author :IT Wang Xiaoer
Blog :https://itwxe.com
Here are some commonly used in work SQL Summary of performance optimization techniques , Including ten common optimization experiences 、order by And group by Optimize 、 Paging query optimization 、join Association query optimization 、in and exsits Optimize 、count(*) Query optimization .
One 、 Ten common optimization experiences
In fact, this ten experience is not necessarily accurate , Through the previous article MySQL Further implementation of the plan trace Tools We already know MySQL Cost analysis will be performed when executing query statements , The amount of data and actual data values will affect MySQL Actual query process , So don't be surprised if the partners find that they are different from those in the sophomore's article after writing according to these ten common experiences .
therefore ... Sophomore has been struggling for a long time. Do you want to write this SQL Ten common optimization experiences , After all, many of these blogs have mentioned , Wanted to think , Let's write it down .
-- Sample table
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT ' full name ',
`age` int(11) NOT NULL DEFAULT '0' COMMENT ' Age ',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT ' Position ',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ' Entry time ',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT=' Employee record form ';
INSERT INTO employees(name,age,position,hire_time) VALUES('itwxe',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('weiwei', 23,'test',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('leilei',23,'dev',NOW());
-- Insert 10w Bar test data
drop procedure if exists insert_employees;
delimiter $$
create procedure insert_employees()
begin
declare i int;
set i = 1;
while(i <= 100000)do
insert into employees(name, age, position) values(CONCAT('itwxe', i), rand() * 42 + 18, 'dev');
set i = i + 1;
end while;
end$$
delimiter ;
call insert_employees();
1. Try to match as much as possible
explain select * from employees where name = 'itwxe';
explain select * from employees where name = 'itwxe' and age = 22;
explain select * from employees where name = 'itwxe' and age = 22 and position = 'manager';
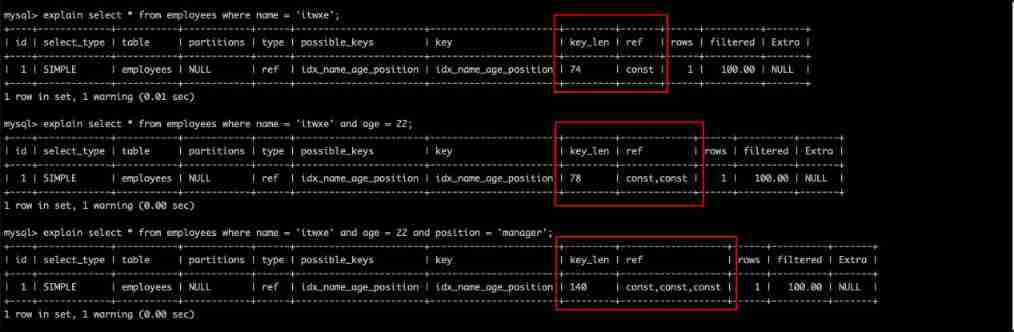
Remember these three key_len Value ,idx_name_age_position (name,age,position) It consists of these three fields ,74 Representative used name Column ;78 Representative used name,age Column ;140 Representative used name,age,position Column .
2. Leftmost prefix principle
Pay special attention to the leftmost prefix principle when using joint index , That is, query from Joint index Start at the top left of the index and don't skip columns in the index .
explain select * from employees where name = 'itwxe' and age = '18';
explain select * from employees where name = 'itwxe' and position = 'manager';
explain select * from employees where position = 'manager';
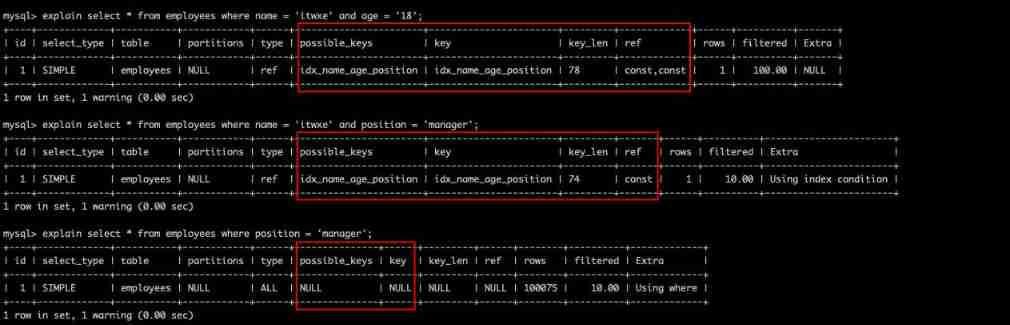
It should also be easy to understand , However, it should be noted that and query SQL The order of writing is irrelevant , The leftmost point is The order of columns when a federated index is created . for example where In reverse order, you will still use idx_name_age_position (name,age,position) Three column index queries in .
