JDOS C'est à JD Kubernetes Plate - forme, Pour l'instant, tout ce que nous avons Flink Tâche de calcul Containerized , Tout fonctionne sur cette plate - forme ;
- Flink L'arrière - plan de l'état de HDFS Et CFS Deux options,Parmi eux CFS C'est le magasin d'objets de JD auto - étude ;
- Flink La disponibilité élevée des grappes est basée sur Zookeeper Construit.
En termes de développement d'applications ,Disponible sur la plateforme SQL Et Jar Deux façons d'emballer,Parmi eux Jar Les utilisateurs peuvent télécharger directement Flink Application Jar Package or provide Git L'adresse est emballée par la plateforme . En outre, notre fonction de plate - forme est relativement parfaite , Comme le Service de métadonnées de base 、SQL Fonction de mise en service, Le côté produit prend en charge toutes les configurations de paramètres ,Et basé sur metrics Surveillance、 Requête du Journal des tâches, etc. .
Connexion à la source de données ,La plateforme passe par connector Prise en charge des types de sources de données riches ,Parmi eux JDQ Open Source Kafka Sur mesure, File d'attente de messages principalement utilisée dans les scénarios de Big Data ;JMQ C'est l'auto - étude de JD , Files d'attente de messages principalement utilisées dans les systèmes en ligne ;JimDB Est distribué par JD Self - Research KV Stockage.

À l'heure actuelle Lambda Dans l'architecture, Supposons que les données de la liaison en temps réel soient stockées dans JDQ, Les données de la liaison hors ligne sont présentes Hive Dans le tableau, Même si le même modèle d'entreprise est calculé , Les métadonnées sont souvent définies différemment , Nous introduisons donc un modèle logique unifié pour la compatibilité des métadonnées des deux côtés de la ligne en temps réel. .
Dans la phase de calcul ,Adoption FlinkSQL Union UDF Pour réaliser un calcul unifié par lots de flux pour la logique d'entreprise , En outre, la plate - forme fournit un grand nombre de services publics UDF, Les utilisateurs peuvent également télécharger des personnalisations UDF. Résultats des calculs , Nous introduisons également un modèle logique unifié pour masquer les différences aux deux extrémités du lot de flux. . Pour les scénarios où seule l'unité de calcul est atteinte , Les résultats du calcul peuvent être écrits séparément dans le stockage correspondant du lot de flux. , Afin de garantir la cohérence des données en temps réel avec les données antérieures .
Pour les scénarios où l'unité de calcul et l'unité de stockage sont réalisées simultanément , Nous pouvons écrire les résultats de nos calculs directement dans le stockage unifié des lots de flux .Nous avons choisi Iceberg Stockage unifié en tant que Lot de flux , Parce qu'il a une bonne architecture , Comme ne pas se lier à un moteur particulier, etc. .
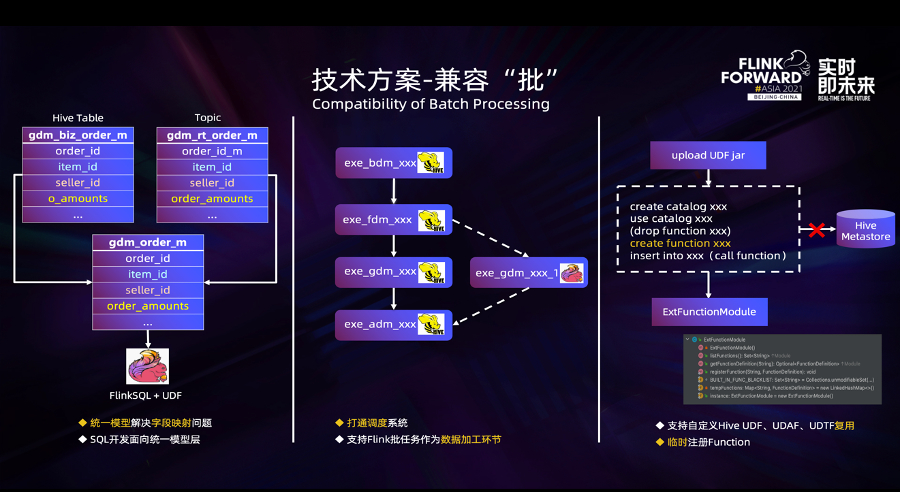
En termes de capacité de traitement par lots compatible , Nous avons principalement travaillé sur les trois aspects suivants :
Premièrement, Réutiliser les données hors ligne Hive Tableau.
Prenons l'exemple de la source de données , Pour protéger le courant moyen de la figure ci - dessus à gauche 、 Différences dans les métadonnées aux deux extrémités du lot , Nous avons défini le modèle logique gdm_order_m Tableau, Et nécessite une spécification affichée par l'utilisateur Hive Table et Topic Correspondance entre les champs de ce tableau logique et les champs de ce tableau logique . Il est important de cartographier ici la définition des relations ,Parce que basé sur FlinkSQL Il suffit de faire face à ce tableau logique , Sans se soucier de la réalité Hive Tableau et Topic Informations sur le terrain dans.Passage à l'exécution connector Lors de la création de tables de flux et de lots , Les champs du tableau logique sont remplacés par des champs réels par des relations cartographiques .
