当前位置:网站首页>ICLR 2022 | pre training language model based on anti self attention mechanism
ICLR 2022 | pre training language model based on anti self attention mechanism
2022-07-07 12:46:00 【PaperWeekly】

author | Zeng Weihao
Company | Beijing University of Posts and telecommunications
Research direction | Conversation summary generation

Title of thesis :
Adversarial Self-Attention For Language Understanding
Source of the paper :
ICLR 2022
Thesis link :
https://arxiv.org/pdf/2206.12608.pdf

Introduction
This paper proposes Adversarial Self-Attention Mechanism (ASA), Use confrontation training to reconstruct Transformer The attention of , Make the model trained in the polluted model structure .
Try to solve the problem :
There is a great deal of evidence that , Self attention can be drawn from allowing bias Benefit from ,allowing bias A certain degree of transcendence ( Such as masking, Smoothing of distribution ) Add to the original attention structure . These prior knowledge can enable the model to learn useful knowledge from smaller corpus . But these prior knowledge are generally task specific knowledge , It makes it difficult to extend the model to rich tasks .
adversarial training The robustness of the model is improved by adding disturbances to the input content . The author found that only input embedding Adding disturbances is difficult confuse To attention maps. The attention of the model does not change before and after the disturbance .
In order to solve the above problems , The author puts forward ASA, It has the following advantages :
Maximize empirical training risk, Learn by automating the process of building prior knowledge biased(or adversarial) Structure .
adversial Structure is learned from input data , bring ASA It is different from the traditional confrontation training or the variant of self attention .
Use gradient inversion layer to convert model and adversary Combine as a whole .
ASA Nature is interpretable .

Preliminary
Represents the characteristics of the input , In the traditional confrontation training , Usually token Sequence or token Of embedding, Express ground truth. For the A parameterized model , The prediction result of the model can be expressed as .
2.1 Adversarial training
The purpose of confrontation training is to improve the robustness of the model by pushing the distance between the disturbed model prediction and the target distribution :
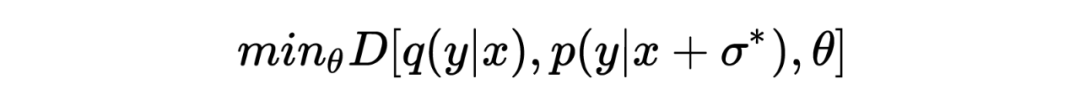
among Represents the process of resisting disturbance Model prediction after disturbance , Represent the target distribution of the model .
Against disturbance By maximizing empirical training risk get :
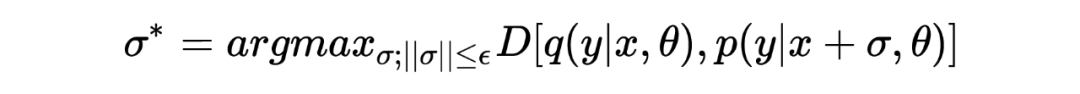
among It's right Constraints made , Hope that in In small cases, it will cause large disturbance to the model . The above two representations show the process of confrontation .
2.2 General Self-Attention
The expression defining self attention is :
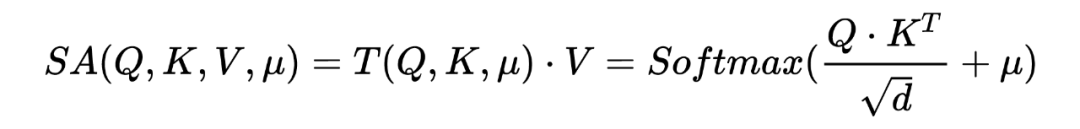
In the most common self attention mechanism Represents congruent matrix , In previous studies , It represents a certain degree of prior knowledge used to smooth the output distribution of attention structure .
In this article, the author will Defined as element Of binary matrix .