explain select * from employees where name = 'itwxe' and age = 22 and position = 'manager';
explain select * from employees where age = 22 and position = 'manager' and name = 'itwxe';
explain select * from employees where position = 'manager' and name = 'itwxe' and age = 22;
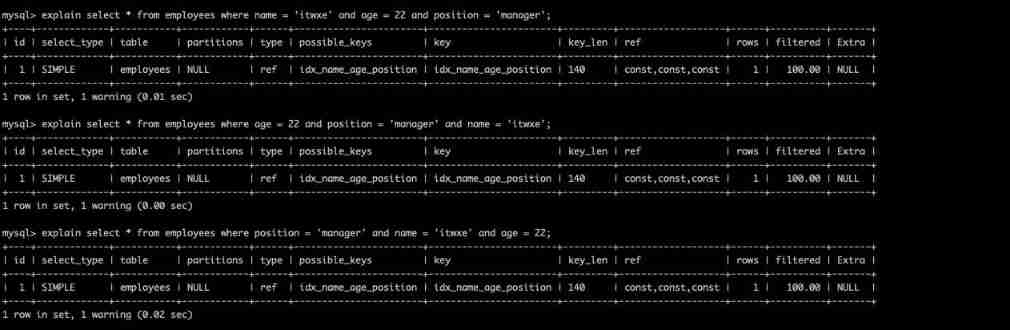
You can see that even if the order is reversed , The implementation plan of the three is the same .
3. Do nothing on the index column ( Calculation 、 function 、( Automatically / Manual ) Type conversion ), It will cause index invalidation and turn to full table scan
It should be noted that the index column mentioned here does not operate ( Calculation 、 function 、( Automatically / Manual ) Type conversion ) Not doing anything means where After the condition , Not in the query result field .
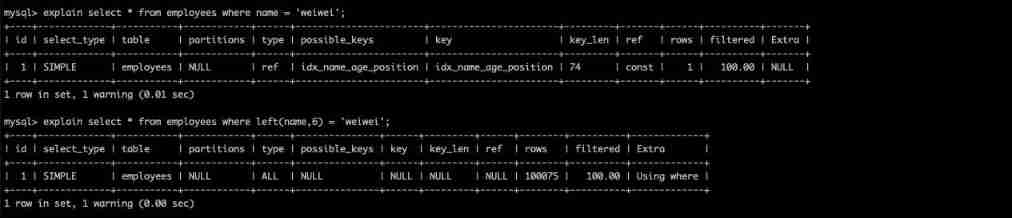
For example name Column for left Function operation .
explain select * from employees where name = 'weiwei';
explain select * from employees where left(name,6) = 'weiwei';
4. The storage engine cannot use the column to the right of the range condition in the index
explain select * from employees where name = 'itwxe' and age = 22 and position = 'manager';
explain select * from employees where name = 'itwxe' and age > 22 and position = 'manager';
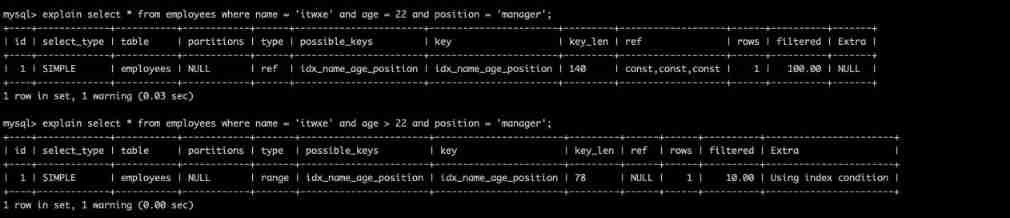
You can see the second SQL Used name,age Column as index to query ,position Not used .
