当前位置:网站首页>Aike AI frontier promotion (7.7)
Aike AI frontier promotion (7.7)
2022-07-07 12:32:00 【Zhiyuan community】
LG - machine learning CV - Computer vision CL - Computing and language AS - Audio and voice RO - robot
Turn from love to a lovely life
Abstract : neural network ( generalization ) And Chomsky hierarchy 、 Downstream task training data demand estimation 、 Improve attention based on levels Transformer Semantic segmentation 、 Transfer learning based on depth table model 、 The influence of model size on gender bias 、 Empirical research on implicit regularization of deep off-line reinforcement learning 、 Improve visual language navigation based on cross language environment independent representation 、 Offline reinforcement learning strategies should be trained to enhance adaptability 、 Based on the preconditioned diffusion sampling, the acceleration is based on the fractional generation model
1、[LG] Neural Networks and the Chomsky Hierarchy
G Delétang, A Ruoss, J Grau-Moya, T Genewein, L K Wenliang, E Catt, M Hutter, S Legg, P A. Ortega
[DeepMind]
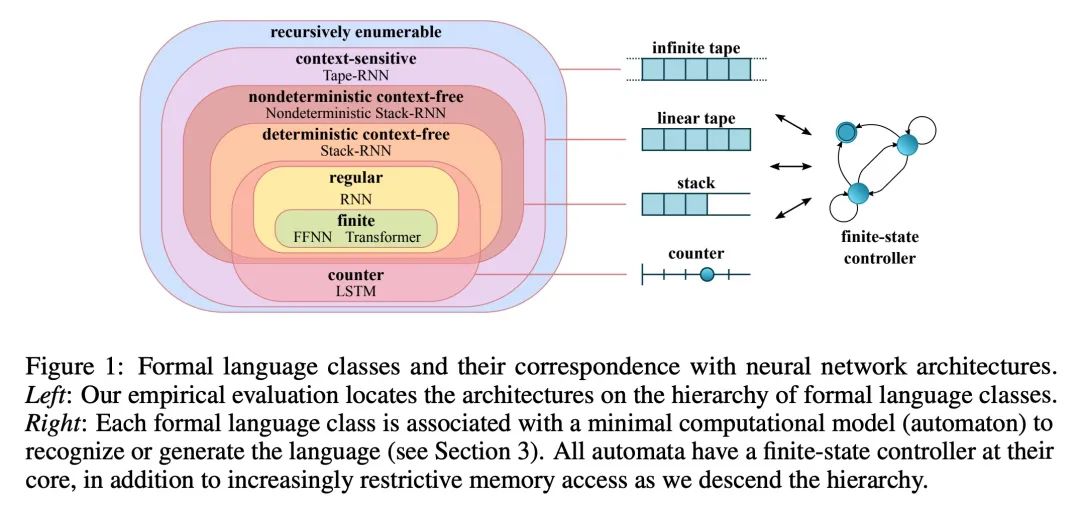
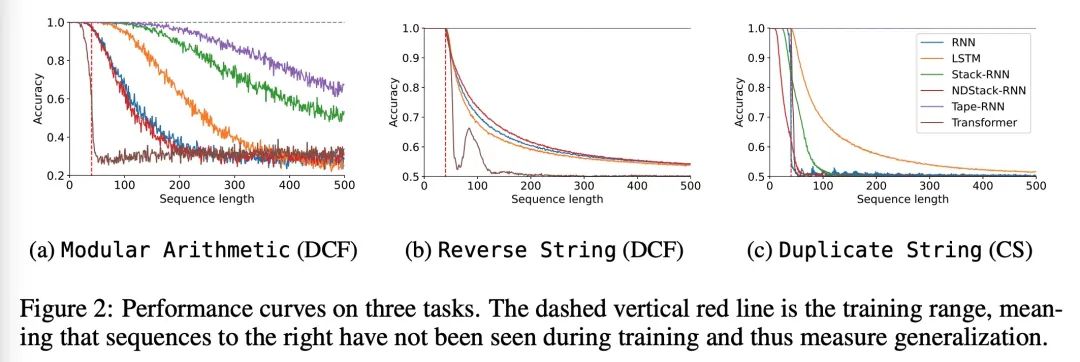
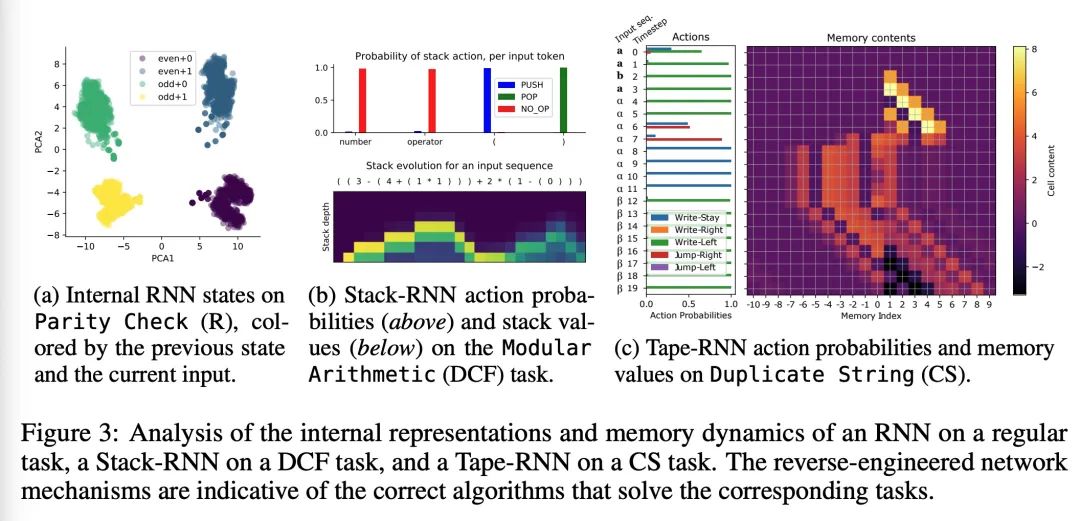
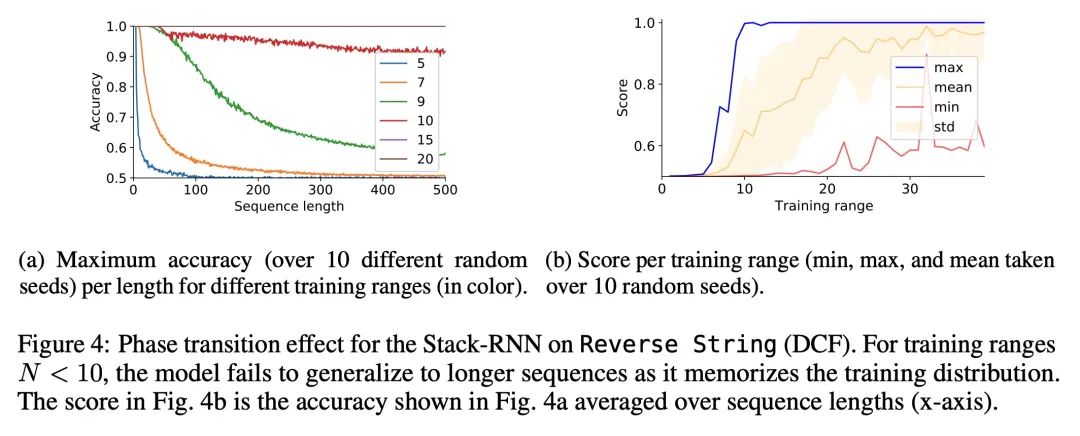
neural network ( generalization ) And Chomsky hierarchy . Reliable generalization is the core of safe machine learning and artificial intelligence . However , Understand when and how neural networks are generalized , It is still one of the most important problems to be solved in this field . This paper conducts an extensive empirical study (2200 A model ,16 A mission ), To investigate whether the insights from computational theory can predict the limits of neural network generalization in practice . Experimental proof , Group tasks according to Chomsky hierarchy , It can be predicted whether some architectures can be generalized to the input outside the distribution . This includes negative results , That is, a large amount of data and training time can not bring any extraordinary generalization , Although the model has enough ability to completely fit the training data . It turns out that , For the subset of tasks described ,RNN and Transformer Failed to generalize unconventional tasks ,LSTM It can solve routine tasks and anti language tasks , And only using structured memory ( Such as stack or memory tape ) Enhanced networks can successfully generalize context free and context sensitive tasks .
