当前位置:网站首页>网络模型的保存与读取
网络模型的保存与读取
2022-07-07 23:11:00 【booze-J】
网络模型的保存
方式1
使用示例代码如下:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
# 加载网络模型
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1(不仅仅保存了结构还保存了网络模型中的一些参数) 模型结构+模型参数
torch.save(vgg16,"vgg16_method1.pth")
torch.save(vgg16,"vgg16_method1.pth")不仅仅保存了结构还保存了网络模型中的一些参数(保存了模型结构+模型参数)。
方式2
使用示例代码如下:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
# 加载网络模型
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式2(将vgg16网络中的参数保存成python中的字典形式) 模型参数(官方推荐)
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
torch.save(vgg16.state_dict(),"vgg16_method2.pth")将vgg16网络中的参数保存成python中的字典形式(保存模型参数(官方推荐)),相当于加载的时候需要先加载网络模型,再加载参数。
网络模型的读取
方式1
使用示例代码如下:
import torchvision
import torch
# 方式1 -》 保存方式1 加载模型+参数
model = torch.load("vgg16_method1.pth")
print("model",model)
前提是使用网络模型保存的方式1,直接使用model = torch.load("vgg16_method1.pth")便可以加载模型和参数。
方式2
使用示例代码如下:
import torchvision
import torch
# 加载网络模型
vgg16 = torchvision.models.vgg16(pretrained=False)
# 方式2 -》 保存方式2 加载参数
model = torch.load("vgg16_method2.pth")
print("model:\n",model)
# 将模型参数添加到模型中
vgg16.load_state_dict(model)
前提是使用网络模型保存的方式2,使用model = torch.load("vgg16_method2.pth")加载只能把模型参数加载出来,好需要将网络模型加载出来vgg16 = torchvision.models.vgg16(pretrained=False),然后把模型参数添加到模型中vgg16.load_state_dict(model)。
网络模型的保存与读取的陷阱
自己写一个简单网络,然后使用方式1保存。
示例代码:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
# 搭建神经网络
class Booze(nn.Module):
# 继承nn.Module的初始化
def __init__(self):
super(Booze, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
# 重写forward函数
def forward(self,x):
output = self.maxpool1(x)
return output
obj = Booze()
# 保存网络模型
torch.save(obj,"obj_method1.pth")
运行代码,网络模型保存成功之后,我们加载一下网络模型试试看
import torchvision
import torch
model = torch.load("obj_method1.pth")
print("model",model)
结果发现: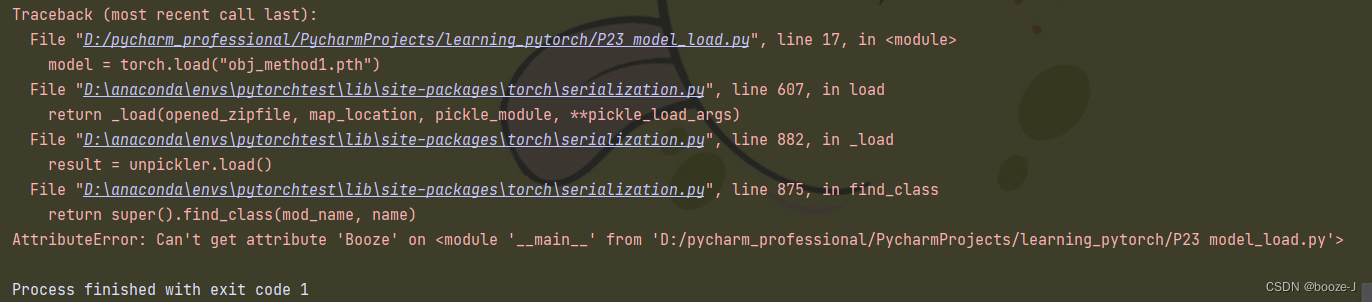
直接这样加载模型会报错!那怎么解决呢?
