当前位置:网站首页>【论文笔记】Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research
【论文笔记】Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research
2022-07-05 04:58:00 【见鹿本鹿(Python版)】
目录
Abstract
首先,它引入了一套基于现有机器人硬件的具有挑战性的连续控制任务(由OpenAI Gym集成)。
所有的任务都有稀疏的二元奖励,并遵循一个多目标强化学习(RL)框架,在该框架中,一个智能体被告知使用一个额外的输入要做什么。
本文的第二部分提出了一套改进RL算法的具体研究思路,其中大部分与多目标RL和事后经验回放有关。
1 Environments
1.1 Fetch environments
抓取环境是基于7自由度抓取机器人臂,它有一个双指平行抓取器。
我们增加了一个额外的到达任务,pick and place任务有点不同。
在所有的获取任务中,目标都是三维的,并描述了目标的期望位置(或要到达的末端执行器)。
奖励是稀疏的和二进制的:如果对象在目标位置(在5厘米内),智能体获得0的奖励,否则−1。
动作是4维的:三维指定在笛卡尔坐标中所需的夹持器运动,最后一个尺寸控制夹持器的开启和关闭。
在将控制返回给智能体之前,我们在20个模拟器步骤中(每个 δ = 0.002 \delta=0.002 δ=0.002)应用相同的动作,即代理的动作频率为 f = 25 H z f=25Hz f=25Hz。
观测结果包括夹具的笛卡尔位置、线速度以及机器人夹具的位置和线速度。
如果一个物体存在,我们也包括使用欧拉角的笛卡尔位置和旋转,它的线性和角速度,以及它的位置和相对于夹持的线性速度。
Reaching (FetchReach)
任务是将夹持器移动到目标位置。这个任务非常容易学习,因此是一个合适的基准,以确保一个新的想法完全工作。
Pushing (FetchPush)
一个盒子被放置在机器人前面的一张桌子上,其任务是将其移动到桌子上的一个目标位置。机器人的手指被锁住,以防止抓握。习得的行为通常是推动和滚动的混合物。
Sliding (FetchSlide)
一个冰球被放置在一个长长的光滑的桌子上,目标位置在机器人的伸手范围之外,所以它必须用这样的力量击中冰球,它滑动,然后由于摩擦而停止在目标位置。
Pick & Place (FetchPickAndPlace)
任务是抓住一个盒子,并将其移动到可能位于桌子表面或桌子上方空中的目标位置。
1.2 Hand environments
这些环境是基于 Shadow Dexterous Hand,这是一个拟人化的,有24个自由度的机械手。在这24个关节中,有20个可以独立控制,而其余的一个是耦合关节。
| Items | Contents |
|---|---|
| Rewards | The agent obtains a reward of 0 if the goal has been achieved (within some task-specific tolerance) and −1 otherwise. |
