当前位置:网站首页>Replace convolution with full connection layer -- repmlp
Replace convolution with full connection layer -- repmlp
2022-07-02 07:52:00 【MezereonXP】
Replace convolution with full connection layer – RepMLP
This time I will introduce you to a job , “RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition”, It's recent MLP A representative article in the upsurge .
Its github Link to https://github.com/DingXiaoH/RepMLP, Energetic friends can go for a run , Take a look at the code .
So let's go back , Previous work based on convolutional Networks . The reason why convolution network can be effective , To some extent, it captures spatial information , Spatial features are extracted through multiple convolutions , And basically cover the whole picture . Suppose we put pictures “ Beat flat ” And then use MLP Training , Then the characteristic information in space is lost .
The contribution of this article lies in :
- Fully connected (FC) Global capabilities of (global capacity) as well as Location awareness (positional perception), It is applied to image recognition
- A simple 、 Platform independent (platform-agnostic)、 Differential algorithm , To convolute and BN Merge into FC
- Sufficient experimental analysis , Verified RepMLP The feasibility of
The overall framework
Whole RepMLP There are two stages :
- Training phase
- Testing phase
For these two stages , As shown in the figure below :

It looks a little complicated , Let's take a look at the training phase alone .
First of all Global perception (global perceptron)
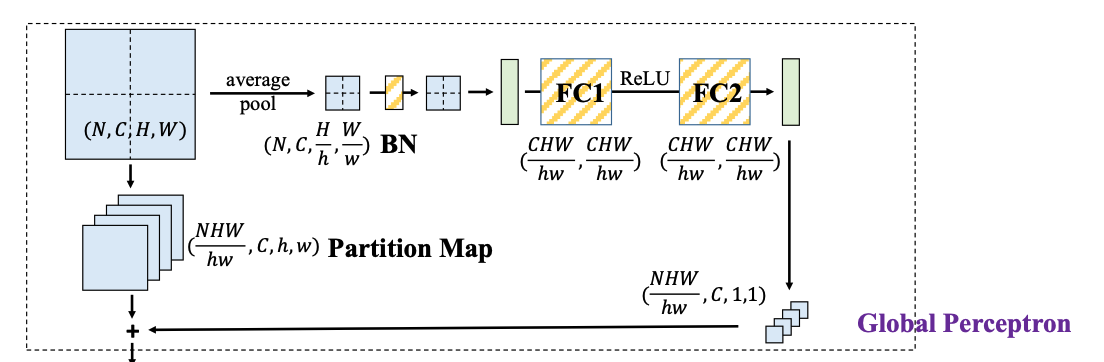
It is mainly divided into two paths :
- route 1: The average pooling + BN + FC1 + ReLU + FC2
- route 2: Block
We remember that the shape of the input tensor is ( N , C , H , W ) (N,C,H,W) (N,C,H,W)
route 1
For the path 1, First, average pooling converts input into ( N , C , H h , W w ) (N,C,\frac{H}{h},\frac{W}{w}) (N,C,hH,wW), Equivalent to scaling , Then the green part indicates that the tensor “ Beat flat ”
That is, to become ( N , C H W h w ) (N,\frac{CHW}{hw}) (N,hwCHW) The tensor of shape , Through two layers FC After the layer , Dimensions remain , Because the entire FC It is equivalent to multiplying left by a square matrix .