5. Try to use overlay index , Reduce select * sentence
Overlay index mentioned in the previous article , Let's not go into details .
6. MySQL In use is not equal to ( != perhaps <> ),not in,not exists Unable to use the index will result in a full table scan
<、>、<=、>= these ,MySQL The internal optimizer will, based on the retrieval ratio 、 Multiple factors such as table size calculate query cost, whether to use index .
explain select * from employees where name != 'itwxe';

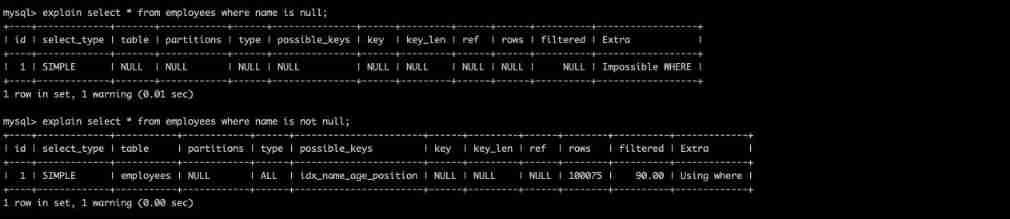
7. is null and is not null In general, you cannot use indexes
explain select * from employees where name is null;
explain select * from employees where name is not null;
8. like Start with a wildcard ('%itwxe...') MySQL Index failure will become a full table scan operation
explain select * from employees where name like 'wei%';
explain select * from employees where name like '%wei';
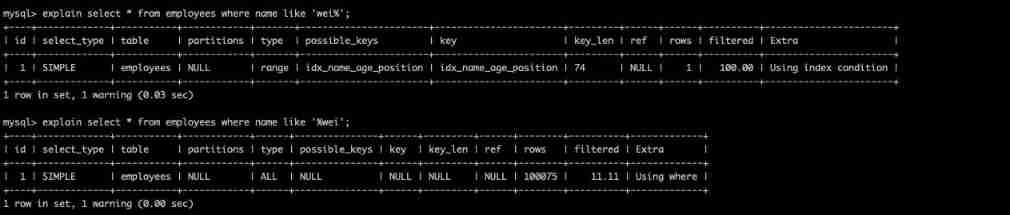
Believe and understand B+tree Small partners in the underlying data structure can easily know why , terms of settlement :
- Establish a joint index according to the business , Query with overlay index .
- If the overlay index cannot be used, use ES Wait for the search engine .
In the query, you can simply put like KK% Understood as a = Constant ,%KK and %KK% Understood as a Range queries .
Here we introduce a Index push down The concept of :
explain select * from employees where name like 'weiwei%' and age = 22 and position = 'manager';
explain select * from employees where name like 'itwxe%' and age = 22 and position = 'manager';
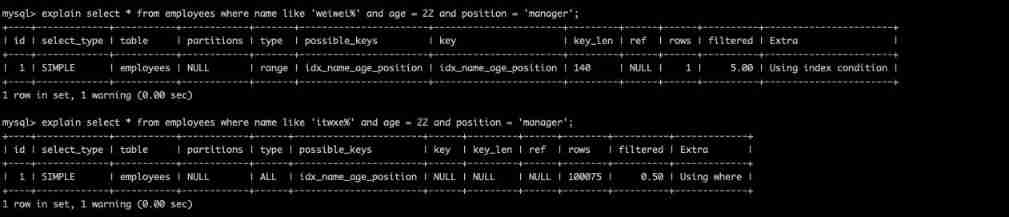
You can see the first SQL in name = 'weiwei%' , according to B+tree The structure of can know the following age,position The columns are out of order , It should not be possible to use age,position Column filter data is right , But finally key_len Indeed 140, That means MySQL Used to name,age,postion Three columns to query , This is because MySQL stay 5.6 Version optimization , Index push down is introduced .
Index push down During index traversal , Judge all the fields contained in the index first , Filter out the unqualified records before returning to the table , It can effectively reduce the times of returning to the table .
When name = 'weiwei%' When filtering , Index push down optimization is used , Filter name At the same time, it will filter in the index age,position Two conditions of , Take the primary key corresponding to the filtered index id Then go back to the table to check the whole row of data .
