当前位置:网站首页>Cloud backup project
Cloud backup project
2022-07-07 07:16:00 【Li Hanhan_】
Cloud backup project
List of articles
Understanding of cloud backup
Automatically upload and back up the files to be backed up in the specified folder on the local computer to the server . And it can be viewed and downloaded through the browser at any time , The download process supports the breakpoint continuation function , The server will also perform hotspot management for uploaded files , Compress and store non hotspot files , Save disk space .
Project objectives
Server program : Deployed in Linux Server
Realize the business processing for client requests : Upload and backup of files , And the viewing and downloading functions of the client browser . And it has the function of hotspot management , Compress and store non hotspot files to save disk space
Client program : Deployed in Windows On the client
Implement files in the specified folder on the client host , Automatic detection to determine whether backup is required , Upload to the server for backup if necessary
Module partition
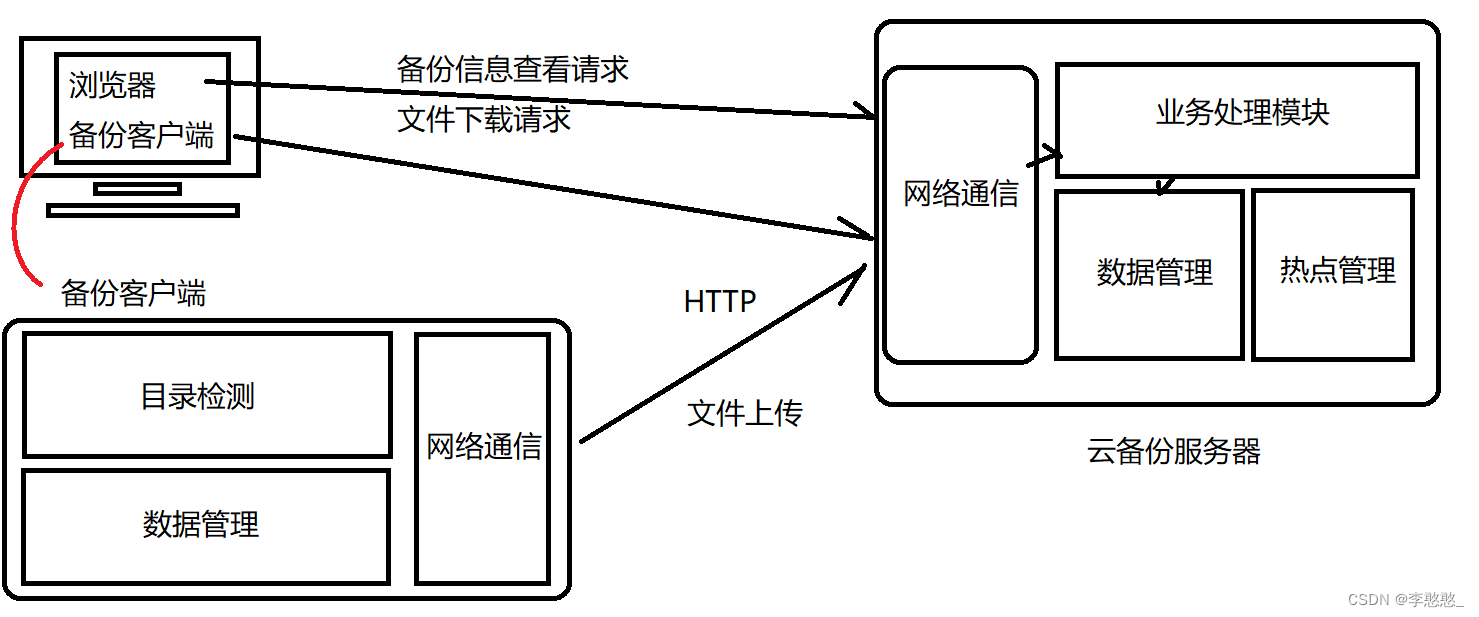
Server side :
Network communication module : Realize network communication with the client , And carry on http Protocol data analysis
Business processing module : Specify the client request , And carry out corresponding business processing ( Upload files , Backup information acquisition , File download )
Data management module : Unified data management
Hotspot management module : Perform hotspot management on the files backed up on the server , Compress and store non hotspot files
On our server , First, there is a network communication module , This module can be implemented with any client , We have two clients , One is the browser , One is the backup client written by ourselves , Our backup client is dedicated to our network communication module , That is, our server sends a file upload request, while the browser sends a backup information view request and file download request to the server .
After the server receives the network communication data , There is a very important module in the server : Business processing module , Its function is , The data is received by the network communication module , The business processing module performs a data analysis , What kind of request is it to analyze this data , And carry out a corresponding business processing for this request .
There is also a module on the server , It is called data management module , This module is a network communication module dedicated to data management. After receiving the data, it will analyze , After parsing, the business processing module performs business processing , Data access will be involved in the process of business processing , No direct access to data , Instead, data is obtained through the data management module , Operate on data , Whether it's management , Storage , Whether it is acquired or not is carried out uniformly by the data management module , Just send the request .
There is also a hot management module running in parallel with the business processing module on the server ( Server background function ), Specifically detect which files on the server are less popular , Become a non hot file , Compress it , If someone in the business processing module wants to download this file , Decompress the file before responding , After all, it is a non hot spot .
client :( Backup client )
Directory detection module : Traverse the specified folder on the client host , Get all the file information under the folder
Data management module : Manage all file information backed up by the client
( Determine whether a file needs to be backed up :1. Historical backup information does not exist ,2. Historical backup information exists but is inconsistent )
Network communication module : Build a network communication client , Upload and back up the files to be backed up to the server
The third party library knows
JSON know
json Is a data exchange format , Use text format completely independent of programming language to store and represent data .
for example : Student information of Xiaoming
char name = " Xiao Ming ";
int age = 18;
float score[3] = {
88.5, 99, 58};
When network data transmission or persistent storage is needed : It needs to be organized according to the specified data format , In this way, it can be resolved when used
be json This data exchange format organizes the various data objects into a string :
[
{
" full name " : " Xiao Ming ",
" Age " : 18,
" achievement " : [88.5, 99, 58]
},
{
" full name " : " Little black ",
" Age " : 18,
" achievement " : [88.5, 99, 58]
}
]
json data type : object , Array , character string , Numbers
object : Use curly braces {} Enclosed represents an object .
Array : Use brackets [] Enclosed represents an array .
character string : Use regular double quotes “” Enclosed represents a string
Numbers : Including integer and floating point , Use it directly .
It is composed of key value pairs
To put it bluntly, it is to format multiple data into a specified format string
jsoncpp library : It provides a series of interfaces for implementation JSON Format serialization and deserialization .
//Json Data object class
class Json::Value{
Value &operator=(const Value &other); //Value Reload the [] and =, Therefore, all assignment and data acquisition can be through
Value& operator[](const std::string& key);// Do it in a simple way val[" full name "] = " Xiao Ming ";
Value& operator[](const char* key);
Value removeMember(const char* key);// Remove elements
const Value& operator[](ArrayIndex index) const; //val[" achievement "][0]
Value& append(const Value& value);// Add array elements val[" achievement "].append(88);
ArrayIndex size() const;// Get the number of array elements val[" achievement "].size();
std::string asString() const;// turn string string name = val["name"].asString();
const char* asCString() const;// turn char* char *name = val["name"].asCString();
Int asInt() const;// turn int int age = val["age"].asInt();
float asFloat() const;// turn float
bool asBool() const;// turn bool
};
Json::Value class :jsoncpp Intermediate data classes for data interaction between the library and the outside world
If you want to serialize multiple and data objects , You need to instantiate a Json::Value object , Add data
Json::Write class :jsoncpp A serialization class of Library
Member interface :write() Interface is used to put Json::Value All data in the object is serialized into a string .
