当前位置:网站首页>JDBC事务、批处理以及连接池(超详细)
JDBC事务、批处理以及连接池(超详细)
2022-07-06 09:23:00 【想要进大厂】
前言
昨天总结了JDBC编码具体步骤,今天我们来说一下JDBC事务、批处理以及JDBC连接池的相关概念及用法,(注:笔者所有代码语句针对MySQL数据库实现)
一、JDBC事务
引出:我们先来看一个问题,假设我们的数据库中有一张余额表,里面有两条记录,如下表:
+----+-----------+---------+
| id | name | balance |
+----+-----------+---------+
| 1 | 马云 | 2800 |
| 2 | 马化腾 | 10100 |
+----+-----------+---------+
现在有如下需求:我们需要将马云的100块转给马化腾,理想结果是马云的balance=2700,而马化腾的balance=10200;我们在idea代码中模拟一下:
@Test
public void noTransaction(){
//1.得到连接
Connection connection = null;
//2.组织sql语句
String sql = "Update account2 set balance = balance-100 where id=1";
String sql2 = "Update account2 set balance = balance+100 where id=2";
PreparedStatement preparedStatement =null;
//3.创建PreparedStatement对象
try {
connection = JDBCUtils.getConnection();//默认情况下,connection是默认自动提交
preparedStatement = connection.prepareStatement(sql);
preparedStatement.executeUpdate();//第一条
int i =1/0;
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();//第二条
} catch (SQLException e) {
throw new RuntimeException(e);
}finally {
//关闭资源
JDBCUtils.close(null,preparedStatement,connection);
}
}注:JDBCUtils工具类是完成对连接数据库,和关闭资源的一系列操作,这里不作详细讲述
如果try-catch代码块中没有 int i =1/0;这条语句,很显然两条语句是可以执行成功,测试结果如下表:

但是如果执行过程中有int i =1/0,就会抛出一个java.lang.ArithmeticException: / by zero 异常,try-catch语句中,只要有代码抛出异常,下面的代码将不会执行,所以出现了一个问题:就是马云的一百块确实转出去了,但是马化腾没有收到100块,这100块凭空消失了,这在我们实际开发中是一个很严重的错误,比如在银行转账取款等问题,可能有小伙伴会说,那为什么要写这个异常呢,你不写它,马化腾不就收到了吗?这里笔者只想从这个问题抛出事务的作用,下面笔者用事务来解决这个问题。
JDBC事务基本介绍
1.JDBC程序中当一个Connection对象创建时,默认情况下时自动提交事务:每次执行一个sql语句时,如果执行成功,就会向数据库自动提交,而不能回滚
2.JDBC程序中为了让多个SQL语句作为一个整体执行,需要使用事务
3.调用Connection当setAutoCommit(false) 可以取消自动提交事务
4.在所有的SQL语句都成功执行后,调用Commit():方法提交事务
5.在其中某个操作失败或出现异常时,调用rollback():方法回滚事务
相信大家看到这里对事务还是有点模模糊糊的,下面笔者用代码解决上面转账的问题。直接上代码!
@Test
public void useTransaction(){
//1.得到连接
Connection connection = null;
//2.组织sql语句
String sql = "Update account2 set balance = balance-100 where id=1";
String sql2 = "Update account2 set balance = balance+100 where id=2";
PreparedStatement preparedStatement =null;
//3.创建PreparedStatement对象
try {
connection = JDBCUtils.getConnection();//默认情况下,connection是默认自动提交
//将connection设置为不再自动提交
connection.setAutoCommit(false); //开启了事务
preparedStatement = connection.prepareStatement(sql);
preparedStatement.executeUpdate();//第一条
int i =1/0;//抛出异常,后面的代码不再执行
preparedStatement = connection.prepareStatement(sql2);
preparedStatement.executeUpdate();//第二条
//这里提交事务
connection.commit();
} catch (SQLException e) {
//抛出异常后,我们可以进行事务回滚,撤销执行的SQL
//默认回滚到事务开始的状态
System.out.println("执行发生了异常,回滚撤销事务");
try {
connection.rollback();
} catch (SQLException ex) {
throw new RuntimeException(ex);
}
throw new RuntimeException(e);
}finally {
//关闭资源
JDBCUtils.close(null,preparedStatement,connection);
}
}我们先将connection设置为不自动提交,这样发生异常后可以利用事务回滚,有效的避免了转账问题,我们来看一下结果:
结果显然:马云的一百块没有转出去,而马化腾也没有收到一百块,在控制台上,我们直接将异常信息打印出来了。相信看到这里,小伙伴应该对事务有了一个新的认识
二、JDBC批处理
引出:我们还是再来看一个问题:
假如我们需要在一个表中加入几千条数据,结果会是怎样的呢?