import torchvision
import torch
from torch import nn
from torch.nn import MaxPool2d
# 搭建神经网络
class Booze(nn.Module):
# 继承nn.Module的初始化
def __init__(self):
super(Booze, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
# 重写forward函数
def forward(self,x):
output = self.maxpool1(x)
return output
# 陷阱1
model = torch.load("obj_method1.pth")
print("model",model)
在加载模型的代码中添加上,搭建神经网络的代码,再运行,就不会报错。
边栏推荐
- 2022-07-07: the original array is a monotonic array with numbers greater than 0 and less than or equal to K. there may be equal numbers in it, and the overall trend is increasing. However, the number
- 丸子官网小程序配置教程来了(附详细步骤)
- AI zhetianchuan ml novice decision tree
- [go record] start go language from scratch -- make an oscilloscope with go language (I) go language foundation
- ThinkPHP kernel work order system source code commercial open source version multi user + multi customer service + SMS + email notification
- 英雄联盟胜负预测--简易肯德基上校
- Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布
- 基于人脸识别实现课堂抬头率检测
- Huawei switch s5735s-l24t4s-qa2 cannot be remotely accessed by telnet
- New library online | cnopendata China Star Hotel data
猜你喜欢
AI遮天传 ML-初识决策树
4.交叉熵
【笔记】常见组合滤波电路

Tapdata 的 2.0 版 ,开源的 Live Data Platform 现已发布
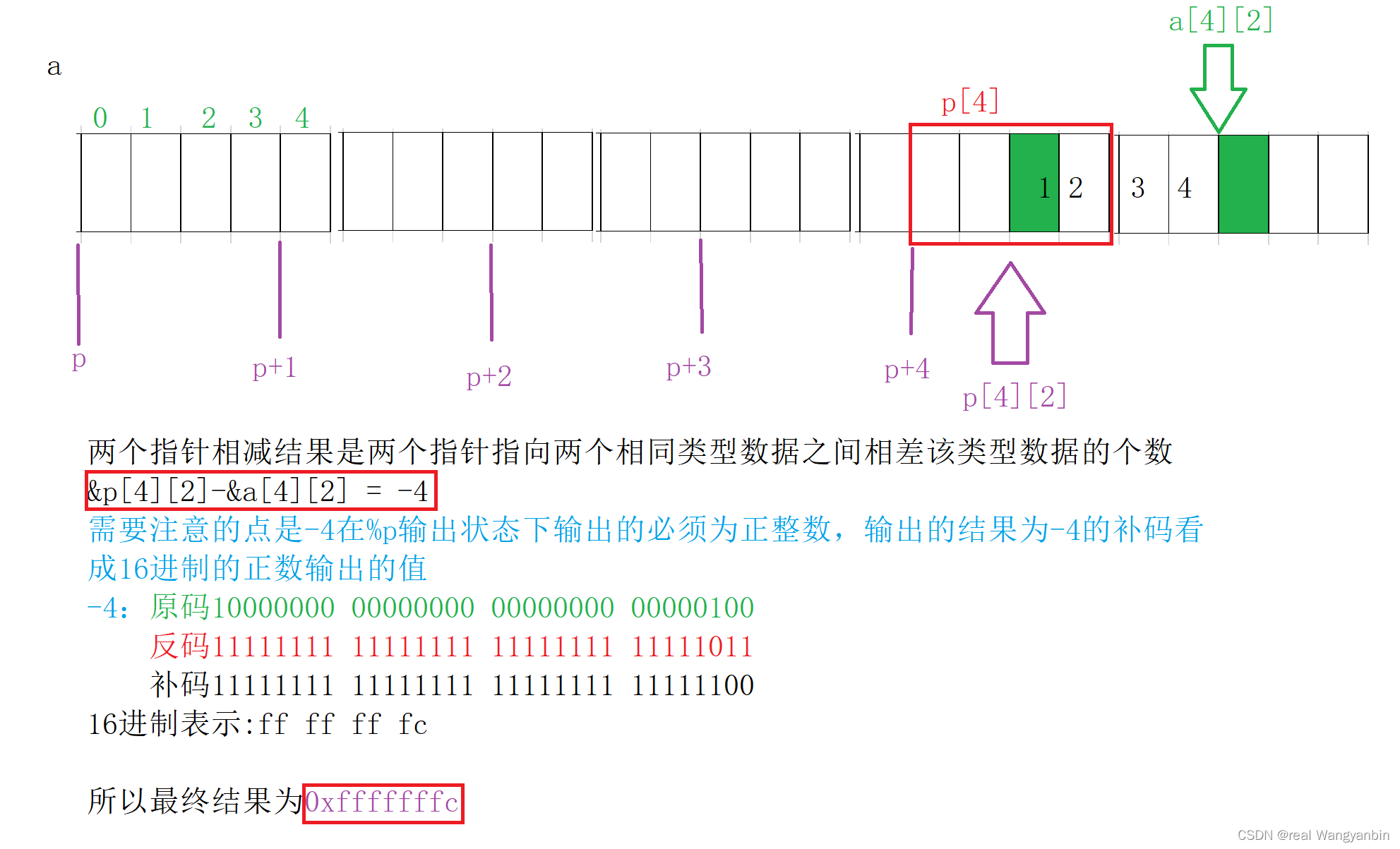
Analysis of 8 classic C language pointer written test questions

Codeforces Round #804 (Div. 2)(A~D)
