当前位置:网站首页>4、策略学习
4、策略学习
2022-07-07 23:21:00 【C--G】
Policy Gradient with Baseline
Policy Gradient
- BaseLine


- Monte Carlo Approximation



- Choices of Baselines
Choice 1: b=0
**Choice 2:b is state-value **
- b = VΠ(St)




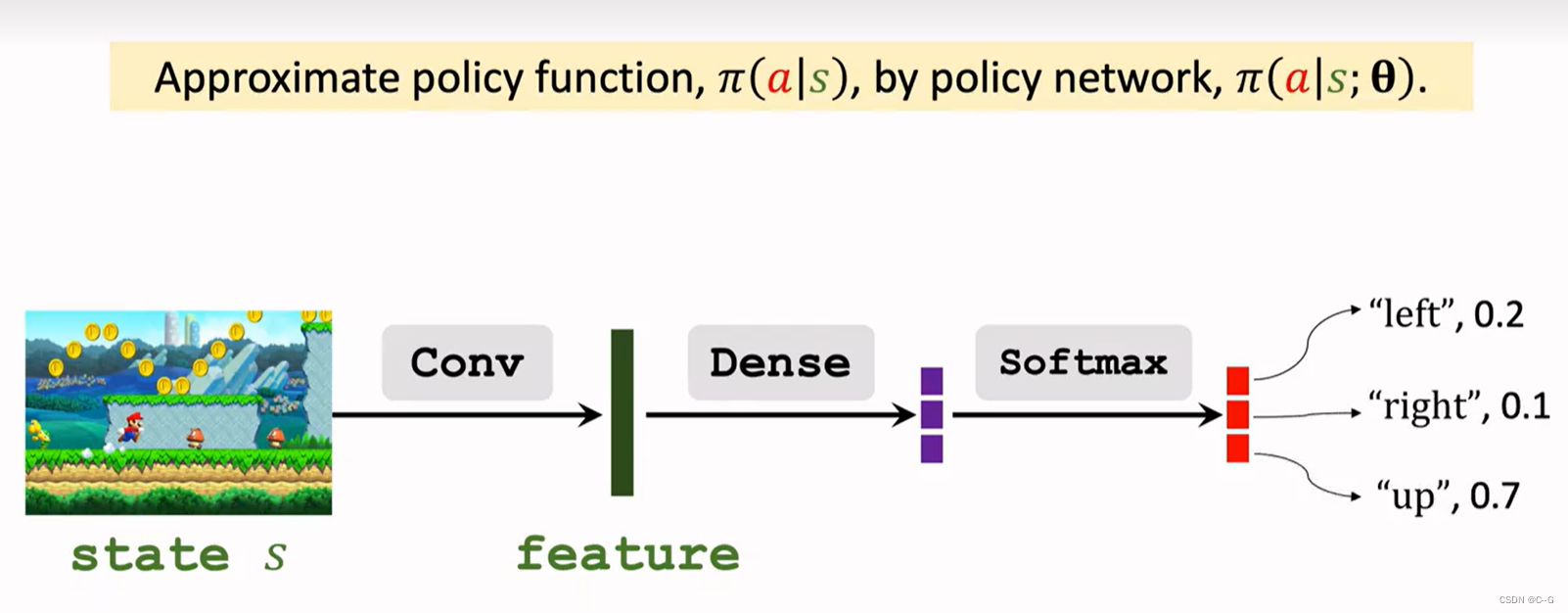
- Policy Network
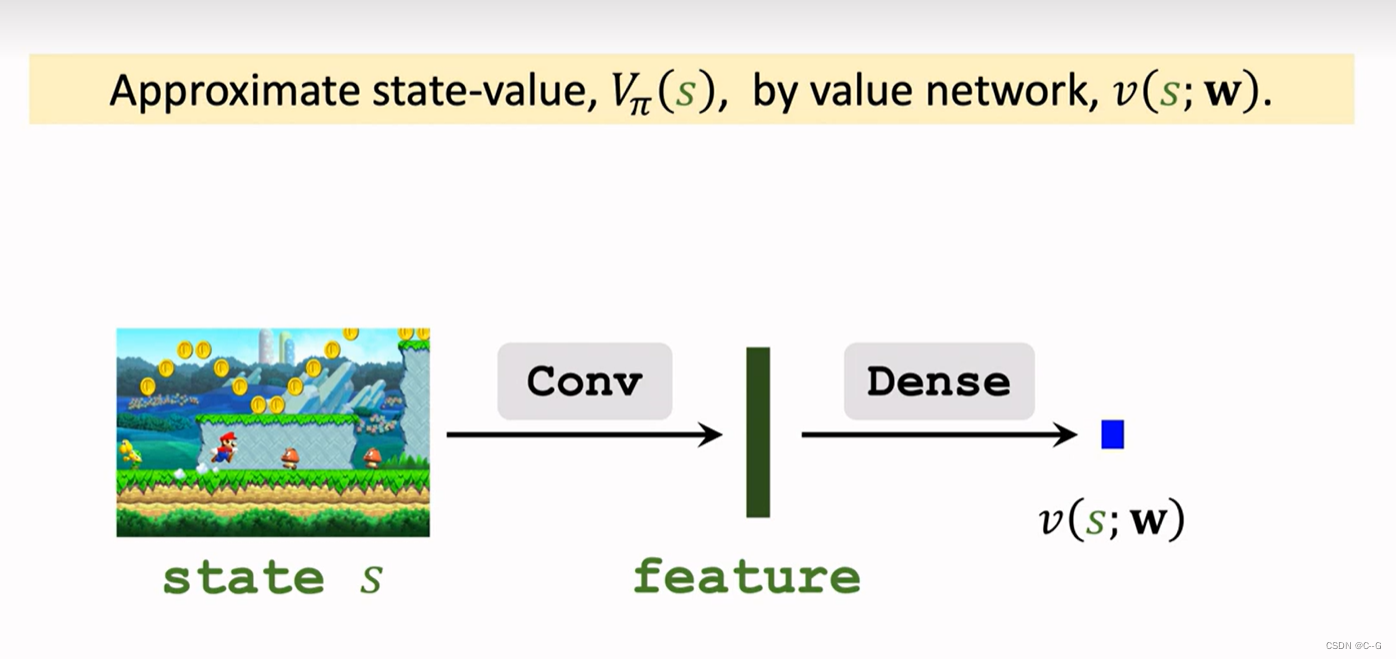
- Value Network
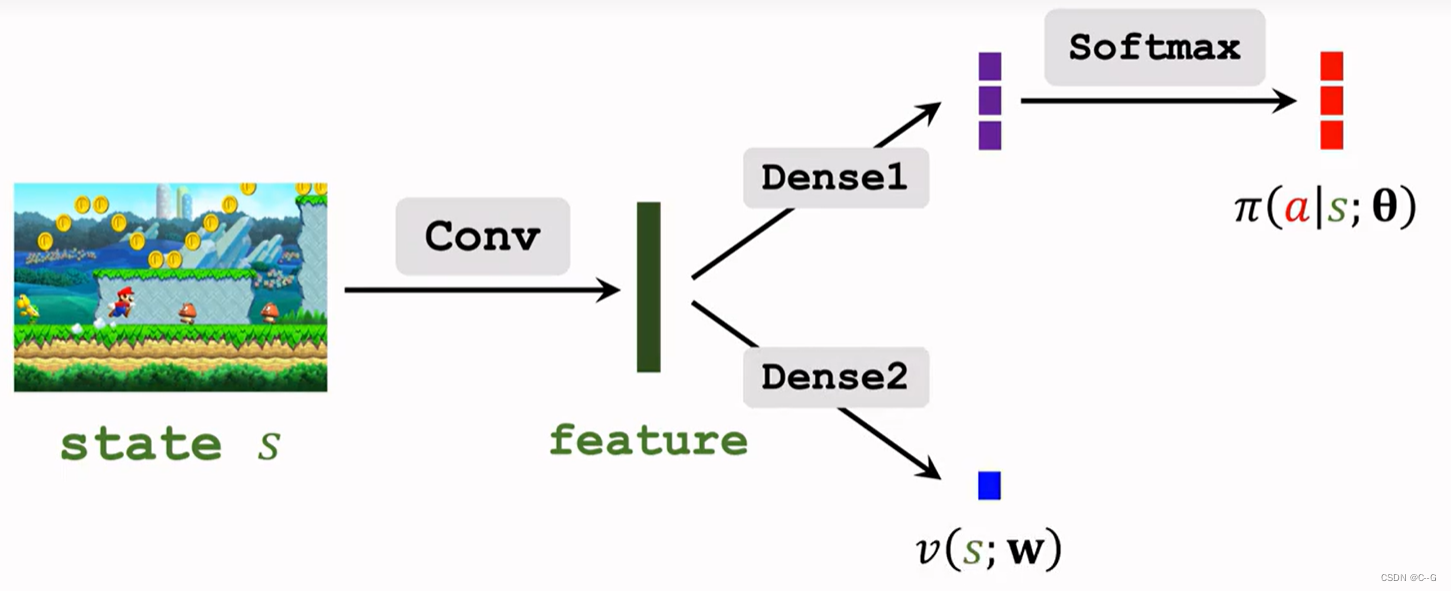
- Parameter Sharing
Reinforce with Baseline
- Updating the policy network