Json::Reader class :jsoncpp An anti sequence class of Library
Member interface :parse() Interface is used to put a json Format string , Parse the data to Json::Value In the object
example :
This is a serialization
#include <iostream>
#include <sstream>
#include <string>
#include <jsoncpp/json/json.h>
using namespace std;
void Serialize() {
const char *name = " Xiao Ming ";
int age = 18;
float score[] = {
77.5, 88, 99};
// serialize
//1. Define a Json::Value object , Fill in the data
Json::Value val;
val[" full name "] = name;
val[" Age "] = age;
val[" achievement "].append(score[0]);
val[" achievement "].append(score[1]);
val[" achievement "].append(score[2]);
//2. Use StreamWriter Object serialization
Json::StreamWriterBuilder swb;
Json::StreamWriter *sw = swb.newStreamWriter();//new One StreamWriter object
stringstream ss;
sw->write(val, &os);// Implement serialization
cout << ss.str() << endl;
delete sw;
}
int main()
{
Serialize();
return 0;
}

Next, let's look at a deserialization
void UnSerialize(string &str) {
Json::CharReaderBuilder crb;
Json::CharReader *cr = crb.newCharReader();
Json::Value val;
string err;
bool ret = cr->parse(str.c_str(), str.c_str() + str.size(), &val, &err);
if (ret == false) {
cout << "UnSerialize failed:" << err << endl;
delete cr;
return ;
}
cout << val[" full name "].asString() << endl;
cout << val[" Gender "].asString() << endl;
cout << val[" Age "].asString() << endl;
int sz = val[" achievement "].size();
for (int i = 0; i < sz; ++i) {
cout << val[" achievement "][i].asFloat() << endl;
}
delete cr;
return;
}

bundle File compression library
BundleBundle Is an embedded compression library , Support 23 Compression algorithm and 2 Archive formats . When using, you only need to add two files bundle.h and bundle.cpp that will do .
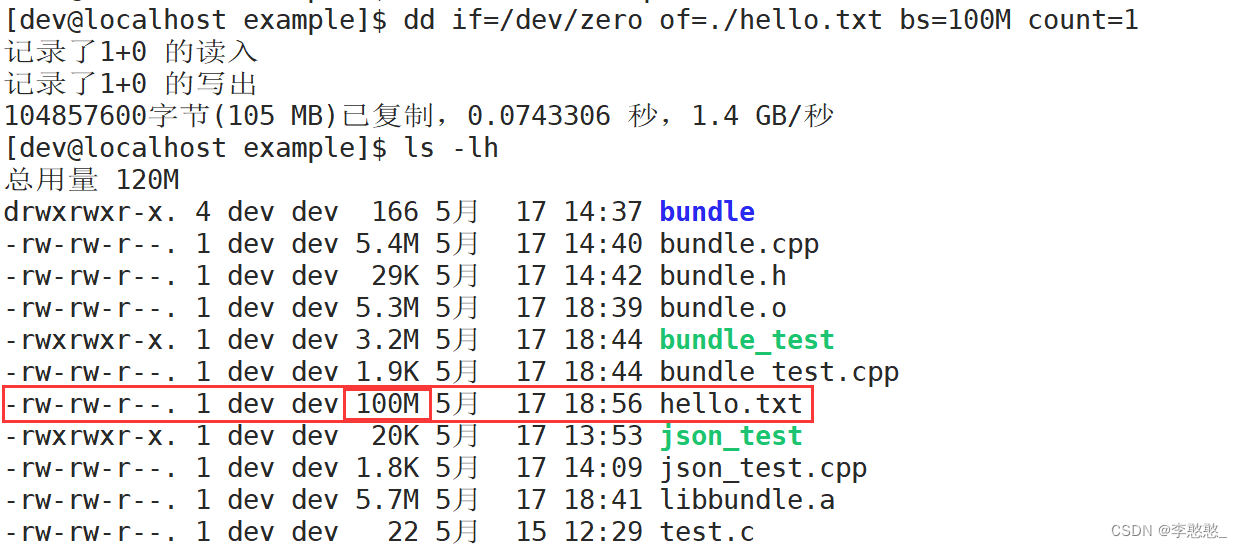
Let's create a 100M Size file
dd if=/dev/zero of=./hello.txt bs=100M count=1
#include <iostream>
#include <fstream>
#include <string>
#include "bundle.h"
using namespace std;
// Read all the data in the file
bool Read(const string &name, string *body) {
ifstream ifs;
ifs.open(name, ios::binary);// Open the file in binary mode
if (ifs.is_open() == false) {
cout << "open failed!\n";
return false;
}
ifs.seekg(0, ios::end);//fseek(fp, 0, SEEK_END);
size_t fsize = ifs.tellg();// Get the offset of the current position from the starting position of the file
ifs.seekg(0, ios::beg);//fseek(fp, 0, SEEK_SET);
body->resize(fsize);
ifs.read(&(*body)[0], fsize);//string::c_str() Return value const char*
if (ifs.good() == false) {
cout << "read file failed!\n";
ifs.close();
return false;
}
ifs.close();
return true;
}
// Write data to file
bool Write(const string &name, const string &body) {
ofstream ofs;
ofs.open(name, ios::binary);// Open the file in binary mode
if (ofs.is_open() == false) {
cout << "open failed!\n";
return false;
}
ofs.write(body.c_str(), body.size());
if (ofs.good() == false) {
cout << "read file failed!\n";
ofs.close();
return false;
}
ofs.close();
return true;
}
void Compress(const string &filename, const string &packname) {
string body;
Read(filename, &body);// from filename Read data from file to body in
string packed = bundle::pack(bundle::LZIP, body);// Yes body The data in lzip Format compression , Return compressed data
Write(packname, packed);// Write the compressed data into the specified compressed package
}
void UnCompress(const string &filename, const string &packname) {
string packed;
Read(packname, &packed);// Read the compressed data from the compressed package
string body = bundle::unpack(packed);// Decompress the compressed data
Write(filename, body);// Write the extracted data to a new file
}
int main()
{
Compress("./hello.txt", "./hello.zip");
UnCompress("./hi.txt", "./hello.zip");
return 0;
}
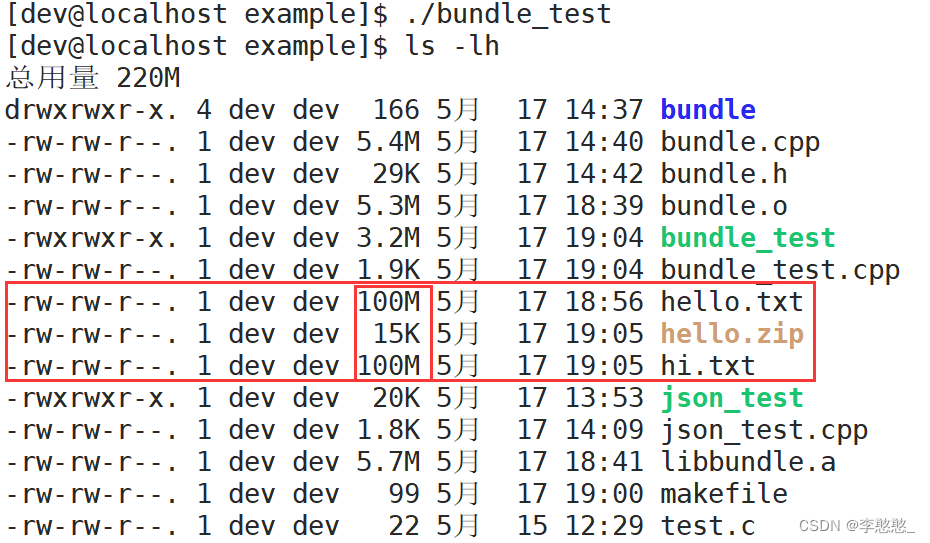
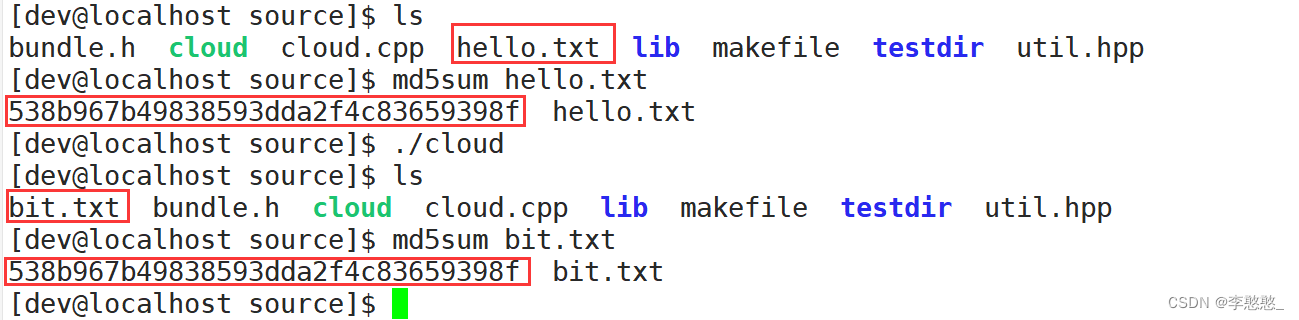
Verify whether the contents of the two files are consistent , Then calculate the of two files MD5 value , Whether the comparison is consistent
MD5: It's a hash algorithm , Will perform a lot of calculations based on data , Finally get a final result ( character string ), As long as the contents of the two documents are slightly different , Then you finally get MD5 Values are completely different 
Obviously, we can see that , These two documents are consistent
httplib library
httplib library , One C++11 Single header cross platform HTTP/HTTPS library . It is very easy to install . Just include httplib.h In your code .
