当前位置:网站首页>Speech recognition learning summary
Speech recognition learning summary
2022-07-05 08:30:00 【... Manmu mountains and rivers】
Learning summary
After a semester of study , Have a superficial understanding of the direction of speech recognition , Now I am writing this blog to sort out what I have learned , The content may be messy , But write it to yourself , It will be updated continuously in the future , Improve your professional level .
Speech recognition process
1. Traditional speech recognition
First, receive the sound through the microphone , Because sound is a kind of wave , Propagation by vibration , Sound waves will cause the vibration of microphone elements , Produce amplitudes of different sizes , It will also produce different current values , This converts analog signals into digital signals , A one-dimensional sequence signal in time domain , The waveform is drawn in the coordinate axis , Then the computer processes the waveform , Filter out useless information , Extract useful information , And produce a text sequence . The auditory mechanism of human ear is to distinguish sound through the frequency domain of sound , The waveforms produced when the pronunciation is similar may also be very different , Therefore, it is difficult to find the pronunciation rules from the waveform , The required waveform is further processed , Transform the waveform in time domain into the waveform in frequency domain through Fourier transform , Then the frequency domain features are processed , Learn rules from them . Because sound is a short-term stable signal , So in processing , Divide the sound into small segments and deal with them , It's a frame , It can be considered that the state of the sound in this short segment is unchanged . Then recognize these frames into corresponding states , Then several states are combined into a phoneme , Then combine the phonemes into the pronunciation of words , For example, in Chinese speech recognition , Phonemes correspond to the initials and finals of a word , Then predict the corresponding text with the pronunciation of the word , Splice the recognized text into a sentence , It completes one sentence speech recognition .
Usually complete the above traditional speech recognition process , Three independent models are needed , Namely :
1. Acoustic models , Recognize the frame as the corresponding state , Then three states are combined to form a phoneme
2. Articulation model , Combine phonemes into the pronunciation of the corresponding word
3. Language model , Predict the corresponding text according to the pronunciation of the word
These three models are trained independently , The training process is complicated , Therefore, it increases the entry difficulty of speech recognition .
2. End to end speech recognition
In recent years , Thanks to the development of neural network and the improvement of software and hardware technology , It has a large number of phonetic corpora , An end-to-end system . To simplify the network , Directly convert speech into text in a model , So this system is called end-to-end system . The general idea of end-to-end speech recognition , It uses a unified and optimized model to realize speech recognition , Simplify the training process of speech recognition , The input of the model is voice , The output is the corresponding text , The text here can be letters 、 Subwords or words . The main principles of end-to-end speech recognition include the use of CTC、RNN、Attention etc. .
The next task is , Read front end beamformer Code for , And how to prepare multi-channel data , Build a multi-channel speech recognition system baseline.
For the first time to use csdn Write an article ,markdown The user is not proficient , The typesetting is relatively simple , The content written is also relatively small , Continue to study and stick to csdn Write an article , Next time, I will write about the preparation process of multi-channel data .
边栏推荐
- 实例009:暂停一秒输出
- Weidongshan Internet of things learning lesson 1
- Working principle and type selection of common mode inductor
- 【三层架构及JDBC总结】
- STM32 --- GPIO configuration & GPIO related library functions
- Meizu Bluetooth remote control temperature and humidity access homeassistant
- 2020-05-21
- Negative pressure generation of buck-boost circuit
- leetcode - 445. 两数相加 II
- Example 004: for the day of the day, enter a day of a month of a year to judge the day of the year?
猜你喜欢
![[trio basic tutorial 17 from getting started to mastering] set up and connect the trio motion controller and input the activation code](/img/58/576b6b77509ed7a9bef138f3899e37.jpg)
[trio basic tutorial 17 from getting started to mastering] set up and connect the trio motion controller and input the activation code
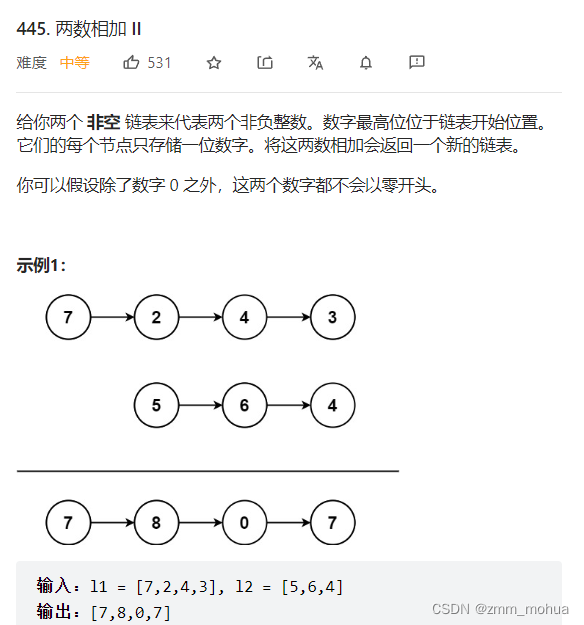
leetcode - 445. 两数相加 II
AttentiveNAS: Improving Neural Architecture Search via Attentive Sampling (未完)](/img/3b/c94b8466370f4461875c85b4f66860.png)
[NAS1](2021CVPR)AttentiveNAS: Improving Neural Architecture Search via Attentive Sampling (未完)
![[trio basic from introduction to mastery tutorial XIV] trio realizes unit axis multi-color code capture](/img/c5/22c6148873508b9205972e1ad970a3.jpg)
[trio basic from introduction to mastery tutorial XIV] trio realizes unit axis multi-color code capture
How to copy formatted notepad++ text?

实例004:这天第几天 输入某年某月某日,判断这一天是这一年的第几天?
Keil use details -- magic wand

每日一题——替换空格
Example 001: the number combination has four numbers: 1, 2, 3, 4. How many three digits can be formed that are different from each other and have no duplicate numbers? How many are each?

剑指 Offer 06. 从尾到头打印链表

随机推荐
Shell script
STM32 --- configuration of external interrupt
Example 008: 99 multiplication table
Several important parameters of LDO circuit design and type selection
On boost circuit
每日一题——替换空格
UE pixel stream, come to a "diet pill"!
Infected Tree(树形dp)
DCDC circuit - function of bootstrap capacitor
Simple design description of MIC circuit of ECM mobile phone
PIP installation
Semiconductor devices (III) FET
leetcode - 445. Add two numbers II
剑指 Offer 06. 从尾到头打印链表
实例009:暂停一秒输出
go依赖注入--google开源库wire
剑指 Offer 05. 替换空格
Bluetooth hc-05 pairing process and precautions
Classic application of MOS transistor circuit design (1) -iic bidirectional level shift
实例002:“个税计算” 企业发放的奖金根据利润提成。利润(I)低于或等于10万元时,奖金可提10%;利润高于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可提成7.