| Actions | 20-dimensional. Use absolute position control for all non-coupled joints of the hand. |
| Observations | include the 24 positions and velocities of the robot’s joints. In case of an object that is being manipulated, we also include its Cartesian position and rotation represented by a quaternion (hence 7-dimensional) as well as its linear and angular velocities. |
Reaching (HandReach)
一个简单的任务,其中目标是15维的,并包含手每个指尖的目标笛卡尔位置。如果指尖与期望位置之间的平均距离小于1厘米,则认为达到了目标。
Block manipulation (HandManipulateBlock)
在块操作任务中,一个块被放置在手掌上。然后,任务是操作块,从而实现目标姿态。
HandManipulateBlockRotateZ
目标围绕块的z轴进行随机旋转。没有目标位置。
HandManipulateBlockRotateParallel
围绕块的z轴的随机目标旋转和x轴和y轴的轴目标旋转。没有目标位置。
HandManipulateBlockRotateXYZ
对块的所有轴的随机目标旋转。没有目标位置。
HandManipulateBlockFull
对块的所有轴的随机目标旋转。随机目标位置。
如果块的位置与其期望位置之间的距离小于1厘米(仅适用于完整变体),且旋转差小于0.1rad,则认为是达到了目标。
Egg manipulation (HandManipulateEgg)
这里的目标类似于块任务,但使用的不是蛋形对象的块。
物体的几何形状对问题的困难程度有显著的不同,而鸡蛋可能是最简单的物体。
目标同样是7维的,包括目标位置(以笛卡尔坐标系)和目标旋转(以四元数表示)。
HandManipulateEggRotate
对鸡蛋的所有轴进行随机的目标旋转。没有目标位置。
HandManipulateEggFull
对鸡蛋的所有轴进行随机的目标旋转。随机目标位置。
如果鸡蛋的位置与其期望位置之间的距离小于1厘米(仅适用于完整变体),且旋转差小于0.1rad,则认为是达到了目标。
Pen manipulation (HandManipulatePen)
抓笔很难,因为它很容易从手上掉下来,很容易碰撞和卡在其他手指之间。
另一种操作,这次是用钢笔而不是积木或鸡蛋。
HandManipulatePenRotate
随机的目标旋转x和y轴,没有目标围绕z轴旋转。没有目标位置。
HandManipulatePenFull
随机的目标旋转x和y轴,没有目标围绕z轴旋转。随机目标位置。