httplib The library is actually used to build a simple http Server or client library , This third-party network library , It can save us the time of setting up the server or client , Put more energy into specific business processing , Improve development efficiency .
http Protocol is an application layer protocol , At the transport layer, it is based on tcp Realize transmission — therefore http The protocol is essentially the data format of the application layer
http Form of agreement :
request :
Request first line : Request method URL Protocol version \r\n
Header field :key:val\r\n The key/value pair
Blank line :\r\n- Used to separate the header from the text
Text : Data submitted to the server
Respond to :
Response first line : Protocol version Response status code Status code description \r\n
Header field :key: val\r\n The key/value pair
Blank line :\r\n- Used for indirect headers and text
Text : Respond to the client's data
stay httplib In the library , There are two data structures , Used to store request and response information :struct Request & struct Response

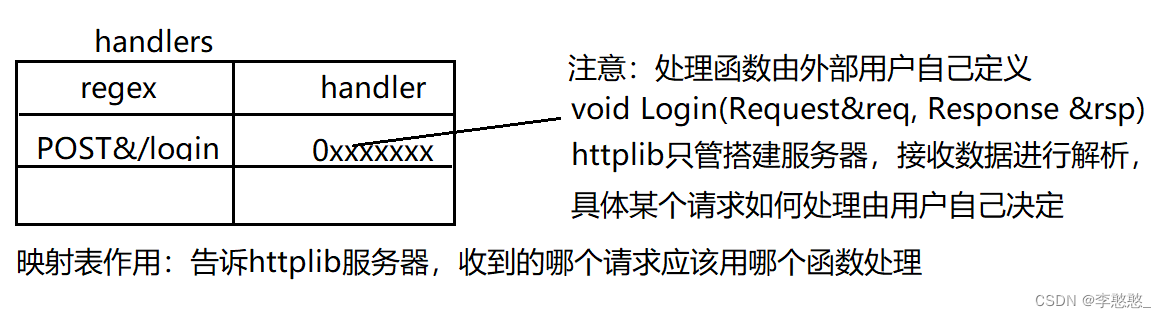
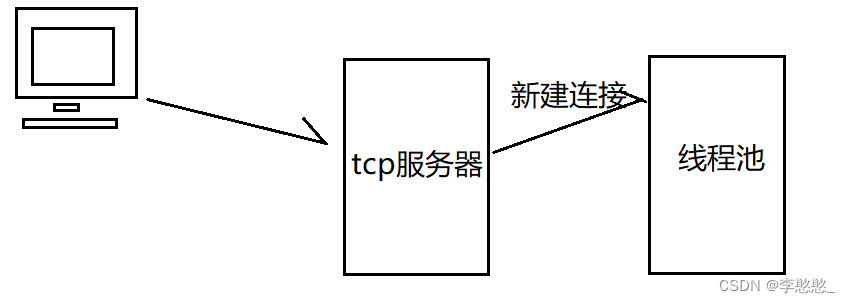
Threads in the thread pool get connections for processing :
1. Receive request data , And analyze , Put the parsed request data into a Request Structural variable req in ;
2. Based on the requested information ( Request method & Resource path ), Go to the mapping table to find out whether there is a corresponding processing function , If not, return 404;
3. If there is corresponding mapping information - Call the business processing function , Will parse the resulting req In the incoming interface , And pass in an empty Response Structural variable rsp;
4. The processing function will be based on req Perform corresponding business processing according to the request information in , And in the process of processing, I think rsp Add response information to the structure ;
5. Wait until the processing function is completed , be httplib Get a filled with response information Response Variable rsp;
6. according to rsp Information in , Organize a http Response in format , Send to client ;
7. If it is a short connection, close the connection and process the next , Long connections wait for requests , If it times out, close the processing of the next ;
First look at a simple file upload interface
<!--html Is a hypertext markup language , A tag can be understood as an element , A control -->
<html>
<body>
<!--form Is a form field control , When you click the submit button in the form field , The data of all controls in the form field will be organized and submitted -->
<!--action Is the resource path of this request ;method Is the requested method ;enctype It's the encoding type , Is the organization format of data -->
<form action="http://192.168.122.000:9090/upload" method="post" enctype="multipart/form-data">
<div>
<input type="file" name="file"> <!-- This is a file upload selection box -->
</div>
<div>
<input type="submit" name="submit" value=" Upload "> <!-- This is a submit Submit button -->
</div>
</form>
</body>
</html>

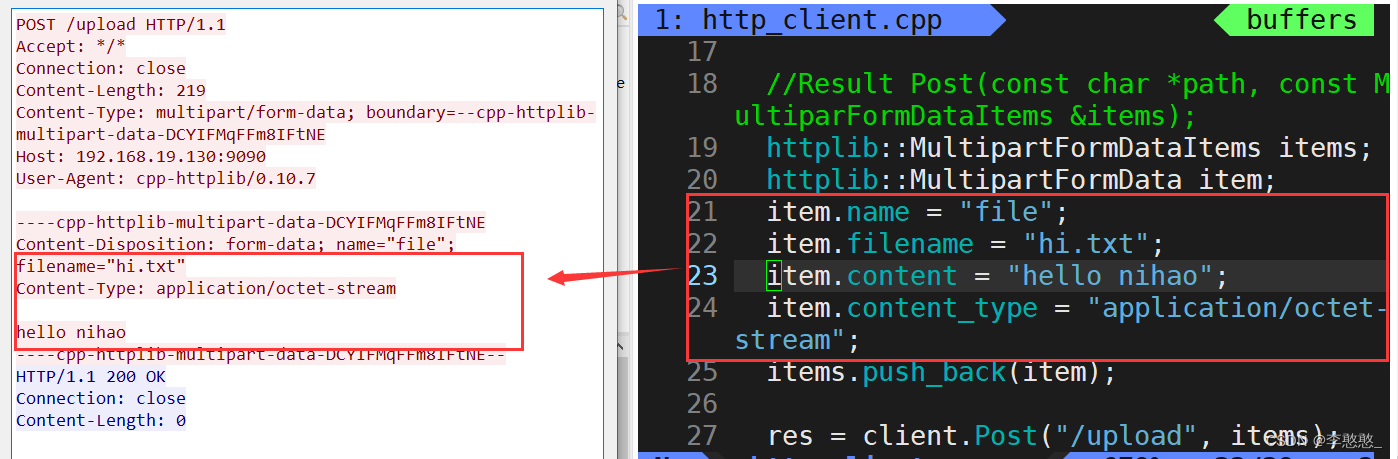
Its data organization format is like this
POST /upload HTTP/1.1
HOST: 192.168.122.130:9090
Connection: keep-alive
Content-Length: xxxxx
Content-Type: multipart/form-data; boundary=--xxxxxxxxxxxxxxxxxxxx
----xxxxxxxxxxxxxxxxxxxxxxxxxx
Content-Disposition: form-data; name='file' filename=''
File data of the selected file
----xxxxxxxxxxxxxxxxxxxxxxxxxx
Content-Disposition: form-data; name='submit'
Upload ( Upload button value value )
----xxxxxxxxxxxxxxxxxxxxxxxxxx
httplib Library setup server
With such an interface , We can build http The server
#include "httplib.h"
using namespace std;
void Numbers(const httplib::Request &req, httplib::Response &rsp)
{
// This is the business processing function
rsp.body = req.path;
rsp.body += "-------------";
rsp.body += req.matches[1];
rsp.status = 200;
rsp.set_header("Content-Type", "text/plain");
}
