当前位置:网站首页>Strengthen basic learning records
Strengthen basic learning records
2022-07-06 13:52:00 【I like the strengthened Xiaobai in Curie】
DQN Strengthen learning record
DQN The algorithm is Q-learning The combination of algorithm and deep neural network (Deep-Q-Network), Used to solve the problem of too high dimension .
One 、 Introduction to the environment
What we use here is gym Environmental ’CartPole-v0’, Here is a brief introduction , Detailed introduction with links .
link : OpenAI Gym Introduction to classic control environment ——CartPole( Inverted pendulum )
(1) The rules of the game : There is a car in the game , There is a pole on it , The initial state will be different after each reset .
<1> The inclination angle of the pole θ Not greater than 15°
<2> Where the trolley moves x It needs to be kept within a certain range ( From the middle to both sides 2.4 Unit length )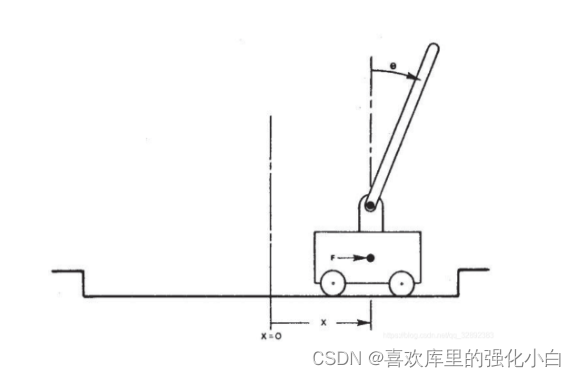
(2) The state space : Here the state space is continuous , The number of States is 4 individual ;
(3) Action space : Here the action space is discrete ,0 Represents shift left ,1 For shift right .
(4) Reward : stay gym Of Cart Pole Environmental Science (env) Inside , Moving the car left or right action after ,env Will return a +1 Of reward.
Two 、 A brief introduction to the algorithm
- Value-based
- Off-Policy
- DQN Characteristics :
<1> The use of neural networks :
When the state action space is large or continuous , Unable to get Q Table storage status - Action value Q(s,a). So we can use neural network , The relationship between fitting state and value . among , The input is the status value , The output is the corresponding q value .
DQN It is generally used to solve discrete action space problems . Because in the continuous action space , It is impossible to enumerate actions one by one , To find the corresponding q value . If you want to solve the problem of continuous action space , Need to introduce AC frame .
<2> Experience the use of playback mechanism :
Experience playback is a technology that makes the experience probability distribution stable , It can improve the stability of training . Experience playback mainly includes “ Storage ” and “ The playback ” Two key steps :
Experience storage : Each step , Intelligent experience stores a (s,a,r,s_,done) Track of , Also called transition, Store this record in the experience pool .
Experience playback : In program implementation , When the stored experience is greater than the set value , You can be in the experience pool , Equal probability extraction BATCH_SIZE Experience training , This breaks the correlation between data , At the same time, reuse experience , It also improves the utilization of data . In practical terms , Maybe according to the importance of experience , Priority playback according to weight .
<3> Use of the target network :
link : Target network
Simply speaking ,DQN Two networks are introduced in , One is behavioral network , One is the target network , Their structures and parameters are the same , Only the parameter lags , Every once in a while , Update the target network . The update here can be hard updated , Feed the parameters directly , You can also make soft updates , Update by weight . This lagging update , It's stable Q Learning on the Internet .
The target network does not carry out reverse transmission , Equivalent to a reference , Behavioral networks through training , Back propagation , The closer to the target network , Instructions for Q Value evaluation is more accurate . - Pseudo code

- Realization
link : Don't worry about it
Refer to the implementation of Mo fan , Some of them , I don't quite understand , Annotated .
