当前位置:网站首页>CSDN question and answer tag skill tree (II) -- effect optimization
CSDN question and answer tag skill tree (II) -- effect optimization
2022-07-06 10:42:00 【Alexxinlu】
Catalog
Series articles
- CSDN Q & a tag skill tree ( One ) —— Construction of basic framework
- CSDN Q & a tag skill tree ( Two ) —— Effect optimization
- CSDN Q & a tag skill tree ( 3、 ... and ) —— Python The skill tree
- CSDN Q & a tag skill tree ( Four ) —— Java The skill tree
- CSDN Q & a tag skill tree ( 5、 ... and ) —— Cloud native skill tree
Team blog : CSDN AI team
1. The problem background
This article continues from the previous article 《CSDN Q & a tag skill tree ( One ) —— Construction of basic framework 》. In short , It's right CSDN Each field label in the question and answer module , Build a complete knowledge system , And the content in the question and answer module 、 The user etc. , Relate to the knowledge system , Finally, a map containing heterogeneous nodes is formed , Better for downstream NLP Tasks provide a resource base .
This article mainly introduces the optimization of skill tree structure , And the effect optimization of matching the question and answer content with the skill tree .
2. Skill tree optimization
This chapter mainly includes two parts , One is the optimization of skill tree structure , The other is to optimize the effect of matching the question and answer content with the skill tree .
The skill tree has been expanded to 16 Languages , But due to the poor effect , Therefore, the current focus is on 2 Plant in CSDN Q & a module is a popular programming language Python and Java, And now a popular concept Cloud native , The concept contains multiple tags , It is a large knowledge field .
2.1 Skill tree structure optimization
The structure of skill tree mainly has two requirements , One is that the coverage of knowledge should be complete , Another is the need for a hierarchy .
2.1.1 Knowledge coverage
The coverage of knowledge is Last article 2.1 section It has been mentioned in , The construction of skill tree is mainly realized by crawling the directory of books and the directory of learning forums .
In this update , I crawled more book catalogs , Used to expand the coverage of knowledge . In the future, we will continue to expand more knowledge , And we will also consider adding the function of user editing , Let users edit and add knowledge points .
2.1.2 Hierarchy
Knowledge is divided into junior high school and senior high school , With python Language as an example , There is a preliminary knowledge skeleton as shown below :
python
├── The first step
│ ├── Preliminary knowledge
│ ├── Basic grammar
│ ├── Advanced Grammar
│ └── object-oriented programming
├── Middle stage
│ ├── Basic skills
│ ├── Web application development
│ ├── Web crawler
│ └── Desktop application development
└── Higher order
├── Basic software package of scientific computing NumPy
├── Structured data analysis tools Pandas
├── Drawing library Matplotlib
├── Scientific computing Toolkit SciPy
├── Machine learning kits Scikit-learn
├── Deep learning
├── Computer vision
└── natural language processing
In order to make the knowledge system have a hierarchical structure , The idea of this article is : First, we will build a knowledge skeleton as shown in the above figure , Then split and integrate the directories of all the books or learning forums obtained , Hang it on the corresponding node on the skeleton . for example : For a book python introduction Books , Split its directory and hang it in the skeleton The first step On the corresponding node , If the skeleton does not cover relevant knowledge points , Then add a new node , If there is redundancy in the newly added knowledge points , There is no need to hang it on the skeleton .
In the specific implementation stage , The current strategy is relatively simple , It's only through manual assignment , Hang the directory on the corresponding level node , As shown below :
The first step --> using_python
The first step --> tutorial_python
The first step --> reference_python
The first step --> library_python
The first step --> liaoxuefeng_python
The first step --> Python Basic course _ The first 3 edition
The first step --> Python Programming fast _ Automate tedious work _ The first 2 edition
The first step --> smooth Python
The first step --> Python Programming _ From introduction to practice _ The first 2 edition
The first step --> Python From entry to mastery
The first step --> Python_Cookbook_ The first 3 edition
Middle stage --> Python Advanced Programming
Middle stage --> Python Programming core _ The first 3 edition
Middle stage --> Python Geek project programming
Middle stage --> Flask_Web Development _ be based on Python Of Web Application development practice _ The first 2 edition
Middle stage --> Web crawler --> Python3 Web crawler development practice
Higher order --> Python3 Advanced tutorials _ The first 3 edition
Higher order --> Python Basis of data analysis
Higher order --> utilize Python Data analysis _ The book first 2 edition
Higher order --> Python Advanced data analysis : machine learning 、 Deep learning and NLP example
Higher order --> Computer vision --> Practical convolutional neural network : Application Python Implement advanced deep learning model
Later, we will consider using Decision tree The idea of algorithm building tree , To build a tree with less redundancy , Skill tree with more reasonable structure .