Adversarial Self-Attention Mechanism
3.1 Optimization
ASA The purpose of is to cover up the most vulnerable attention unit in the model . These most vulnerable units depend on the input of the model , Therefore, confrontation can be expressed as input learned “meta-knowledge”:,ASA Attention can be expressed as :
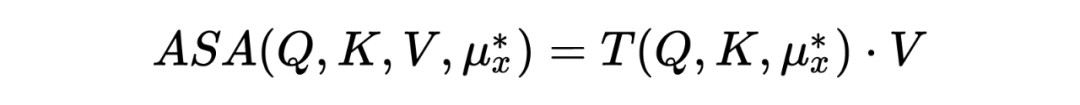
Similar to confrontation training , The model is used to minimize the following divergence:
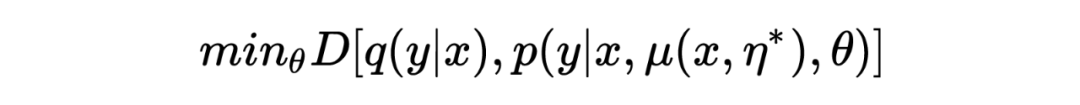
By maximizing empirical risk It is estimated that :
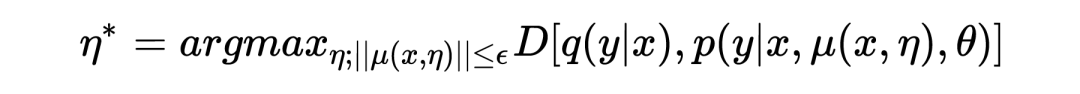
among It means The decision boundary of , To prevent ASA Damage model training .
in consideration of With attention mask There is a form of , Therefore, it is more suitable to use constraints masked units To constrain . Because it is difficult to measure .
The specific value of , So it will hard constraint Into a punishment unconstraint:
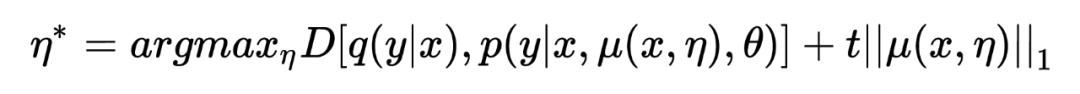
among t Used to control the degree of confrontation .
3.2 Implementation
The author puts forward ASA Simple and fast implementation of .
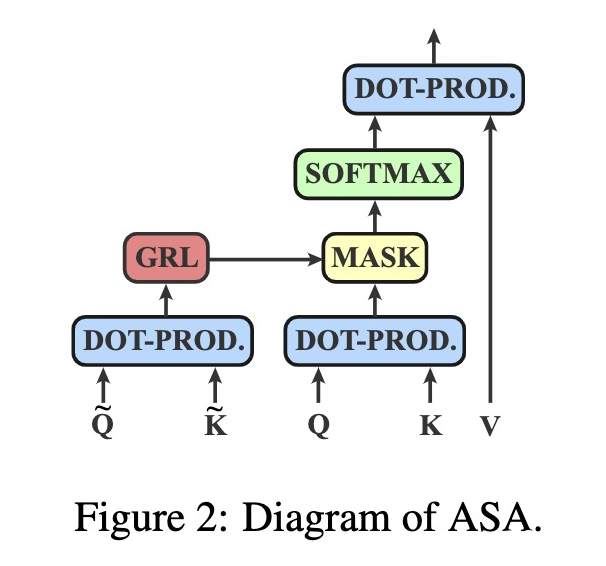
For the first From the attention level , Can be obtained from the input hidden layer state . To be specific , Use linear layers to transform the hidden layer state into as well as , Obtain matrix by dot multiplication , Then the matrix is transformed by the re parameterization technique binary turn .
Because confrontation training usually includes inner maximization as well as outer minimization Two goals , So at least twice backward The process . So in order to speed up training , The author adopts Gradient Reversal Layer(GRL) Merge the two processes .
3.3 Training
The training objectives are as follows :
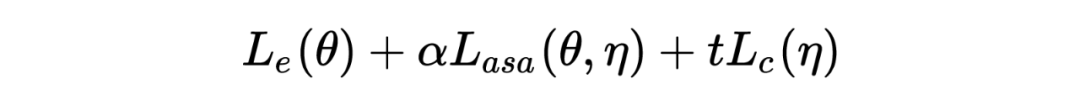
Express task- specific Loss , Express plus ASA Losses after confrontation , Means for Constraints .