Eventually the ( N , C H W h w ) (N,\frac{CHW}{hw}) (N,hwCHW) Shape output reshape, Get a shape that is ( N H W h w , C , 1 , 1 ) (\frac{NHW}{hw}, C, 1, 1) (hwNHW,C,1,1) Output
route 2
For the path 2, Directly enter ( N , C , H , W ) (N,C,H,W) (N,C,H,W) convert to N H W h w \frac{NHW}{hw} hwNHW individual ( h , w ) (h,w) (h,w) Small pieces , Its shape is ( N H W h w , C , h , w ) (\frac{NHW}{hw},C,h,w) (hwNHW,C,h,w)
Finally, the path 1 And the path 2 Add the result of , Because the dimensions are not right , But in the PyTorch in , Automatic copy operation , That's all ( h , w ) (h,w) (h,w) The size of each pixel of the block , Will add a value .
The output shape of this part is ( N H W h w , C , h , w ) (\frac{NHW}{hw},C,h,w) (hwNHW,C,h,w)
Then enter Local awareness and Block perception Part of , As shown in the figure below :
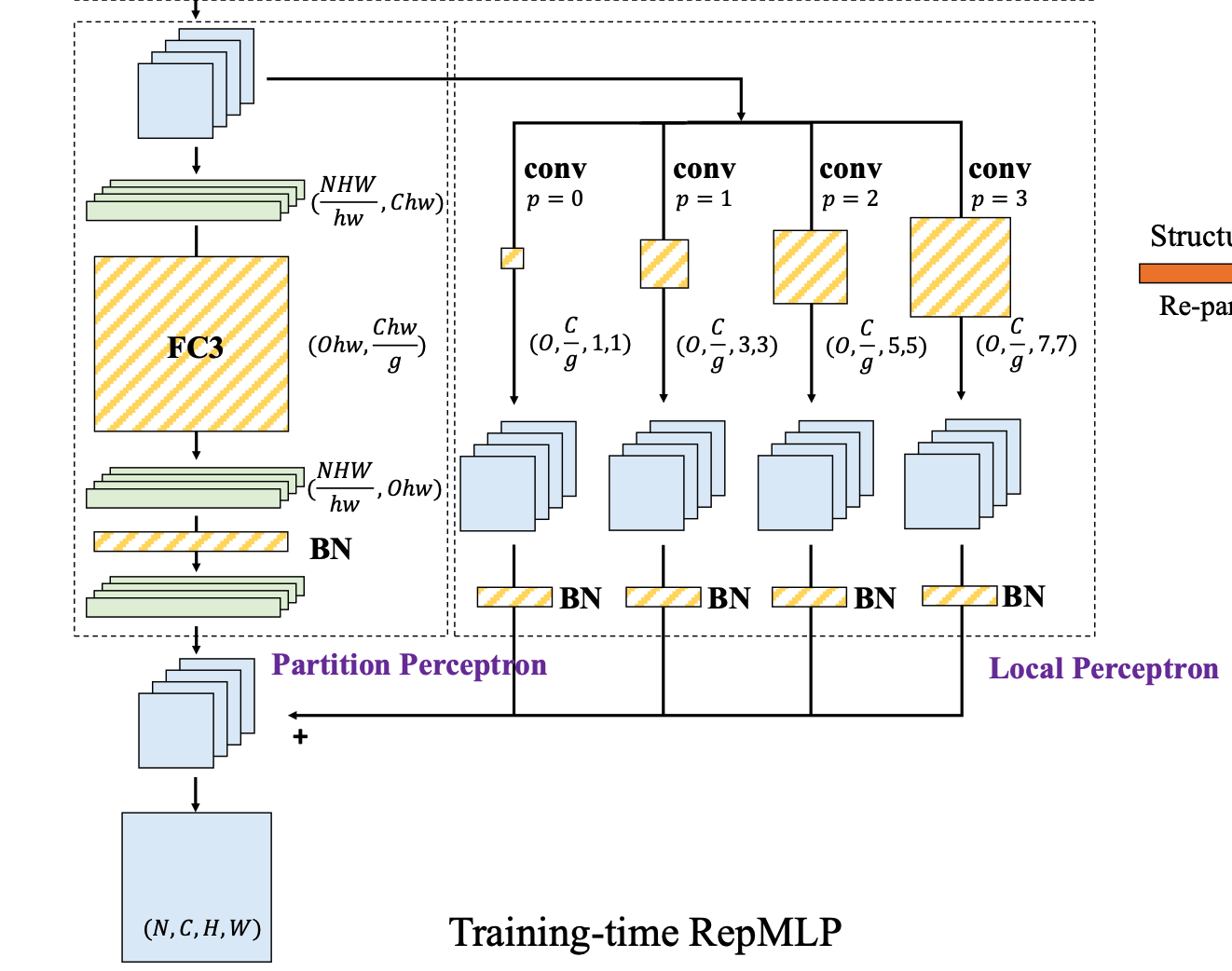
about Block perception (partition perceptron)
First , take 4 The tensor of dimension is plotted as 2 dimension , namely ( N H W h w , C , h , w ) (\frac{NHW}{hw},C,h,w) (hwNHW,C,h,w) become ( N H W h w , C h w ) (\frac{NHW}{hw},Chw) (hwNHW,Chw)
then FC3 It's a reference Grouping convolution (groupwise conv) The operation of , among g g g Is the number of groups
Original FC3 Should be ( O h w , C h w ) (Ohw,Chw) (Ohw,Chw) A matrix of , But in order to reduce the number of parameters , Used In groups FC(groupwise FC)
Packet convolution is essentially grouping channels , Let me give you an example :
Suppose the input is a ( C , H , W ) (C,H,W) (C,H,W) Tensor , If we want the output to be ( N , H ′ , W ′ ) (N,H',W') (N,H′,W′)
Usually, the shape of our convolution kernel is ( N , C , K , K ) (N,C,K,K) (N,C,K,K) , among K K K It's the size of the convolution kernel
We are right on the channel C C C Grouping , Every time g g g A group of channels , Then there is C g \frac{C}{g} gC A set of
For each group individually , Convolution operation , The shape of our convolution kernel will be reduced to ( N , C g , K , K ) (N,\frac{C}{g},K,K) (N,gC,K,K)
ad locum , grouping FC That is, the number of channels C h w Chw Chw Group and then pass each group FC, The resulting ( N H W h w , O , h , w ) (\frac{NHW}{hw}, O,h,w) (hwNHW,O,h,w) Tensor
after BN layer , The tensor shape remains unchanged .
And for Local awareness (local perceptron)