Reliable generalization lies at the heart of safe ML and AI. However, understanding when and how neural networks generalize remains one of the most important unsolved problems in the field. In this work, we conduct an extensive empirical study (2200 models, 16 tasks) to investigate whether insights from the theory of computation can predict the limits of neural network generalization in practice. We demonstrate that grouping tasks according to the Chomsky hierarchy allows us to forecast whether certain architectures will be able to generalize to out-ofdistribution inputs. This includes negative results where even extensive amounts of data and training time never led to any non-trivial generalization, despite models having sufficient capacity to perfectly fit the training data. Our results show that, for our subset of tasks, RNNs and Transformers fail to generalize on nonregular tasks, LSTMs can solve regular and counter-language tasks, and only networks augmented with structured memory (such as a stack or memory tape) can successfully generalize on context-free and context-sensitive tasks.
https://arxiv.org/abs/2207.02098

2、[CV] How Much More Data Do I Need? Estimating Requirements for Downstream Tasks
R Mahmood, J Lucas, D Acuna, D Li, J Philion, J M. Alvarez, Z Yu, S Fidler, M T. Law
[NVIDIA]
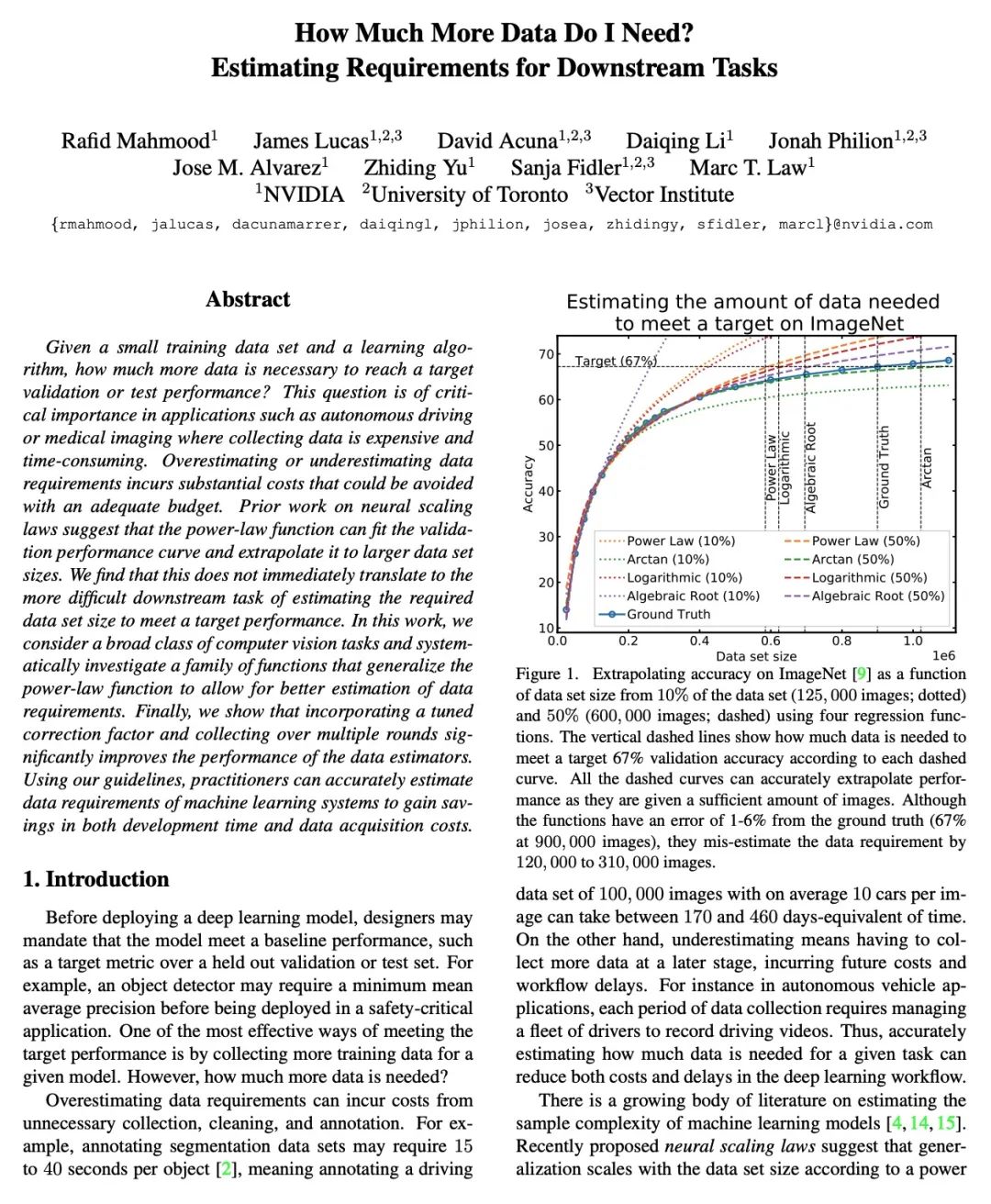
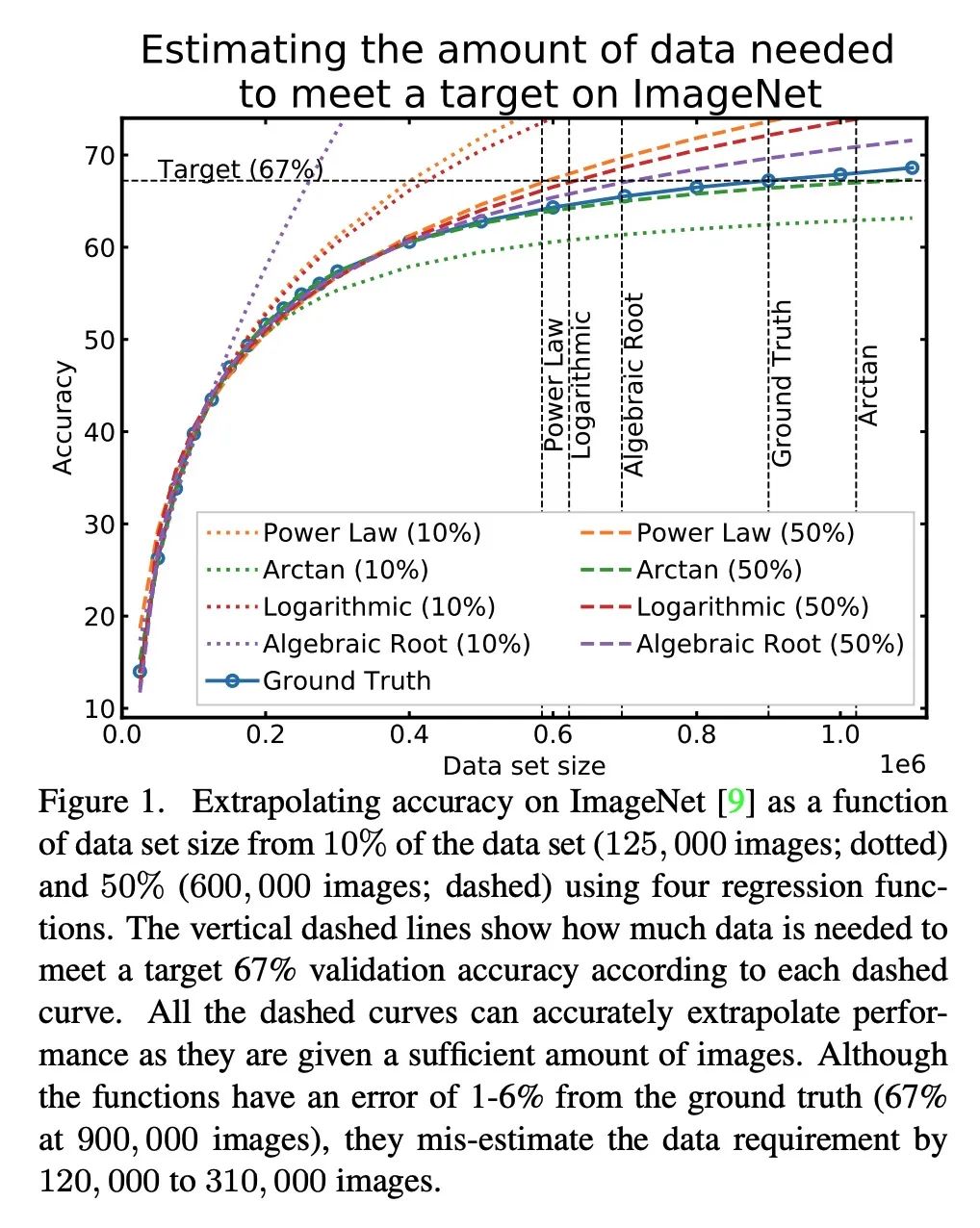
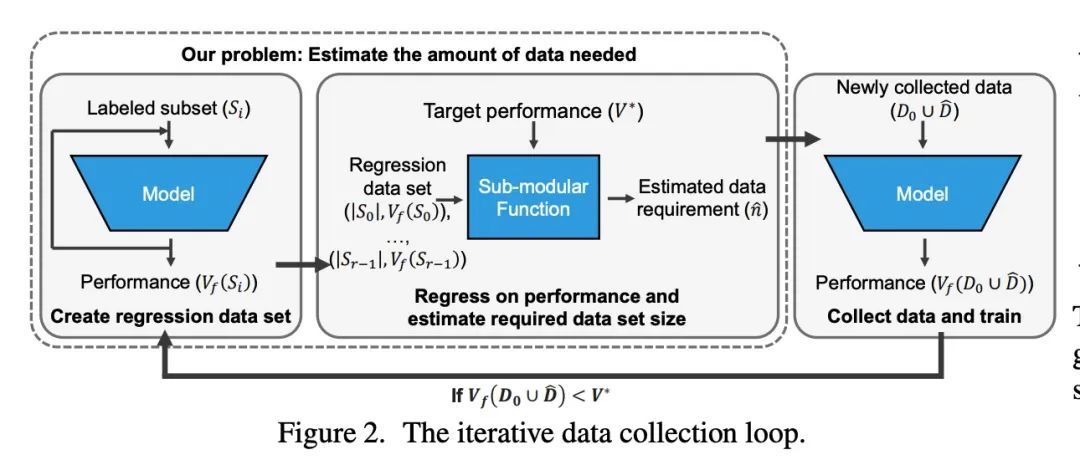
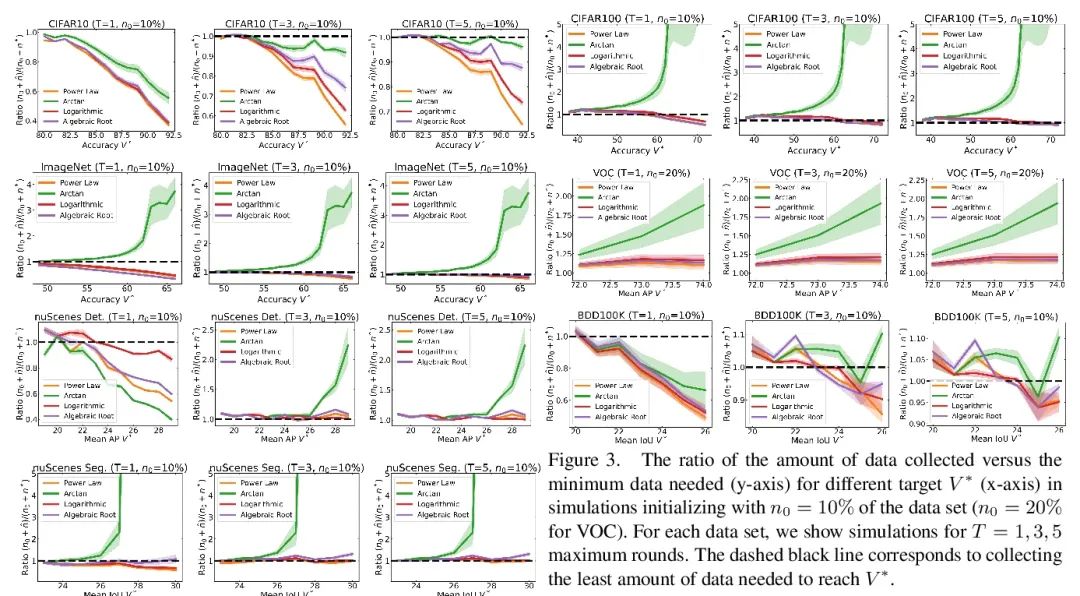
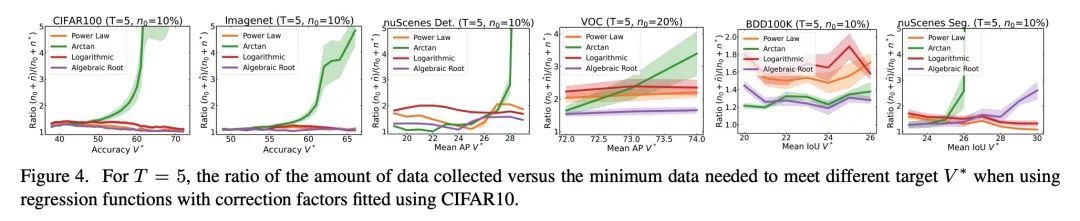
How much more data is needed ? Downstream task training data demand estimation . Given a small training data set and a learning algorithm , How much more data is needed to achieve the target verification or test performance ? This problem is crucial in applications such as driverless or medical imaging , Because in these applications , Collecting data is expensive and time-consuming . Overestimating or underestimating data demand will generate a lot of costs , And these costs can be avoided through an adequate budget . Previous work on neural scaling law has shown that , Power law function can fit and verify the performance curve , And extrapolate it to a larger dataset . This paper finds that , This cannot be directly applied to more difficult downstream tasks , To estimate the required data set size , To achieve the target performance . This paper considers a wide range of computer vision tasks , A series of functions of generalized power-law functions are systematically studied , To better estimate data needs . Experiments show that , The correction factor of fine adjustment is included and collected in multiple rounds , It can significantly improve the performance of data estimator . Use the guidelines , Practitioners can accurately estimate the data requirements of machine learning systems , To save development time and data acquisition costs .
