当前位置:网站首页>ICLR 2022 | 基于对抗自注意力机制的预训练语言模型
ICLR 2022 | 基于对抗自注意力机制的预训练语言模型
2022-07-07 10:33:00 【PaperWeekly】

作者 | 曾伟豪
单位 | 北京邮电大学
研究方向 | 对话摘要生成

论文名称:
Adversarial Self-Attention For Language Understanding
论文来源:
ICLR 2022
论文链接:
https://arxiv.org/pdf/2206.12608.pdf

Introduction
本文提出了 Adversarial Self-Attention 机制(ASA),利用对抗训练重构 Transformer 的注意力,使模型在被污染的模型结构中得到训练。
尝试解决的问题:
大量的证据表明,自注意力可以从 allowing bias 中获益,allowing bias 可以将一定程度的先验(如 masking,分布的平滑)加入原始的注意力结构中。这些先验知识能够让模型从较小的语料中学习有用的知识。但是这些先验知识一般是任务特定的知识,使得模型很难扩展到丰富的任务上。
adversarial training 通过给输入内容添加扰动来提升模型的鲁棒性。作者发现仅仅给 input embedding 添加扰动很难 confuse 到 attention maps. 模型的注意在扰动前后没有发生变化。
为了解决上述问题,作者提出了 ASA,具有以下的优势:
最大化 empirical training risk,在自动化构建先验知识的过程学习得到biased(or adversarial)的结构。
adversial 结构是由输入数据学到,使得 ASA 区别于传统的对抗训练或自注意力的变体。
使用梯度反转层来将 model 和 adversary 结合为整体。
ASA 天然具有可解释性。

Preliminary
表示输入的特征,在传统的对抗训练中, 通常是 token 序列或者是 token 的 embedding, 表示 ground truth. 对于由 参数化的模型,模型的预测结果可以表示为 。
2.1 Adversarial training
对抗训练的目的是旨在通过推近经过扰动的模型预测和目标分布之间的距离来提升模型的鲁棒性:
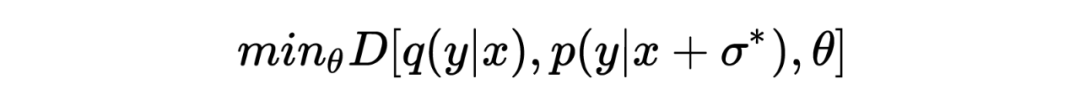
其中 代表经过对抗扰动 扰动后的模型预测, 表示模型的目标分布。
对抗扰动 通过最大化 empirical training risk 获得:
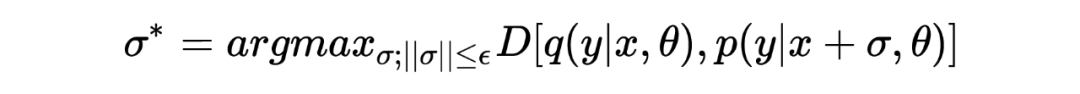
其中 是对 做出的约束,希望在 较小的情况下给模型造成较大的扰动。上述的两个表示展示的就是对抗的过程。
2.2 General Self-Attention
定义自注意力的表达式为:
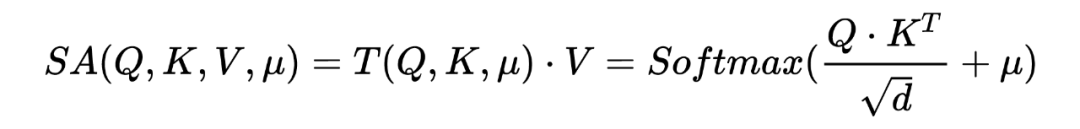
在最普通的自注意力机制中 代表全等矩阵,而之前的研究中, 代表的是用来平滑注意力结构的输出分布的一定程度的先验知识。
作者在本文将 定义为元素为 的 binary 矩阵。