void Upload(const httplib::Request &req, httplib::Response &rsp)
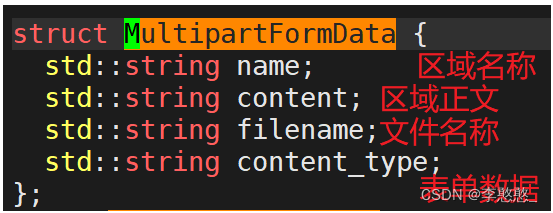
{
//req.files MultipartFormDataMap v--MultipartFormData{name, filename, content, content_type}
for (auto &v : req.files) {
cout << v.second.name << endl; // Area field identification name
cout << v.second.filename << endl;// If it is a file upload, save the file name
cout << v.second.content << endl;// Area body data , If it is file upload, it is file content data
}
}
int main()
{
// Instantiation server object
httplib::Server server;
// Add mapping relationship -- Tell the server what request to use and which function to process
// Because the number cannot determine the fixed data , So people actually use regular expressions -- Match the data that conforms to the rules
// In regular expressions \d Represents a numeric character ;+ Indicates matching the preceding character one or more times ;() It means to capture the data of rules in parentheses
server.Get("/numbers/(\\d+)", Numbers);
server.Post("/upload", Upload);
//0.0.0.0 Indicates any address of the server ; The virtual machine needs to turn off the firewall ; ECS needs to set the security group opening port
server.listen("0.0.0.0", 9090);
return 0;
}
We can action Change the resource path in to our own virtual machine or ECS address , Then when we click Select , Choose what we just wrote HTML file , Then click upload , You can see the result 
httplib Library build client
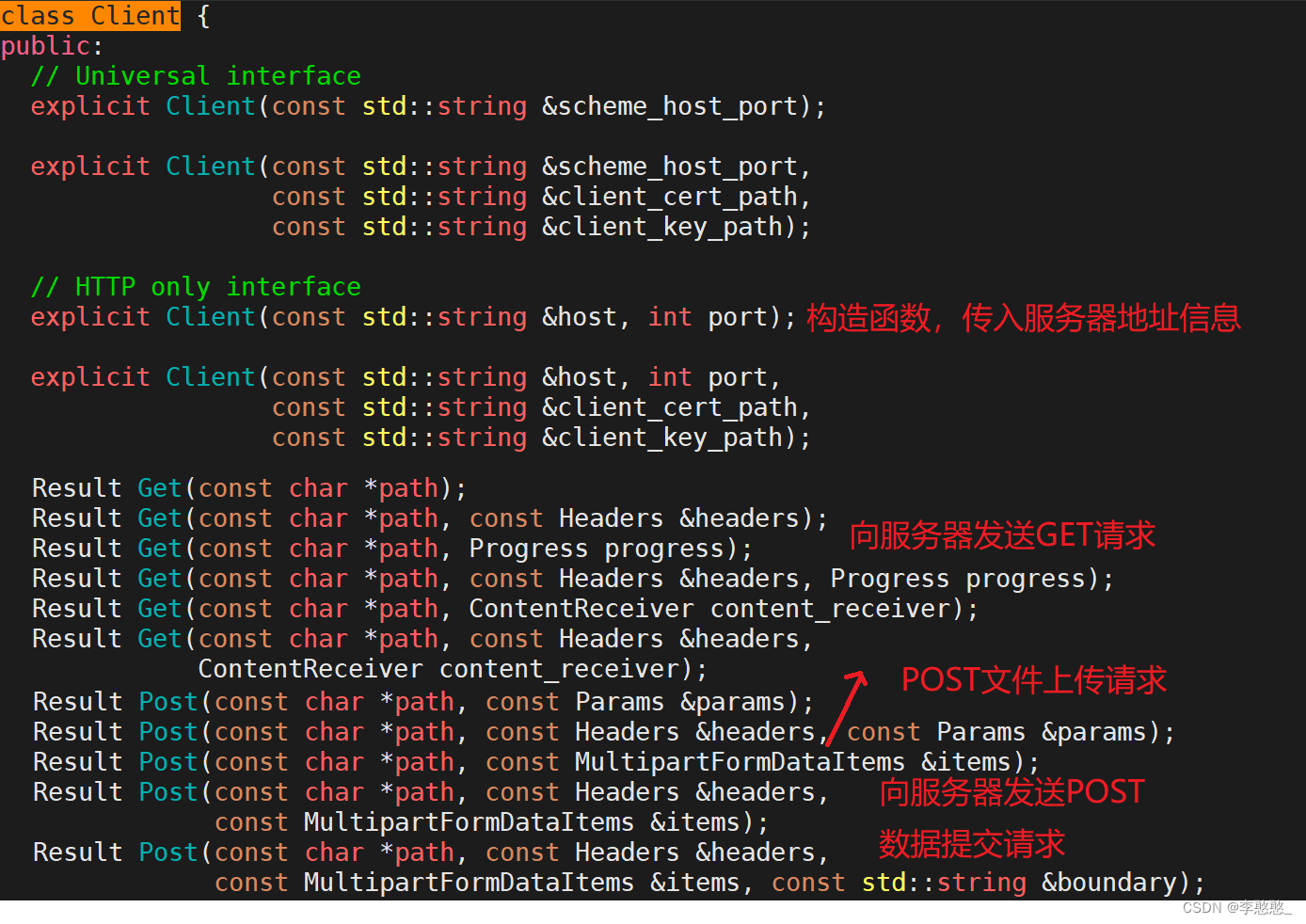
#include "httplib.h"
using namespace std;
int main()
{
httplib::Client client("192.168.19.xxx", 9090);
//Result Get(const char *path, const Headers &headers);
httplib::Headers header = {
{
"connection", "close"}
};
//Response *res
auto res = client.Get("/numbers/5678", header);
if (res && res->status == 200) {
cout << res->body << endl;
}
//Result Post(const char *path, const MultiparFormDataItems &items);
httplib::MultipartFormDataItems items;
httplib::MultipartFormData item;
item.name = "file";
item.filename = "hi.txt";
item.content = "hello nihao";
item.content_type = "application/octet-stream";
items.push_back(item);
res = client.Post("/upload", items);
return 0;
}

Project implementation
Cloud backup server implementation
Network communication module : adopt httplib build http The client and server realize network communication
Business processing module : Handle client requests ( Upload , download , Display interface )
Data management module : Unified data management
Hotspot management module : Find out the non hot files in the backup file , Compressed storage
If a file is a non hotspot file , We will compress storage , But whether compressed or not , When others get the display interface , We all need to give the uploaded file information , And when the client wants to download files , You can also find the corresponding compressed package , After decompression , Return source file data ( It cannot be a compressed package )
Data management module
Data management module : Unified data management
What data should be managed : original file name , Original file size , Original file time attribute , Corresponding package name , Compress logo
Uploaded files , Finally, you should be able to view and download on the browser , On the browser interface, we need to be able to show the files that the client has backed up : original file name , file size , File backup time
And a non hot file , If compressed , The obtained size is the size of the compressed package , Time is the time of the compressed package , However, the page should show the attributes of the original file , Instead of the properties of the compressed package
Once a file is compressed , The compressed package will be stored in the compressed package path , The original file will be deleted
A compressed package is decompressed , You should put the unzipped file in the backup path , The compressed package should be deleted
The data information to be managed has been determined , The question is how to manage ?