如果笔的位置与其期望位置之间的距离小于5厘米(仅适用于完整变体),并且旋转的差异,忽略z轴,小于0.1rad,则认为是达到了目标。
1.3 Multi-goal environment interface
Goal-aware observation space
它要求观察空间的种类是:gym.space.Dict
observtion
机器人的状态或位姿。
desired_goal
智能体必须达到的目标。
achieved_goal
智能体当前已经达到的目标。在FetchReach中,这是机器人末端执行器的位置。理想情况下,这将尽快与desired_goal相同。
Exposed reward function
其次,我们以一种允许以不同目标的方式重新计算奖励的方式展现奖励功能。这是一种可以替代目标的HER式算法的必要要求。
Compatibility with standard RL algorithms
我们包括一个简单的包装器,它将新的基于字典的目标观察空间转换为一个更常见的数组表示。
1.4 Benchmark results
实验对象
| DDPG+HER with sparse rewards | DDPG+HER with dense rewards | DDPG with sparse rewards | DDPG with dense rewards |
|---|
我们通过对每个MPI工作者执行10个确定性测试推出来评估每个阶段之后的性能,然后通过对推出和MPI工作者进行平均来计算测试成功率。
在所有情况下,我们用5个不同的随机种子重复一个实验,并通过计算中位数测试成功率和四分位数范围来报告结果。
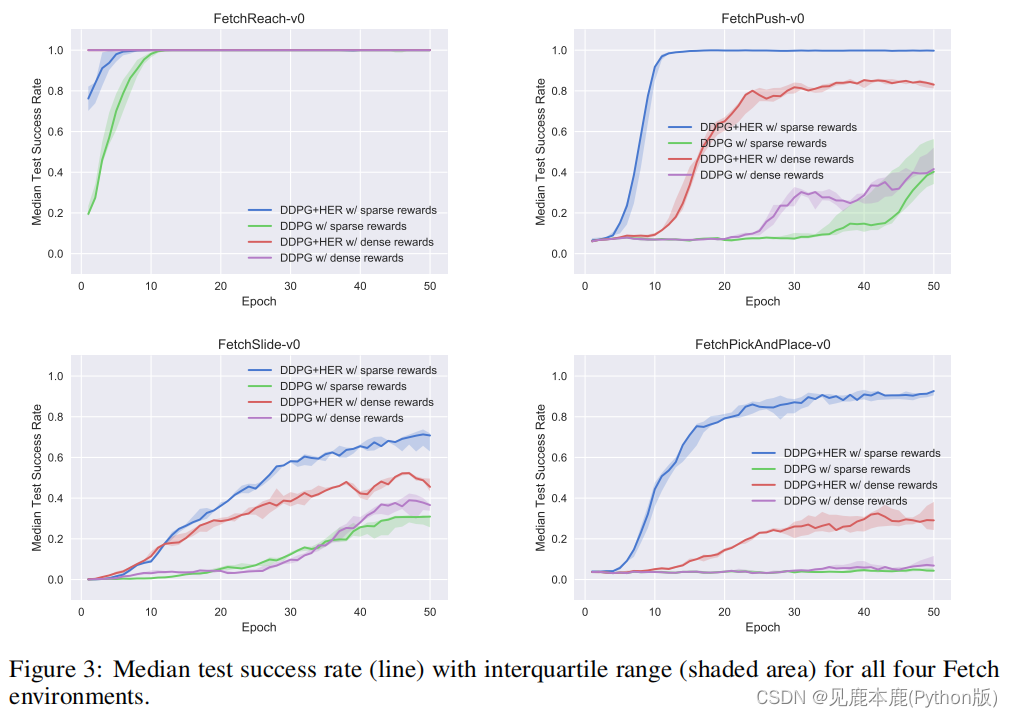
在其余的环境中,DDPG+HER明显优于所有其他配置。
如果奖励结构是稀疏的,但也能够成功地从密集的奖励中学习,那么DDPG+HER的表现最好。
对于普通的DDPG,它通常更容易从密集的奖励中学习,而稀疏的奖励则更具挑战性。
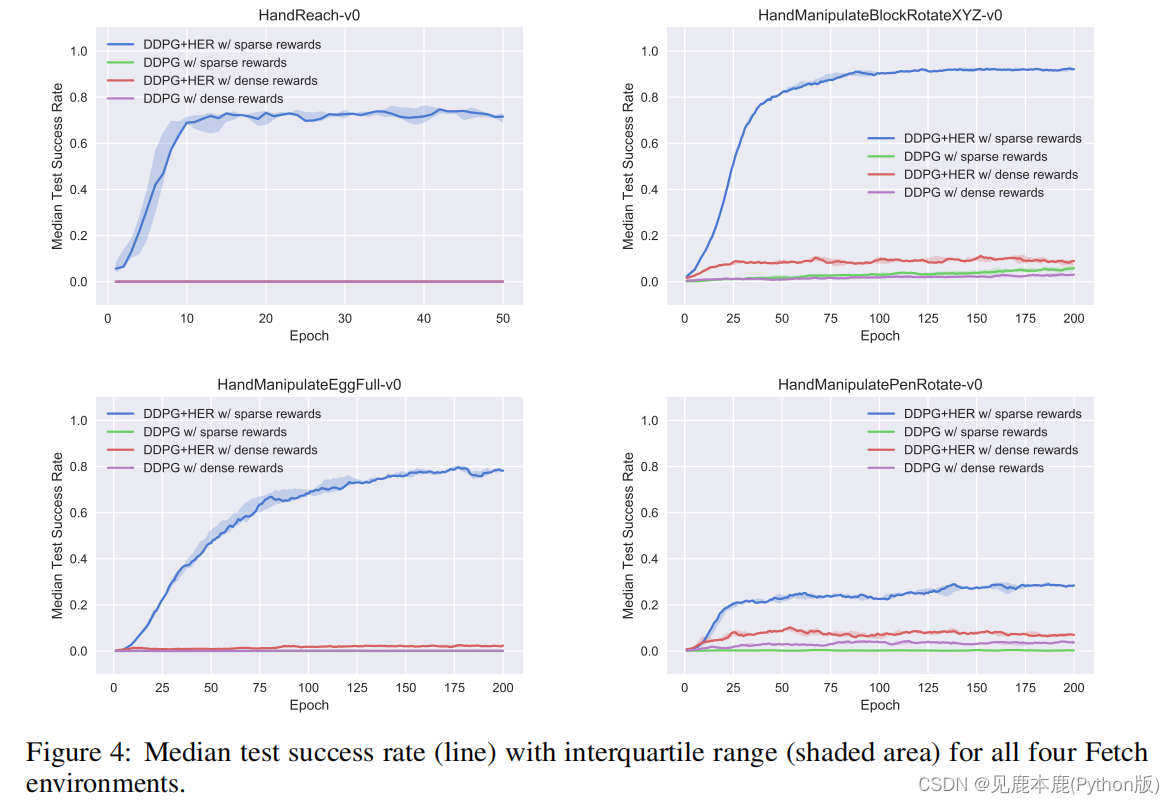
与之前类似,在使用HER时,稀疏奖励结构明显优于密集奖励结构。
她能够在所有环境中学习到部分成功的政策,但特别是HandManipulatePen尤其具有挑战性。
原因解释:
- 学习稀疏返回要简单得多,因为批评家只需要区分成功的状态和失败的状态。
- 然而,密集的奖励鼓励政策选择一个直接达到预期目标的策略。
2 Request for Research
Automatic hindsight goals generation
我们可以了解哪些目标对经验重播最有价值。
最大的问题是如何判断哪些目标对重播最有价值。一种选择是训练生成器,以最大化贝尔曼误差。
Unbiased HER
HER以一种无原则的方式改变了重放元组的联合分布。
理论上,这可能使训练在极其随机的环境中不可能,尽管我们在实践中没有注意到这一点。
考虑一个环境,其中有一个特殊的动作,将智能体带到一个随机状态,事件在那之后结束。
事后看来,如果我们重播智能体在未来实现的目标,这样的行动似乎是完美的。