Experiments
4.1 Result
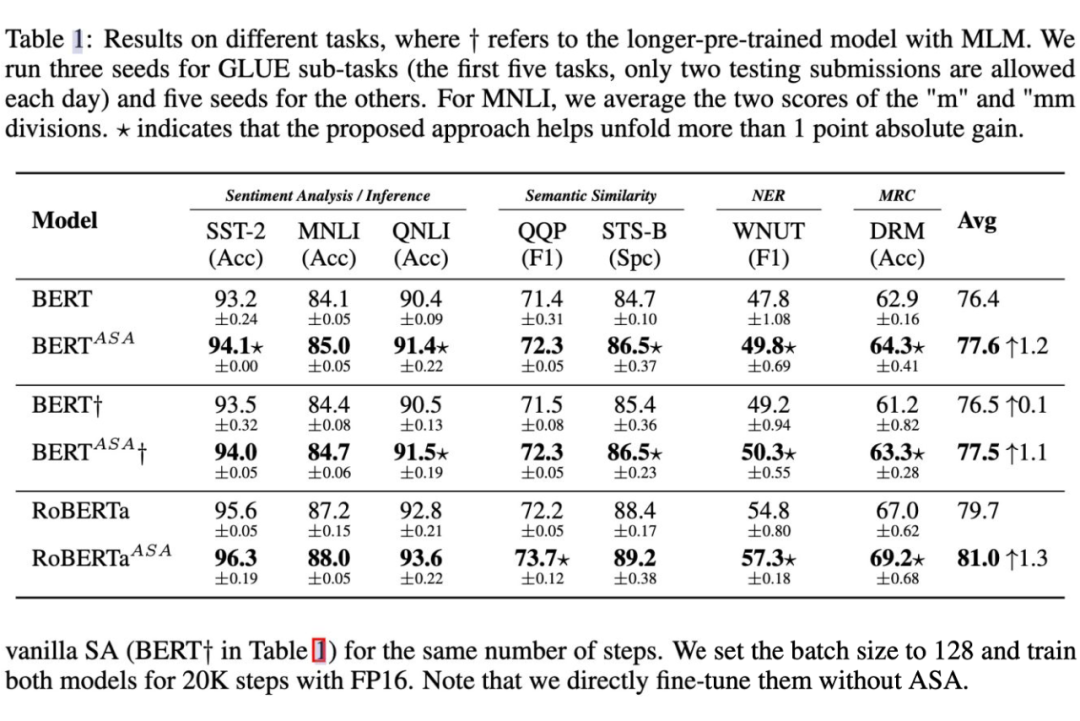
As can be seen from the table above , In terms of fine tuning ,ASA The supported model always exceeds the original BERT and RoBERTa. You can see ,ASA In small data sets, for example STS-B,DREAM Excellent performance ( It is generally believed that these small data sets are easier to over fit ) At the same time, on a larger data set, such as MNLI,QNLI as well as QQP There is still a good improvement in , Illustrates the ASA It can not only improve the generalization ability of the model, but also improve the language expression ability of the model .
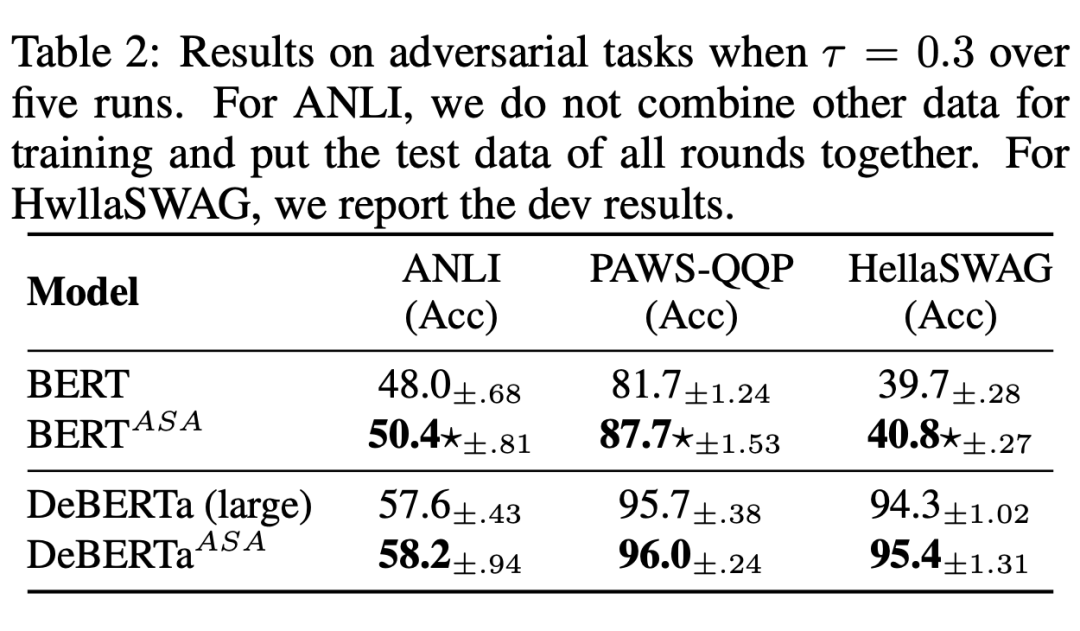
As shown in the following table ,ASA It plays a great role in improving the robustness of the model .
4.2 Analytical experiment
1. VS. Naive smoothing
take ASA Compare with other attention smoothing methods .

