当前位置:网站首页>The principle of attention mechanism and its application in seq2seq (bahadanau attention)
The principle of attention mechanism and its application in seq2seq (bahadanau attention)
2022-07-05 04:32:00 【SaltyFish_ Go】
Overview of attention mechanism
1、 Additive attention Additive Attention
2、 Zoom in and out and focus Scaled Dot-Product Attention
stay seq2seq Application in Attention(Bahdanau attention )
stay seq2seq Use in attention The motive of :
added attention The difference after
Specific implementation process :
Bahdanau Code implementation of attention
Overview of attention mechanism
Psychological definition : Pay attention to noteworthy points in complex situations
“ Whether to include autonomy tips ” Distinguish the attention mechanism from the full connection layer or aggregation layer :
Convolution 、 Full connection 、pooling They only consider non will clues ;
The attention mechanism considers will clues : Will clue ( Autonomy tips ) be called Inquire about (query). Given any query , Attention mechanism through Focus (attention pooling) Guide selection to Sensory input (sensory inputs, For example, intermediate features represent ). In the attention mechanism , These sensory inputs are called value (value). A more popular explanation , Each value is associated with a key (key) pairing , This can be imagined as an involuntary cue for sensory input . Such as chart 10.1.3 Shown , We can design focus , So that the given query ( Autonomy tips ) Can be used with the key ( Involuntary cues ) Match , This will lead to the best matching value ( Sensory input ).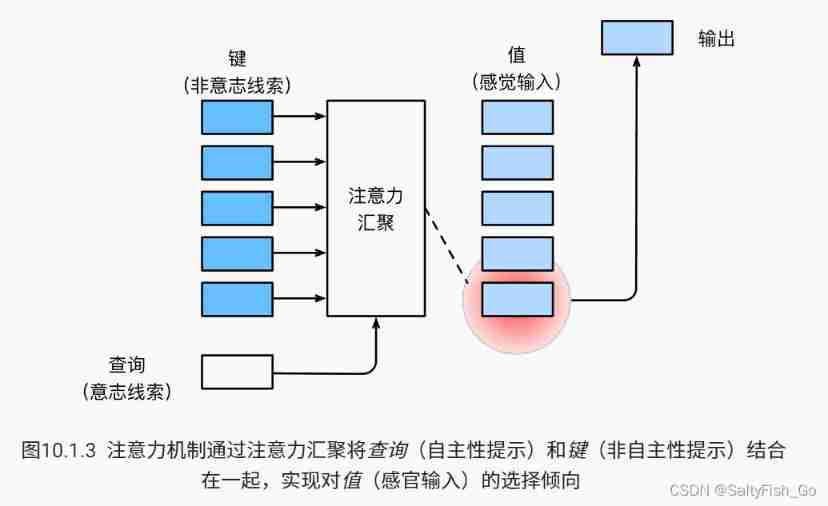
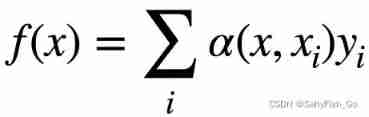
![]() It's attention weight
It's attention weight
Will clue query Namely f(x), In the formula x It's a non will clue key. Simply speaking ,query That's right key Did a weighted arithmetic , The weight is query Yes key Biased choice .
Attention rating
The attention score is query and key The similarity ( Take a chestnut , When I go to the company to apply for a job , Guess your salary , It should be similar to my major , The salary of people with similar work content and time , These people will have high attention scores ), No, Normalized Of alpha Is the attention score a.
Inquire about q Sum key ki The weight of attention ( Scalar ) Through the attention scoring function a Map two vectors into scalars , after softmax Calculated .. Choose different attention scoring functions a It will lead to different attention focusing operations .
1、 Additive attention Additive Attention
Given a query q∈Rq and key k∈Rk, Additive attention (additive attention) The scoring function is
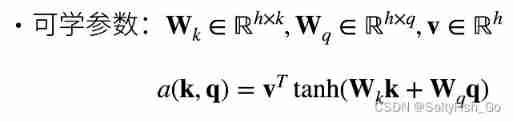
take query and key Connect them and input them into a multi-layer perceptron (MLP) in , The sensor contains a hidden layer , The number of hidden cells is a super parameter h. By using tanh As an activation function , And disable the offset item .query and key It can be any length , By matrix multiplication , final a It's a value , because (1*h)*(h*1).
#@save
class AdditiveAttention(nn.Module):
""" Additive attention """
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# After dimension expansion ,
# queries The shape of the :(batch_size, Number of queries ,1,num_hidden)
# key The shape of the :(batch_size,1,“ key - value ” The number of right ,num_hiddens)
# Use broadcast for summation
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# self.w_v There is only one output , So remove the last dimension from the shape .
# scores The shape of the :(batch_size, Number of queries ,“ key - value ” The number of right )
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# values The shape of the :(batch_size,“ key - value ” The number of right , Dimension of value )
return torch.bmm(self.dropout(self.attention_weights), values)2、 Zoom in and out and focus Scaled Dot-Product Attention
When n individual query and m individual Key It's all the length of d when