Data management is divided into two parts :
One part is data management in memory : More efficient query —undered_mep(hash)
One part is persistent disk storage management : Prevent data loss due to power failure — File store (json serialize & Deserialization )— You can also use a database to store
Data is stored in memory for query efficiency ; Put it on disk for safety ;
Don't rush to complete the data management module :
The first is to complete some tool interfaces
File operation tool class :
File operations : Get the attributes of the file ( Time , size ,……), File write data , Read data from file
Directory operation : Create directory , Traverse the directory ( Get all the file information in the directory )
JSON Operation tool class :
Realization Json serialize &Json Deserialization
The third tool class : File compression and decompression ( Applied in the hotspot management module )
In essence, it is the operation of files , So simplify the operation , Put the function implementation directly into the file tool class
File operation tool class
util.hpp
#ifndef __MY_UTIL__
#define __MY_UTIL__
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <time.h>
#include <sys/stat.h>
#include <experimental/filesystem>
namespace fs = std::experimental::filesystem;
using namespace std;
namespace cloud{
class FileUtil{
private:
string _name;
public:
FileUtil(const string &name): _name(name){
}
// Does the file exist
bool Exists() {
return fs::exists(_name);
}
// Get file size
size_t Size() {
if (this->Exists() == false) {
return 0;
}
return fs::file_size(_name);
}
// Last modification time
time_t MTime() {
if (this->Exists() == false) {
return 0;
}
auto ftime = fs::last_write_time(_name);
time_t cftime = decltype(ftime)::clock::to_time_t(ftime);
return cftime;
}
// Last visit time
time_t ATime() {
if (this->Exists() == false) {
return 0;
}
struct stat st;
stat(_name.c_str(), &st);
return st.st_atime;
}
// Read all data from the file to body in
bool Read(string *body) {
if (this->Exists() == false) {
return false;
}
ifstream ifs;
ifs.open(_name, ios::binary);// Open the file in binary mode
if (ifs.is_open() == false) {
cout << "open failed!\n";
return false;
}
size_t fsize = this->Size();
body->resize(fsize);
ifs.read(&(*body)[0], fsize);//string::c_str() Return value const char*
if (ifs.good() == false) {
cout << "read file failed!\n";
ifs.close();
return false;
}
ifs.close();
return true;
}
// take body The data in is written to a file
bool Writer(const string &body) {
ofstream ofs;
ofs.open(_name, ios::binary);// Open the file in binary mode
if (ofs.is_open() == false) {
cout << "open failed!\n";
return false;
}
ofs.write(body.c_str(), body.size());
if (ofs.good() == false) {
cout << "read file failed!\n";
ofs.close();
return false;
}
ofs.close();
return true;
}
// Create directory
bool CreateDirectory() {
if (this->Exists()) {
return true;
}
fs::create_directories(_name);
return true;
}
// Traverse the directory , Get the pathnames of all files in the directory
bool ScanDirectory(vector<string> *array) {
if (this->Exists() == false) {
return false;
}
// Currently, the directory iterator can only traverse directories with a depth of one layer by default
for(auto &a : fs::directory_iterator(_name)) {
if(fs::is_directory(a) == true) {
continue;// If the current file is a folder , Do not deal with , Traverse to the next
}
// Currently, our directory is traversing , Only get ordinary file information , Do not do in-depth processing for directories
//string pathname = fs::path(a).filename().string();// Pure file name
string pathname = fs::path(a).relative_path().string();// File name with path
array->push_back(pathname);
}
}
};
}
#endif
cloud.cpp
#include "util.hpp"
void FileUtilTest()
{
//cloud::FileUtil("./testdir/adir").CreateDirectory();
//cloud::FileUtil("./testdir/a.txt").Writer("hello bit\n");
//string body;
//cloud::FileUtil("./testdir/a.txt").Read(&body);
//cout << body << endl;
//cout << cloud::FileUtil("./testdir/a.txt").Size() << endl;
//cout << cloud::FileUtil("./testdir/a.txt").MTime() << endl;
//cout << cloud::FileUtil("./testdir/a.txt").ATime() << endl;
vector<string> array;
cloud::FileUtil("./testdir").ScanDirectory(&array);
for(auto& a : array) {
cout << a << endl;
}
}
create a file , Write data to file , Include file size , Modification time , There is no problem with the access time 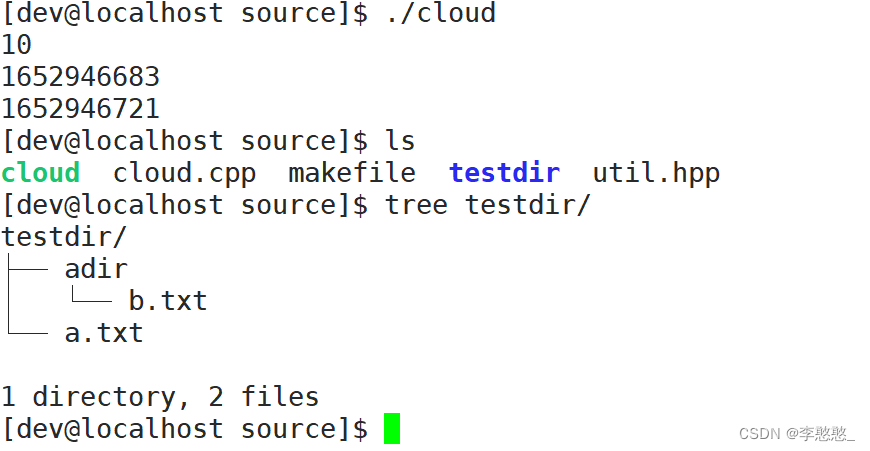
Json Operation tool class
class JsonUtil{
public:
// serialize
static bool Serialize(Json::Value &val, string *body) {
Json::StreamWriterBuilder swb;
Json::StreamWriter *sw = swb.newStreamWriter(); //new One StreamWriter object
stringstream ss;
int ret = sw->write(val, &ss);// Implement serialization
if (ret != 0) {
cout << "seriallize failed!\n";
delete sw;
return false;
}
*body = ss.str();
delete sw;
return true;
}
// Deserialization
static bool UnSerialize(string &body, Json::Value *val) {
Json::CharReaderBuilder crb;
Json::CharReader *cr = crb.newCharReader();
string err;
//pars( String first address , Address at the end of the string ,Json::Value Object pointer , Error information acquisition )
bool ret = cr->parse(body.c_str(), body.c_str() + body.size(), val, &err);
if (ret == false) {
cout << "UnSerialize failed:" << err << endl;
delete cr;
return false;
}
delete cr;
return true;
}
};
void JsonTest()
{
Json::Value val;
val[" full name "] = " Xiao Ming ";
val[" Gender "] = " male ";
val[" Age "] = 18;
val[" achievement "].append(77.5);
val[" achievement "].append(78.5);
val[" achievement "].append(79.5);
string body;
cloud::JsonUtil::Serialize(val, &body);
cout << body << endl;
Json::Value root;
cloud::JsonUtil::UnSerialize(body, &root);
cout << root[" full name "].asString() << endl;
cout << root[" Gender "].asString() << endl;
cout << root[" Age "].asInt() << endl;
cout << root[" achievement "][0].asFloat() << endl;
cout << root[" achievement "][1].asFloat() << endl;
cout << root[" achievement "][2].asFloat() << endl;
}
Serialization and deserialization are no problem 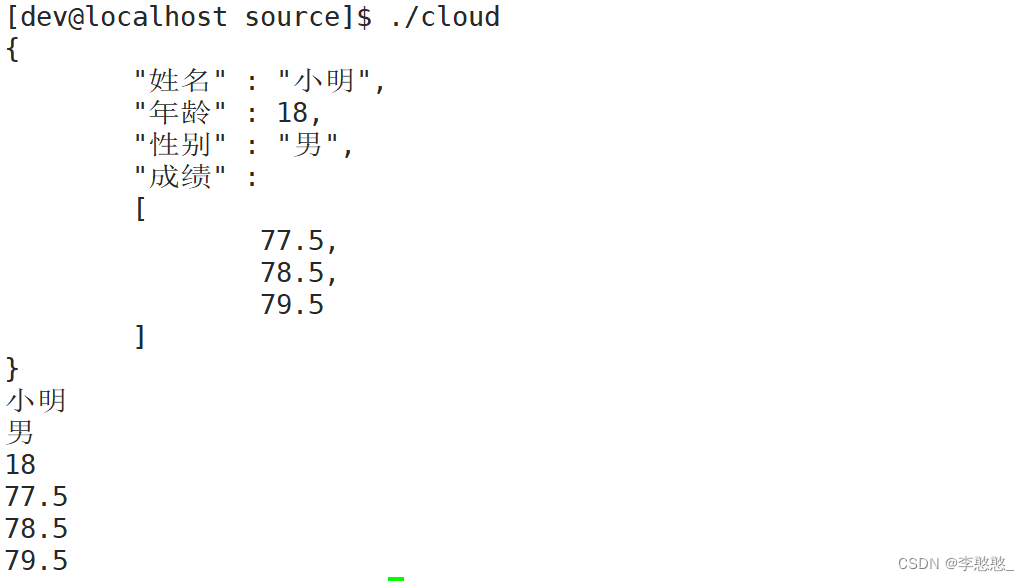
File compression and decompression
// File compression
bool Compress(const string &packname) {
if (this->Exists() == false) {
return false;
}
string body;
if (this->Read(&body) == false) {
cout << "Compress read failed!\n";
}
string packed = bundle::pack(bundle::LZIP, body);
if (FileUtil(packname).Writer(packed) == false) {
cout << "Compress write pack data failed!\n";
return false;
}
fs::remove_all(_name);// Delete the original file after compression
return true;
}
// Extract the file
bool UnCompress(const string &filename) {
if (this->Exists() == false) {
return false;
}
string body;
if (this->Read(&body) == false) {
cout << "UnCompress read pack data failed!\n";
}
string unpack_data = bundle::unpack(body);
if (FileUtil(filename).Writer(unpack_data) == false) {
cout << "UnCompress write file data failed!\n";
return false;
}
fs::remove_all(_name);// Delete the compressed package after decompression