similar FPN Thought , Group convolution of different scales is carried out , Got it 4 The shape is ( N H W h w , O , h , w ) (\frac{NHW}{hw}, O,h,w) (hwNHW,O,h,w) Tensor
Add the results of local perception and block perception , Got it. ( N , O , H , W ) (N,O,H,W) (N,O,H,W) Output
Here you might ask , Isn't there still convolution ?
This is just the training stage , In the reasoning stage , Will throw away the convolution , As shown in the figure below :
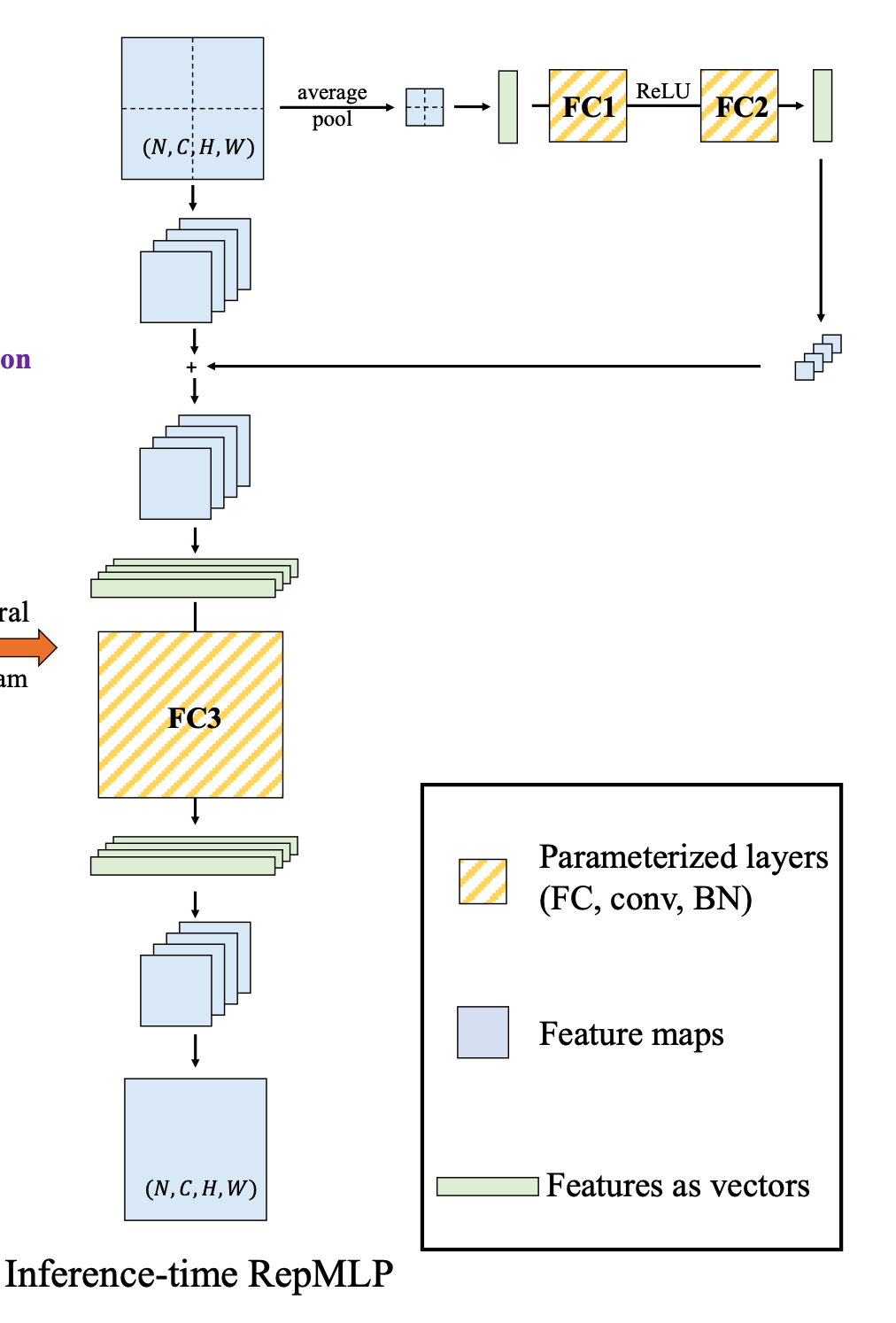
thus , We use it MLP Instead of a convolution operation
experimental analysis
The first is a series of Ablation Experiment (Ablation Study), stay CIFAR-10 Test on dataset
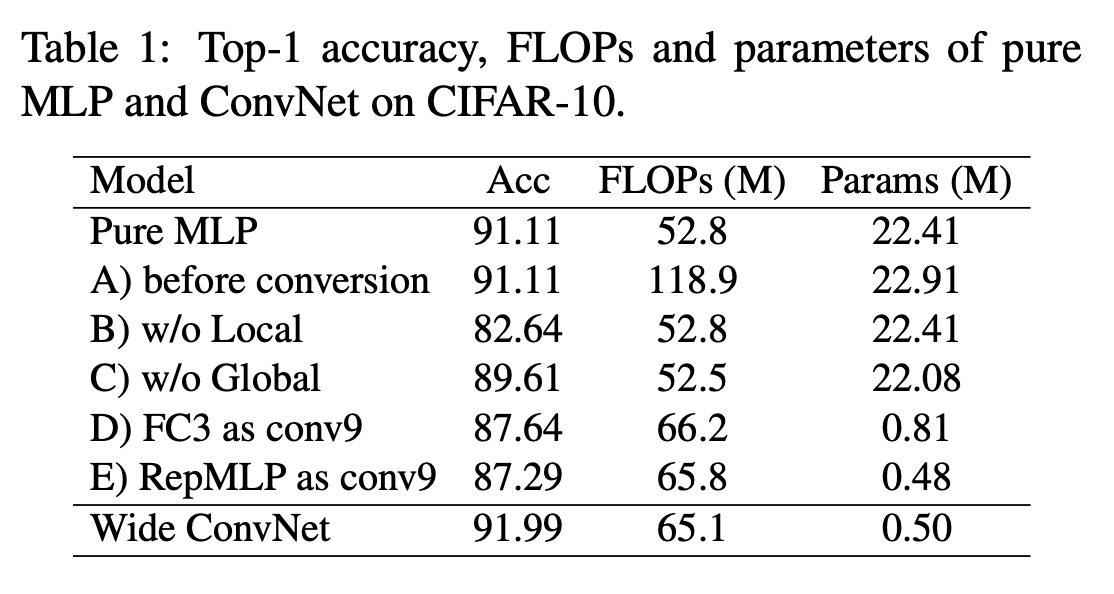
A The condition is to keep when inferring BN Layer and the conv layer , The results have not changed
D,E The conditions are to use a 9x9 Instead of the convolution layer FC3 And the whole RepMLP
Wide ConvNet It is to double the number of channels of the original network structure
The results show the importance of local perception and global perception , At the same time, it has no effect to remove the convolution part when inferring , Realized MLP Replacement
Then the author replaced ResNet50 Some of block, Tested