批处理基本介绍:
1.当需要成批插入或者更新记录时,可以采用java的批量更新机制,这一机制运行多条语句一次性提交给数据库批量处理,通常情况下比单独提交处理更有效率
2.JDBC的批量处理语句包括下面方法:
addBatch():添加需要批量处理的SQL语句或参数
executeBatch():执行批量处理语句;
clearBatch():清空批处理包的语句
3.JDBC连接MySQL时,如果要使用批处理功能,请再url中加参数?rewriteBatchedStatement=true
4.批处理往往和PreparedStatement一起搭配使用,可以既减少编译次数,又减少运行次数,效率大大提高;
首先,我们利用传统方法解决这个问题:
@Test
public void noBatch()throws Exception{
//使用JDBCUtils工具类创建连接对象
Connection connection = JDBCUtils.getConnection();
//组织SQL语句
String sql ="insert into admin2 values(null,?,?)";
//执行SQL语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
System.out.println("开始执行了");
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
preparedStatement.setString(1,"jack"+i);
preparedStatement.setString(2,"666");
preparedStatement.executeUpdate();
}
long end = System.currentTimeMillis();
System.out.println("传统的方法 耗时= "+ (end-start));
JDBCUtils.close(null,preparedStatement,connection);
}我们看一下传统方法的耗时:

很显然是非常耗费时间的,我们这里只是一个java程序,在实际开发中,我们会有很多的用户对数据库进行操作,很多个java文件对数据库进行添加,那么这个时间效率就会非常低了,显然不利于我们开发的。那么如何解决这个问题呢?我们利用批处理的方式来解决这个问题:
//使用批量方式添加数据
@Test
public void batch() throws Exception{
Connection connection = JDBCUtils.getConnection();
String sql ="insert into admin2 values(null,?,?)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
System.out.println("开始执行了");
long start = System.currentTimeMillis();
for (int i = 0; i < 5000; i++) {
preparedStatement.setString(1,"jack"+i);
preparedStatement.setString(2,"666");
//将要执行的SQL语句放入批处理包中
preparedStatement.addBatch();
//当有一千条记录时,再批量执行
if ((i+1) % 1000 ==0){
preparedStatement.executeBatch();
//清空一把
preparedStatement.clearBatch();
}
}
long end = System.currentTimeMillis();
System.out.println("批量方式 耗时= "+ (end-start));
JDBCUtils.close(null,preparedStatement,connection);
}我们再来看一下批处理方式耗时:

批处理方式耗时和传统方式耗时相差很多,在实际开发中,批处理的方式显然更为有效
那么,批处理是如何执行的呢,它为什么执行的那么快呢?很好,如果你有这样的想法,很大程度上说明有在思考问题哦️
我们来看下addBatch()方法的底层源码:
public void addBatch() throws SQLException {
synchronized(this.checkClosed().getConnectionMutex()){
if(this.batchedArgs == null){
this.batchedArgs = new ArrayList();
