当前位置:网站首页>7.正则化应用
7.正则化应用
2022-07-07 23:12:00 【booze-J】
一、正则化的应用
在6.Dropout应用中的未使用Dropout的代码的网络模型构建中添加正则化。
将6.Dropout应用中的
# 创建模型 输入784个神经元,输出10个神经元
model = Sequential([
# 定义输出是200 输入是784,设置偏置为1,添加softmax激活函数 第一个隐藏层有200个神经元
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
# 第二个隐藏层有 100个神经元
Dense(units=100,bias_initializer='one',activation="tanh"),
Dense(units=10,bias_initializer='one',activation="softmax")
])
修改为
# 创建模型 输入784个神经元,输出10个神经元
model = Sequential([
# 定义输出是200 输入是784,设置偏置为1,添加softmax激活函数 第一个隐藏层有200个神经元
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh",kernel_regularizer=l2(0.0003)),
# 第二个隐藏层有 100个神经元
Dense(units=100,bias_initializer='one',activation="tanh",kernel_regularizer=l2(0.0003)),
Dense(units=10,bias_initializer='one',activation="softmax",kernel_regularizer=l2(0.0003))
])
使用l2正则化之前需要先导入from keras.regularizers import l2。
运行结果: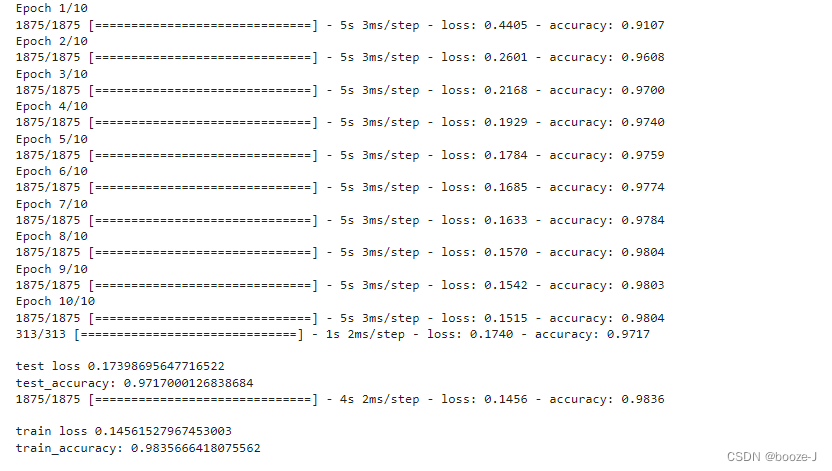
从运行结果可以看出来明显克服了一些过拟合的情况,模型对于数据集不是很复杂,加上正则化的话,它的效果可能就不是很好。
完整代码
代码运行平台为jupyter-notebook,文章中的代码块,也是按照jupyter-notebook中的划分顺序进行书写的,运行文章代码,直接分单元粘入到jupyter-notebook即可。
1.导入第三方库
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from keras.regularizers import l2
2.加载数据及数据预处理
# 载入数据
(x_train,y_train),(x_test,y_test) = mnist.load_data()
# (60000, 28, 28)
print("x_shape:\n",x_train.shape)
# (60000,) 还未进行one-hot编码 需要后面自己操作
print("y_shape:\n",y_train.shape)
# (60000, 28, 28) -> (60000,784) reshape()中参数填入-1的话可以自动计算出参数结果 除以255.0是为了归一化
x_train = x_train.reshape(x_train.shape[0],-1)/255.0
x_test = x_test.reshape(x_test.shape[0],-1)/255.0
# 换one hot格式
y_train = np_utils.to_categorical(y_train,num_classes=10)
y_test = np_utils.to_categorical(y_test,num_classes=10)
3.训练模型
# 创建模型 输入784个神经元,输出10个神经元
model = Sequential([
# 定义输出是200 输入是784,设置偏置为1,添加softmax激活函数 第一个隐藏层有200个神经元
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh",kernel_regularizer=l2(0.0003)),
# 第二个隐藏层有 100个神经元
Dense(units=100,bias_initializer='one',activation="tanh",kernel_regularizer=l2(0.0003)),
Dense(units=10,bias_initializer='one',activation="softmax",kernel_regularizer=l2(0.0003))
])
# 定义优化器
sgd = SGD(lr=0.2)
# 定义优化器,loss_function,训练过程中计算准确率
model.compile(
optimizer=sgd,
loss="categorical_crossentropy",
metrics=['accuracy']
)
# 训练模型
model.fit(x_train,y_train,batch_size=32,epochs=10)
# 评估模型
# 测试集的loss和准确率
loss,accuracy = model.evaluate(x_test,y_test)
print("\ntest loss",loss)
print("test_accuracy:",accuracy)
# 训练集的loss和准确率
loss,accuracy = model.evaluate(x_train,y_train)
print("\ntrain loss",loss)
print("train_accuracy:",accuracy)
边栏推荐
- 【obs】Impossible to find entrance point CreateDirect3D11DeviceFromDXGIDevice
- 第四期SFO销毁,Starfish OS如何对SFO价值赋能?
- Play sonar
- 第一讲:链表中环的入口结点
- 大二级分类产品页权重低,不收录怎么办?
- 服务器防御DDOS的方法,杭州高防IP段103.219.39.x
- Cascade-LSTM: A Tree-Structured Neural Classifier for Detecting Misinformation Cascades(KDD20)
- 8道经典C语言指针笔试题解析
- 玩轉Sonar
- Class head up rate detection based on face recognition
猜你喜欢

They gathered at the 2022 ecug con just for "China's technological power"
Service mesh introduction, istio overview
QT adds resource files, adds icons for qaction, establishes signal slot functions, and implements
Letcode43: string multiplication
Installation and configuration of sublime Text3

第四期SFO销毁,Starfish OS如何对SFO价值赋能?
Cve-2022-28346: Django SQL injection vulnerability
How does the markdown editor of CSDN input mathematical formulas--- Latex syntax summary
Binder core API

13.模型的保存和載入
随机推荐
串口接收一包数据
They gathered at the 2022 ecug con just for "China's technological power"
第四期SFO销毁,Starfish OS如何对SFO价值赋能?
Basic principle and usage of dynamic library, -fpic option context
Introduction to paddle - using lenet to realize image classification method I in MNIST
Vscode software
Cause analysis and solution of too laggy page of [test interview questions]
Semantic segmentation model base segmentation_ models_ Detailed introduction to pytorch
AI遮天传 ML-回归分析入门
Installation and configuration of sublime Text3
Handwriting a simulated reentrantlock
LeetCode刷题
8.优化器
letcode43:字符串相乘
Summary of weidongshan phase II course content
Implementation of adjacency table of SQLite database storage directory structure 2-construction of directory tree
大二级分类产品页权重低,不收录怎么办?
Password recovery vulnerability of foreign public testing
深潜Kotlin协程(二十二):Flow的处理
ReentrantLock 公平锁源码 第0篇