Côté produit, Nous pouvons lier les tables de flux et de lots aux tables logiques respectivement , Spécifiez la relation de cartographie entre les champs en faisant glisser . Ce modèle nous permet de développer différemment , Auparavant, créez une nouvelle tâche et spécifiez s'il s'agit d'une tâche de flux ou d'un lot. ,Et ensuite SQL Développement, Pour spécifier la configuration liée à la tâche , Dernière tâche de publication . Et en mode Stream Batch one , Le modèle de développement devient le premier SQL Développement, Cela inclut la logique 、Physique DDL Définitions, Et la spécification de la relation de cartographie des champs entre eux ,DML Préparation, etc. , Ensuite, spécifiez séparément les configurations liées aux tâches par lots de flux , Enfin, publier les deux tâches du lot de flux .
Deuxièmement, Connexion au système de répartition .
Le traitement des données de l'entrepôt de données hors ligne est basé sur Hive/Spark Mode de programmation combiné , Le graphique centré ci - dessus en est un exemple. , Le traitement des données est divisé en 4 Étapes, Correspondant respectivement à l'entrepôt de données BDM、FDM、GDM Et ADM Couche.Avec Flink Renforcement des capacités , L'utilisateur veut mettre GDM Les tâches de traitement des données pour la couche sont remplacées par FlinkSQL Tâches par lots pour ,Il faut mettre FlinkSQL Les tâches par lots sont intégrées dans le processus actuel de traitement des données , En tant que lien entre .
Pour résoudre ce problème, Configurer les règles d'ordonnancement en plus de la tâche elle - même , On a aussi branché le système de répartition , Hérite des dépendances de la tâche parent , Et synchroniser les informations de la tâche elle - même dans le système d'ordonnancement , Prise en charge des tâches en tant que parent des tâches en aval ,Pour réaliser FlinkSQL La tâche Batch pour le traitement des données brutes dans le cadre de .
Troisièmement, Personnalisé pour l'utilisateur Hive UDF、UDAF Et UDTF Multiplexage de.
Pour les bases existantes Hive Tâches d'usinage hors ligne pour , Si l'utilisateur a développé UDF Fonctions, La meilleure façon est de migrer Flink C'est vrai UDF Multiplexage direct ,Au lieu de suivre Flink UDF Définir la mise en œuvre .
In UDF Sur la compatibilité ,Pour utilisation Hive Scénarios avec fonctions intégrées ,La communauté a fourni load hive modules Programme. Si l'utilisateur souhaite utiliser un Hive UDF,Peut être réalisé en utilisant create catalog、use catalog、create function,Enfin, DML La méthode appelée dans pour implémenter , Ce processus Function Informations enregistrées auprès de Hive De Metastore Moyenne.Du point de vue de la gestion de la plateforme, Nous voulons que les utilisateurs UDF Avoir une certaine isolation ,Limiter les utilisateurs Job Taille des grains,Réduction par rapport à Hive Metastore Interaction et risque de génération de métadonnées de fonctions sales .
En outre, Lorsque les méta - informations ont été enregistrées , J'espère que la prochaine fois Flink Utilisation normale de la plate - forme ,Si non utilisé if not exist Syntaxe, D'habitude, il faut d'abord drop function,On recommence. create Fonctionnement. Mais ce n'est pas assez élégant. , Il y a aussi des limites à la façon dont les utilisateurs peuvent l'utiliser. . Une autre solution est que les utilisateurs peuvent s'inscrire temporairement Hive UDF,In Flink1.12 Inscription temporaire en UDF La façon dont create temporary function,Mais... Function Doit être réalisé UserDefinedFunction La vérification ultérieure ne peut être effectuée qu'après l'interface. ,Sinon, l'inscription échouera.
Donc nous n'utilisons pas create temporary function,C'est juste create function Quelques ajustements ont été apportés,étendu ExtFunctionModule,À analyser FunctionDefinition Inscrivez - vous à ExtFunctionModule Moyenne,J'ai fait ça une fois Job Inscription temporaire au niveau . L'avantage est qu'il n'y a pas de pollution Hive Metastore, Offre une bonne isolation , Il n'y a pas non plus de restrictions sur les habitudes d'utilisation des utilisateurs , Offre une bonne expérience .
Mais le problème est dans la communauté 1.13 La version de .Par l'introduction Hive Extension de l'analyseur, etc. , Peut déjà être réalisé UDF、GenericUDF Personnalisation de l'interface Hive La fonction passe par create temporary function Syntaxe pour l'enregistrement et l'utilisation .