如何避免这个问题?一种可能的方法是使用重要抽样来消除抽样偏差,但这可能会导致梯度的过高的方差。
HER+HRL
这项工作的一个可能的扩展是取代不仅目标,而且更高水平的行动,例如,如果高层要求低水平达到状态,但其他一些状态B状态,我们可以重播这一过程取代高层行动B。
这可以让即使在低水平的政策非常糟糕但是具有更高的水平学习,但这并不是很有原则,可能使训练不稳定。
Richer value functions
UVFA将价值函数扩展到多个目标,而TDM将其扩展到不同的时间范围。
这两种创新都可以使训练更容易,尽管学习的功能更复杂。
Faster information propagation
大多数最先进的非策略RL算法使用目标网络来稳定训练。
然而,这是以限制算法的最大学习速度为代价的,因为每次目标网络更新只将返回的信息及时返回一步(如果使用一步引导)。
我们注意到,在训练的早期阶段,DDPG+HER的学习速度往往与目标网络更新的频率成正比,但目标网络更新的频率/幅度过大会导致训练不稳定,最终表现更差。
HER + multi-step returns
HER生成的数据非常偏离策略,因此不能使用多步回归,除非我们使用一些修正因子,如重要性抽样。
虽然有许多处理数据的非策略的解决方案,但尚不清楚它们是否会在训练数据远非策略上的设置中表现良好。
使用多步返回可能是有益的,因为引导频率的降低可以导致更少的偏置梯度。
此外,它加速了在时间上关于返回的信息的反向传递,根据我们的实验,这往往是DDPG+HER训练的限制因素(比较前一段)。
On-policy HER
Rauber等人提出了一些关于普通政策梯度的初步结果,但这种方法需要在更具挑战性的环境中进行测试,如本报告中提出的环境。一种可能的选择也是使用类似于IPG中使用的技术。
Combine HER with recent improvements in RL
RL with very frequent actions
在连续控制域中,当采取行动的频率趋近于无穷大时,性能就会趋近于零,这是由两个因素引起的。
- 不一致的探索和需要引导更多的时间来及时向后传播关于返回的信息。如何设计一个样本效率高的RL算法,即使采取行动的频率趋于无穷大,也能保持其性能?探索利用问题可以通过使用参数噪声来解决,采用多步返回可以实现更快的信息传播。
- 其他的方法可以是一个自适应的和可学习的帧跳过。
Appendix A
Appendix B
边栏推荐
猜你喜欢
Autocad-- Real Time zoom
![[groovy] closure (closure call | closure default parameter it | code example)](/img/61/754cee9a940fd4ecd446b38c2f413d.jpg)
[groovy] closure (closure call | closure default parameter it | code example)

LeetCode之單詞搜索(回溯法求解)

Manually implement heap sorting -838 Heap sort