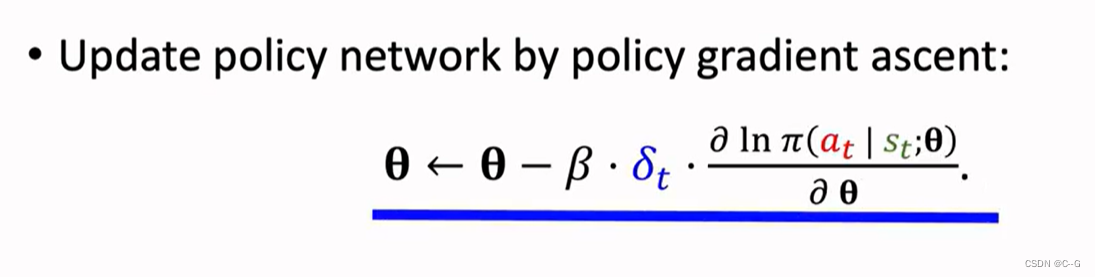

Advantage Actor-Critic(A2C)

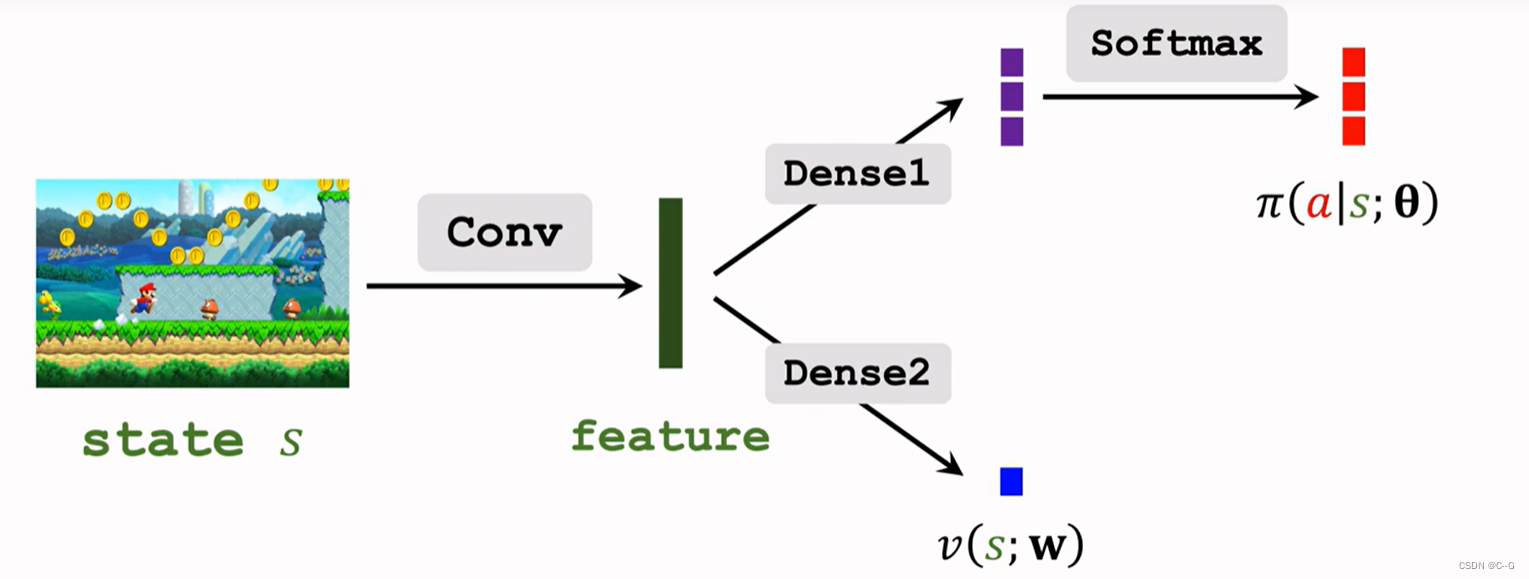