2.2 Optimization of matching algorithm
After building the skill tree , The questions adopted in the Q & a module need to be , Based on Matching Algorithm , Hang it on the corresponding node , As the data resource of this node . For users' new questions , Based on Matching Algorithm , Recommend the adopted problems on the most relevant nodes to users , It is further recommended that users learn relevant knowledge adjacent to the node on the skill tree .
2.2.1 Optimization of matching algorithm
stay Last article 2.4 section in , Only the leaf node of the skill tree and the question title are used to match , This method has the following defects :
- The ancestor nodes of leaf nodes also contain a lot of useful information , Using only leaf nodes will lose ancestral information ;
- Some users' questions are not specific to the leaf nodes that are described in great detail , It may be an overview of a large class of non leaf nodes ;
- English keywords play a vital role in matching , Need to focus on .
Therefore, in view of the above problems , The matching algorithm is improved as follows :
- Get the path set of all nodes in the skill tree . Path refers to the path from the root node to the current node ;
- Calculate the similarity between the question title and all paths . Because the last node in the path is the node to be matched , And the larger the number of layers, the more accurate the description of nodes , More information . So when calculating the similarity , The weight of the node is given according to the layer number of the node in the path , The larger the floor number , The greater the weight ;
- When the match , Increase the weight of English keywords .
Besides , Because the path is long and short , The above algorithm will be more inclined to match shorter paths , The longer path gets the lower score , So the final score , Normalization is required based on the length of the path . The specific code implementation is as follows :
def get_most_sim_node_paths_to_leaves(self, all_paths_to_leaves, node_id_seg_dict, query, lang):
''' Calculate the scores of user question titles and all paths in the skill tree '''
# first floor ( Programming language name ) And the second node ( Subdirectory name ) meaningless
max_path_len = max([len(m_path) for m_path in all_paths_to_leaves]) - 2
# Yes query Carry out word segmentation
query_seg = word_segmentation(query)
# Remove the name of the current programming language
lang_syn_name_list = lang_std_syn_dict[lang]
query_seg = [m_word for m_word in query_seg if m_word not in lang_syn_name_list]
result = {
'score': 0, 'path_to_leaf': []}
for ori_path_to_leaf in all_paths_to_leaves:
# first floor ( Programming language name ) And the second node ( Subdirectory name ) meaningless
path_to_leaf = ori_path_to_leaf[2:]
score_list = []
num_nodes = len(path_to_leaf)
if num_nodes == 0:
continue
for m_node_id in path_to_leaf:
# Calculate the similarity of two word sequences
sim_score, _, _ = cal_simlarity(node_id_seg_dict[m_node_id], query_seg, lcs_ratio_threshold=0, alpha=0)
score_list.append(sim_score)
# On the path from root node to leaf node , After removing the tail, the score is 0 Of , Sub path to leaf node
score_list.reverse()
non_zero_index = 0
for m_index, sim_score in enumerate(score_list):
if sim_score != 0:
non_zero_index = m_index
break
score_list = score_list[non_zero_index :]
score_list.reverse()
# If there is intersection and union ratio 1 The node of , Then directly return the path from the root node to the node
value_one_flag = False
value_one_index_list = [m_index for m_index, sim_score in enumerate(score_list) if sim_score == 1]
if len(value_one_index_list) != 0:
value_one_index = value_one_index_list[-1]
score_list = score_list[: value_one_index + 1]
value_one_flag = True
# The weight given to the node according to the layer number , Also consider the length of the path
num_nodes = len(score_list)
final_score = 0.0
denominator = (1.0 + num_nodes) * num_nodes / 2
for m_index, m_score in enumerate(score_list):
floor_score = (m_index + 1) / denominator
final_score += m_score * floor_score
path_len_score = num_nodes / max_path_len
final_score *= path_len_score
if final_score > result['score']:
result['score'] = final_score
result['path_to_leaf'] = ori_path_to_leaf[: num_nodes + 2]
if value_one_flag:
result['score'] = final_score
result['path_to_leaf'] = ori_path_to_leaf[: num_nodes + 2]
break
return result
2.2.2 Pretreatment optimization
This task mainly involves the matching of node description and user questions , And the existence of stop words , And the quality of keywords , Will affect the matching effect , Therefore, it is necessary to aim at the specific characteristics of the task , Carry out appropriate pretreatment operations , Only keep high-quality keywords , And then improve the matching effect .