Adversarial Self-Attention Mechanism
3.1 Optimization
ASA 的目的是掩盖模型中最脆弱的注意力单元。这些最脆弱的单元取决于模型的输入,因此对抗可以表示为由输入学习到的“meta-knowledge”:,ASA 注意力可以表示为:
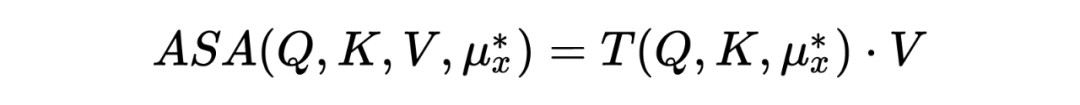
与对抗训练类似,模型用来最小化如下的 divergence:
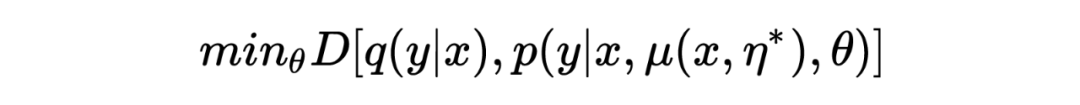
通过最大化 empirical risk 估计得到 :
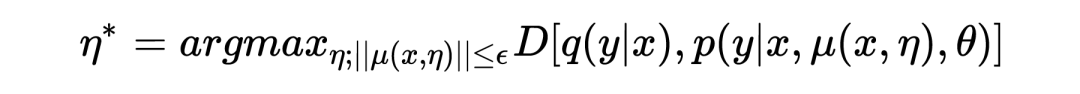
其中 表示的是 的决策边界,用来防止 ASA 损害模型的训练。
考虑到 以 attention mask 的形式存在,因此更适合通过约束 masked units 的比例来约束。由于很难测量 。
的具体数值,因此将 hard constraint 转化为具有惩罚的 unconstraint:
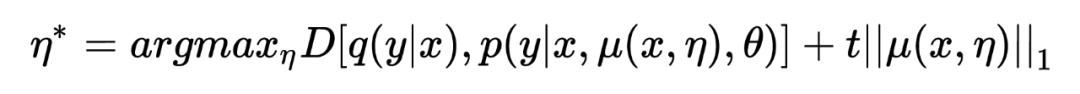
其中 t 用来控制对抗的程度。
3.2 Implementation
作者提出了 ASA 的简单且快速的实现。
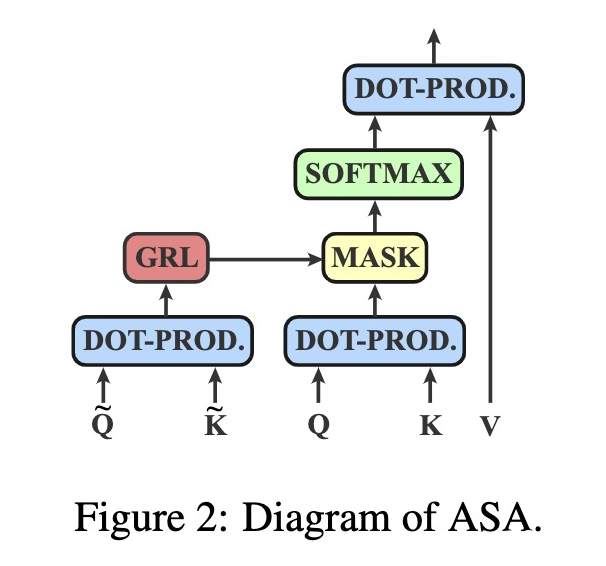
对于第 自注意力层, 可以由输入的隐层状态获得。具体而言,使用线性层将隐层状态转化为 以及 ,通过点乘获得矩阵 ,再通过重参数化技巧将矩阵 binary 化。
由于对抗训练通常包括 inner maximization 以及 outer minimization 两个目标,因此至少需要两次 backward 过程。因此为了加速训练,作者采用了 Gradient Reversal Layer(GRL)将两个过程合并。
3.3 Training
训练目标如下所示:
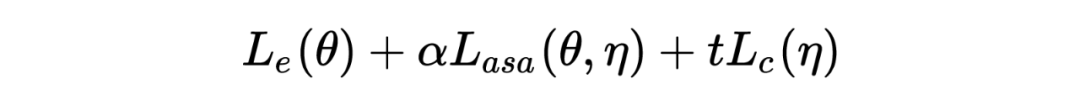
表示 task- specific 损失, 表示加上 ASA 对抗后的损失, 表示对于对于 的约束。