So it's very simple , Second SQL The reason why the index is not used is because MySQL The calculation uses the index to push down and filter out the data , Query secondary index + The query cost of back table is greater than that of full table scanning , therefore MySQL Select full table scan .
9. Type mismatch MySQL Automatic transformation leads to index invalidation
String index is invalid without single quotation marks , Or the single quotation mark index of the numeric type is invalid , That is, the automatic type conversion mentioned in the third point ( Also called implicit conversion ) Cause index to fail .
10. To use less or or in , When you use it to query ,MySQL Not necessarily index
MySQL The internal optimizer will, based on the retrieval ratio 、 Multiple factors such as table size calculate query cost, whether to use index .
Two 、order by and group by Optimize
1. order by Optimize
In the previous article, grade two introduced the underlying data structure of the index , I know that the index itself is a kind of Arrange order well Of data structure , So the best way to optimize sorting is to implement it on the index , In this way, the queried data has been arranged in order , This sort is in MySQL Is called Using Index, That is, overlay index . Then, if the queried data itself is not sorted according to the required fields , Then there will be Using filesort, That is, file sorting .
therefore , We need to optimize order by, So the main thing is to eliminate inefficient Using filesort, Establish an appropriate union index and use the overlay index to sort .
Using filesort Detailed explanation of document sorting principle
Using filesort It is divided into One way sorting and Two way sorting ( Also called table sorting mode ).
- One way sorting : Retrieve all fields of the qualified row at one time , And then in sort buffer In order ; use trace Tools can see sort_mode The message shows
< sort_key, additional_fields >perhaps< sort_key, packed_additional_fields > - Two way sorting : First, take out the corresponding... According to the corresponding conditions Sort field and You can directly locate the row of row data ID, And then in sort buffer In order , After sorting, you need to retrieve other required fields again ; use trace Tools can see sort_mode The message shows
< sort_key, rowid >
MySQL By comparing system variables max_length_for_sort_data( Default 1024 byte ) And the total size of the fields to be queried to determine which sort mode to use .
- If the total length of the field is less than max_length_for_sort_data , Then use one-way sorting mode
- If the total length of the field is greater than max_length_for_sort_data , Then use the two-way sorting mode
Next use trace Tools to see one-way sorting and two-way sorting :
-- One way sorting
mysql> set session optimizer_trace="enabled=on", end_markers_in_json=on;
mysql> select * from employees where name = 'itwxe' order by position;
mysql> select * from information_schema.OPTIMIZER_TRACE;
"join_execution": { -- sql Execution phase
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`employees`",
"field": "position"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": { -- File sort information
"rows": 1, -- Estimated number of scan lines
"examined_rows": 1, -- The number of rows participating in the sort
"number_of_tmp_files": 0, -- Number of temporary files used , If this value is 0 Represents all used sort_buffer Memory sorting , Otherwise, it will be used Disk file sorting
"sort_buffer_size": 262056, -- Sort the size of the cache , Company Byte
"sort_mode": "<sort_key, packed_additional_fields>" -- sort order , The one-way sorting used here
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
-- Two way sorting
mysql> set max_length_for_sort_data = 10; -- employees The total length of all fields in the table, even one record, must be greater than 10 byte
mysql> select * from employees where name = 'itwxe' order by position;
mysql> select * from information_schema.OPTIMIZER_TRACE;
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`employees`",
"field": "position"
}
] /* filesort_information */,
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
} /* filesort_priority_queue_optimization */,
"filesort_execution": [
] /* filesort_execution */,
"filesort_summary": {
"rows": 1,
"examined_rows": 1,
"number_of_tmp_files": 0,
"sort_buffer_size": 262136,
"sort_mode": "<sort_key, rowid>" -- sort order , The two-way sort used here
} /* filesort_summary */
}
] /* steps */
} /* join_execution */
One way sorting Detailed process :
- From the index name Find the first satisfaction
name = 'itwxe'The primary key of the condition id - According to primary key id Take out the whole line , Take the values of all fields , Deposit in sort_buffer in
- From the index name Find the next satisfaction
name = 'itwxe'The primary key of the condition id. - Repeat step 2、3 Until not satisfied
name = 'itwxe' - Yes sort_buffer The data in is sorted by field
positionSort - Returns the result to the client
Two way sorting Detailed process :
- From the index name Find the first satisfaction
name = 'itwxe'Primary key of id - According to primary key id Take out the whole line , Put the sort field position And the primary key id These two fields are placed in sort buffer in
- From the index name Take down a satisfaction
name = 'itwxe'The primary key of the record id - repeat 3、4 Until not satisfied
name = 'itwxe' - Yes sort_buffer In the field
positionAnd the primary key id According to the fieldpositionSort - Traversal sort ok id And field
position, according to id Value Go back to the original watch Take out the values of all fields and return them to the client
summary : The entire row will be sorted to the cache sort buffer in , The two-way sorting only the primary key id And sort fields into sort buffer Middle order , According to the sorted data , From the original table according to id The query data is returned to the client .