import matplotlib.pyplot as plt
import torch # Import torch
import torch.nn as nn # Import torch.nn
import torch.nn.functional as F # Import torch.nn.functional
import numpy as np # Import numpy
import gym # Import gym
# Hyperparameters
BATCH_SIZE = 32 # Number of samples
LR = 0.01 # Learning rate
EPSILON = 0.9 # greedy policy
GAMMA = 0.9 # reward discount
TARGET_REPLACE_ITER = 100 # Target network update frequency
MEMORY_CAPACITY = 2000 # Memory capacity
env = gym.make('CartPole-v0').unwrapped # Use gym Environment in the Library :CartPole, And open the package ( If you want to understand the environment , Please Baidu )
N_ACTIONS = env.action_space.n # The number of pole movements (2 individual )
N_STATES = env.observation_space.shape[0] # Number of pole States (4 individual )
""" torch.nn It's a modular interface designed specifically for neural networks .nn Built on Autograd above , It can be used to define and run neural networks . nn.Module yes nn A very important class in , It includes the definition and of each layer of the network forward Method . Defining network : Need to inherit nn.Module class , And implement forward Method . Generally, the layers with learnable parameters in the network are placed in the constructor __init__() in . As long as nn.Module Is defined in subclass of forward function ,backward The function will be implemented automatically ( utilize Autograd). """
# Definition Net class ( Defining network )
class Net(nn.Module):
def __init__(self): # Definition Net A series of properties of
# nn.Module The subclass function of must execute the constructor of the parent class in the constructor
super(Net, self).__init__() # Equivalence and nn.Module.__init__()
self.fc1 = nn.Linear(N_STATES, 50) # Set up the first full connection layer ( Input layer to hidden layer ): State several neurons to 50 Neurons
self.fc1.weight.data.normal_(0, 0.1) # Weight initialization ( The mean for 0, The variance of 0.1 Is a normal distribution )
self.out = nn.Linear(50, N_ACTIONS) # Set up the second full connection layer ( Hidden layer to output layer ): 50 From neurons to action neurons
self.out.weight.data.normal_(0, 0.1) # Weight initialization ( The mean for 0, The variance of 0.1 Is a normal distribution )
def forward(self, x): # Definition forward function (x For state )
x = F.relu(self.fc1(x)) # Connect the input layer to the hidden layer , And use the excitation function ReLU To process the value after passing through the hidden layer
actions_value = self.out(x) # Connect the hidden layer to the output layer , Get the final output value ( Action value )
return actions_value # Return the action value
# Definition DQN class ( Define two networks )
class DQN(object):
def __init__(self): # Definition DQN A series of properties of
self.eval_net, self.target_net = Net(), Net() # utilize Net Create two neural networks : Evaluate the network and target network
self.learn_step_counter = 0 # for target updating
self.memory_counter = 0 # for storing memory
self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # Initialize the memory , One line represents one transition
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR) # Use Adam Optimizer ( Input is the parameters and learning rate of the evaluation network )
self.loss_func = nn.MSELoss() # Use the mean square loss function (loss(xi, yi)=(xi-yi)^2)
def choose_action(self, x): # Define the action selection function (x For state )
x = torch.unsqueeze(torch.FloatTensor(x), 0) # take x convert to 32-bit floating point form , And in dim=0 Increase the dimension to 1 Dimensions
if np.random.uniform() < EPSILON: # Generate a new one in [0, 1) The random number in , If it is less than EPSILON, Choose the best action
actions_value = self.eval_net.forward(x) # By evaluating the network input status x, Forward propagation obtains action value
#torch.max(a,1) Presentation selection a The largest element in each line ,[1] Represents an index similar to a key value pair [0] Express the numpy Get the one-dimensional array of
action = torch.max(actions_value, 1)[1].data.numpy() # Output the index of the maximum value of each row , And into numpy ndarray form
action = action[0] # Output action The first number of
else: # Randomly choose actions
action = np.random.randint(0, N_ACTIONS) # here action Random equals 0 or 1 (N_ACTIONS = 2)
return action # Return to the selected action (0 or 1)
def store_transition(self, s, a, r, s_): # Define memory storage functions ( Enter here as a transition)
transition = np.hstack((s, [a, r], s_)) # Concatenate arrays horizontally
# If the memory bank is full , Then overwrite the old data
index = self.memory_counter % MEMORY_CAPACITY # obtain transition The number of rows to put
self.memory[index, :] = transition # Implantation transition
self.memory_counter += 1 # memory_counter Self adding 1