Experiments
4.1 Result
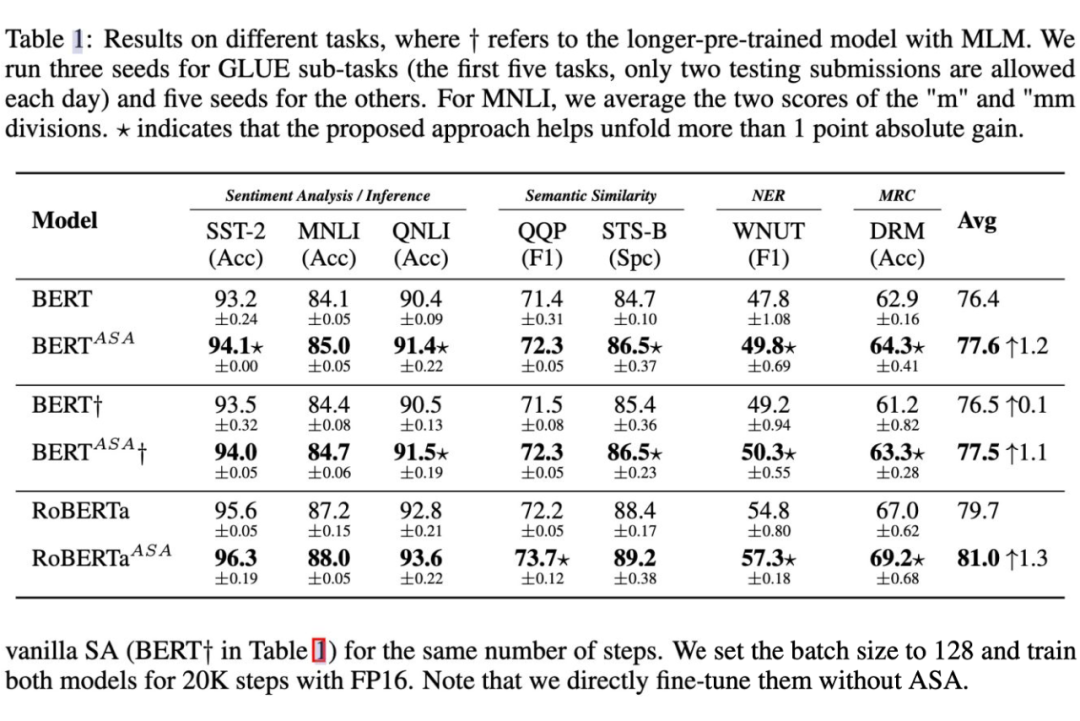
从上表可以看出,在微调方面,ASA 支持的模型始终在很大程度上超过了原始的BERT 和 RoBERTa. 可以看到,ASA 在小规模数据集比如说 STS-B,DREAM 上表现优异(一般认为这些小规模数据集上更容易过拟合)同时在更大规模的数据集上如 MNLI,QNLI 以及 QQP 上仍然有较好的提升,说明了 ASA 在提升模型泛化能力的同时能提升模型的语言表示能力。
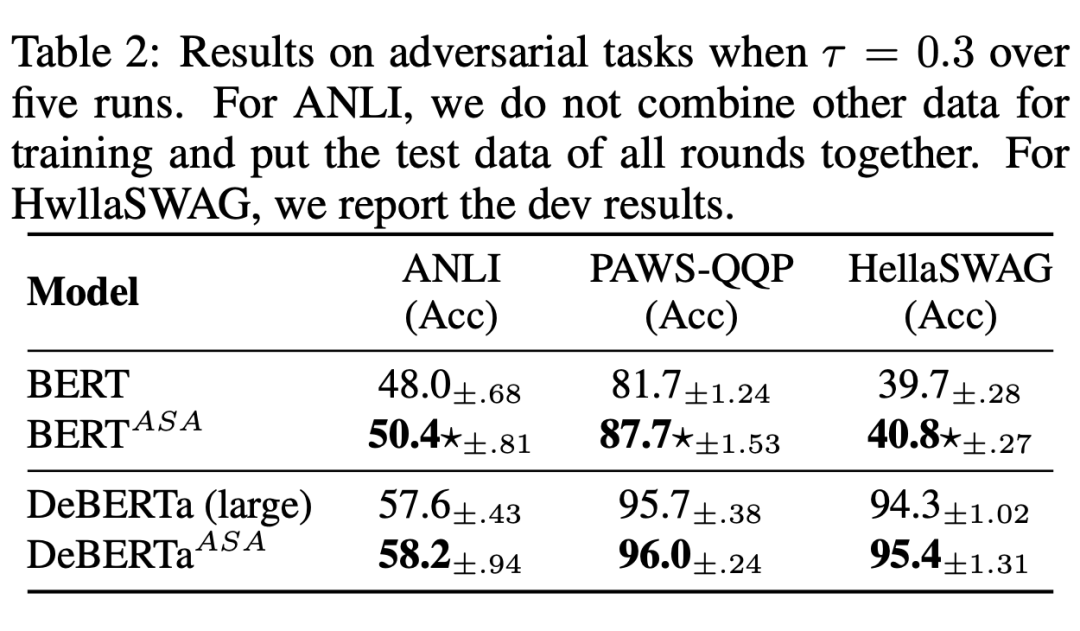
如下表所示,ASA 在提升模型鲁棒性上具有较大的作用。
4.2 分析实验
1. VS. Naive smoothing
将 ASA 与其他注意力平滑方式进行比较。