How to choose one-way sorting or multi-way sorting ?
MySQL The optimizer has its own algorithm to judge whether to use two-way sorting or single-way sorting , If the column field of the query is greater than max_length_for_sort_data Variable , Then two-way sorting will be used , On the contrary, one-way sorting will be used , One way sorting is faster , But it takes up more memory , If you want to use one-way sorting when memory space allows , Can increase max_length_for_sort_data The size of the variable .
But be careful , If you use it all sort_buffer Memory sorting is generally more efficient than disk file sorting , But you can't just increase because of this sort_buffer( Default 1M),mysql Many parameter settings have been optimized , Don't adjust easily .
2. group by Optimize
group by And order by Is very similar , The essence of which is Sort first, then group , Comply with The leftmost prefix rule of index creation order . about group by The optimization of the If you don't need to sort, you can add order by null No sorting .
3、 ... and 、 Paging query optimization
The paging query optimization example table is still employees.
select * from employees limit 90000,10;
Many times, the paging function of our business system may be used as follows SQL Realization , It looks like MySQL Is to take 90001 The line 10 Bar record , But actually MySQL When processing this page, it is necessary to read before 90010 Bar record , And then put the front 90000 Records discarded , Take out 90001-90010 The data is returned to the client . Therefore, if you want to query a large table and compare the data at the back , Execution efficiency is very low .
1. Paged query sorted by auto increasing and continuous primary key
select * from employees where id > 90000 limit 10;
principle : Index according to the primary key id exclude <90000 The data of , After taking 10 Avoid full table scanning of data .
shortcoming : If the primary key id Discontinuous , Or delete data in the middle , The effect cannot be achieved , So we usually use the second method below .
2. Paging queries sorted by non primary key fields
select * from employees order by name limit 90000,10;
select * from employees ed_all inner join (select id from employees order by name limit 90000,10) ed_id on ed_all.id = ed_id.id;
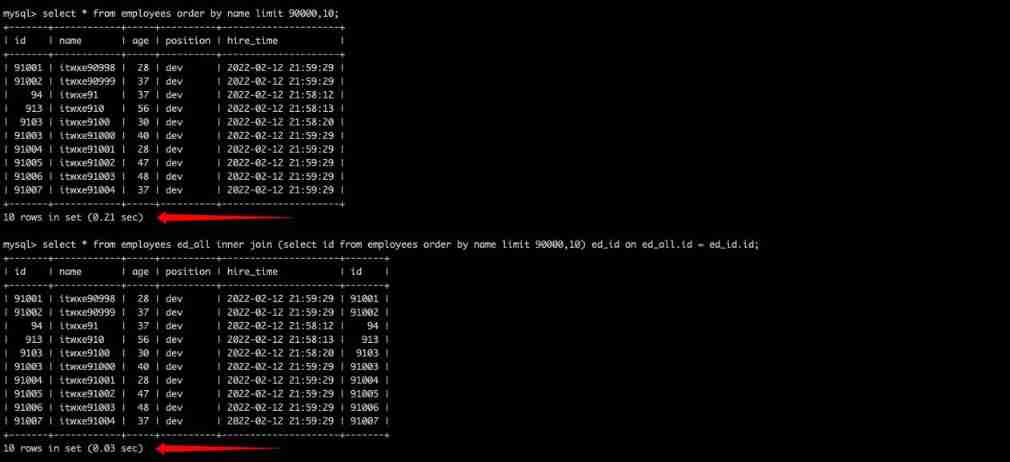
You can see the same result of the query , But there is a huge gap in query speed , This is just 10w+ Test data for , Join yes 100w Well , How big is the gap !