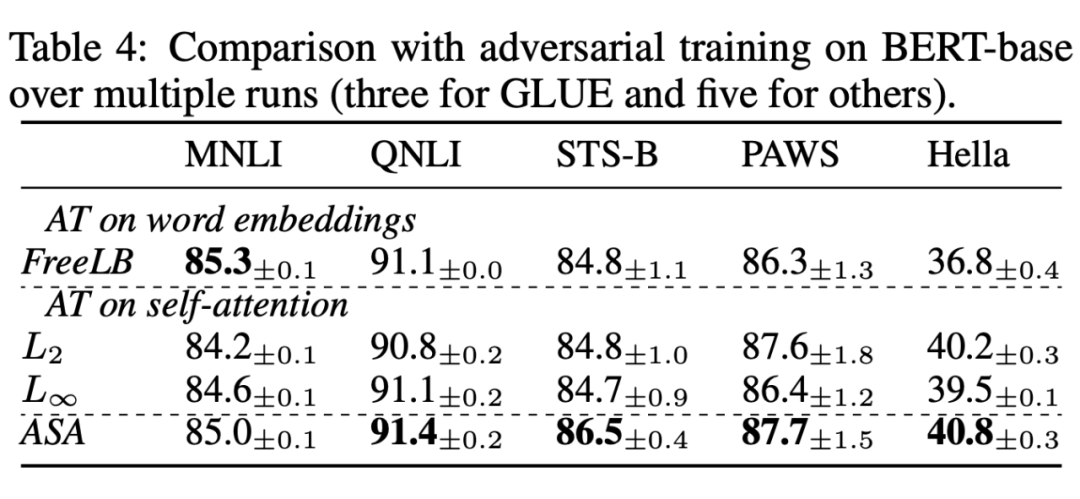
2. VS. Adversial training
take ASA Compare with other confrontation training methods
4.3 Visualization
1. Why ASA improves generalization
Confrontation can reduce the attention of keywords and let non keywords receive more attention .ASA Prevents lazy prediction of the model , But urge it to learn from contaminated clues , Thus, the generalization ability is improved .