Replace only the penultimate residual block , There are more parameters , But the accuracy has increased slightly
If we replace more convolution parts completely

The parameter quantity will increase , The accuracy will also increase slightly
边栏推荐
猜你喜欢
Use Baidu network disk to upload data to the server

Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations
win10+vs2017+denseflow编译
【多模态】CLIP模型

传统目标检测笔记1__ Viola Jones

Network metering - transport layer

【Random Erasing】《Random Erasing Data Augmentation》
Installation and use of image data crawling tool Image Downloader
![[mixup] mixup: Beyond Imperial Risk Minimization](/img/14/8d6a76b79a2317fa619e6b7bf87f88.png)
[mixup] mixup: Beyond Imperial Risk Minimization
mmdetection训练自己的数据集--CVAT标注文件导出coco格式及相关操作
随机推荐
Translation of the paper "written mathematical expression recognition with bidirectionally trained transformer"
【DIoU】《Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression》
【Batch】learning notes
【深度学习系列(八)】:Transoform原理及实战之原理篇
自然辩证辨析题整理
[Sparse to Dense] Sparse to Dense: Depth Prediction from Sparse Depth samples and a Single Image
【双目视觉】双目矫正
【Paper Reading】
【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
How do vision transformer work?【论文解读】
[binocular vision] binocular correction
Faster-ILOD、maskrcnn_ Benchmark training coco data set and problem summary
Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations
How to turn on night mode on laptop
Comparison of chat Chinese corpus (attach links to various resources)
yolov3训练自己的数据集(MMDetection)
Mmdetection model fine tuning
TimeCLR: A self-supervised contrastive learning framework for univariate time series representation
Use Baidu network disk to upload data to the server
论文tips