Ali Java This situation is also described in the development manual , I highly recommend you to take a look at Ali Java Development Manual , There is a special chapter on MySQL Development specifications are described .
Four 、join Association query optimization
-- Sample table
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
create table t2 like t1;
-- Go to t1 Table insert 1w Line test data
drop procedure if exists insert_t1;
delimiter $$
create procedure insert_t1()
begin
declare i int;
set i = 1;
while(i <= 10000)do
insert into t1(a,b) values(i,i);
set i = i + 1;
end while;
end$$
delimiter ;
call insert_t1();
-- Go to t2 Table insert 100 Line test data
drop procedure if exists insert_t2;
delimiter $$
create procedure insert_t2()
begin
declare i int;
set i = 1;
while(i <= 100)do
insert into t2(a,b) values(i,i);
set i = i + 1;
end while;
end$$
delimiter ;
call insert_t2();
1. Two common algorithms for table Association
Nested loop connection Nested-Loop Join(NLJ) Algorithm
NLJ Algorithm Loop from the first table one row at a time ( The driver table ) Read lines in , Get the associated field in this row of data , According to the associated fields in another table ( Was the driver table ) Take out the line that meets the conditions , Then take out the result set of the two tables .
explain select * from t1 inner join t2 on t1.a = t2.a;

As can be seen from the implementation plan ,t2 As The driver table ,t1 As Was the driver table . The first thing to execute is the drive table ( The results of the implementation plan id If the same, execute from top to bottom SQL), Optimizer Usually Will give priority to small tables as driving tables , use where After condition filtering, the driver table , Then do an association query with the driven table . So use inner join when , The top table is not necessarily the driving table .
- When using left join when , The left table is the driver table , The right table is the driven table .
- When using right join when , The right table is the driving table , The left table is the driven table .
- When using inner join when ,MySQL Usually A table with a small amount of data will be selected as The driver table , A large watch serves as Was the driver table .
Be careful : When deciding which watch to drive , Two tables should be filtered according to their own conditions , After filtering , Calculate participation join The total amount of data in each field of , The table with small amount of data , Namely “ Watch ”, It should be used as a driving table . Instead of simply comparing the total data of the two tables .
above SQL The general process is as follows :
- From the table t2 Read a row of data in the ( If t2 Table with query filter criteria , Filter with the first condition , Then take out a row of data from the filtering result ).
- From 1 Step data , Take out the associated fields a, To table t1 Search for .
- Take out the watch t1 The line that satisfies the condition in , Follow t2 Merge the results obtained in , Return to the client as a result .
- Repeat the above 3 Step .
The whole process will read t2 All data of table ( scanning 100 That's ok ), Then traverse the fields in each row of data a Value , according to t2 In the table a Value index scan t1 The corresponding row in the table ( scanning 100 Time t1 Index of tables ,1 One scan can be considered as only scanning in the end t1 One row of complete data in the table , That's all t1 The watch was also scanned 100 That's ok ). So the whole process scans 200 That's ok .
If there is no index on the column of the join query ,NLJ The performance of the algorithm will be low , that MySQL Will choose BNL Algorithm .
Block based nested loop connections Block Nested-Loop Join(BNL) Algorithm
BNL The algorithm puts The driver table Data read into join_buffer( Connect query cache ) in , Then scan Was the driver table , hold Was the driver table Take out each line and follow join_buffer Compare the data in .
explain select * from t1 inner join t2 on t1.b = t2.b;

Extra Medium Using join buffer (Block Nested Loop) This indicates that the association query uses BNL Algorithm . And you can see that t2 Still as a driver table ,t1 As a driven table .
above SQL The general process is as follows :
- hold t2 Put all the data into join_buffer in .
- Keep watch t1 Take out every line in the , Follow join_buffer Compare the data in .
- Return to satisfaction join Conditional data .
The whole process is on the table t1 and t2 We did a full scan , Therefore, the total number of rows scanned is 10000( surface t1 Total data of ) + 100( surface t2 Total data of ) = 10100. also join_buffer The data in the is out of order , So watch t1 Each line in , Do it all 100 Second judgment , So the number of judgments in memory is 100 * 10000= 100 Ten thousand times .