Besides , Users' questions are more colloquial , The description of nodes in the skill tree is more written , When matching, just remove the stop words of one party , Therefore, this paper only analyzes the description of nodes in the skill tree , This greatly reduces the workload of preprocessing operations .
Stop word filtering
Previously, only a few recognized stop word dictionaries on the Internet were used to filter stop words , But the tasks in specific fields are not enough . After analyzing the data , Find some words with specific parts of speech , It has little effect on the task , It mainly includes the following parts of speech :pos Chinese name c Conjunction e interjection h Prefix k suffix m numeral o an onomatopoeia p Preposition r pronouns u auxiliary word w Punctuation x character string y Statement label designator z State words p.s. All parts of speech beginning with the above initials are counted
For both valid words , It also includes the part of speech of stop words , Through the statistics + The method of manual screening , Find out the high-frequency stop words , Add to the stop phrase dictionary , Total additions 159 Stop words , As shown in the following table :
The first 1 Column The first 2 Column The first 3 Column The first 4 Column in Item in Novice modern more Less than New people In the near future fast Class time Vegetable dog At present finger Adorable new rookie Be overdue in solve Vegetable chicken need front Equipped with brother Use help Just in master Three big look for This is a self-taught Stop words hand predecessors thank you — pit a string thank Which ones when request Brother Can't find Add just Homework Meng Xingang learn At least Crazy Just entered the pit Just. trouble teacher The same ask answer Be really something Next month, thank emergency ! This question Help Next Urgent demand subject Look not to understand On Rescue Source code Ah ah after uncle Problem. Online, etc. Inside emergency Between It's too hard Outside Help Easy to Family between Please Trivial brothers new Ball huge one's junior of equal standing used For help appropriate This question Big Ask for advice mysterious This question Small Beg Bizarre Examination questions First A great god complete A question take bosses best Source code not Instruction again Programming questions No Give directions Simple convert to most The small white complex How to write the question still children correct How to solve the problem can Help error Source code yes Help direct haha Yes brother indirect curriculum design to want to sister Commonly used Fundamentally Lieutenant general Younger sister all Everything is Beginners Youngest sister Ignore notorious close The younger brother more unique How many? eldest brother A certain Based on part of speech bigram phrase
For words incorrectly segmented by the word splitter , Merge bigram phrase , And bigram The meaning is clearer , It can improve the accuracy of matching . To be specific , According to the part of speech , Splice adjacent words , Form larger phrase units . By observing the data , Get the following common part of speech combinations that need to be spliced :first pos second pos d q d v d n f q h n h v h a n k n n n q n s p.s. All parts of speech beginning with the above initials are counted
2.2.3 Add other class nodes
Some users' questions have gone beyond the current field , Or it is difficult to exhaust on the skill tree , Therefore, another node of other classes is added , Used to match this kind of problem . For example, for Python label , Other class nodes , It is subdivided into the following three categories :
others
├── Other category label problems
├── Application problems
├── Third party package problem
The judgment of other problems is mainly realized by rules , For the above three kinds of problems , The following rules :
- Other category label problems
Does not contain the current domain label , But the question title contains labels of other fields .
- Application problems
re.compile(r'(( how | Yes? ).*?( Calculation | Realization | Make )| practice | subject )')
- Third party package problem
re.compile(r'( tool kit |(?: The third party |[a-z]+?) library |py(?!thon)[a-z0-9]+| install [a-z0-9]+|[a-z0-9]+ Installation )')
2.3 Match effect
After the above optimization , The specific effect improvement is as follows , The evaluation standard used is the accuracy (Accuracy).
| Domain label | baseline | now |
|---|---|---|
| Python | 54% | 78% |
| Java | 57% | 82% |
| Cloud native | - | - |
p.s. Because there is less valid data native to the cloud , Therefore, the data set has not been built , And test the effect .
3. Summary and next step plan
The skill tree already supports 16 Tree , This article focuses on optimizing Python、Java、 Cloud native Skill tree of three domain labels , It mainly includes the optimization of skill tree structure , And the optimization of matching algorithm .
Next step :
- The skill tree structure is further upgraded : reference Decision tree The idea of algorithm building tree , To build a tree with less redundancy , Skill tree with more reasonable structure ;
- Construction of cloud native data resources ;
- Expand other types of data resources . Currently, only question and answer data resources are used , We will consider using CSDN Heterogeneous data resources of other modules , Include : Blog 、 Course 、 video 、 special column 、 User favorites etc. .
