当前位置:网站首页>Chapter XI feature selection
Chapter XI feature selection
2022-07-08 01:07:00 【Intelligent control and optimization decision Laboratory of Cen】
1、 Briefly describe the purpose of feature selection .
Feature selection is an important “ Data preprocessing ” The process , In real machine learning tasks , Feature selection is usually carried out after obtaining data , Then train the learning machine . There are two main purposes for our feature selection :
- Reduce the disaster of dimensionality
We often encounter the problem of dimension disaster in real tasks , This is caused by too many attributes , If you can choose important features , So that the subsequent learning process only needs to build a model on some features , Then the disaster of dimension will be greatly reduced . In that sense , The motivation of feature selection is similar to that of dimensionality reduction introduced in Chapter 10 . - Reduce the difficulty of learning tasks
Removing irrelevant features often reduces the difficulty of learning tasks , It's like a detective solving a case , If you strip the cocoon of complicated factors , Leave only the key elements , The truth is often easier to see .
2、 Try to compare the similarities and differences between feature selection and dimension reduction methods introduced in Chapter 10 .
The purpose of dimensionality reduction and feature selection is to reduce the data dimension . But in fact, the difference between the two is very big , Their essence is completely different . Now let's focus on the difference between the two :
- Dimension reduction
Dimensionality reduction is essentially mapping from one dimension space to another , The number of features does not decrease , Of course, in the process of mapping, the eigenvalues will change accordingly . for instance , Now it's characterized by 1000 dimension , We want to bring it down to 500 dimension . The process of dimensionality reduction is to find a new one 1000 Dimension maps to 500 Mapping of dimensions . In raw data 1000 Features , Each corresponds to the dimension reduced 500 A value in dimensional space . Suppose that the value of one of the original features is 9, Then the corresponding value after dimension reduction may be 3. - feature selection
Feature selection is to select part of the extracted features as training set features , The feature does not change its value before and after selection , But the feature dimension after selection must be smaller than before , After all, we only chose some of the features . for instance , Now it's characterized by 1000 dimension , Now we are going to start from here 1000 Choose among the features 500 individual , Well, this 500 The value of each feature is the same as that of the corresponding original feature 500 The two eigenvalues are exactly the same . For another 500 Features that were not selected were directly discarded . Suppose that the value of one of the original features is 9, Then feature selection after selecting this feature, its value is still 9, It hasn't changed .
3、 According to the selection strategy, feature selection can be divided into what kinds , Explain their characteristics respectively .
Filter selection
The filtering method is to select the features of the data set first , And then train the learner . The feature selection process has nothing to do with the subsequent learners , This is equivalent to first analyzing the initial characteristics “ Filter ”, Then use the filtered features to train the model .
Filter selection methods include :
1. Remove low variance features ;
2. Correlation coefficient ranking , The correlation coefficient between each feature and the output value is calculated separately , Set a threshold , Select some features whose correlation coefficient is greater than the threshold ;
3. The correlation between features and output values is obtained by hypothesis test , Methods include, for example, chi square test 、t test 、F Inspection, etc .
4. Mutual information , Using mutual information, the correlation is analyzed from the perspective of information entropy .Package selection
Wrap type continuously selects feature subsets from the initial feature set , Training learner , Evaluate the subset according to the performance of the learner , Until the best subset is selected . Wrapped feature selection is directly optimized for a given learner .
advantage : From the performance of the final learner , Wrapped is better than filtered ;
shortcoming : Because the learner needs to be trained many times in the process of feature selection , Therefore, the computational cost of wrapped feature selection is usually larger than that of filtered feature selection .Embedded options
Embedded feature selection integrates feature selection and learner training , Both are completed in the same optimization process , Feature selection is also automatically carried out in the process of learner training .
The main idea is : In the process of determining the model , Pick out the attributes that are important to the training of the model .
4、 Try to write Relief-F Algorithm description of .
Relief The algorithm is simple and efficient , But it can only handle two kinds of data , The improved Relief-F Algorithm , It can deal with many kinds of problems .Relief-F When dealing with multi class problems , Take one sample randomly from the training sample set each time R, Then from and R Find similar samples R Of k Nearest neighbor samples (near Hits), From each R Of different classes of samples k Nearest neighbor samples (near Misses), Then update the weight of each feature , It is shown in the following formula :
W ( A ) = W ( A ) − ∑ j = 1 k d i f f ( A , R , H j ) / ( m k ) + ∑ C ∉ c l a s s ( R ) [ p ( C ) 1 − p ( c l a s s ( R ) ) ∑ j = 1 k d i f f ( A , R , M j ( C ) ) ] / ( m k ) W(A)=W(A)-\sum_{j=1}^{k}diff(A,R,H_j)/(mk)+\sum_{C\notin class(R)}[\frac{p(C)}{1-p(class(R))}\sum_{j=1}^{k}diff(A,R,M_j(C))]/(mk) W(A)=W(A)−∑j=1kdiff(A,R,Hj)/(mk)+∑C∈/class(R)[1−p(class(R))p(C)∑j=1kdiff(A,R,Mj(C))]/(mk)
upper-middle d i f f ( A , R 1 , R 2 ) diff(A,R_1,R_2) diff(A,R1,R2) Representative sample R 1 R_1 R1 and R 2 R_2 R2 In character A A A The difference in , M j ( C ) M_j(C) Mj(C) Represents a class C ∉ c l a s s ( R ) C\notin class(R) C∈/class(R) pass the civil examinations j j j Nearest neighbor samples , As follows :
d i f f ( A , R 1 , R 2 ) = { ∣ R 1 [ A ] − R 2 [ A ] ∣ m a x ( A ) − m i n ( A ) if A is continuous 0 if A is discrete and R 1 [ A ] ≠ R 2 [ A ] 1 if A is discrete and R 1 [ A ] = R 2 [ A ] diff(A,R_1,R_2)=\left\{ \begin{array}{rcl} \frac{|R_1[A]-R_2[A]|}{max(A)-min(A)} & &\text{if A is continuous} \\ 0 & & \text{if A is discrete and $R_1[A]\neq R_2[A]$}\\ 1 && \text{if A is discrete and $R_1[A]= R_2[A]$} \end{array} \right. diff(A,R1,R2)=⎩⎨⎧max(A)−min(A)∣R1[A]−R2[A]∣01if A is continuousif A is discrete and R1[A]=R2[A]if A is discrete and R1[A]=R2[A]
The significance of weight lies in , Subtract the difference of this feature of the same classification , Add the difference of this feature in different classifications .( If the feature is related to classification , Then the value of the feature of the same classification should be similar , The values of different categories should be different ).