Given a small training data set and a learning algorithm, how much more data is necessary to reach a target validation or test performance? This question is of critical importance in applications such as autonomous driving or medical imaging where collecting data is expensive and time-consuming. Overestimating or underestimating data requirements incurs substantial costs that could be avoided with an adequate budget. Prior work on neural scaling laws suggest that the power-law function can fit the validation performance curve and extrapolate it to larger data set sizes. We find that this does not immediately translate to the more difficult downstream task of estimating the required data set size to meet a target performance. In this work, we consider a broad class of computer vision tasks and systematically investigate a family of functions that generalize the power-law function to allow for better estimation of data requirements. Finally, we show that incorporating a tuned correction factor and collecting over multiple rounds significantly improves the performance of the data estimators. Using our guidelines, practitioners can accurately estimate data requirements of machine learning systems to gain savings in both development time and data acquisition costs.
https://arxiv.org/abs/2207.01725
3、[CV] Improving Semantic Segmentation in Transformers using Hierarchical Inter-Level Attention
G Leung, J Gao, X Zeng, S Fidler
[University of Toronto]
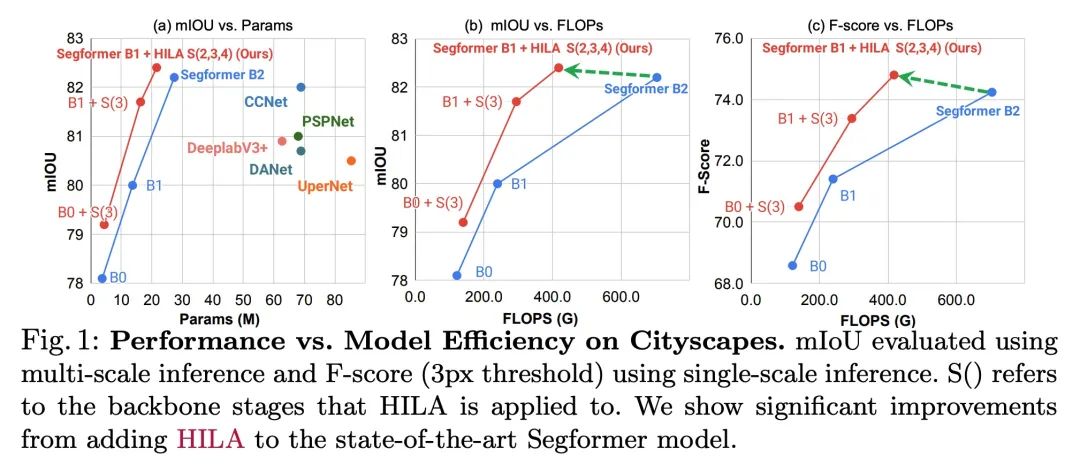
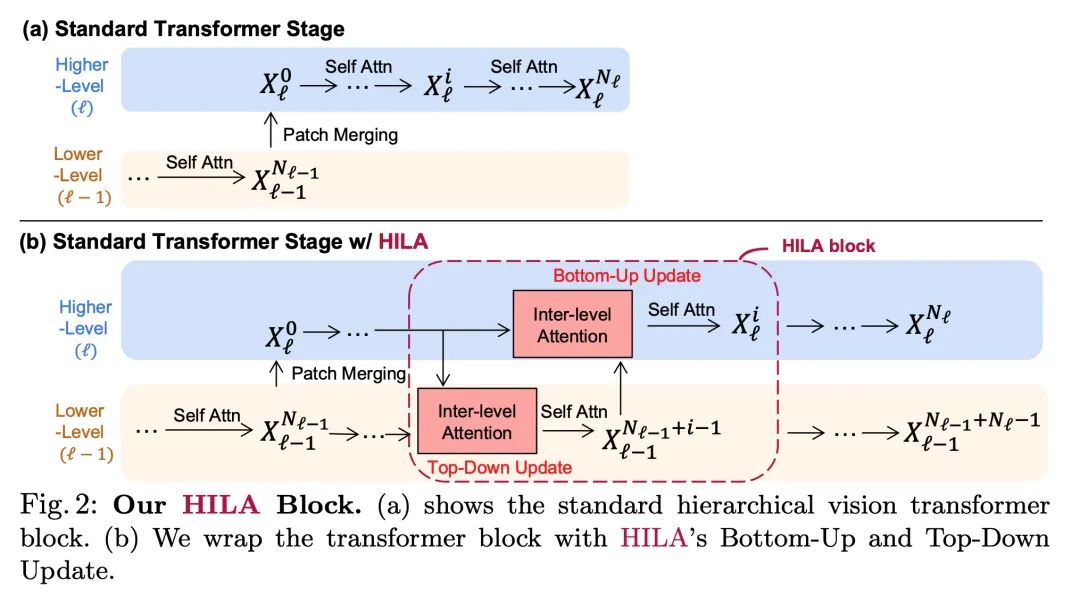
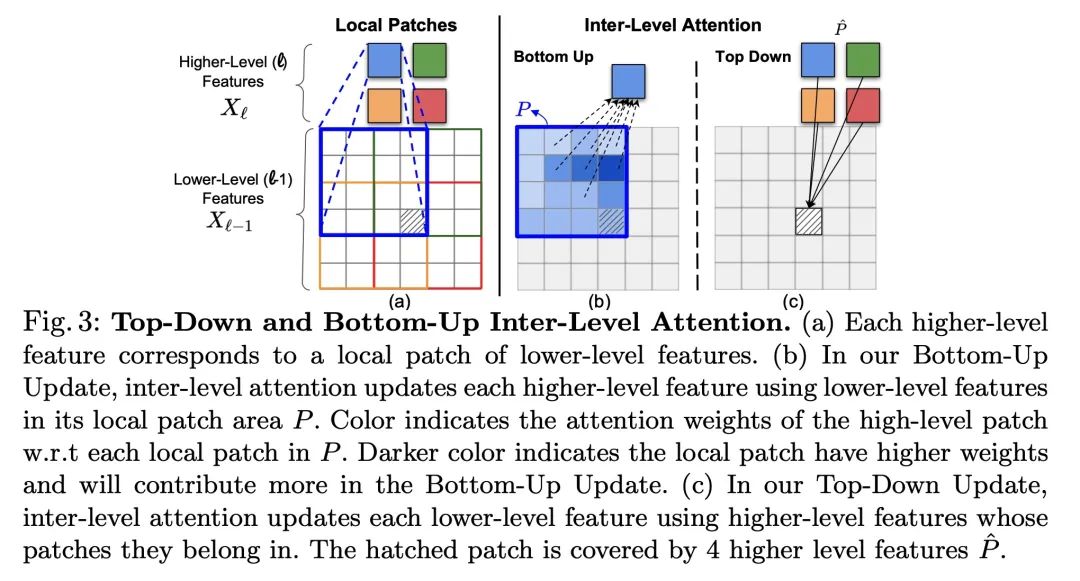
Improve attention based on levels Transformer Semantic segmentation . Existing based on Transformers Image skeleton , Usually, feature information is transmitted from low level to high level in one direction . This may not be ideal , Because the positioning ability of accurately dividing the object boundary is low 、 High resolution feature map is the most prominent , The semantics of image signals that can distinguish between one object and another object , It usually occurs at a higher level of treatment . This paper puts forward the idea of hierarchical attention (Hierarchical Inter-Level Attention,HILA), An attention based approach , It can capture the bottom-up and top-down updates between different levels of features .HILA By adding local connections between higher and lower layer features in the backbone encoder , Extended hierarchical vision Transformers Structure . Each iteration updates the low-level features belonging to them by letting the high-level features compete for allocation , Iterative solution goal - Part of the relationship to build the hierarchy . These improved low-level features are used to update the high-level features .HILA Can be integrated into most hierarchies , There is no need to make any changes to the basic model . take HILA Add to SegFormer and Swin Transformer in , It shows that in semantic segmentation, with fewer parameters and FLOPS There is a significant improvement in accuracy .