return true;
}
void CompressTest()
{
cloud::FileUtil("./hello.txt").Compress("hello.zip");
cloud::FileUtil("./hello.zip").UnCompress("bit.txt");
}
Implementation of data management module :
thought :
1. The file information is saved through the structure
2. Multiple file information , adopt hash Table organization management
3. Persistent storage , Complete by file , File storage format Json Serialization format
Data manipulation
Data addition, deletion, modification and query :
increase : Enter a file name , Get various information in the interface , Generate the compressed package name , Fill structure , Push the hash surface
Change : When the file is compressed and stored , To modify the compression flag , After downloading and decompressing, you should also modify the compression flag
check : Query all backup information ( The front-end display interface needs - file name , Download link , size , Backup time ), Query single file information ( File download - Get file timing backup path )
Delete : Basic backup files are not deleted ( Defense function expansion )
Header file and structure
#ifndef __MY_DATA__
#define __MY_DATA__
#include "util.hpp"
#include <iostream>
#include <unordered_map>
#include <jsoncpp/json/json.h>
using namespace std;
namespace cloud {
typedef struct _FileInfo {
string filename; // file name
string url_path; // Download link path
string real_path; // Actual storage path
size_t file_size; // file size
time_t back_time; // Backup time
bool pack_flag; // Compress logo
string pack_path; // Compressed package pathname
}FileInfo;
Data management class :
Private data members
class DataManager {
private:
string _back_dir = "./backup_dir/";// The actual storage path of the backup file
string _pack_dir = "./pack_dir/";// Compressed package storage path
string _download_prefix = "/download/";// Download the prefix path of the link
string _pack_subfix = ".zip";// Package suffix
string _back_info_file = "./backup.dat";// A file that stores backup information
// use url As key, Because when downloading the file , It will be sent url
unordered_map<string, FileInfo> _back_info;//<url, fileinfo> Backup information
Constructors
public:
DataManager() {
FileUtil(_back_dir).CreateDirectory();
FileUtil(_pack_dir).CreateDirectory();
if (FileUtil(_back_info_file).Exists()) {
InitLoad();
}
}
data storage
bool Storage() {
Json::Value infos;
vector<FileInfo> arry;
this->SelectAll(&arry);
for (auto& a : arry) {
Json::Value info;
info["filename"] = a.filename;
info["url_path"] = a.url_path;
info["real_path"] = a.real_path;
info["file_size"] = (Json::UInt64)a.file_size;
info["back_time"] = (Json::UInt64)a.back_time;
info["pack_flag"] = a.pack_flag;
info["pack_path"] = a.pack_path;
infos.append(info);
}
string body;
JsonUtil::Serialize(infos, &body);
FileUtil(_back_info_file).Writer(body);
return true;
}
When the module runs , Read out the historical information and store it in hash In the table
// When the module runs , Read out the historical information and store it in hash In the table
bool InitLoad() {
//1. Read the historical backup information in the file
string body;
bool ret = FileUtil(_back_info_file).Read(&body);
if (ret == false) {
cout << "load history failed!\n";
return false;
}
//2. Deserialize the read information
Json::Value infos;
ret = JsonUtil::UnSerialize(body, &infos);
if (ret == false) {
cout << "initload parse history falied!\n";
return false;
}
//3. Store the data obtained by deserialization into hash In the table
int sz = infos.size();
for (int i = 0; i < sz; ++i) {
FileInfo info;
info.filename = infos[i]["filename"].asString();
info.url_path = infos[i]["url_path"].asString();
info.real_path = infos[i]["real_path"].asString();
info.file_size = infos[i]["file_size"].asInt64();
info.back_time = infos[i]["back_time"].asInt64();
info.pack_flag = infos[i]["pack_flag"].asBool();
info.pack_path = infos[i]["pack_path"].asString();
_back_info[info.url_path] = info;
}
return true;
}
Data addition, deletion, modification and query
increase : Enter a file name , Get various information in the interface , Generate the compressed package name , Fill structure , Push the hash surface
bool Insert(const string& pathname) {
if (cloud::FileUtil(pathname).Exists() == false) {
cout << "insert file is not exists!\n";
return false;
}
// pathname = ./backup_dir/a.txt
FileInfo info;
info.filename = cloud::FileUtil(pathname).Name();//a.txt
info.url_path = _download_prefix + info.filename;// /download/a.txt Download the linked resource path
info.real_path = pathname; // Actual storage path ./backup_dir/a.txt
info.file_size = cloud::FileUtil(pathname).Size(); // file size
info.back_time = cloud::FileUtil(pathname).MTime();// The last modification time is the backup time
info.pack_flag = false;// The files just uploaded are in uncompressed state
info.pack_path = _pack_dir + info.filename + _pack_subfix;// Compressed package pathname /.pack_dir/a.txt.zip
_back_info[info.url_path] = info;// With url_path by key,info by value Add to map in ;
Storage();
return true;
}
Change : When the file is compressed and stored , To modify the compression flag , After downloading and decompressing, you should also modify the compression flag
bool UpdateStatus(const string& pathname, bool status) {
string url_path = _download_prefix + FileUtil(pathname).Name();
auto it = _back_info.find(url_path);
if (it == _back_info.end()) {
cout << "file info is not exists!\n";
return false;
}
it->second.pack_flag = status;
return true;
}
check : Query all backup information ( The front-end display interface needs - file name , Download link , size , Backup time ),
Query single file information ( File download - Get file timing backup path )
bool SelectAll(vector<FileInfo>* infos) {
for (auto it = _back_info.begin(); it != _back_info.end(); ++it) {
infos->push_back(it->second);
}
return true;
}
bool SelectOne(const string& url_path, FileInfo* info) {
auto it = _back_info.find(url_path);
if (it == _back_info.end()) {
cout << "file info is not exists!\n";
return false;
}
*info = it->second;
return true;
}
Delete : Basic backup files are not deleted ( Defense function expansion )
bool DeleteOne(const string& url_path) {
auto it = _back_info.find(url_path);
if (it == _back_info.end()) {
cout << "file info is not exists!\n";
return false;
}
_back_info.erase(it);
Storage();
return true;
}
Hotspot management module
Compress and store non hotspot files , Save server disk space .
function : For the files in the backup directory , To test , Check the last access time of each file , Judge whether the time from the current system has exceeded the hot spot judgment time (30 Seconds no access ), If it exceeds, it means that this is a non hot file , Compressed storage is required , Delete the original file after compression , After successful compression , Manage objects through data , Modify backup information – The status is compressed .