AutoCAD -- dimension break
Establish cloth effect in 10 seconds
AutoCAD - full screen display
Panel panel of UI

Solutions and answers for the 2021 Shenzhen cup
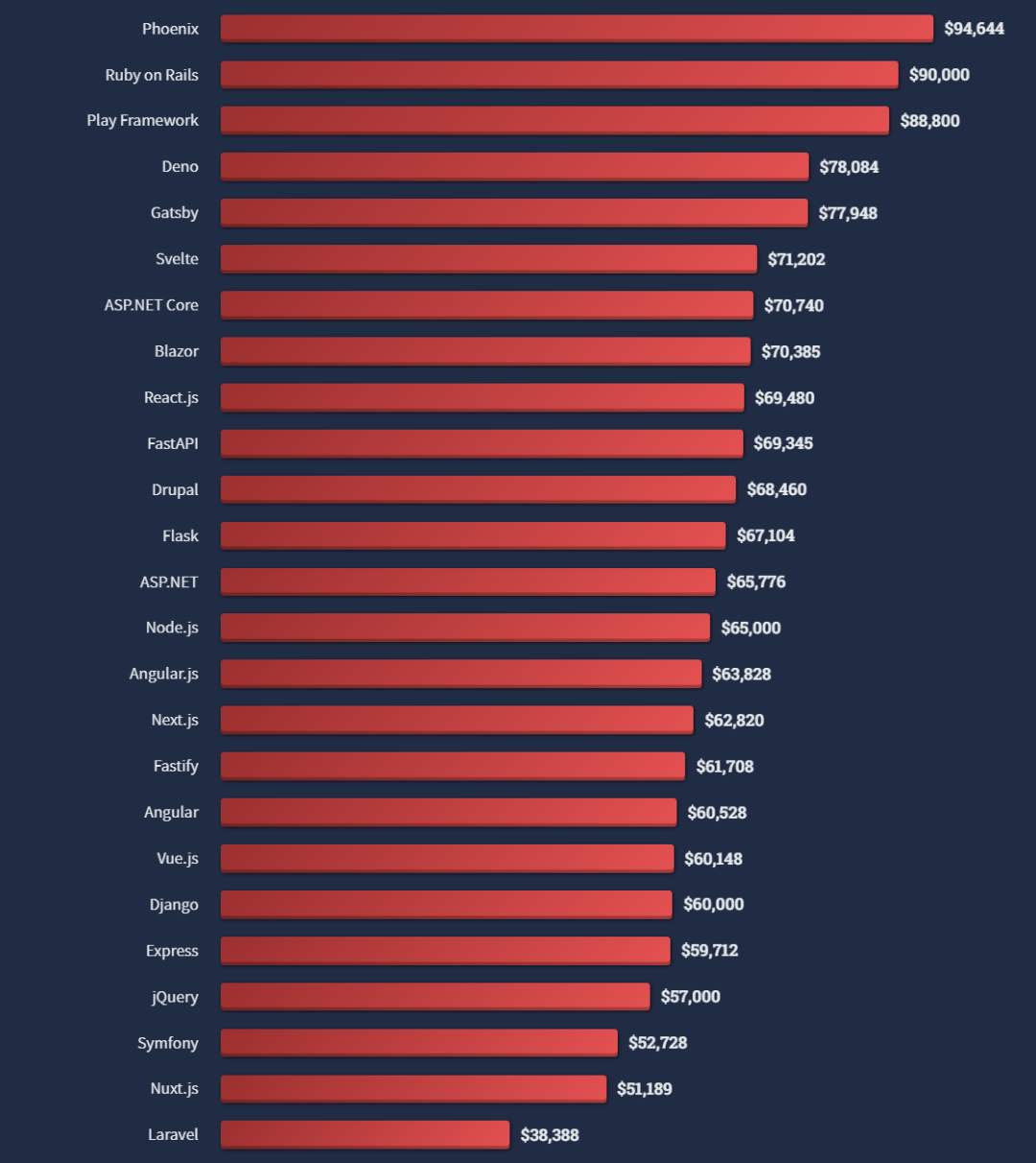
PostgreSQL surpasses mysql, and the salary of "the best programming language in the world" is low
随机推荐
MySQL audit log Archive
[groovy] closure (closure call is associated with call method | call () method is defined in interface | call () method is defined in class | code example)
Sixth note
Panel panel of UI
LeetCode之單詞搜索(回溯法求解)
AutoCAD - full screen display
AutoCAD - lengthening
Detailed explanation of the ranking of the best universities
2020-10-27
Group counting notes (1) - check code, original complement multiplication and division calculation, floating point calculation
Introduce Hamming distance and calculation examples
Three dimensional dice realize 3D cool rotation effect (with complete source code) (with animation code)
PostgreSQL surpasses mysql, and the salary of "the best programming language in the world" is low
猿人学第一题
Emlog博客主题模板源码简约好看响应式
3dsmax snaps to frozen objects
Cocos progress bar progresstimer
On-off and on-off of quality system construction
2022 thinking of Mathematical Modeling B problem of American college students / analysis of 2022 American competition B problem
C4D simple cloth (version above R21)