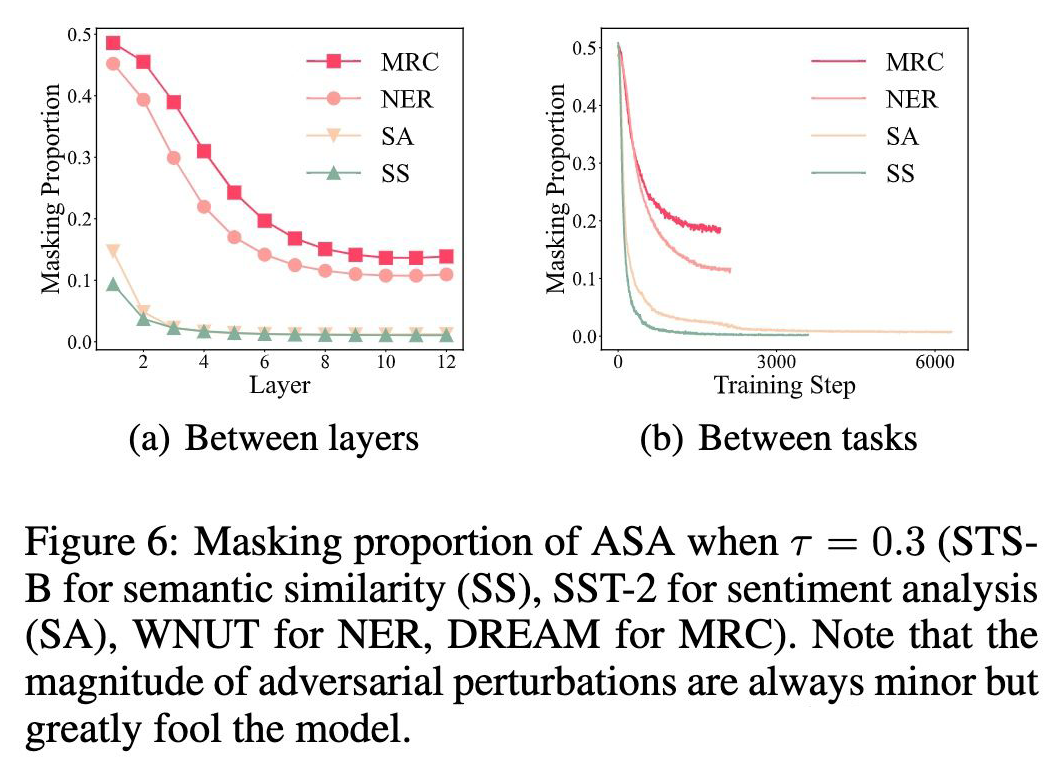
2. Bottom layers are more vulnerable
You can see masking The proportion gradually decreases with the number of floors from the bottom to the top , Higher masking The proportion means that the vulnerability of the layer is higher .

Conclusion
This paper proposes Adversarial Self-Attention mechanism(ASA) To improve the generalization and robustness of the pre training language model . A large number of experiments show that the proposed method can improve the robustness of the model in the pre training and fine-tuning stages .
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
猜你喜欢
SQL head injection -- injection principle and essence
2022A特种设备相关管理(锅炉压力容器压力管道)模拟考试题库模拟考试平台操作

Learning and using vscode

Static comprehensive experiment
SQL Lab (36~40) includes stack injection, MySQL_ real_ escape_ The difference between string and addslashes (continuous update after)
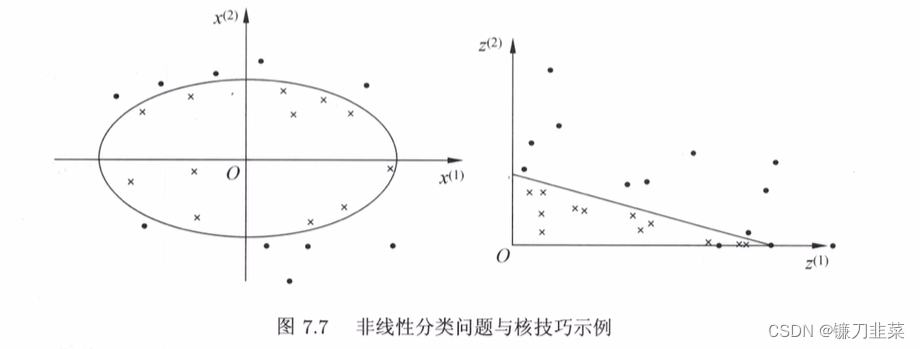
【统计学习方法】学习笔记——支持向量机(下)