Existing transformer-based image backbones typically propagate feature information in one direction from lower to higher-levels. This may not be ideal since the localization ability to delineate accurate object boundaries, is most prominent in the lower, high-resolution feature maps, while the semantics that can disambiguate image signals belonging to one object vs. another, typically emerges in a higher level of processing. We present Hierarchical Inter-Level Attention (HILA), an attention-based method that captures Bottom-Up and Top-Down Updates between features of different levels. HILA extends hierarchical vision transformer architectures by adding local connections between features of higher and lower levels to the backbone encoder. In each iteration, we construct a hierarchy by having higher-level features compete for assignments to update lower-level features belonging to them, iteratively resolving object-part relationships. These improved lower-level features are then used to re-update the higher-level features. HILA can be integrated into the majority of hierarchical architectures without requiring any changes to the base model. We add HILA into SegFormer and the Swin Transformer and show notable improvements in accuracy in semantic segmentation with fewer parameters and FLOPS. Project website and code: this https URL
https://arxiv.org/abs/2207.02126


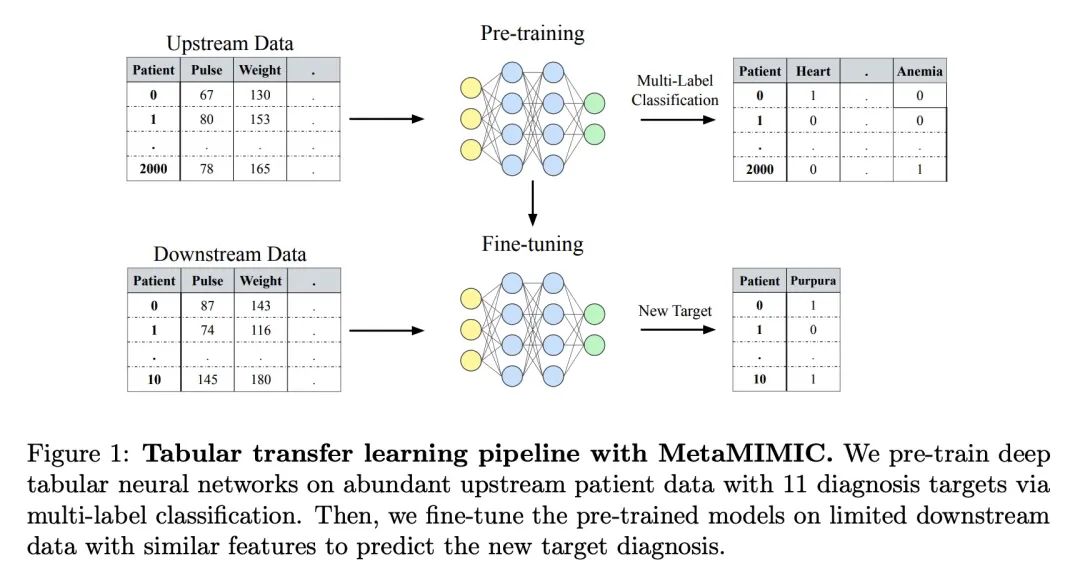
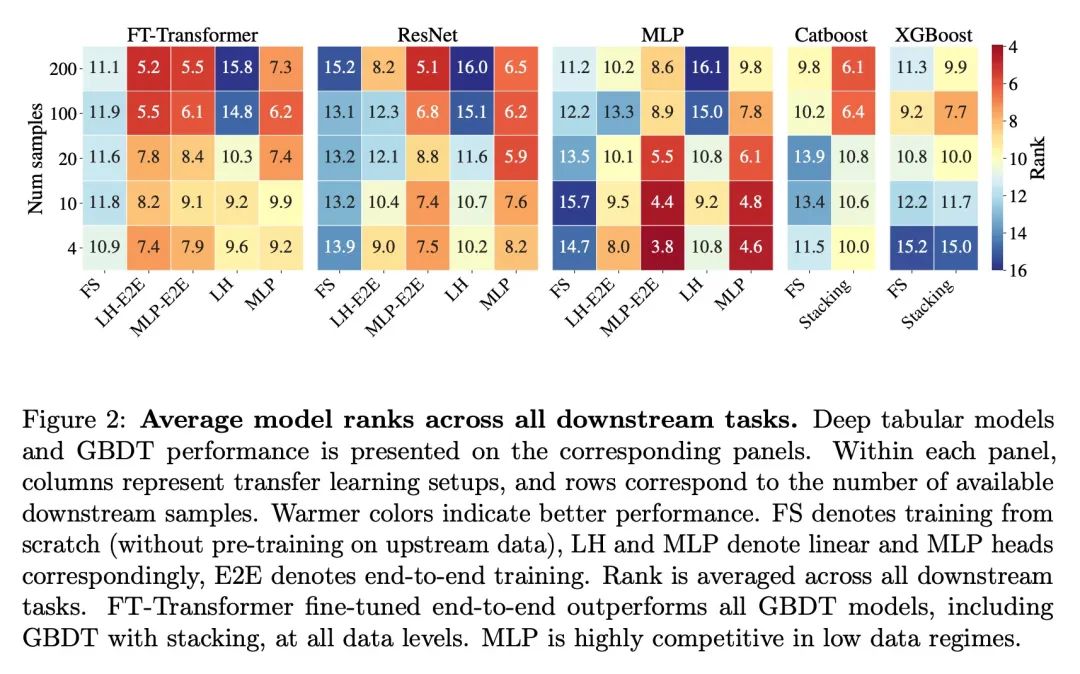
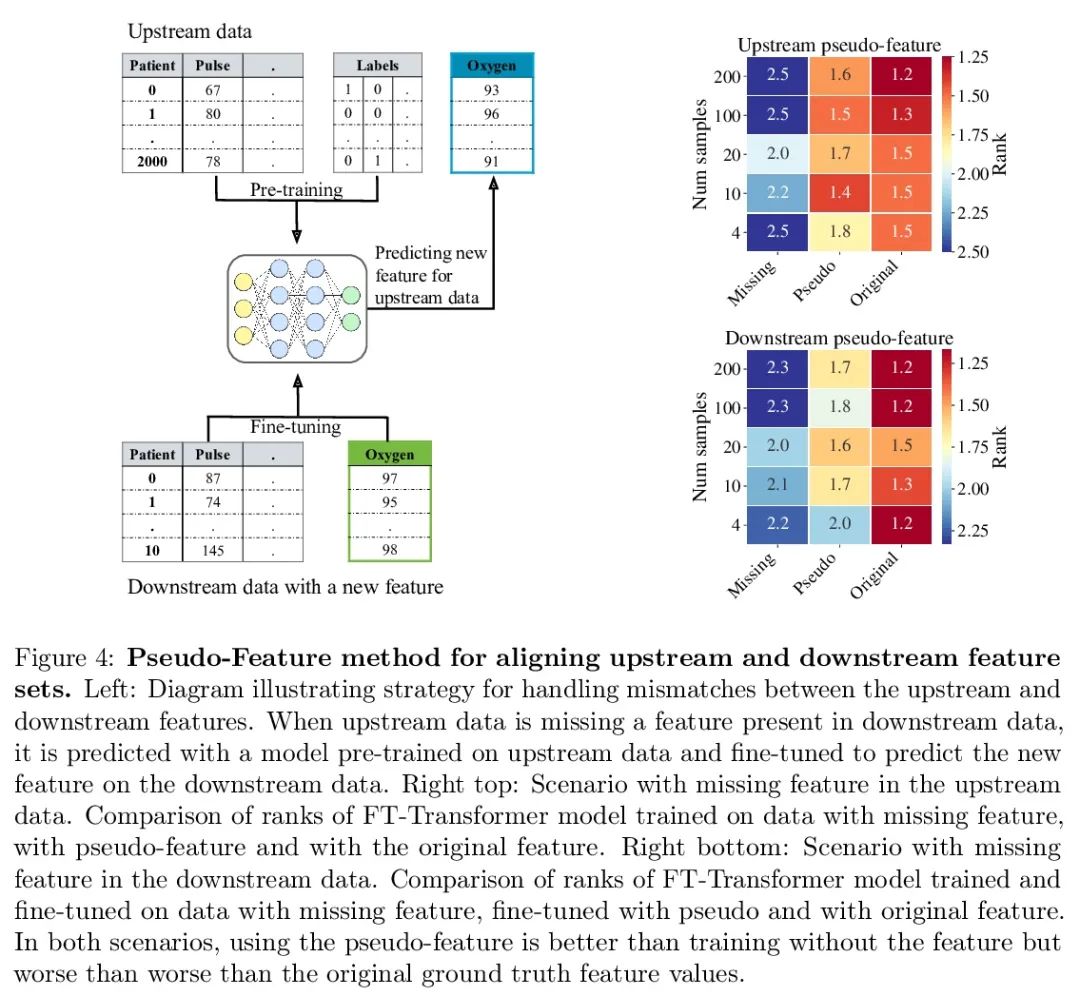
4、[LG] Transfer Learning with Deep Tabular Models
R Levin, V Cherepanova, A Schwarzschild, A Bansal, C. B Bruss, T Goldstein...