In this example, the table t2 only 100 That's ok , If table t2 It's a big watch ,join_buffer What can I do if I can't put it down ?
join_buffer The size of is determined by the parameter join_buffer_size Set , The default value is 256k. If you can't put the table t2 All the data of , The strategy is simple , Namely Put... In sections . The process is as follows :
- Take part of the data from the drive table and put it into join_buffer, until join_buffer I can't let it go .( such as t2 Table has 1000 rows , join_buffer You can only put... At a time 800 Row data , Then the execution process is to go first join_buffer Put in 800 rows )
- Scan each row of data in the driven table , Follow join_buffer Compare the data in , Satisfy join Conditional data is returned as part of the result set .( from t1 Take data from the table and follow join_buffer Some results are obtained by comparing the data in )
- Empty join_buffer.( Empty join_buffer)
- Continue reading the remaining data of the driver table , Repeat the first three steps , The data of the driving table has been scanned .( then t2 Table remaining 200 Line records are placed in join_buffer in , Again from t1 Take data from the table and follow join_buffer Data comparison in . So I scanned it once more t1 Table and the number of multi scan segments t2 surface )
So take this example of subsection placement , If the number of rows driving the table is N, Need points K Segment can be scanned , The number of rows in the driven table is M, The number of rows scanned is N + K * M, namely 1000 + 2 * 10000 = 21000 That's ok ; The total number of memory judgments is (800 + 200) * 10000 = 100 Ten thousand times .
The associated field of the driven table has no index. Why do you choose to use BNL Algorithm without using NLJ The algorithm ?
Assuming there is no index, select NLJ Algorithm , Then the number of lines to be scanned is 100 * 10000 = 100w Ten thousand times , But this is Disk scan .
Obviously , use BNL The number of disk scans of the algorithm is much less , And compared to disk scanning ,BNL Memory computing will be much faster .
therefore MySQL For an associated query with no index for the associated field of the driven table , Generally used BNL Algorithm ; If there is an index, generally choose NLJ Algorithm , With an index NLJ Algorithm ratio BNL The algorithm has higher performance .
2. For Association SQL The optimization of the
It's over NLJ Algorithm and BLJ Algorithm , It must be related to SQL There are also some ideas for the optimization of .
- More than three tables prohibited join, When multi table associated query , Ensure that the associated field needs to have an index , Try to choose NLJ Algorithm , Simultaneous need join Field of , Data types must be absolutely consistent .
- Small tables drive large tables , Write multi table join SQL If you know which table is small, you can use it
straight_joinFixed connection drive mode , Omit mysql The optimizer's own time .
straight_join:straight_join Same function inner join similar , But let the left watch drive the right watch , It can change the execution order of the table optimizer for the associated table query . such as :select * from t2 straight_join t1 on t2.a = t1.a; The representative designates MySQL choice t2 Table as drive table .
- straight_join Only applicable to inner join, It doesn't apply to left join、right join.( because left join、right join The execution order of the table has been specified on behalf of )
- Let the optimizer judge as much as possible , Use straight_join Be careful , Because in some cases, the artificially specified execution order is not necessarily more reliable than the optimization engine .
5、 ... and 、in and exsits Optimize
principle : Small tables drive large tables .
in Optimize : When B The data set of the table is less than A When the data set of the table ,in be better than exists.
select * from A where id in (select id from B);
# Equivalent to :
for(select id from B) {
select * from A where A.id = B.id;
}
exsits Optimize : When A The data set of the table is less than B When the data set of the table ,exists be better than in.
select * from A where exists (select 1 from B where B.id = A.id);
# Equivalent to :
for(select * from A) {
select 1 from B where B.id = A.id;
}
exists (subquery)Only return true or false, So in the subquerySELECT *It can also be used.SELECT 1Replace , The official saying is that the actual implementation will be ignored select detailed list , So there's no difference .- exists Subqueries can often also be used join Instead of , How to optimize the query requires specific analysis of specific problems .
6、 ... and 、count(*) Query optimization
1. count Compare
-- Temporarily Closed MySQL The query cache
set global query_cache_size=0;
set global query_cache_type=0;
-- count
explain select count(*) from employees;
explain select count(1) from employees;
explain select count(id) from employees;
explain select count(name) from employees;
My friends may have heard of DBA Or some blogs suggest not to use count(*) To count the number of data rows , But it's not really like that , You can find the above four SQL The implementation plan is the same as ten cents .