}
for(int i =0;i<this.parameterValues.length;++i){
this.checkAllParametersSet(this.parameterValues[i],this.parameterStreams[i],i);
}
this.batchedArgs.add(new PreparedStatement.BatchParams(this.parameterValues,this.parameterValues);
}
}笔者自己debug后,仍然觉得自己的理解不够深入,又在网上查了下对这个方法的讲诉,给大家总结一下:
1.第一步就创建ArrayList - elementData => object[] 2.elementData => Object[] 就会存放我们预处理的SQL语句 3.当elementData满后,就按照1.5倍扩容 4.当添加到指定到值后,就会executeBatch 5.批量处理会减少我们发生sql语句到网络开销,而且减少编译次数,因此效率高
三、JDBC连接池
JDBC连接池的必要性
在我们基于数据库进行开发时,传统模式基本按下面步骤:
1.注册驱动
2.获取连接
3.执行增删改查
4.释放资源
普通模式的弊端:
1.传统的JDBC数据库连接使用DriverManager来获取,每次向数据库建立连接的时候都要将Connection加载到内存中,再验证ip地址,用户名和密码(0.05s~1s),需要数据库连接到时候,就向数据库要求一个,频繁到进行数据库连接操作将会占用很多的系统资源,容易造成服务器崩溃
2.每一次数据库连接,使用完都得断开,如果程序出现异常而未能关闭,将导致数据库内存泄漏,最终将会导致重启数据库
3.传统获取连接的方式,不能控制创建的连接数据,如果连接过多,也可能导致内存泄漏,MySQL崩溃
数据库连接池技术
基本介绍:
1.预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去
2.数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个
3.当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将会被加入到等待队列中
数据库连接池原理图:
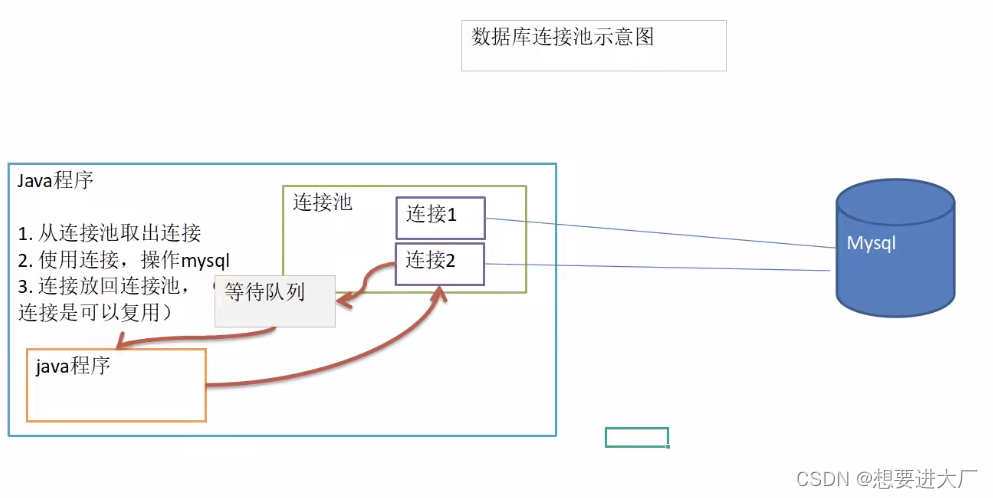
数据库连接池优点:
1.资源重用
因为数据库连接得以重用,避免了频繁的创建,释放造成大量性能开销,减少系统消耗的同时,也增加了系统运行环境的稳定性;
2.系统反应速度更快
数据库连接池的原理是在连接池中预先创建好若干个数据库连接,这时的初始化工作已经完成,对于各种请求数据库连接的操作直接由连接池进行分配,可以直接利用,避免了数据库连接初始化和释放过程中的时间开销,从而减少系统的响应时间;
3.新的资源分配手段
多个应用共享同一数据库的系统,可在应用层通过数据库连接池的配置,设置最大连接数,避免了某一个应用独占所有的数据库资源
4.统一管理,避免数据库连接泄漏
数据库连接池的种类
JDBC的数据库连接池使用javax.sql.DateSource来表示,DataSource只是一个接口,通常被称为数据源,它包含连接池和连接池管理两个部分,DataSource用来取代DriverManager来获取Connection,获取速度快,同时还可以大幅度提高数据库访问速度
1.C3P0数据库连接池,速度相对较慢,稳定性不错
2.DBCP数据库连接池,速度相对C3P0较快,但不稳定
3.Proxool数据库连接池,有监控连接池状态的功能,稳定性较C3P0差一点
4.BoneCP 数据库连接池,速度快
5.Druid(德鲁伊)是阿里提供的数据库连接池,集DBCP、C3P0、Proxool优点于一身的连接池(最常用,用得最多)
这里着重介绍C3P0数据库连接池和德鲁伊连接池;
C3P0数据库连接池:
获取连接的前置工作:需要将c3p0.jar包导入idea中,并添加到项目中;
<c3p0-config>
<named-config name="xyx_edu">
<!-- 驱动类 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<!-- url-->
<property name="jdbcUrl">jdbc:mysql://127.0.0.1:3306/xyx_db02</property>
<!-- 用户名 -->
<property name="user">root</property>
<!-- 密码 -->
<property name="password">???</property>