[University of Washington & University of Maryland & Capital One & New York University]
Transfer learning based on depth table model . Recent in-depth learning work on table data , It shows the powerful performance of the depth table model , Shrunk Gradient lift decision tree And Neural Networks . Except for accuracy , A major advantage of neural models , They can learn reusable features , And it is easy to fine tune in new fields . This feature is often used in computer vision and natural language applications , When training data for a specific task is scarce , Transfer learning is very necessary . This paper proves that the upstream data makes the tabular neural network more widely used than GBDT The model has a decisive advantage , A realistic medical diagnosis benchmark is proposed for table transfer learning , And put forward guidelines on how to use upstream data to improve the performance of various tabular neural network architectures . Last , A pseudo feature method is proposed for different upstream and downstream feature sets , This situation is a table format specific problem that widely exists in real world applications .
Recent work on deep learning for tabular data demonstrates the strong performance of deep tabular models, often bridging the gap between gradient boosted decision trees and neural networks. Accuracy aside, a major advantage of neural models is that they learn reusable features and are easily fine-tuned in new domains. This property is often exploited in computer vision and natural language applications, where transfer learning is indispensable when task-specific training data is scarce. In this work, we demonstrate that upstream data gives tabular neural networks a decisive advantage over widely used GBDT models. We propose a realistic medical diagnosis benchmark for tabular transfer learning, and we present a how-to guide for using upstream data to boost performance with a variety of tabular neural network architectures. Finally, we propose a pseudo-feature method for cases where the upstream and downstream feature sets differ, a tabular-specific problem widespread in real-world applications. Our code is available at github.com/LevinRoman/tabular-transfer-learning.
https://arxiv.org/abs/2206.15306


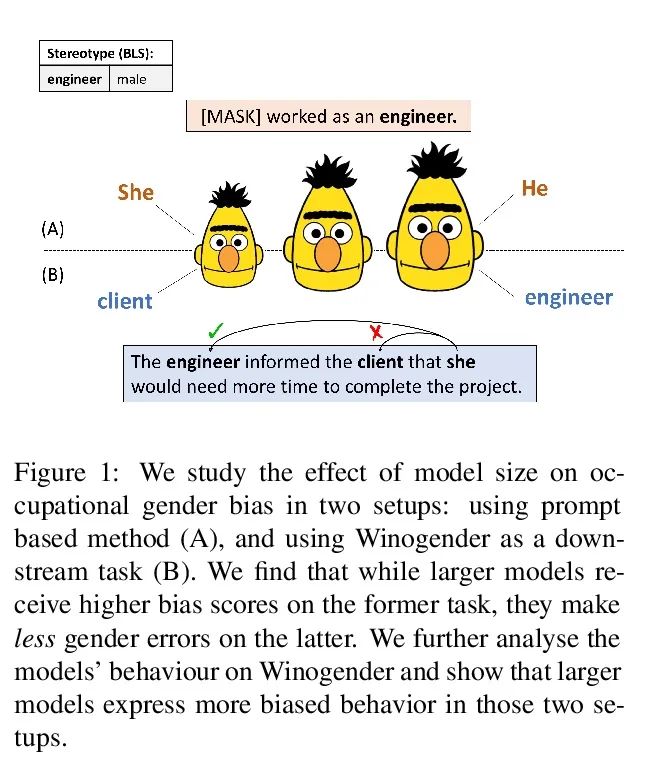
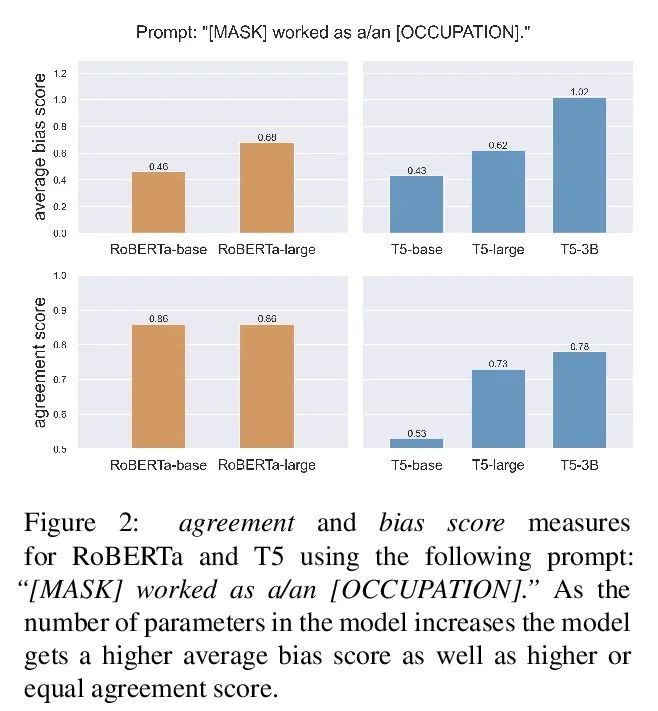
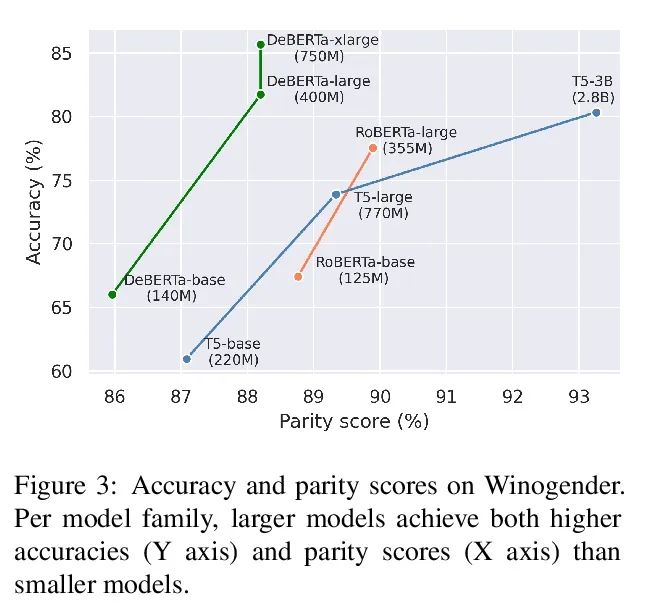
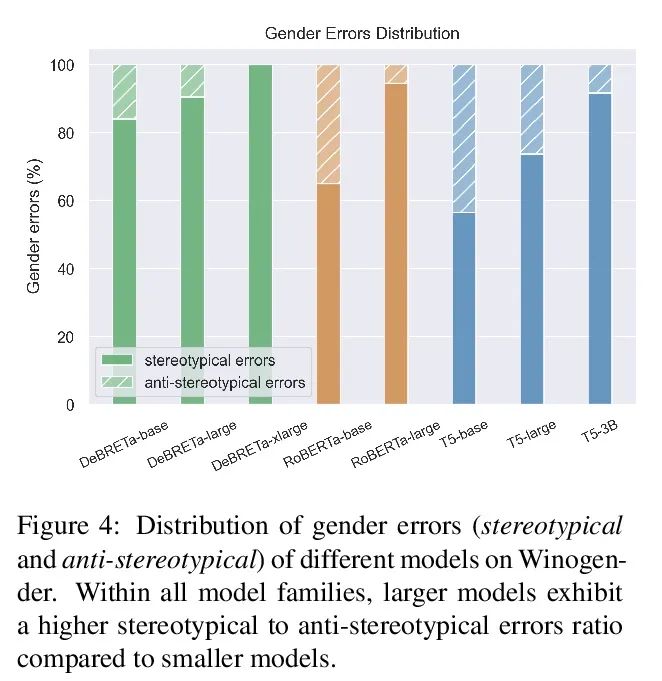
5、[CL] Fewer Errors, but More Stereotypes? The Effect of Model Size on Gender Bias
Y Tal, I Magar, R Schwartz
[The Hebrew University of Jerusalem]
The fewer mistakes , More rigid ? The influence of model size on gender bias . The scale of the pre training model is expanding , It's in a variety of ways NLP The performance on the task is also getting better . However , With the growth of memory ability , And the training model may accept more social prejudice . This paper studies the model size and its gender bias ( Especially professional gender prejudice ) The connection between . Three mask language model families are measured in two settings (RoBERTa、DeBERTa and T5) The deviation of : Use the prompt based method directly , And adopt downstream tasks (Winogender). Results found , One side , The larger model showed a higher deviation score in the previous task , But when evaluated in the latter , There are fewer gender errors . In order to study these possible conflicting results , This paper carefully investigates different models in Winogender The act of . It is found that although the performance of the large model is better than that of the small model , But its error is caused by gender bias with a higher probability . Besides , Compared with anti gender bias errors , The proportion of stereotypes increases with the size of the model . The findings of this paper emphasize the potential risks that may be brought about by the increase of the scale of the model .