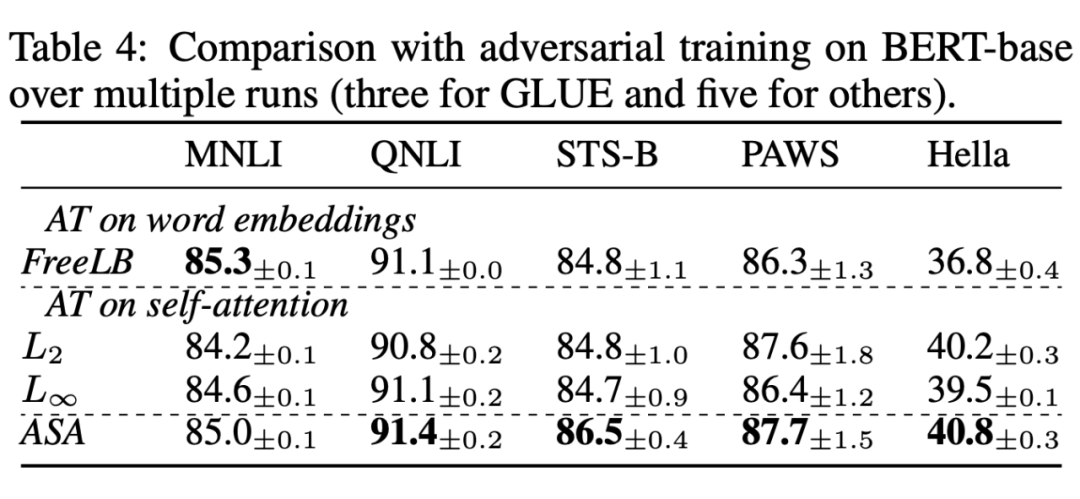
2. VS. Adversial training
将 ASA 与其他对抗训练方式进行比较
4.3 Visualization
1. Why ASA improves generalization
对抗能够减弱关键词的注意力而让非关键词接受更多的注意力。ASA 阻止了模型的懒惰预测,但敦促它从被污染的线索中学习,从而提高了泛化能力。