<!-- 每次增长的连接数-->
<property name="acquireIncrement">5</property>
<!-- 初始的连接数 -->
<property name="initialPoolSize">10</property>
<!-- 最小连接数 -->
<property name="minPoolSize">5</property>
<!-- 最大连接数 -->
<property name="maxPoolSize">50</property>
<!-- 可连接的最多的命令对象数 -->
<property name="maxStatements">5</property>
<!-- 每个连接对象可连接的最多的命令对象数 -->
<property name="maxStatementsPerConnection">2</property>
</named-config>
</c3p0-config>方式一:
//方式1:相关参数,在程序中指定user,url,password等
@SuppressWarnings({"all"})
@Test
public void testC3P0_01() throws Exception{
//1.创建一个数据源对象
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();
//2.通过配置文件mysql.properties获取相关连接信息
Properties properties = new Properties();
properties.load(new FileInputStream("src//mysql.Properties"));
//获取相关的信息
String user = properties.getProperty("user");
String url = properties.getProperty("url");
String password = properties.getProperty("password");
String driver = properties.getProperty("driver");
//3.给数据源 comboPooledDataSource 设置相关的参数
//连接的管理是由comboPooledDataSource来管理的
comboPooledDataSource.setDriverClass(driver);
comboPooledDataSource.setJdbcUrl(url);
comboPooledDataSource.setUser(user);
comboPooledDataSource.setPassword(password);
//4.设置初始化连接数
comboPooledDataSource.setInitialPoolSize(10);
comboPooledDataSource.setMaxPoolSize(50);//最大连接数
//5.获取连接(核心方法) 从DataSource接口实现的
Connection connection = comboPooledDataSource.getConnection();
connection.close();
}注意:connection.close()没有关闭数据库的物理连接,只是将数据库连接释放,归还给了数据库连接池中
方式二:
//第二种方式 使用配置文件模版来完成
//1.将c3p0-config-xml文件 拷贝到src目录下
//2.该文件指定来连接数据库和连接池到相关参数
@Test
public void testC3P0_02() throws Exception{
//创建指定参数到数据库连接池(数据源)
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource("xyx_edu");
//关闭连接
connection.close();
}这两种方式都可取,但是更推荐第二种,减少了代码的冗余,减少编码量。
德鲁伊连接池(Druid)
获取连接前置工作:
1.将druid.jar包导入到idea中,并添加到项目
2.将druid配置文件拷贝到src目录下
3.修改src目录下druid配置文件中的数据库表名称,密码,以及最小连接数和最大连接数
#key=value
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/xyx_db02?rewriteBatchedStatements=true
username=root
password=???