The size of pretrained models is increasing, and so is their performance on a variety of NLP tasks. However, as their memorization capacity grows, they might pick up more social biases. In this work, we examine the connection between model size and its gender bias (specifically, occupational gender bias). We measure bias in three masked language model families (RoBERTa, DeBERTa, and T5) in two setups: directly using prompt based method, and using a downstream task (Winogender). We find on the one hand that larger models receive higher bias scores on the former task, but when evaluated on the latter, they make fewer gender errors. To examine these potentially conflicting results, we carefully investigate the behavior of the different models on Winogender. We find that while larger models outperform smaller ones, the probability that their mistakes are caused by gender bias is higher. Moreover, we find that the proportion of stereotypical errors compared to antistereotypical ones grows with the model size. Our findings highlight the potential risks that can arise from increasing model size.
https://arxiv.org/abs/2206.09860

Several other papers worthy of attention :
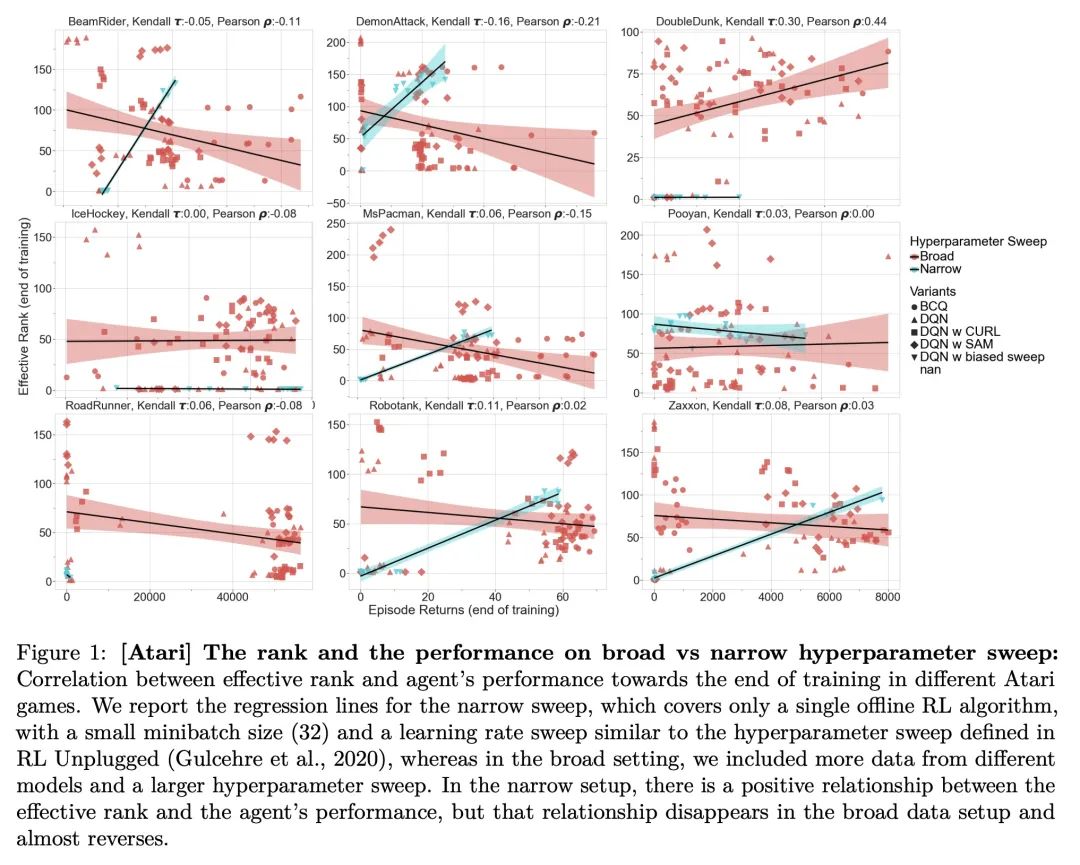
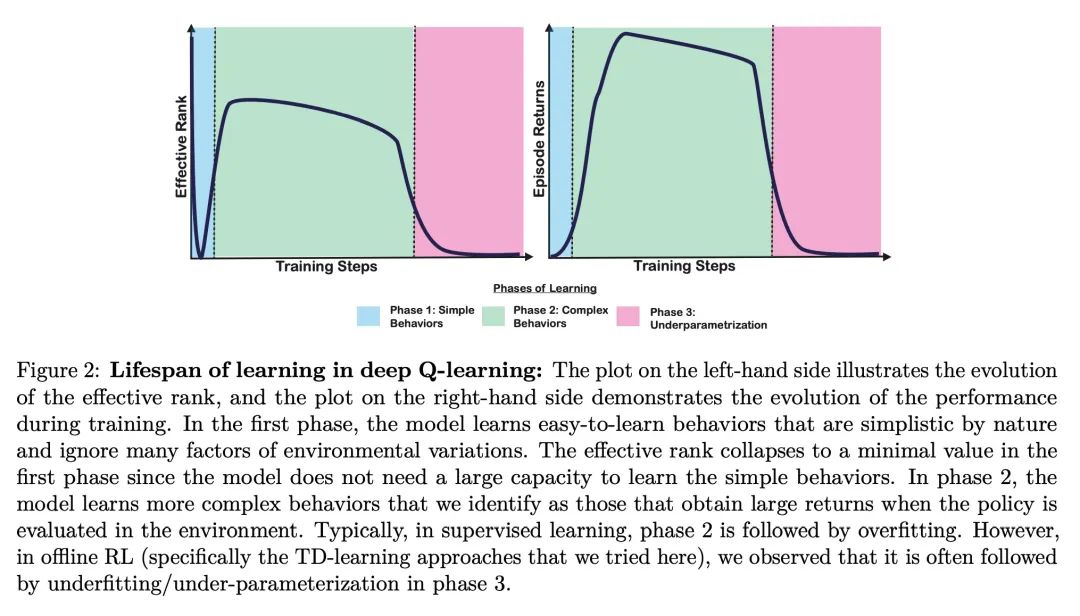
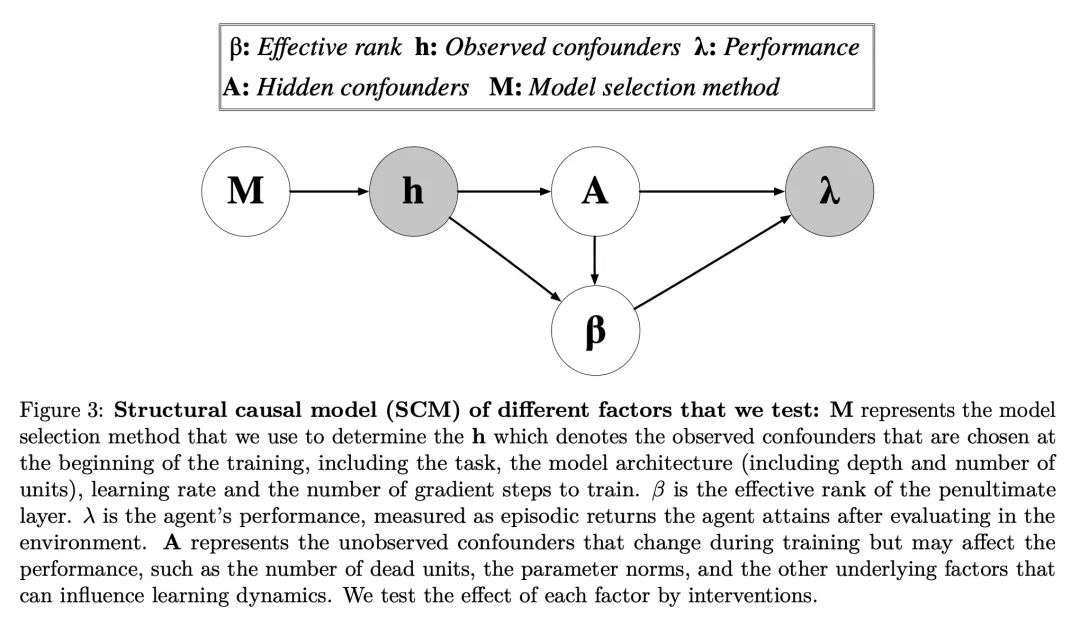
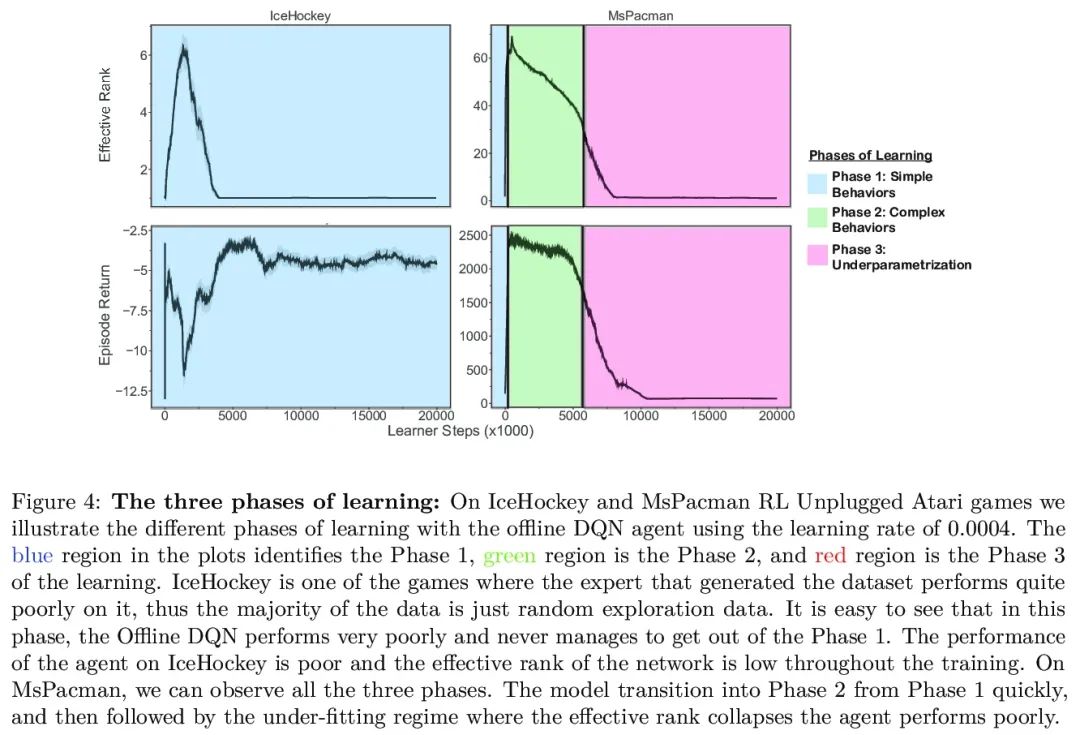
[LG] An Empirical Study of Implicit Regularization in Deep Offline RL
Empirical research on implicit regularization of deep off-line reinforcement learning
C Gulcehre, S Srinivasan, J Sygnowski, G Ostrovski, M Farajtabar, M Hoffman, R Pascanu, A Doucet
[DeepMind]
https://arxiv.org/abs/2207.02099