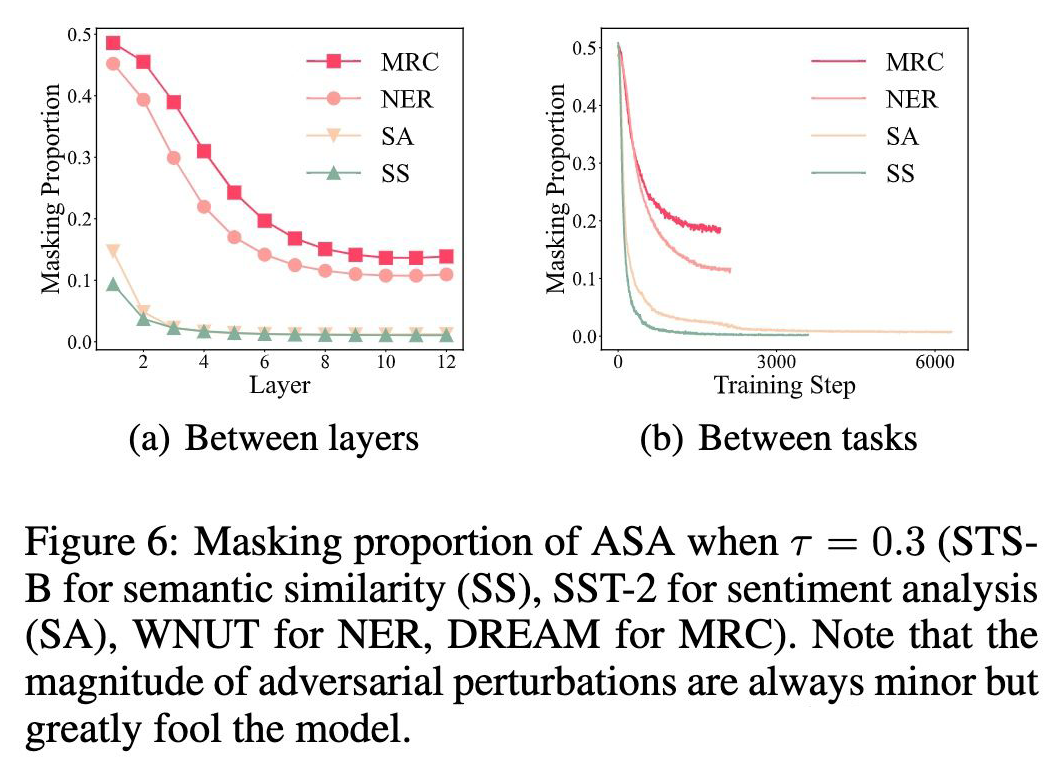
2. Bottom layers are more vulnerable
可以看到 masking 占比随着层数由底层到高层逐渐降低,更高的 masking 占比意味着层的脆弱性更高。

Conclusion
本文提出了 Adversarial Self-Attention mechanism(ASA)来提高预训练语言模型的泛化性和鲁棒性。大量实验表明本文提出的方法能够在预训练和微调阶段提升模型的鲁棒性。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·

边栏推荐
- Session
- SQL Lab (41~45) (continuous update later)
- Tutorial on the principle and application of database system (008) -- exercises on database related concepts
- 【PyTorch实战】用RNN写诗
- Several ways to clear floating
- Learning and using vscode
- SQL Lab (46~53) (continuous update later) order by injection
- 2022A特种设备相关管理(锅炉压力容器压力管道)模拟考试题库模拟考试平台操作
- The left-hand side of an assignment expression may not be an optional property access. ts(2779)
- 图形对象的创建与赋值
猜你喜欢
SQL Lab (41~45) (continuous update later)
Attack and defense world ----- summary of web knowledge points
EPP+DIS学习之路(1)——Hello world!
Epp+dis learning road (2) -- blink! twinkle!
图形对象的创建与赋值
Tutorial on principles and applications of database system (010) -- exercises of conceptual model and data model
30. Feed shot named entity recognition with self describing networks reading notes

SQL lab 11~20 summary (subsequent continuous update) contains the solution that Firefox can't catch local packages after 18 levels
SQL Lab (46~53) (continuous update later) order by injection
Vxlan static centralized gateway
随机推荐
File upload vulnerability - upload labs (1~2)
浅谈估值模型 (二): PE指标II——PE Band
SQL lab 1~10 summary (subsequent continuous update)
SQL lab 11~20 summary (subsequent continuous update) contains the solution that Firefox can't catch local packages after 18 levels
数据库安全的重要性
Static routing assignment of network reachable and telent connections
SQL lab 21~25 summary (subsequent continuous update) (including secondary injection explanation)
Financial data acquisition (III) when a crawler encounters a web page that needs to scroll with the mouse wheel to refresh the data (nanny level tutorial)
[爬虫]使用selenium时,躲避脚本检测
opencv的四个函数
[statistical learning method] learning notes - logistic regression and maximum entropy model
gcc 编译报错
密码学系列之:在线证书状态协议OCSP详解
Static comprehensive experiment
[疑难杂症]pip运行突然出现ModuleNotFoundError: No module named ‘pip‘
leetcode刷题:二叉树22(二叉搜索树的最小绝对差)
2022危险化学品生产单位安全生产管理人员考题及在线模拟考试
【统计学习方法】学习笔记——第五章:决策树
Common knowledge of one-dimensional array and two-dimensional array
数据库系统原理与应用教程(007)—— 数据库相关概念