当前位置:网站首页>强化学习基础记录
强化学习基础记录
2022-07-06 09:22:00 【喜欢库里的强化小白】
强化学习的算法大致分为三类,value-based、policy-based和两者的结合Actor-Critic,这里简单写一下近期对AC的学习心得。
一、环境介绍
这里使用的是gym环境的’CartPole-v1’,该环境和上篇文章的’CartPole-v0’几乎没有什么区别,主要区别在于每个回合的最大步数和奖励的有关定义,如下图所示。
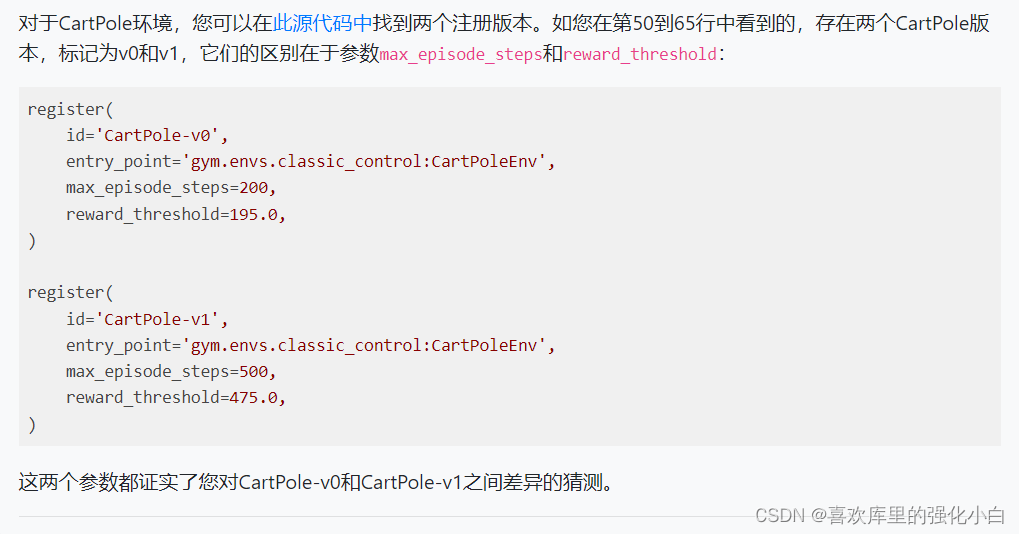
在本文中,想尝试结合On-Policy的算法,所以对单回合的的最大步数做了限制,大小为100。
'CartPole-v0’环境的详细介绍附上链接。
链接: OpenAI Gym 经典控制环境介绍——CartPole(倒立摆)
二、算法简单介绍
- Actor-Critic
该算法有两个框架,即策略相关的Actor网络和值相关的Critic网络。由于这里采用随机性策略,所以Actor网络利用了softmax函数将概率进行归一化;Critic为网络利用v值进行计算。此外,这里利用了A2C的优势函数(Advantage)。
- On-Policy
这里采取了On-Policy的算法,注意每回合100步游戏,会产生100条transition,待将这些transition存储之后,开始学习,直接利用这100个样本,并且将样本清空,以便下一回合获得新的样本。
- AC(A2C)伪代码:


- 实现
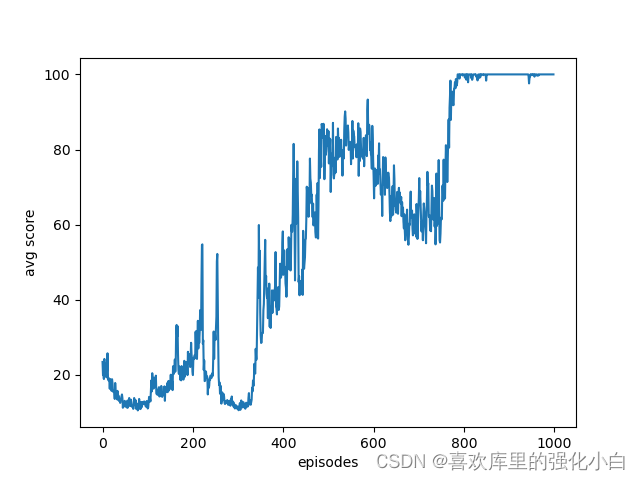
这里的实现参考了网上的教程,但是源代码只是Policy-Gradient的方法,这里进行了简单修改。此外,这里是随机性策略,本身就增加了探索性,不同于之前的确定性策略,用到了torch的抽样函数,具体还没研究。结果也附在下图,可以看到经过训练后,奖励基本上收敛到100。
import gym
import numpy
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
import matplotlib.pyplot as plt
# Hyperparameters
learning_rate = 0.0002
gamma = 0.98
n_rollout = 100
MAX_EPISODE = 20000
RENDER = False
env = gym.make('CartPole-v1')
env = env.unwrapped
env.seed(1)
torch.manual_seed(1)
#print("env.action_space :", env.action_space)
#print("env.observation_space :", env.observation_space)
n_features = env.observation_space.shape[0]
n_actions = env.action_space.n
class ActorCritic(nn.Module):
def __init__(self):
super(ActorCritic, self).__init__()
self.data = []
hidden_dims = 256
self.feature_layer = nn.Sequential(nn.Linear(n_features, hidden_dims),
nn.ReLU())
self.fc_pi = nn.Linear(hidden_dims, n_actions)
self.fc_v = nn.Linear(hidden_dims, 1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x):
x = self.feature_layer(x)
x = self.fc_pi(x)
prob = F.softmax(x, dim=-1)
return prob
def v(self, x):
x = self.feature_layer(x)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
s_lst, a_lst, r_lst, s_next_lst, done_lst = [], [], [], [], []
for transition in self.data:
s, a, r, s_, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r / 100.0])
s_next_lst.append(s_)
done_mask = 0.0 if done else 1.0
done_lst.append([done_mask])
s_batch, a_batch, r_batch, s_next_batch, done_batch = torch.tensor(numpy.array(s_lst),
dtype=torch.float), torch.tensor(
a_lst), torch.tensor(numpy.array(r_lst), dtype=torch.float), torch.tensor(
numpy.array(s_next_lst), dtype=torch.float), torch.tensor(
numpy.array(done_lst), dtype=torch.float)
self.data = []
return s_batch, a_batch, r_batch, s_next_batch, done_batch
def train_net(self):
s, a, r, s_, done = self.make_batch()
td_target = r + gamma * self.v(s_) * done
delta = td_target - self.v(s)
def critic_learn():
loss_func = nn.MSELoss()
loss1 = loss_func(self.v(s),td_target)
self.optimizer.zero_grad()
loss1.backward()
self.optimizer.step()
def actor_learn():
pi = self.pi(s)
pi_a = pi.gather(1, a)
loss = -torch.log(pi_a) * delta.detach() + F.smooth_l1_loss(self.v(s), td_target.detach())
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
critic_learn()
actor_learn()
def main():
model = ActorCritic()
print_interval = 20
score = 0.0
avg_returns = []
for n_epi in range(MAX_EPISODE):
s = env.reset()
for t in range(n_rollout):
prob = model.pi(torch.from_numpy(s).float())
m = Categorical(prob)
a = m.sample().item()
s_next, r, done, info = env.step(a)
model.put_data((s, a, r, s_next, done))
s = s_next
score += r
model.train_net()
if n_epi % print_interval == 0 and n_epi != 0:
avg_score = score / print_interval
print("# of episode :{}, avg score : {:.1f}".format(n_epi, score / print_interval))
avg_returns.append(avg_score)
score = 0.0
env.close()
plt.figure()
plt.plot(range(len(avg_returns)),avg_returns)
plt.xlabel('episodes')
plt.ylabel('avg score')
plt.savefig('./plt_ac.png',format= 'png')
if __name__ == '__main__':
main()
边栏推荐
- Thoroughly understand LRU algorithm - explain 146 questions in detail and eliminate LRU cache in redis
- About the parental delegation mechanism and the process of class loading
- (original) make an electronic clock with LCD1602 display to display the current time on the LCD. The display format is "hour: minute: Second: second". There are four function keys K1 ~ K4, and the fun
- 仿牛客技术博客项目常见问题及解答(二)
- 7-14 错误票据(PTA程序设计)
- 4. Branch statements and loop statements
- Using spacedesk to realize any device in the LAN as a computer expansion screen
- 强化学习系列(一):基本原理和概念
- Zatan 0516
- 1. First knowledge of C language (1)
猜你喜欢

仿牛客技术博客项目常见问题及解答(二)

优先队列PriorityQueue (大根堆/小根堆/TopK问题)
编写程序,模拟现实生活中的交通信号灯。
Read only error handling
7-5 走楼梯升级版(PTA程序设计)
扑克牌游戏程序——人机对抗
仿牛客技术博客项目常见问题及解答(三)
4. Binary search
(original) make an electronic clock with LCD1602 display to display the current time on the LCD. The display format is "hour: minute: Second: second". There are four function keys K1 ~ K4, and the fun
![[dark horse morning post] Shanghai Municipal Bureau of supervision responded that Zhong Xue had a high fever and did not melt; Michael admitted that two batches of pure milk were unqualified; Wechat i](/img/d7/4671b5a74317a8f87ffd36be2b34e1.jpg)
[dark horse morning post] Shanghai Municipal Bureau of supervision responded that Zhong Xue had a high fever and did not melt; Michael admitted that two batches of pure milk were unqualified; Wechat i
随机推荐
【黑马早报】上海市监局回应钟薛高烧不化;麦趣尔承认两批次纯牛奶不合格;微信内测一个手机可注册俩号;度小满回应存款变理财产品...
【毕业季·进击的技术er】再见了,我的学生时代
Wechat applet
Miscellaneous talk on May 27
实验五 类和对象
The latest tank battle 2022 full development notes-1
实验四 数组
[au cours de l'entrevue] - Comment expliquer le mécanisme de transmission fiable de TCP
FAQs and answers to the imitation Niuke technology blog project (II)
Why use redis
甲、乙机之间采用方式 1 双向串行通信,具体要求如下: (1)甲机的 k1 按键可通过串行口控制乙机的 LEDI 点亮、LED2 灭,甲机的 k2 按键控制 乙机的 LED1
2. Preliminary exercises of C language (2)
【九阳神功】2019复旦大学应用统计真题+解析
Brief introduction to XHR - basic use of XHR
Safe driving skills on ice and snow roads
5月14日杂谈
Have you encountered ABA problems? Let's talk about the following in detail, how to avoid ABA problems
记一次猫舍由外到内的渗透撞库操作提取-flag
7. Relationship between array, pointer and array
力扣152题乘数最大子数组