#initial connection Size
initialSize=10
#min idle connecton size
minIdle=5
#max active connection size
maxActive=50
#max wait time (5000 mil seconds)
maxWait=5000获取连接
@Test
public void testDruid() throws Exception{
//1.加入 Druid jar包
//2. 加入 配置文件 druid.properties ,将该文件拷贝到项目到src目录
//3.创建Properties对象,读取配置文件
Properties properties = new Properties();
properties.load(new FileInputStream("src//druid.properties"));
//4.创建一个指定参数到数据库连接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
Connection connection = dataSource.getConnection();
connection.close();
}边栏推荐
猜你喜欢
Intensive literature reading series (I): Courier routing and assignment for food delivery service using reinforcement learning
Hackmyvm target series (3) -visions

强化學習基礎記錄

Hackmyvm target series (5) -warez
List and data frame of R language experiment III
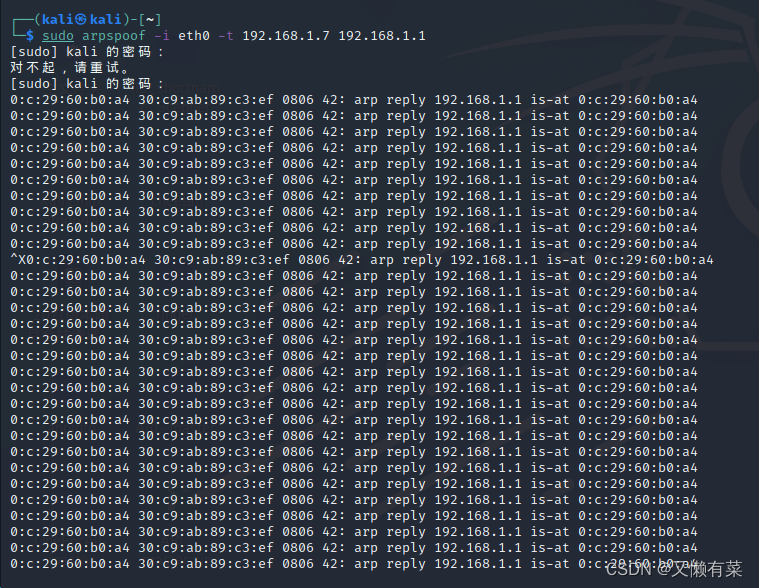
Network layer - simple ARP disconnection
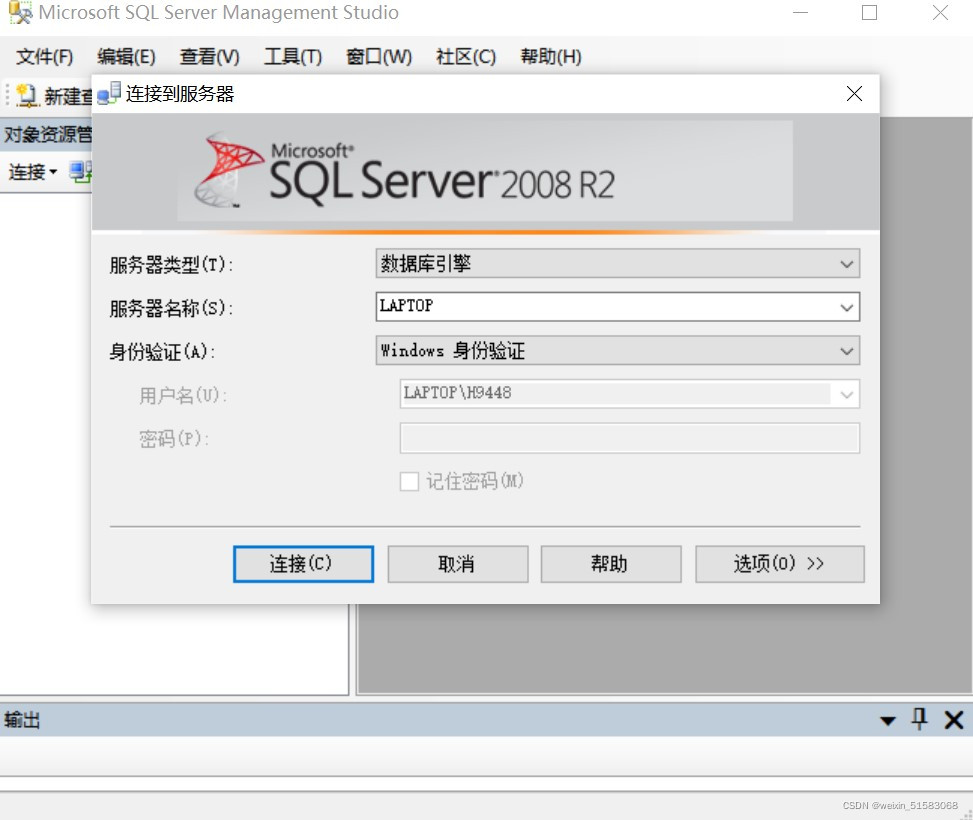
附加简化版示例数据库到SqlServer数据库实例中
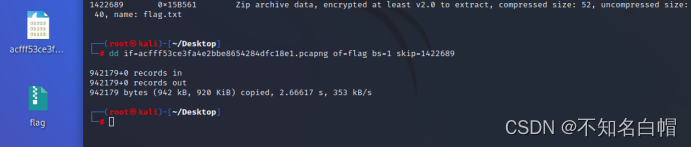
Attack and defense world misc practice area (simplerar, base64stego, no matter how high your Kung Fu is, you are afraid of kitchen knives)