5、 Try to describe the basic framework of filtering and wrapping selection methods .
Filtering selection is to design a filtering method for feature selection , Then train the learner . And this filtering method is to design a “ Correlation statistics ”, To calculate the characteristics , Finally, set a threshold to choose . Calculation of relevant statistics : For each sample x i x_i xi, He can do the following things : Find out the same kind , The nearest sample x 1 x_1 x1 ; In the alien , Find the nearest x 2 x_2 x2 . If x i x_i xi And x 1 x_1 x1 A more recent , It shows that features are beneficial to the same kind and different kinds , Will increase the corresponding statistics ; conversely , If x i x_i xi And x 2 x_2 x2 A more recent , Explain that the feature plays a side effect , Will reduce the corresponding statistics . As shown in the figure below :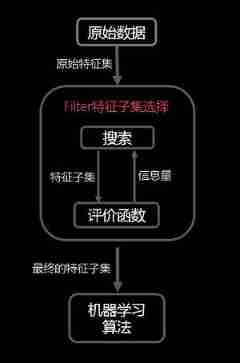
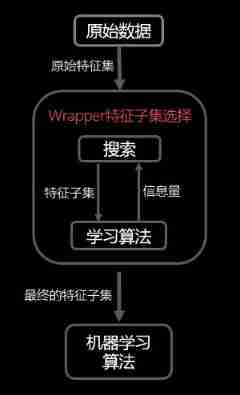
2. The feature selection process of wrapped selection method is related to learners , It directly uses the performance of the learner as the evaluation criterion of feature selection , Select the feature subset that is most conducive to the performance of the learner . As shown in the figure below :
边栏推荐
- Application practice | the efficiency of the data warehouse system has been comprehensively improved! Data warehouse construction based on Apache Doris in Tongcheng digital Department
- Marubeni official website applet configuration tutorial is coming (with detailed steps)
- Stock account opening is free of charge. Is it safe to open an account on your mobile phone
- Codeforces Round #804 (Div. 2)(A~D)
- AI遮天传 ML-回归分析入门
- How is it most convenient to open an account for stock speculation? Is it safe to open an account on your mobile phone
- Su embedded training - Day8
- C# ?,?.,?? .....
- C#中string用法
- Introduction to paddle - using lenet to realize image classification method II in MNIST
猜你喜欢
Where is the big data open source project, one-stop fully automated full life cycle operation and maintenance steward Chengying (background)?
A network composed of three convolution layers completes the image classification task of cifar10 data set
基于卷积神经网络的恶意软件检测方法
【愚公系列】2022年7月 Go教学课程 006-自动推导类型和输入输出
130. 被围绕的区域
英雄联盟胜负预测--简易肯德基上校
Using GPU to train network model
![[note] common combined filter circuit](/img/2f/a8c2ef0d76dd7a45b50a64a928a9c8.png)
[note] common combined filter circuit
[Yugong series] go teaching course 006 in July 2022 - automatic derivation of types and input and output
ThinkPHP kernel work order system source code commercial open source version multi user + multi customer service + SMS + email notification
随机推荐
[Yugong series] go teaching course 006 in July 2022 - automatic derivation of types and input and output
133. 克隆图
The whole life cycle of commodity design can be included in the scope of industrial Internet
Complete model training routine
Invalid V-for traversal element style
1.线性回归
Using GPU to train network model
jemter分布式
Cascade-LSTM: A Tree-Structured Neural Classifier for Detecting Misinformation Cascades(KDD20)
v-for遍历元素样式失效
Interface test advanced interface script use - apipost (pre / post execution script)
Su embedded training - Day6
swift获取url参数
[note] common combined filter circuit
Image data preprocessing
130. 被圍繞的區域
Reentrantlock fair lock source code Chapter 0
Y59. Chapter III kubernetes from entry to proficiency - continuous integration and deployment (III, II)
Swift get URL parameters
11.递归神经网络RNN