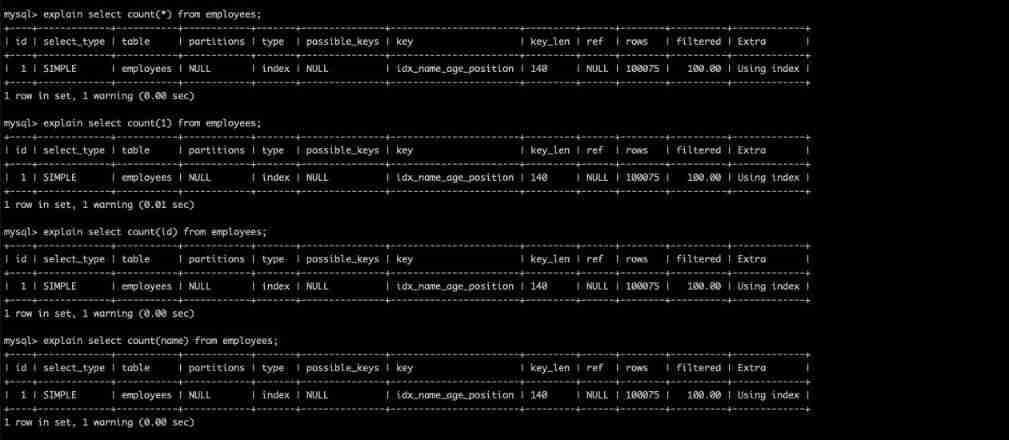
So since the implementation plan is the same , So that means that 4 The execution efficiency of this statement is almost the same. In fact , even to the extent that 5.7 After version count(*) More efficient . But here's the thing count(name) No statistics name by null The data line .
- The field has an index :
count(*) ≈ count(1) > count( Field ) > count( Primary key id)// The field has an index ,count( Field )Statistics go through secondary index , Secondary indexes store less data than primary indexes , thereforecount( Field ) > count( Primary key id). - Field has no index :
count(*) ≈ count(1)> count( Primary key id) > count( Field )// Field has no index ,count( Field )Statistics can't be indexed ,count( Primary key id)You can also go through the primary key index , thereforecount( Primary key id) > count( Field ) count(1)Followcount( Field )The execution process is similar to , howevercount(1)There is no need to take out the field statistics , Just use constants 1 Do statistics ,count( Field )You also need to take out the fields , So theoreticallycount(1)Thancount( Field )It will be faster .count(*)It's an exception ,MySQL It doesn't take all the fields out , It's optimized , No value , Add by line , It's very efficient , So you don't need to usecount( Name )orcount( Constant )To replace count(*).
Why for
count(id),MySQL Finally, select the secondary index instead of the primary key clustered index ?
Because the secondary index stores less data than the primary key index , Retrieval performance should be higher ,MySQL5.7 The internal version has been optimized .
2. Common optimization methods
a. Inquire about MySQL The total number of rows maintained by yourself
about MyISAM The table of the storage engine does not have where Conditions of the count Query performance is very high , because MyISAM The total number of rows in the table of the storage engine will be MySQL Stored on disk , The query does not need to calculate .
select count(*) from test_myisam;
explain select count(*) from test_myisam;
You can see that there is no query in the execution plan table .
b. show table status
If you only need to know the estimated value of the total number of rows in the table, you can use show table status like 'employyees'; Inquire about , The query result is an estimate .

c. Maintain the total to Redis in
When inserting or deleting table data rows, maintain Redis The total number of rows in the table key The count of ( use incr or decr command ), But this way may not be right , It is difficult to guarantee table operation and redis Transactional consistency of operations .
d. Add database count table
Maintain the count table while inserting or deleting table data rows , Let them operate in the same transaction .
common SQL Here are the performance optimization techniques , It's late at night ~~~
Of course! ,SQL Of course, optimization techniques are inseparable from how to create an appropriate index , The length of this article is estimated to be very long ... therefore ... In the next article, the sophomore will talk about the principles and skills of index design through an interesting small case , See you guys next .