Related links
- IT Talent growth roadmap
- Various skill trees
- Summarize and sort out skill trees in various fields of artificial intelligence
P.S.
This series of articles will be continuously updated . hope NLP Colleagues in other fields 、 Teachers and experts can provide valuable advice , thank you !
边栏推荐
- Ueeditor internationalization configuration, supporting Chinese and English switching
- API learning of OpenGL (2003) gl_ TEXTURE_ WRAP_ S GL_ TEXTURE_ WRAP_ T
- Anaconda3 installation CV2
- Not registered via @EnableConfigurationProperties, marked(@ConfigurationProperties的使用)
- Pytorch LSTM实现流程(可视化版本)
- 使用OVF Tool工具从Esxi 6.7中导出虚拟机
- 基于Pytorch肺部感染识别案例(采用ResNet网络结构)
- CSDN问答标签技能树(一) —— 基本框架的构建
- MySQL28-数据库的设计规范
- MySQL combat optimization expert 02 in order to execute SQL statements, do you know what kind of architectural design MySQL uses?
猜你喜欢
IDEA 导入导出 settings 设置文件
Mysql25 index creation and design principles
Mysql28 database design specification

Super detailed steps to implement Wechat public number H5 Message push
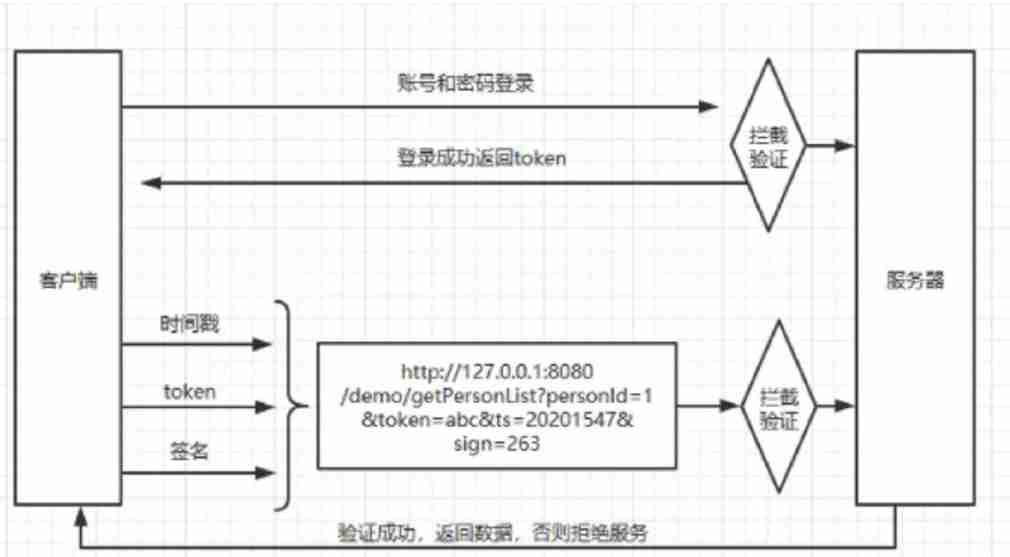
Security design verification of API interface: ticket, signature, timestamp

Win10: how to modify the priority of dual network cards?
该不会还有人不懂用C语言写扫雷游戏吧
Record the first JDBC
CSDN问答模块标题推荐任务(一) —— 基本框架的搭建
基于Pytorch肺部感染识别案例(采用ResNet网络结构)
随机推荐
Adaptive Bezier curve network for real-time end-to-end text recognition
Google login prompt error code 12501
MySQL23-存储引擎
Just remember Balabala
Anaconda3 安装cv2
Security design verification of API interface: ticket, signature, timestamp
Mysql27 index optimization and query optimization
Global and Chinese market of wafer processing robots 2022-2028: Research Report on technology, participants, trends, market size and share
MySQL learning diary (II)
PyTorch RNN 实战案例_MNIST手写字体识别
Introduction tutorial of typescript (dark horse programmer of station B)
MySQL29-数据库其它调优策略
UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd0 in position 0成功解决
Bytetrack: multi object tracking by associating every detection box paper reading notes ()
Moteur de stockage mysql23
Valentine's Day is coming, are you still worried about eating dog food? Teach you to make a confession wall hand in hand. Express your love to the person you want
Use of dataset of pytorch
该不会还有人不懂用C语言写扫雷游戏吧
Super detailed steps to implement Wechat public number H5 Message push
MySQL24-索引的数据结构