当前位置:网站首页>Complete model verification (test, demo) routine
Complete model verification (test, demo) routine
2022-07-08 01:01:00 【booze-J】
article
Network model training and preservation reference utilize GPU Training network models , And the loaded network model is also trained by the code in this article .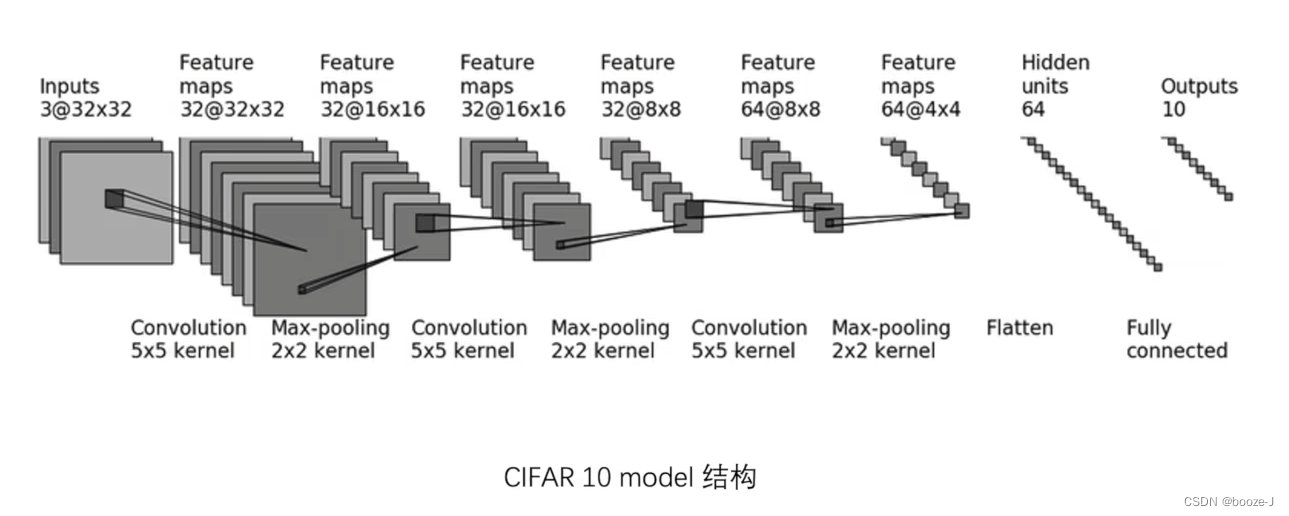
Validation model sample code :
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
# Get the picture storage path
image_path = "./images/img.png"
# Read the picture
image = Image.open(image_path)
# The type of picture read is <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=296x183 at 0x1FBD755E340>
print("image:\n",image)
image = image.convert("RGB")
''' The next step is to image Do channel conversion , because png The format is four channel , except RGB Outside of three channels , There is also a transparency channel . So we call image = image.convert("RGB"), Keep its color channel Of course , If the picture is originally three color channels , After this operation , unchanged . With this step, you can adapt png,jpg Pictures in various formats 、 '''
# [Resize](https://pytorch.org/vision/stable/generated/torchvision.transforms.Resize.html?highlight=resize#torchvision.transforms.Resize)
# Why Resize This step ? Because the required input of our network model is 32*32 Size picture
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
# take image Convert to the appropriate type
image = transform(image)
print("image:\n",image.shape) # torch.Size([3, 32, 32])
# Building neural networks ( Open a separate file to store the network model )
class Booze(nn.Module):
def __init__(self):
super(Booze, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
# Load network model
model = torch.load("./model/obj_0.pth")
# Transform the picture into four-dimensional (3,32,32) -> (1,3,32,32)
image = torch.reshape(image,(1,3,32,32))
# Define the equipment used for the test Different training methods of models (GPU Training 、CPU Training ) The data type when testing is also different
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Look at the model
print(model)
model.eval() # When it comes to testing , You may often forget this step
with torch.no_grad(): # # You may often forget this step
# Model if used cuda Trained , You also need to use cuda Type of data to test
output = model(image.to(device))
''' tensor([[-1.1961, 0.1016, 0.6076, 0.5585, 0.4856, 0.4466, 0.4176, 0.3158, -1.4603, -0.5929]], device='cuda:0') You can see output contain 10 Data , Each data represents a probability that the test image belongs to this class '''
print(output)
# Print out the category predicted by the test image using the network model The discovery is different from the actual category The reason is that the training times of the network model are less More accurate network models can be obtained by increasing training batches and adjusting learning rates
print(output.argmax(1).item())
Some points needing attention are described in detail in the comments in the code .
Be careful
- png The format is four channel , except RGB Outside of three channels , There is also a transparency channel . So we call
image = image.convert("RGB"), Keep its color channel of course , If the picture is originally three color channels , After this operation , unchanged . - Before the picture to be predicted is introduced into the network model for prediction , Pretreatment is needed first , Whether the image size meets the input requirements , Whether the image format and dimension meet the requirements, etc .
- Model if used cuda Trained , You also need to use cuda Type of data to test
- Print out the category predicted by the test image using the network model , The discovery is different from the actual category , The reason is that the training times of the network model are less or the learning rate is inappropriate , More accurate network models can be obtained by increasing training batches and adjusting learning rates .
边栏推荐
- Malware detection method based on convolutional neural network
- Kubernetes Static Pod (静态Pod)
- 新库上线 | CnOpenData中国星级酒店数据
- Introduction to ML regression analysis of AI zhetianchuan
- 大二级分类产品页权重低,不收录怎么办?
- 完整的模型验证(测试,demo)套路
- Cascade-LSTM: A Tree-Structured Neural Classifier for Detecting Misinformation Cascades(KDD20)
- 英雄联盟胜负预测--简易肯德基上校
- How is it most convenient to open an account for stock speculation? Is it safe to open an account on your mobile phone
- Stock account opening is free of charge. Is it safe to open an account on your mobile phone
猜你喜欢
CVE-2022-28346:Django SQL注入漏洞
New library online | cnopendata China Star Hotel data
My best game based on wechat applet development
基于人脸识别实现课堂抬头率检测
Kubernetes Static Pod (静态Pod)
【深度学习】AI一键换天
11.递归神经网络RNN
![[go record] start go language from scratch -- make an oscilloscope with go language (I) go language foundation](/img/76/b048e100d2c964ac00bc4f64e97e7a.png)
[go record] start go language from scratch -- make an oscilloscope with go language (I) go language foundation
FOFA-攻防挑战记录
Application practice | the efficiency of the data warehouse system has been comprehensively improved! Data warehouse construction based on Apache Doris in Tongcheng digital Department
随机推荐
tourist的NTT模板
新库上线 | CnOpenData中华老字号企业名录
130. Zones environnantes
Deep dive kotlin synergy (XXII): flow treatment
From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run
Cancel the down arrow of the default style of select and set the default word of select
Su embedded training - Day7
C# ?,?.,?? .....
QT adds resource files, adds icons for qaction, establishes signal slot functions, and implements
Which securities company has a low, safe and reliable account opening commission
DNS series (I): why does the updated DNS record not take effect?
NTT template for Tourism
基于微信小程序开发的我最在行的小游戏
国内首次,3位清华姚班本科生斩获STOC最佳学生论文奖
How does starfish OS enable the value of SFO in the fourth phase of SFO destruction?
大二级分类产品页权重低,不收录怎么办?
130. 被围绕的区域
手写一个模拟的ReentrantLock
50Mhz产生时间
攻防演练中沙盘推演的4个阶段