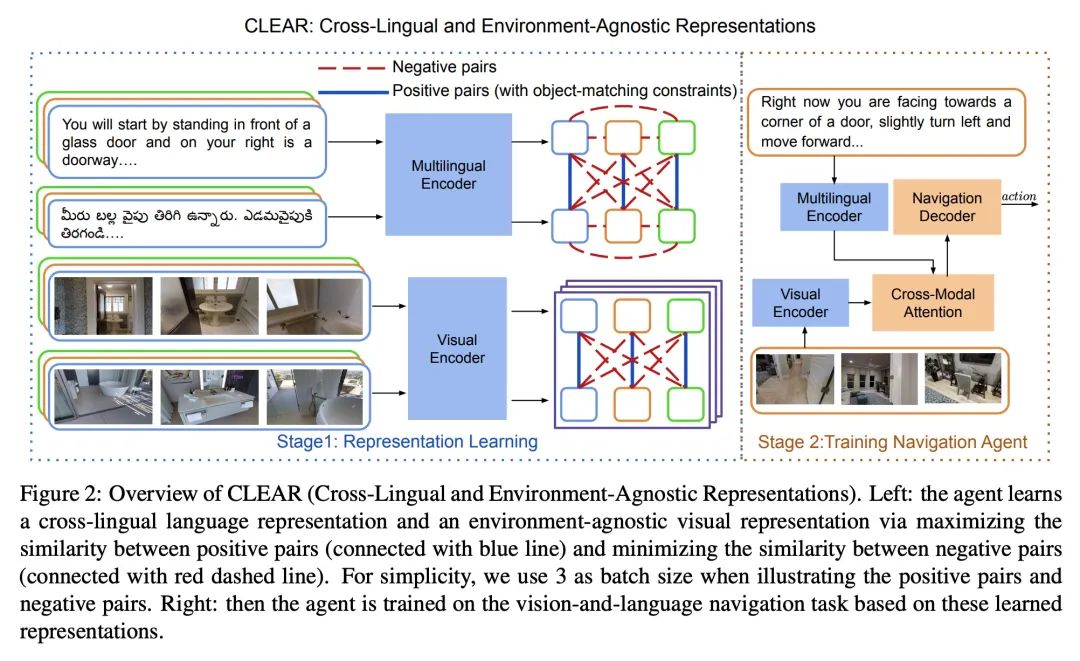
[CV] CLEAR: Improving Vision-Language Navigation with Cross-Lingual, Environment-Agnostic Representations
CLEAR: Improve visual language navigation based on cross language environment independent representation
J Li, H Tan, M Bansal
[UNC Chapel Hill]
https://arxiv.org/abs/2207.02185




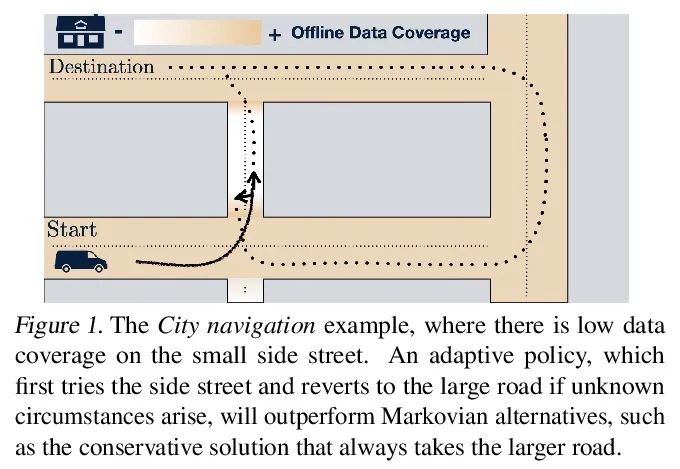
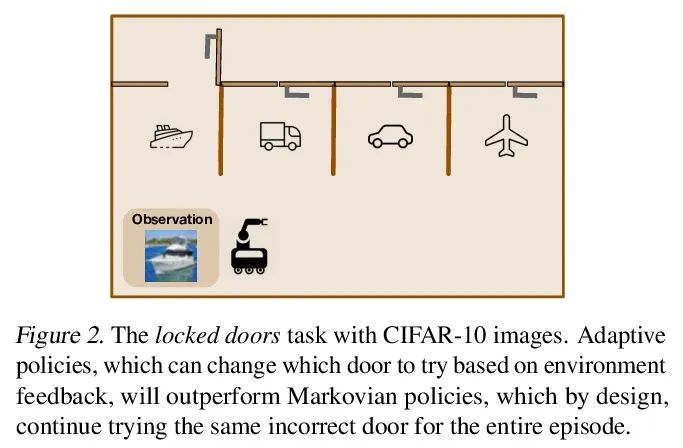
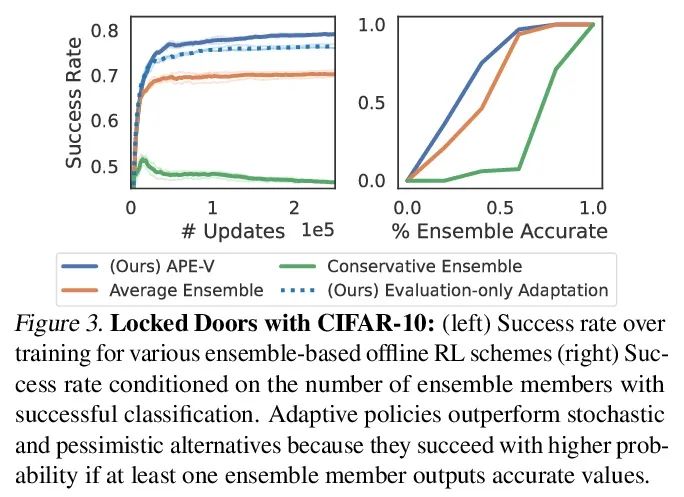
[LG] Offline RL Policies Should be Trained to be Adaptive
Offline reinforcement learning strategies should be trained to enhance adaptability
D Ghosh, A Ajay, P Agrawal, S Levine
[UC Berkeley & MIT]
https://arxiv.org/abs/2207.02200


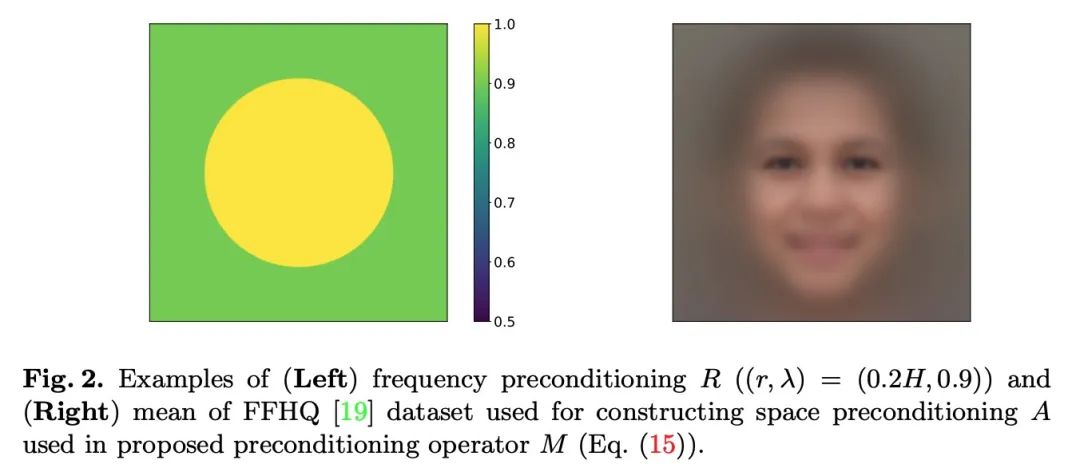
[CV] Accelerating Score-based Generative Models with Preconditioned Diffusion Sampling
Based on the preconditioned diffusion sampling, the acceleration is based on the fractional generation model
H Ma, L Zhang, X Zhu, J Feng
[Fudan University & University of Surrey]
https://arxiv.org/abs/2207.02196




边栏推荐
- H3C HCl MPLS layer 2 dedicated line experiment
- 什么是ESP/MSR 分区,如何建立ESP/MSR 分区
- Static comprehensive experiment
- [deep learning] image multi label classification task, Baidu paddleclas
- 【PyTorch实战】用PyTorch实现基于神经网络的图像风格迁移
- 2022 8th "certification Cup" China University risk management and control ability challenge
- idm服务器响应显示您没有权限下载解决教程
- Attack and defense world ----- summary of web knowledge points
- PowerShell cs-utf-16le code goes online
- Tutorial on the principle and application of database system (011) -- relational database
猜你喜欢
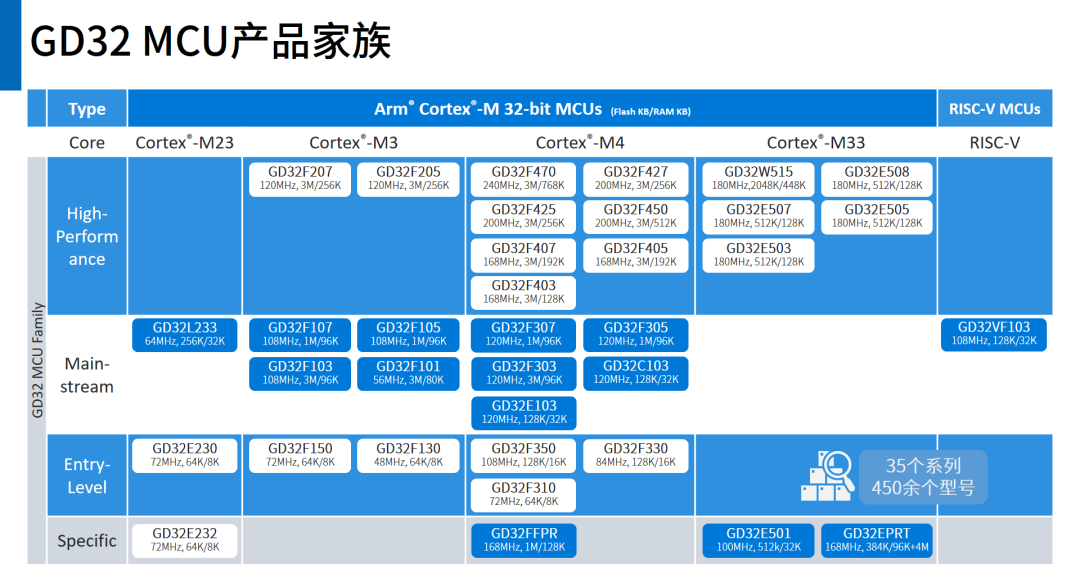
解密GD32 MCU产品家族,开发板该怎么选?