Reinforce versus A2C
两者网络结构几乎一致,价值网络不同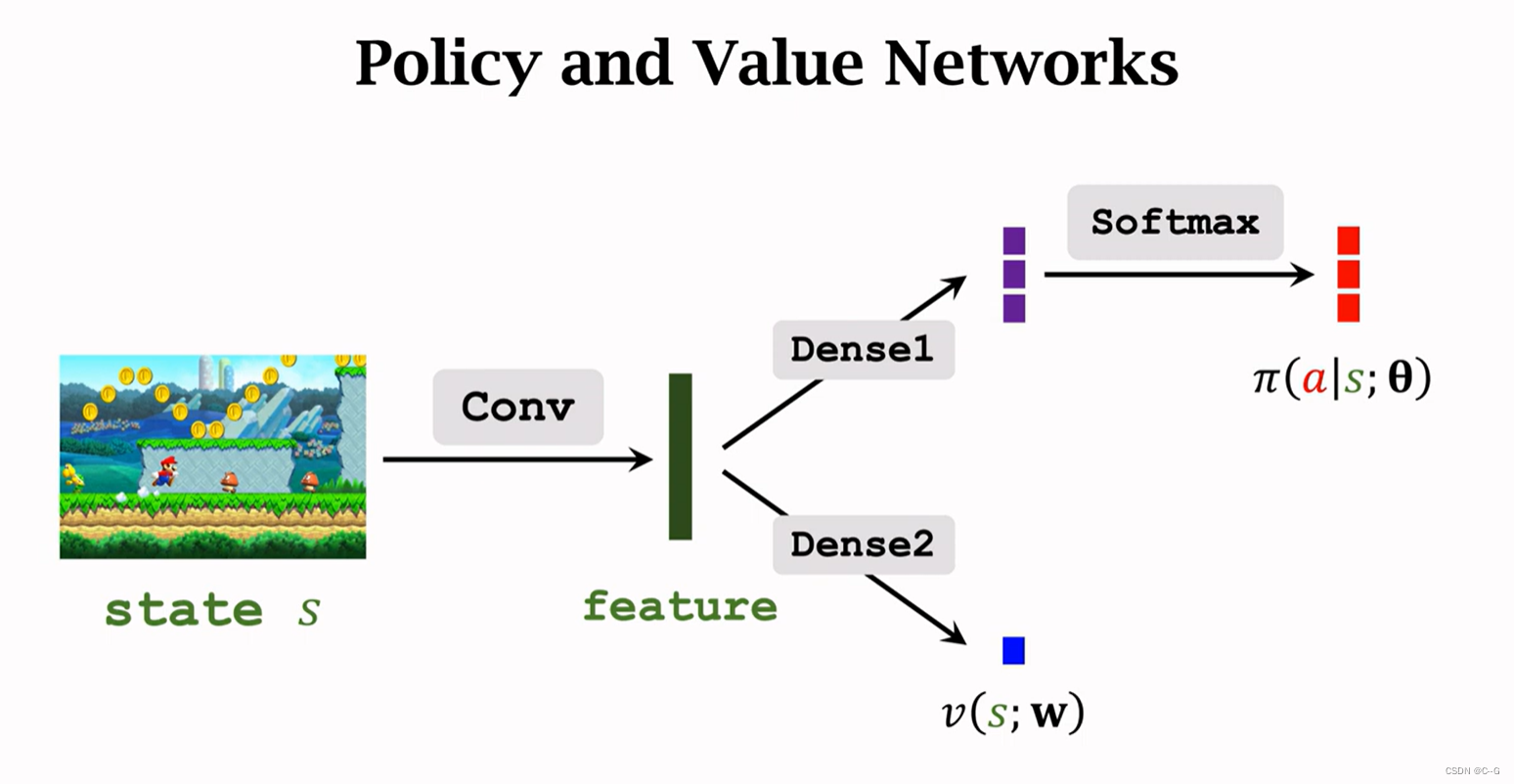
A2C with Multi-Step TD Target
one tep