def learn(self): # Defining learning functions ( When the memory bank is full, start learning )
# Target network parameter update
if self.learn_step_counter % TARGET_REPLACE_ITER == 0: # Trigger at the beginning , Then each 100 Step trigger
self.target_net.load_state_dict(self.eval_net.state_dict()) # Assign the parameters of the evaluation network to the target network
self.learn_step_counter += 1 # The number of learning steps increases by itself 1
# Extract batch data from the memory
#sampe_index:ndarray(32,)
sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE) # stay [0, 2000) Internal random sampling 32 Number , May repeat
#b_memory:ndarray(32,10) #b_s:ndarray(32,4)
b_memory = self.memory[sample_index, :] # extract 32 An index corresponds to 32 individual transition, Deposit in b_memory
b_s = torch.FloatTensor(b_memory[:, :N_STATES])
# take 32 individual s Draw out , To 32-bit floating point form , And store it to b_s in ,b_s by 32 That's ok 4 Column
b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int))
# take 32 individual a Draw out , To 64-bit integer (signed) form , And store it to b_a in ( The reason is LongTensor type , It's for the convenience of the back torch.gather Use ),b_a by 32 That's ok 1 Column
b_r = torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2])
# take 32 individual r Draw out , To 32-bit floating point form , And store it to b_s in ,b_r by 32 That's ok 1 Column
b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:])
# take 32 individual s_ Draw out , To 32-bit floating point form , And store it to b_s in ,b_s_ by 32 That's ok 4 Column
# obtain 32 individual transition Evaluation value and target value , And use the loss function and optimizer to evaluate the network parameter update
q_eval1 = self.eval_net(b_s)
q_eval = q_eval1.gather(1, b_a)
# eval_net(b_s) By evaluating the network output 32 Each row b_s Corresponding series of action values , then .gather(1, b_a) Represents the corresponding index for each row b_a Of Q Value extraction for aggregation
q_next = self.target_net(b_s_).detach()
# q_next No reverse transfer error , therefore detach;q_next Indicates output through the target network 32 Each row b_s_ Corresponding series of action values
q = q_next.max(1)[0]
q_target = b_r + GAMMA * q.view(BATCH_SIZE,1)
# q_next.max(1)[0] Indicates that only the maximum value of each row is returned , Do not return index ( The length is 32 One dimensional tensor of );.view() It means to change the one-dimensional tensor obtained above into (BATCH_SIZE, 1) The shape of the ; Finally, the target value is obtained through the formula
loss = self.loss_func(q_eval, q_target)
# Input 32 Evaluation value and 32 Target value , Use the mean square loss function
self.optimizer.zero_grad() # Clear the residual update parameter value of the previous step
loss.backward() # Error back propagation , Calculate parameter update values
self.optimizer.step() # Update all parameters of the evaluation network
dqn = DQN() # Make dqn=DQN class
rewards = []
for i in range(400): # 400 individual episode loop
print('<<<<<<<<<Episode: %s' % i)
s = env.reset() # Reset environment
episode_reward_sum = 0 # Initialize... Corresponding to this loop episode The total reward for
while True: # Start a episode ( Each cycle represents a step )
env.render() # Show experimental animation
a = dqn.choose_action(s) # Enter the status corresponding to this step s, Choose action
s_, r, done, info = env.step(a) # Executive action , Get feedback
# Modify the award ( You can do it without modification , Modify the reward just to get the trained swing faster )
x, x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
new_r = r1 + r2
dqn.store_transition(s, a, new_r, s_) # Store samples
episode_reward_sum += new_r # Gradually add one episode Each inside step Of reward
s = s_ # Update status
if dqn.memory_counter > MEMORY_CAPACITY: # If cumulative transition The number exceeds the fixed capacity of the memory 2000
# Begin to learn ( Extract memory , namely 32 individual transition, And update the evaluation network parameters , And after starting to study every 100 Assign the parameters of the evaluation network to the target network )
dqn.learn()
if done: # If done by True
# round() Method returns episode_reward_sum The decimal point of is rounded to 2 A digital
print('episode%s---reward_sum: %s' % (i, round(episode_reward_sum, 2)))
rewards.append(episode_reward_sum)
break
边栏推荐
- [graduation season · advanced technology Er] goodbye, my student days
- Programme de jeu de cartes - confrontation homme - machine
- [hand tearing code] single case mode and producer / consumer mode
- 力扣152题乘数最大子数组
- Mortal immortal cultivation pointer-2
- [during the interview] - how can I explain the mechanism of TCP to achieve reliable transmission
- 自定义RPC项目——常见问题及详解(注册中心)
- . How to upload XMIND files to Jinshan document sharing online editing?