EPP+DIS学习之路(1)——Hello world!
Attack and defense world ----- summary of web knowledge points
Epp+dis learning path (1) -- Hello world!

Sort out the garbage collection of JVM, and don't involve high-quality things such as performance tuning for the time being
leetcode刷题:二叉树26(二叉搜索树中的插入操作)
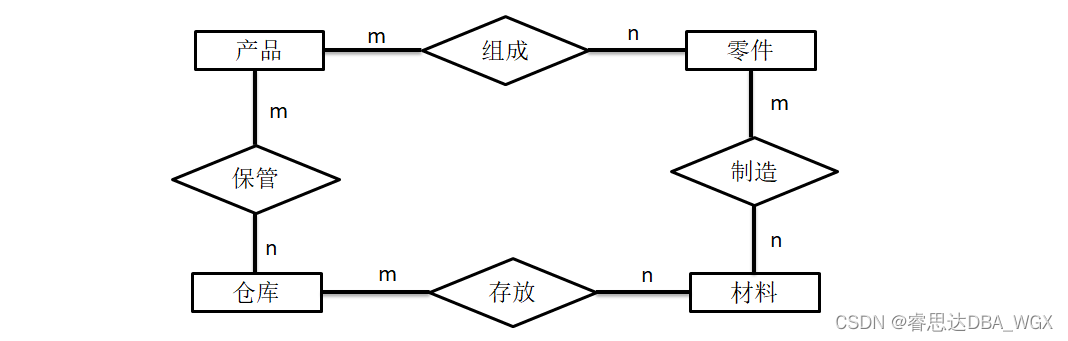
数据库系统原理与应用教程(010)—— 概念模型与数据模型练习题
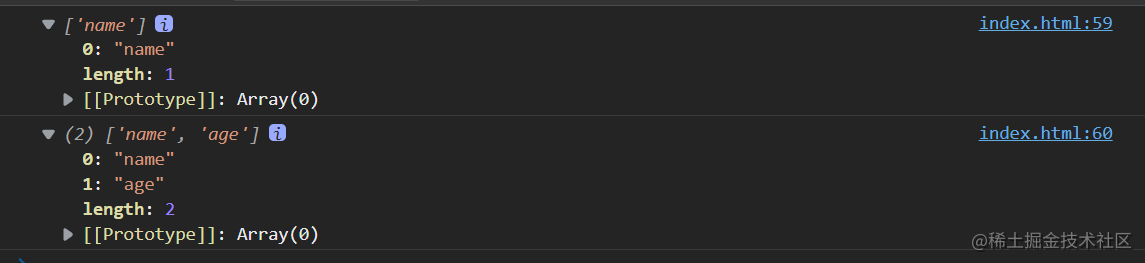
盘点JS判断空对象的几大方法

Completion report of communication software development and Application
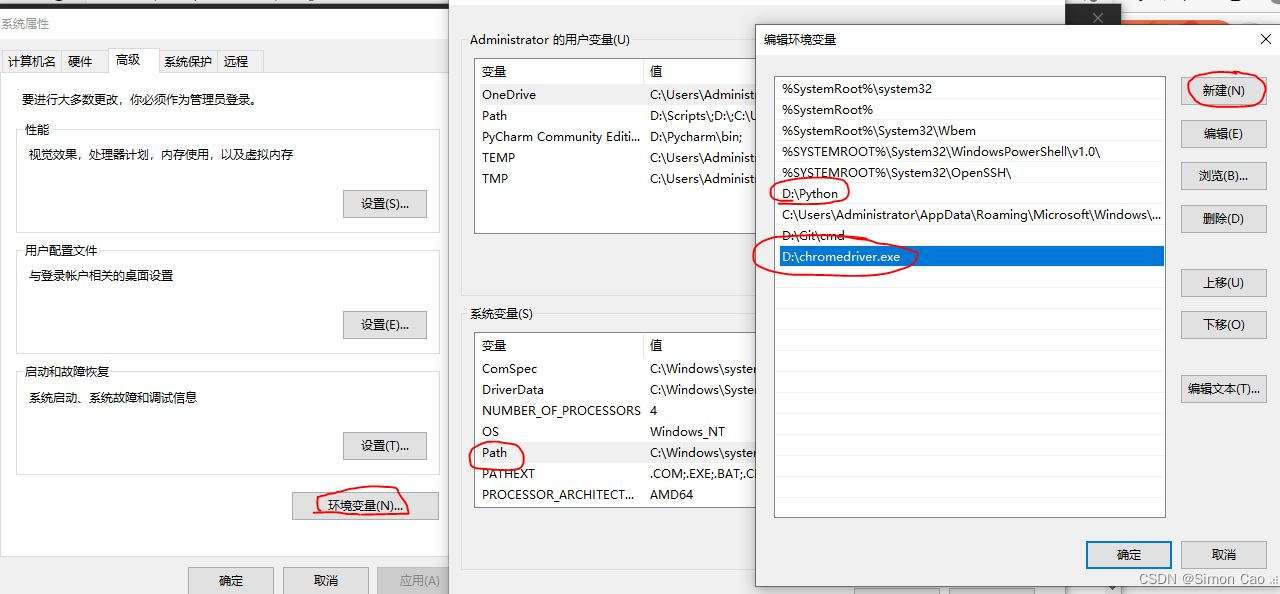
Financial data acquisition (III) when a crawler encounters a web page that needs to scroll with the mouse wheel to refresh the data (nanny level tutorial)
随机推荐
SQL lab 1~10 summary (subsequent continuous update)
消息队列消息丢失和消息重复发送的处理策略
免备案服务器会影响网站排名和权重吗?
[Q&A]AttributeError: module ‘signal‘ has no attribute ‘SIGALRM‘
Experiment with a web server that configures its own content
Simple network configuration for equipment management
VSCode的学习使用
How to understand the clothing industry chain and supply chain
H3C HCl MPLS layer 2 dedicated line experiment
About sqli lab less-15 using or instead of and parsing
【统计学习方法】学习笔记——第五章:决策树
爱可可AI前沿推介(7.7)
Attack and defense world ----- summary of web knowledge points
What are the technical differences in source code anti disclosure
2022-07-07日报:GAN发明者Ian Goodfellow正式加入DeepMind
SQL Lab (41~45) (continuous update later)
Zhimei creative website exercise
The left-hand side of an assignment expression may not be an optional property access.ts(2779)
Preorder, inorder and postorder traversal of binary tree
What is an esp/msr partition and how to create an esp/msr partition