Multi step
Reinforce with Baseline

versus


边栏推荐
- Marubeni official website applet configuration tutorial is coming (with detailed steps)
- A speed Limited large file transmission tool for every major network disk
- Fofa attack and defense challenge record
- Know how to get the traffic password
- Image data preprocessing
- Introduction to the types and repair methods of chip Eco
- y59.第三章 Kubernetes从入门到精通 -- 持续集成与部署(三二)
- AI遮天传 ML-回归分析入门
- AI zhetianchuan ml novice decision tree
- [go record] start go language from scratch -- make an oscilloscope with go language (I) go language foundation
猜你喜欢

解决报错:npm WARN config global `--global`, `--local` are deprecated. Use `--location=global` instead.
Scheme selection and scheme design of multifunctional docking station for type C to VGA HDMI audio and video launched by ange in Taiwan | scheme selection and scheme explanation of usb-c to VGA HDMI c
12. RNN is applied to handwritten digit recognition
133. Clone map

Complete model training routine
Know how to get the traffic password
1. Linear regression
11. Recurrent neural network RNN
12.RNN应用于手写数字识别

For the first time in China, three Tsinghua Yaoban undergraduates won the stoc best student thesis award
随机推荐
Su embedded training - Day6
Chapter improvement of clock -- multi-purpose signal modulation generation system based on ambient optical signal detection and custom signal rules
Complete model training routine
Fofa attack and defense challenge record
130. 被围绕的区域
Generic configuration legend
Capstone/cs5210 chip | cs5210 design scheme | cs5210 design data
A speed Limited large file transmission tool for every major network disk
Chapter XI feature selection
Marubeni official website applet configuration tutorial is coming (with detailed steps)
C#中string用法
130. Surrounding area
9.卷积神经网络介绍
10.CNN应用于手写数字识别
13.模型的保存和载入
Connect to the previous chapter of the circuit to improve the material draft
Design method and reference circuit of type C to hdmi+ PD + BB + usb3.1 hub (rj45/cf/tf/ sd/ multi port usb3.1 type-A) multifunctional expansion dock
Ag9310 for type-C docking station scheme circuit design method | ag9310 for type-C audio and video converter scheme circuit design reference
The weight of the product page of the second level classification is low. What if it is not included?
German prime minister says Ukraine will not receive "NATO style" security guarantee