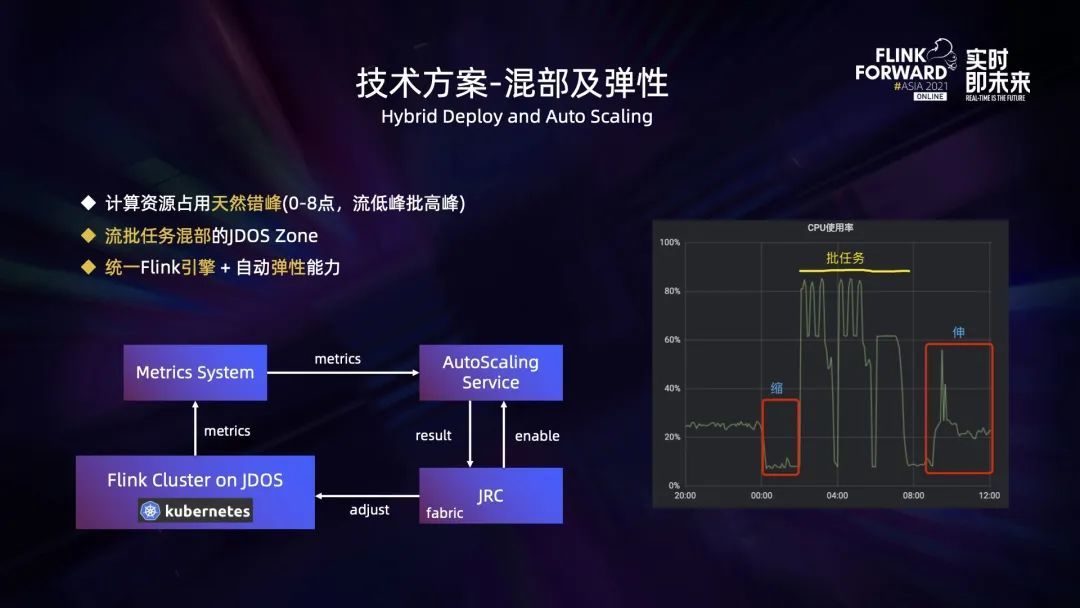
Occupation des ressources , Les débits et les lots sont naturellement décalés .Pour le traitement par lots, Entrepôt de données hors ligne tous les jours 0 Commencez à calculer les données de la dernière journée , Le traitement des données de tous les rapports hors ligne sera terminé avant le travail le lendemain. ,Donc d'habitude, 00:00 À 8:00 Est la période pendant laquelle la tâche de calcul par lots consomme beaucoup de ressources , Et le trafic en ligne est généralement faible pendant cette période . La charge de traitement du flux est positivement liée au trafic en ligne , Par conséquent, les besoins en ressources pour le traitement des flux au cours de cette période sont relativement faibles. .Matin 8 De midi à soir 0 Point, Le trafic en ligne est assez élevé , La plupart des tâches par lots de cette période ne sont pas déclenchées pour l'exécution .
Sur la base de ce pic naturel décalé , On peut le faire en JDOS Zone Différents types d'applications par lots de flux sont utilisés pour améliorer l'utilisation des ressources. , Et si elle est utilisée uniformément Flink Moteur pour traiter les applications par lots de flux , L'utilisation des ressources sera plus élevée .
En même temps, afin que l'application puisse être ajustée dynamiquement en fonction du débit , Nous avons également développé des services d'auto - élasticité (Auto-Scaling Service).Il fonctionne comme suit:: Fonctionnant sur la plateforme Flink Escalade des tâches metrics Message à metrics Système,Auto-Scaling Service Sera basé sur metrics Quelques indicateurs clés du système ,Par exemple, TaskManager De CPU Taux d'utilisation、 La contre - pression de la tâche détermine si la tâche doit augmenter ou diminuer les ressources de calcul. , Et transmettre les résultats des ajustements à JRC Plate - forme,JRC Plate - forme intégrée fabric Le client synchronise les résultats des ajustements vers JDOS Plate - forme,Pour compléter TaskManager Pod Ajustement du nombre .En outre,Les utilisateurs peuvent JRC La configuration sur la plateforme détermine si cette fonction est activée pour la tâche .
Le graphique de droite ci - dessus montre que nous sommes JDOS Zone Lors de l'essai pilote du Service d'expansion élastique CPU Utilisation.Je vois. 0 La tâche point Stream a été mise à l'échelle , Libérer des ressources pour les tâches par lots . Notre nouvelle mission est 2 Début de l'exécution,Donc de 2 Le temps commence à minuit et se termine le matin. ,CPU Le taux d'utilisation de ,Jusqu'à 80% Ci - dessus. Après l'exécution des tâches par lots , Quand le trafic en ligne a commencé à augmenter , La tâche Stream a été élargie ,CPU Le taux d'utilisation a également augmenté .
Pour plus de détails, voir:
https://blog.stackanswer.com/articles/2022/07/01/1656663988707.html