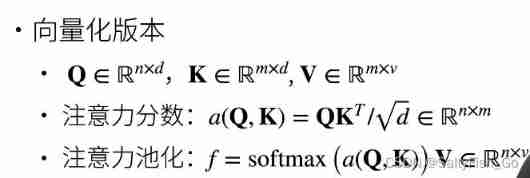
#@save
class DotProductAttention(nn.Module):
""" Zoom in and out and focus """
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries The shape of the :(batch_size, Number of queries ,d)
# keys The shape of the :(batch_size,“ key - value ” The number of right ,d)
# values The shape of the :(batch_size,“ key - value ” The number of right , Dimension of value )
# valid_lens The shape of the :(batch_size,) perhaps (batch_size, Number of queries )
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# Set up transpose_b=True In exchange for keys The last two dimensions of
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)stay seq2seq Application in Attention(Bahdanau attention )
Notice what is in this model value\key\query
key—— Each word in the encoder corresponds to RNN Output .
query—— The predictive output of the decoder for the previous word ( Used to match related key).
value—— Semantics of context ?
stay seq2seq Use in attention The motive of :
In machine translation , Each generated word may be related to a different word in the source sentence . however seq2seq This cannot be modeled directly :decoder The input of is the last H, Although it contains the previous information , But we have to Restore the location information .
added attention The difference after
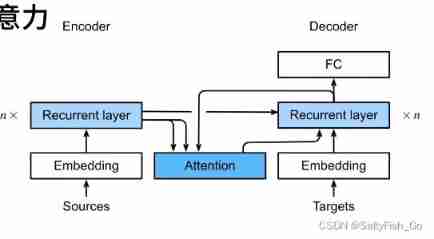
The original input forever All are encoder Of RNN The last hidden state is the context context and embedding Passed into the decoder together RNN.
Add... To the original basis attention( Using the state of the last moment as input is not good , We should look at the hidden state of the previous moments according to the translated words ). It is equivalent to making a weighted average of the previous hidden states , Take the most relevant state.
Specific implementation process :
compiler encoder Take the output of each word as Key and value( The two are the same ) In the attention Inside , Then when decoder Predict hello When , Take the output prediction as query Put in attention seek hello Words around ( matching match Of Key).
“ Create index with compiler , Use the prediction of the decoder to locate the focus ”
The last input is attention Output and embedding
Bahdanau Code implementation of attention
added attention_weight function
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs The shape of is (batch_size,num_steps,num_hiddens).
# hidden_state The shape of is (num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs The shape of is (batch_size,num_steps,num_hiddens).
# hidden_state The shape of is (num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# Output X The shape of is (num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# query The shape of is (batch_size,1,num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# context The shape of is (batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# Connect... In the feature dimension
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# take x Deformed to (1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# After full connection layer transformation ,outputs The shape of is
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights边栏推荐
- File upload bypass summary (upload labs 21 customs clearance tutorial attached)
- 【科普】热设计基础知识:5G光器件之散热分析
- 如何进行「小步重构」?
- This is an age of uncertainty
- Neural networks and deep learning Chapter 5: convolutional neural networks reading questions
- Moco is not suitable for target detection? MsrA proposes object level comparative learning target detection pre training method SOCO! Performance SOTA! (NeurIPS 2021)...
- 介绍汉明距离及计算示例
- How to force activerecord to reload a class- How do I force ActiveRecord to reload a class?
- 【虚幻引擎UE】打包报错出现!FindPin错误的解决办法
- Neural networks and deep learning Chapter 3: linear model reading questions
猜你喜欢
Sword finger offer 04 Search in two-dimensional array
Serpentine matrix
Invalid bound statement (not found) in idea -- problem solving

Learning notes 8
A survey of automatic speech recognition (ASR) research
函數(易錯)
![[illusory engine UE] method to realize close-range rotation of operating objects under fuzzy background and pit recording](/img/11/b55f85ef9e1f22254218cb9083b823.png)
[illusory engine UE] method to realize close-range rotation of operating objects under fuzzy background and pit recording
Burpsuite grabs app packets
Realize the attention function of the article in the applet

2022-2028 global and Chinese video coding and transcoding Market Research Report
随机推荐
[untitled]
Learning notes 8
【虛幻引擎UE】實現UE5像素流部署僅需六步操作少走彎路!(4.26和4.27原理類似)
level18
Rome chain analysis
学习MVVM笔记(一)
C26451: arithmetic overflow: use the operator * on a 4-byte value, and then convert the result to an 8-byte value. To avoid overflow, cast the value to wide type before calling the operator * (io.2)
The scale of computing power in China ranks second in the world: computing is leaping forward in Intelligent Computing
How can CIOs use business analysis to build business value?
首席信息官如何利用业务分析构建业务价值?
Managed service network: application architecture evolution in the cloud native Era
自动语音识别(ASR)研究综述
揭秘技术 Leader 必备的七大清奇脑回路
WeNet:面向工业落地的E2E语音识别工具
Live broadcast preview | container service ack elasticity prediction best practice
Neural networks and deep learning Chapter 5: convolutional neural networks reading questions
[untitled]
指针函数(基础)
Threejs Internet of things, 3D visualization of farms (II)
Reading and visualization of DICOM, MHD and raw files in medical imaging