![[necessary for R & D personnel] how to make your own dataset and display it.](/img/50/3d826186b563069fd8d433e8feefc4.png)
[necessary for R & D personnel] how to make your own dataset and display it.
"An excellent programmer is worth five ordinary programmers", and the gap lies in these seven key points
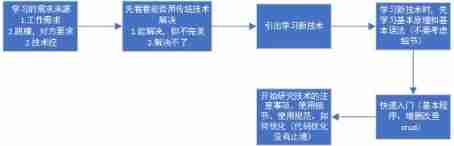
How to learn a new technology (programming language)
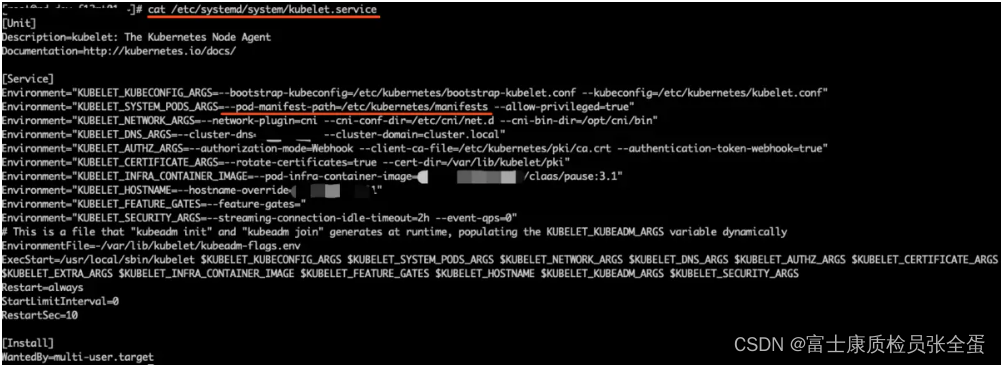
Kubernetes Static Pod (静态Pod)
随机推荐
Semantic segmentation model base segmentation_ models_ Detailed introduction to pytorch
fabulous! How does idea open multiple projects in a single window?
Letcode43: string multiplication
Lecture 1: the entry node of the link in the linked list
What is load balancing? How does DNS achieve load balancing?
【obs】Impossible to find entrance point CreateDirect3D11DeviceFromDXGIDevice
Summary of the third course of weidongshan
【obs】Impossible to find entrance point CreateDirect3D11DeviceFromDXGIDevice
[OBS] the official configuration is use_ GPU_ Priority effect is true
New library online | information data of Chinese journalists
A brief history of information by James Gleick
9.卷积神经网络介绍
8道经典C语言指针笔试题解析
Cancel the down arrow of the default style of select and set the default word of select
Play sonar
Su embedded training - Day3
FOFA-攻防挑战记录
STL -- common function replication of string class
华为交换机S5735S-L24T4S-QA2无法telnet远程访问
My best game based on wechat applet development