Realization :
1. Traverse the specified directory - File backup directory - Original file storage path , Get the actual pathnames of all files in the directory
2. Traverse all file names , By file pathname , Get the time attribute of the file ( Last visit time )
3. Get the current time of the system , Subtract from the last access time of the file , Compare the difference with the specified length of hot spot judgment time
4. If it exceeds the hot spot judgment time , It is determined as non hot spot , Compressed storage
5. After compression , Modify backup information
#ifndef __MY_HOT__
#define __MY_HOT__
#include "data.hpp"
#include <unistd.h>
extern cloud::DataManager* _data;// Global data
using namespace std;
namespace cloud {
class HotManager {
private:
time_t _hot_time = 30; // Hot spot judgment duration , It should be a configurable item , Current simplification , Default to 30s
string _backup_dir = "./back_dir/"; // The storage path of the original file to be detected
public:
HotManager() {
FileUtil(_backup_dir).CreateDirectory();
}
bool IsHot(const string& filename) {
time_t atime = FileUtil(filename).ATime();
time_t ctime = time(NULL);
if ((ctime - atime) > _hot_time) {
return false;
}
return true;
}
bool RunModule() {
while (1) {
//1. Traverse the directory
vector<string> arry;
FileUtil(_backup_dir).ScanDirectory(&arry);
//2. Traversal information
for (auto& file : arry) {
//3. Get the specified file time attribute , Based on the current system time , Make hot spot judgment
if (IsHot(file) == true) {
continue;// Hot files will not be processed for the time being
}
// Get the historical information of the current file
FileInfo info;
bool ret = _data->SelectOneByRealpath(file, &info);
if (ret == false) {
// Currently detected files , No historical backup information , This may be an abnormal uploaded file , Delete processing
cout << "An exception file is deleted. Delete it!\n";
FileUtil(file).Remove();
continue;// After the exception file is deleted , Deal with the next
// For files without historical information detected , Then add information , Then compress and store
//_data->Insert(file);
//_data->SelectOneByRealpath(file, &info);
}
//4. Non hotspot compressed storage
FileUtil(file).Compress(info.pack_path);
//5. After compression, modify the backup information
info.pack_flag = true;
_data->UpdateStatus(file, true);
}
usleep(1000);// Avoid empty directories , Empty traversal consumption CPU Excessive resources
}
return true;
}
};
}
#endif
Network communication module & Business processing module
The network communication module uses httplib Library building http The server , We pay more attention to business processing .
Business processing : Upload processing , View the processing of page requests , Download processing
#ifndef __MY_SERVER__
#define __MY_SERVER__
#include "data.hpp"
#include "httplib.h"
#include <sstream>
using namespace std;
extern cloud::DataManager* _data;
namespace cloud {
class Server {
private:
int _srv_port = 9090;// The binding listening port of the server
string _url_prefix = "/download/";
string _backup_dir = "./backup_dir/";// Backup storage path of uploaded files
httplib::Server _srv;
private:
static void Upload(const httplib::Request& req, httplib::Response& rsp) {
string _backup_dir = "./backup_dir/";// Backup storage path of uploaded files
// Judge whether there is data in the file upload area corresponding to the identification
if (req.has_file("file") == false) {
// Judge whether there is name The field value is file Marked area
cout << "Upload file data format error!\n";
rsp.status = 400;
return;
}
// Get the parsed area data
httplib::MultipartFormData data = req.get_file_value("file");
//cout << data.filename << endl;// If it is a file upload, save the file name
//cout << data.content << endl;// Area body data , If it is file upload, it is file content data
// The actual storage path name of the organization file
string realpath = _backup_dir + data.filename;
// Write data to file , It's actually backing up the files
if (FileUtil(realpath).Writer(data.content) == false) {
cout << "back file failed!\n";
rsp.status = 500;
return;
}
// Add backup information
if (_data->Insert(realpath) == false) {
cout << "insert back info failed!\n";
rsp.status = 500;
return;
}
rsp.status = 200;
return;
}
static string StrTime(time_t t) {
return asctime(localtime(&t));
}
static void List(const httplib::Request& req, httplib::Response& rsp) {
// Get all historical backup information , And according to this information, organize a html page , As a response body
vector<FileInfo> arry;
if (_data->SelectAll(&arry) == false) {
cout << "select all back info failed!\n";
rsp.status = 500;
return;
}
stringstream ss;
ss << "<html>";
ss << "<head>";
ss << "<meta http-equiv='Content-Type' content='text/html;charset=utf-8'>";
ss << "<title>Download</title>";
ss << "</head>";
ss << "<body>";
ss << "<h1>Download</h1>";
ss << "<table>";
for (auto& a : arry) {
// Organize page tags for each row
ss << "<tr>";
//<td><a href="/download/test.txt">test.txt</a></td>
ss << "<td><a href='" << a.url_path << "'>" << a.filename << "</a></td>";
//<td align="right"> 2021-12-29 10:10:10 </td>
ss << "<td align='right'>" << StrTime(a.back_time) << "</td>";
ss << "<td align='right'>" << a.file_size / 1024 << " KB </td>";
ss << "</tr>";
}
ss << "</table>";
ss << "</body>";
ss << "</html>";
rsp.set_content(ss.str(), "text/html");
rsp.status = 200;
return;
}
static string StrETag(const string& filename) {
//etag Is the unique identification of a file , When the file is modified, it will change
// here etag No content calculation : file size - File last modified
time_t mtime = FileUtil(filename).MTime();
size_t fsize = FileUtil(filename).Size();
stringstream ss;
ss << fsize << "-" << mtime;
return ss.str();
}
static void Download(const httplib::Request& req, httplib::Response& rsp) {
FileInfo info;
if (_data->SelectOne(req.path, &info) == false) {
cout << "select one back info failed!\n";
rsp.status = 404;
return;
}
// If the file has been compressed , Decompress first , Then go to the original file to read the data
if (info.pack_flag == true) {
FileUtil(info.pack_path).UnCompress(info.real_path);
}
if (req.has_header("If-Range")) {
//using Range = std::pair<ssize_t, ssize_t>;
//using Ranges = std::vector<Range>;
string old_etag = req.get_header_value("If-Range");
string cur_etag = StrETag(info.real_path);
if (old_etag == cur_etag) {
// If the file has not been changed, it can be continued at a breakpoint
// If we handle it ourselves and parse the string to get the start and end positions
//size_t start = req.Ranges[0].first;// however httplib It has been parsed for us
//size_t end = req.Ranges[0].second;// without end Numbers , At the end of the file
//httplib Will second Set to -1, At this time, from the file start Position start reading end-start+1 length , If end yes -1, be > It's the length of the file -start length
// Because of the assumption 1000 The length of the file , request 900-999, Returns a message containing 900 and 999 In total 100 Length data
// And if you ask 900-,1000 The end of the length is actually 999, Direct length minus 900 That's all right.
//
//httplib Has completed the function of breakpoint continuation for us , We just need to put all the data of the file into body in ,
// Then set the response status code 206,httplib The detected response status code is 206, It will start from body Intercept the data of the specified interval in Respond to
FileUtil(info.real_path).Read(&rsp.body);
rsp.set_header("Content-Type", "application/octet-stream");// Set the body type to binary stream
rsp.set_header("Accept-Ranges", "bytes");// Tell the client that I support breakpoint resuming
//rsp.set_header("Content-Range", "bytes start-end/fsize");//httplib It's automatically set
rsp.set_header("ETag", cur_etag);
rsp.status = 206;
return;
}
}
FileUtil(info.real_path).Read(&rsp.body);
rsp.set_header("Content-Type", "application/octet-stream");// Set the body type to binary stream
rsp.set_header("Accept-Ranges", "bytes");// Tell the client that I support breakpoint resuming
rsp.set_header("ETag", StrETag(info.real_path));
rsp.status = 200;
return;
}
public:
Server() {
FileUtil(_backup_dir).CreateDirectory();
}
bool RunModule() {
// build http The server
// Build request - Handle function mapping
//Post( The requested resource path , Corresponding business processing callback function );
_srv.Post("/upload", Upload);
_srv.Get("/list", List);// This is a request to show the page
string regex_download_path = _url_prefix + "(.*)";
_srv.Get(regex_download_path, Download);
// Start the server
_srv.listen("0.0.0.0", _srv_port);
return true;
}
};
}
#endif
Breakpoint continuation
When downloading a file , Download halfway , Because of the Internet or other reasons , Cause download interruption , If you download all the file data again after the second time , It's less efficient , Because in fact, the previously transmitted data does not need to be retransmitted , If this download is just a re download from the last disconnected location , Download efficiency can be improved
Realization thought : One end must be able to record the position of its transmission , That is, where you downloaded it , But in fact, the server record is inappropriate , Because all requests are initiated by the client , Therefore, it should be recorded by the client , In fact, who needs data , Just who records .
During client download , Record the length and location of your downloaded data , If the download is interrupted , At the next request , Send the interval range of the specified file you need to the server , The server can return data according to the specified range .