- 1. Preliminary exercises of C language (1)
- Implementation principle of automatic capacity expansion mechanism of ArrayList
猜你喜欢

优先队列PriorityQueue (大根堆/小根堆/TopK问题)
2. C language matrix multiplication
![[during the interview] - how can I explain the mechanism of TCP to achieve reliable transmission](/img/d6/109042b77de2f3cfbf866b24e89a45.png)
[during the interview] - how can I explain the mechanism of TCP to achieve reliable transmission
4. Branch statements and loop statements

Thoroughly understand LRU algorithm - explain 146 questions in detail and eliminate LRU cache in redis
7-5 走楼梯升级版(PTA程序设计)
SRC挖掘思路及方法
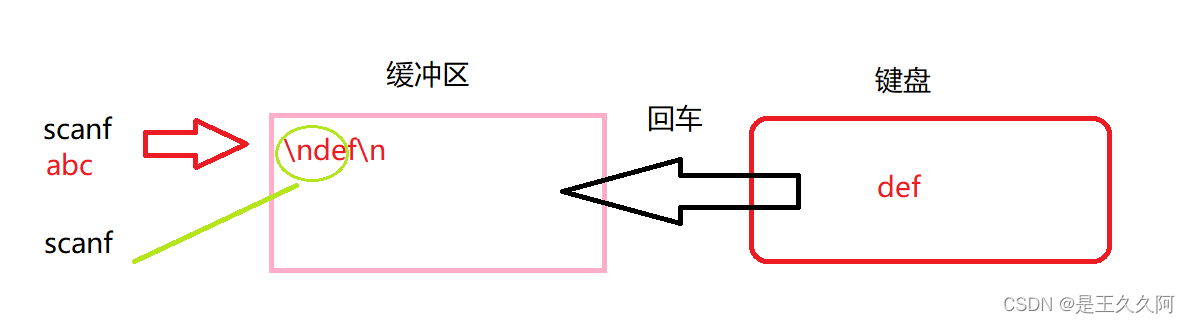
3. Input and output functions (printf, scanf, getchar and putchar)

It's never too late to start. The tramp transformation programmer has an annual salary of more than 700000 yuan
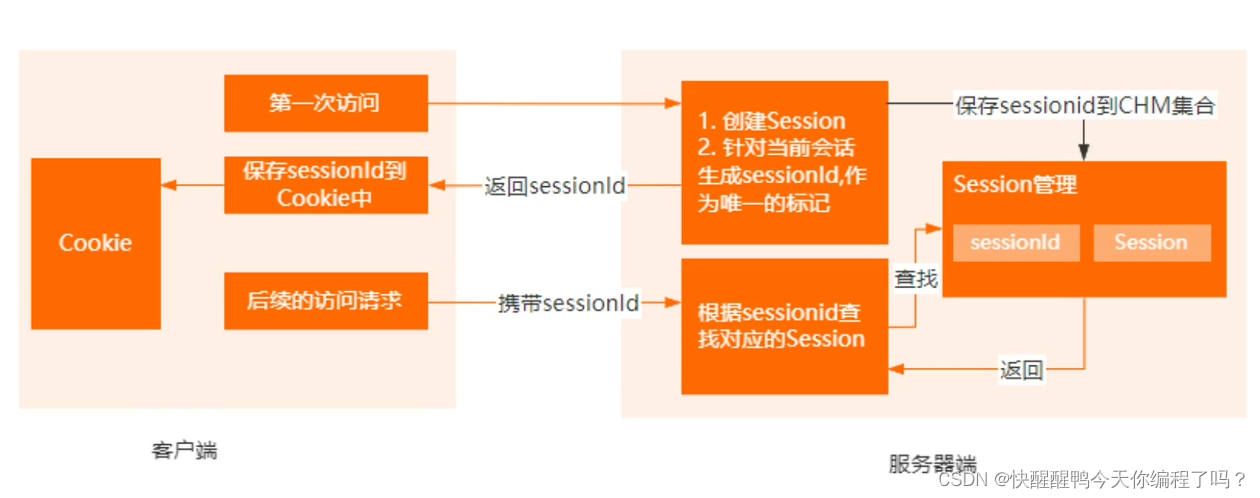
The difference between cookies and sessions
随机推荐
[dark horse morning post] Shanghai Municipal Bureau of supervision responded that Zhong Xue had a high fever and did not melt; Michael admitted that two batches of pure milk were unqualified; Wechat i
杂谈0516
实验七 常用类的使用
[the Nine Yang Manual] 2022 Fudan University Applied Statistics real problem + analysis
[during the interview] - how can I explain the mechanism of TCP to achieve reliable transmission
【MySQL-表结构与完整性约束的修改(ALTER)】
渗透测试学习与实战阶段分析
Redis的两种持久化机制RDB和AOF的原理和优缺点
ABA问题遇到过吗,详细说以下,如何避免ABA问题
7-3 构造散列表(PTA程序设计)
Using spacedesk to realize any device in the LAN as a computer expansion screen
Mortal immortal cultivation pointer-2
Difference and understanding between detected and non detected anomalies
Relationship between hashcode() and equals()
Mode 1 two-way serial communication is adopted between machine a and machine B, and the specific requirements are as follows: (1) the K1 key of machine a can control the ledi of machine B to turn on a
一段用蜂鸣器编的音乐(成都)
Have you encountered ABA problems? Let's talk about the following in detail, how to avoid ABA problems
【九阳神功】2019复旦大学应用统计真题+解析
Implementation of count (*) in MySQL
【九阳神功】2016复旦大学应用统计真题+解析