7-7 7003 combination lock (PTA program design)
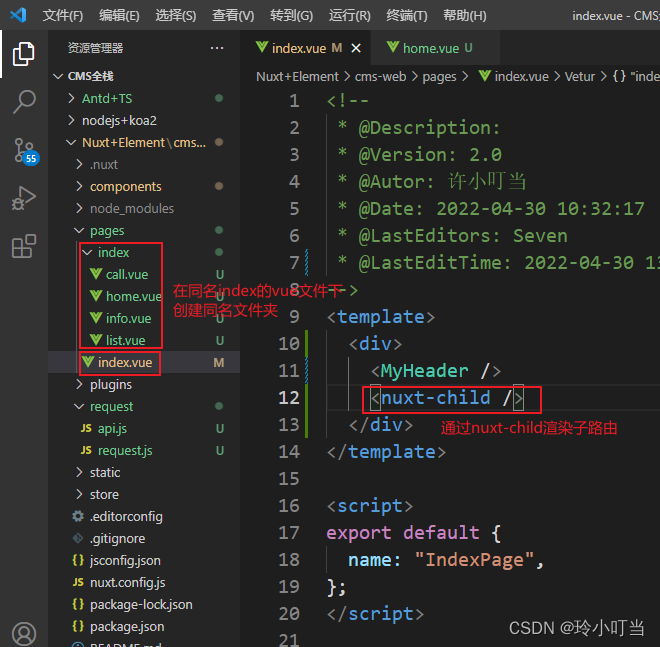
Nuxtjs quick start (nuxt2)
随机推荐
Experiment five categories and objects
Strengthen basic learning records
Strengthen basic learning records
7-11 机工士姆斯塔迪奥(PTA程序设计)
Experiment 7 use of common classes
7-6 local minimum of matrix (PTA program design)
[dark horse morning post] Shanghai Municipal Bureau of supervision responded that Zhong Xue had a high fever and did not melt; Michael admitted that two batches of pure milk were unqualified; Wechat i
Matlab opens M file garbled solution
On the idea of vulnerability discovery
Hackmyvm target series (3) -visions
captcha-killer验证码识别插件
[MySQL database learning]
XSS之冷门事件
网络层—简单的arp断网
Force deduction 152 question multiplier maximum subarray
7-9 make house number 3.0 (PTA program design)
Record a penetration of the cat shed from outside to inside. Library operation extraction flag
"Gold, silver and four" job hopping needs to be cautious. Can an article solve the interview?
7-14 error ticket (PTA program design)
Record once, modify password logic vulnerability actual combat