But there is a problem : How to ensure the next downloaded file , It is consistent with the current file to be renewed ??? That is, if the sequel , The file data on the server has changed , Then the sequel is meaningless !!! So there must be a sign , It is used to identify whether the file on the server has been modified after a download . If it has not been modified, you can continue transmission at breakpoint , If it is modified, it cannot be continued at breakpoint , Need to download again
So breakpoint continuation , Need to be associated with the last download , Need the support of the last download information , For example, the unique identification of the file .
Whether a server supports breakpoint retransmission , You should tell the client from the first download
Client implementation
Environmental Science :Windows10/vs2017 above
Because our file manipulation tool class uses C++17 File system libraries in , and C++17 In low version VS Insufficient support in
function : Detect the files in the specified folder on the client host , Which file needs to be backed up , Then upload it to the server for backup
thought :
1. Directory search : Traverse the specified folder , Get all file path names
2. Get the properties of all files : Judge whether this file needs to be backed up according to the attribute information
Conditions for file backup :1. New files ;2. Recently modified files after the last upload ;
Record the backup information of the file every time : Backup file pathname & The unique identification of the document , When the file is modified, it will change , If the historical backup information cannot be found according to the file path name , It means that this file is newly added , Need backup , If historical backup information is found , But the unique ID is different from the current ID , It means that it has been modified after uploading , Need backup ;
There is a situation : A file may be currently under continuous modification , It will cause that every retrieval needs to be backed up , The actual processing — Judge that a file is not currently occupied by other processes , To determine whether backup is needed , Simple handling — Judge whether a file needs to be backed up if the specified time interval has not been modified
3. If a file needs to be backed up , Create http client , Upload files
4. After uploading the file , Add the historical backup information of the current file .
Module partition :
1. Data management module : Manage the historical backup record information of the client
2. Directory retrieval module : Get all files in the specified folder
3. Network communication module : Upload the files to be backed up to the server for backup
#pragma once
#include "data.hpp"
#include "httplib.h"
namespace cloud {
class Client {
private:
string _backup_dir = "./backup_dir";
DataManager* _data = NULL;
string _srv_ip;
int _srv_port;
private:
string FileEtag(const string& pathname) {
size_t fsize = FileUtil(pathname).Size();
time_t mtime = FileUtil(pathname).MTime();
stringstream ss;
ss << fsize << "-" << mtime;
return ss.str();
}
bool IsNeedBackup(const string& filename) {
// Need backup :1. No historical information ;2. There is historical information , But it has been modified ( Whether the identification is consistent )
string old_etag;
if (_data->SelectOne(filename, &old_etag) == false) {
return true;// No historical backup information
}
string new_etag = FileEtag(filename);
time_t mtime = FileUtil(filename).MTime();
time_t ctime = time(NULL);
// Prevent files from being continuously modified , So judge the last modification time , Whether the interval with the current time exceeds 3 second
if (new_etag != old_etag && (ctime - mtime) > 3) {
return true;// The current logo is different from the historical logo , It means that the file has been modified
}
return false;
}
bool Upload(const string& filename) {
httplib::Client client(_srv_ip, _srv_port);
httplib::MultipartFormDataItems items;
httplib::MultipartFormData item;
item.name = "file";// Area name identification
item.filename = FileUtil(filename).Name();// file name
FileUtil(filename).Read(&item.content); // File data
item.content_type = "application/octet-stream";// File data format --- Binary stream
items.push_back(item);
auto res = client.Post("/upload", items);
if (res && res->status != 200) {
return false;
}
return true;
}
public:
Client(const string srv_ip, int srv_port) :_srv_ip(srv_ip), _srv_port(srv_port) {
}
bool RunModule() {
//1. initialization : Initialize the data management object , Create a monitoring Directory
FileUtil(_backup_dir).MCreateDirectory();
_data = new DataManager();
while (1) {
//2. Create directory , Get all the files in the directory
vector<string> arry;
FileUtil(_backup_dir).ScanDirectory(&arry);
//3. Judge according to the historical backup information , Whether the current file needs to be backed up
for (auto& a : arry) {
if (IsNeedBackup(a) == false) {
continue;
}
cout << a << "need backup!\n";
//4. Back up files if necessary
bool ret = Upload(a);
//5. Add backup information
_data->Insert(a);
cout << a << "backup success!\n";
}
Sleep(10);
}
}
};
}
边栏推荐
- Chinese and English instructions prosci LAG-3 recombinant protein
- Bindingexception exception (error reporting) processing
- 虚拟机的作用
- Kuboard无法发送邮件和钉钉告警问题解决
- 多线程与高并发(9)——AQS其他同步组件(Semaphore、ReentrantReadWriteLock、Exchanger)
- "Xiaodeng in operation and maintenance" meets the compliance requirements of gdpr
- MySQL service is missing from computer service
- mips uclibc 交叉编译ffmpeg,支持 G711A 编解码
- Modify the jupyter notebook file path
- Hidden Markov model (HMM) learning notes
猜你喜欢

jdbc数据库连接池使用问题
Basic process of network transmission using tcp/ip four layer model
Abnova membrane protein lipoprotein technology and category display
Precise space-time travel flow regulation system - ultra-high precision positioning system based on UWB
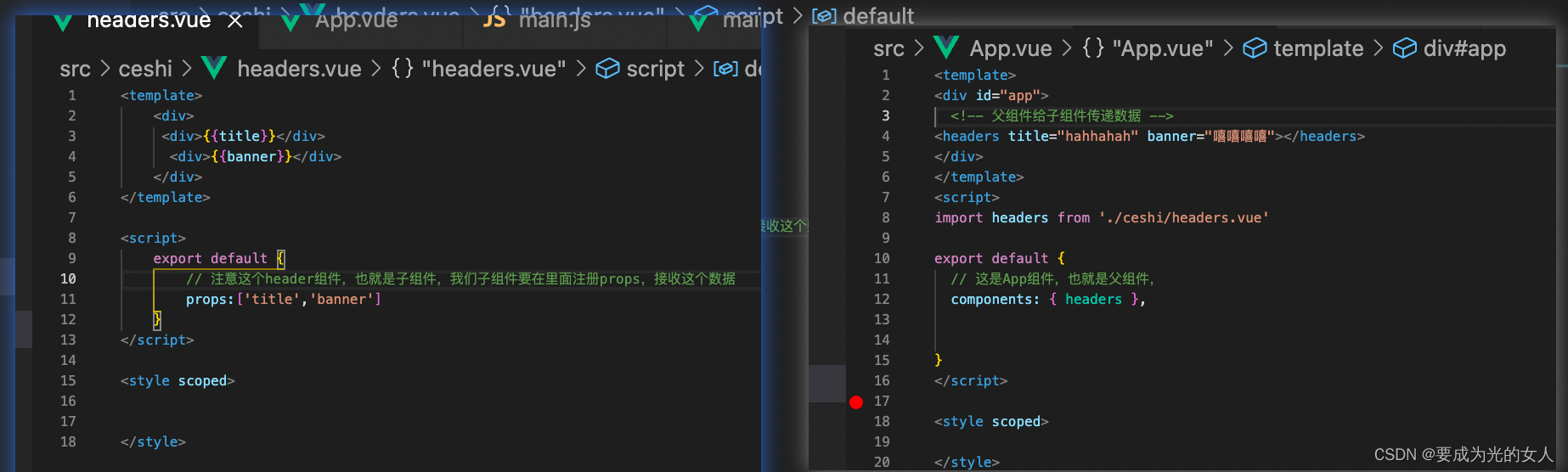
父组件传递给子组件:Props
Fast quantitative, abbkine protein quantitative kit BCA method is coming!

Sword finger offer high quality code
云备份项目
Maze games based on JS
关于数据库数据转移的问题,求各位解答下
随机推荐
Prime partner of Huawei machine test questions
How can brand e-commerce grow against the trend? See the future here!
弹性布局(二)
JDBC database connection pool usage problem
main函数在import语句中的特殊行为
异步组件和Suspense(真实开发中)
toRefs API 与 toRef Api
关于数据库数据转移的问题,求各位解答下
Torefs API and toref API
Non empty verification of collection in SQL
Complete process of MySQL SQL
Software acceptance test
OOM(内存溢出)造成原因及解决方案
MOS tube parameters μ A method of Cox
[noi simulation] regional division (conclusion, structure)
Multidisciplinary integration
Mysql---- import and export & View & Index & execution plan
请教一下,监听pgsql ,怎样可以监听多个schema和table
計算機服務中缺失MySQL服務
oracle如何备份索引