Inverted index of ES underlying principle
Ctfhub -web SSRF summary (excluding fastcgi and redI) super detailed
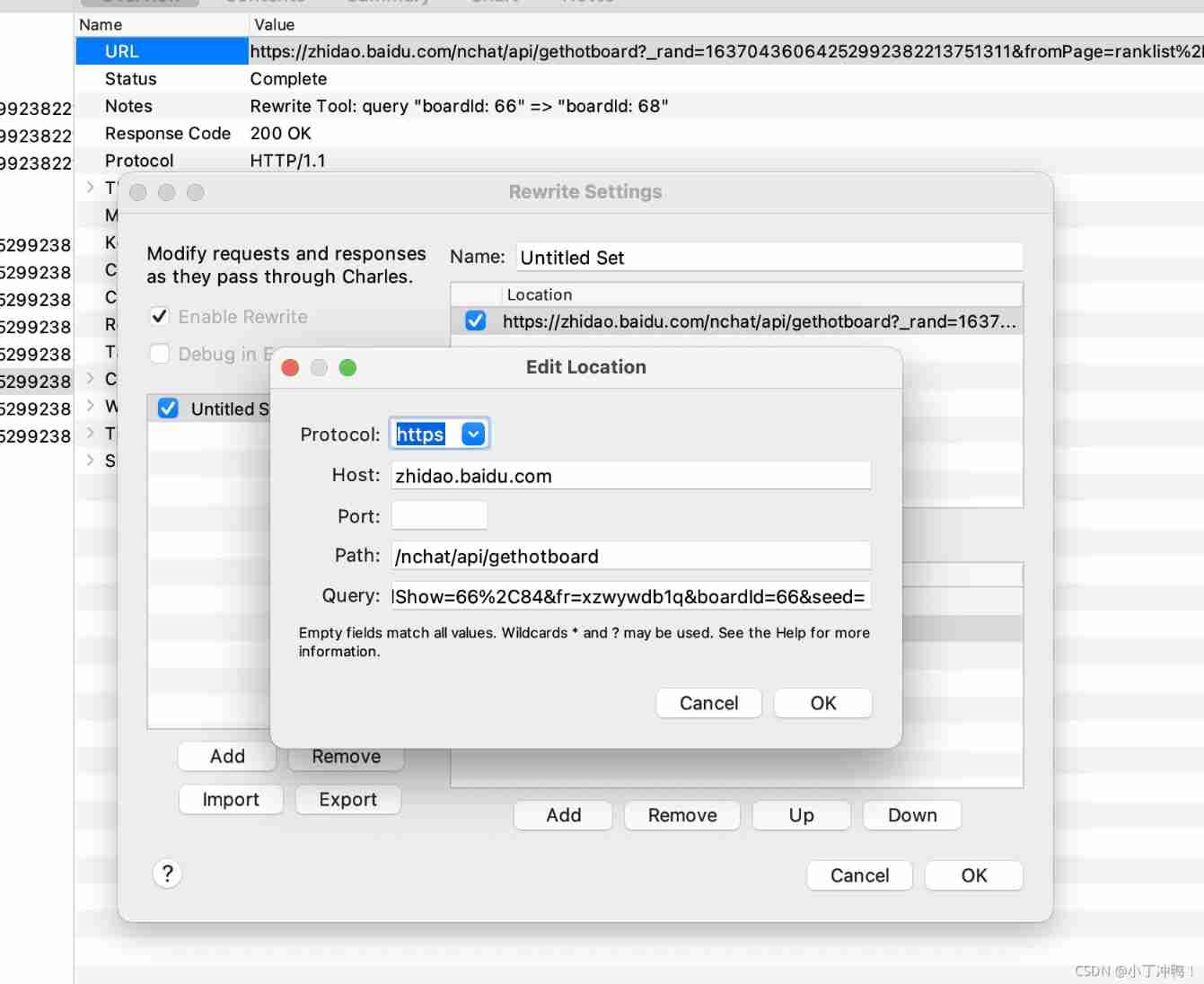
Charles: four ways to modify the input parameters or return results of the interface
Experiment with a web server that configures its own content
随机推荐
Importance of database security
对话PPIO联合创始人王闻宇:整合边缘算力资源,开拓更多音视频服务场景
GCC compilation error
Dialogue with Wang Wenyu, co-founder of ppio: integrate edge computing resources and explore more audio and video service scenarios
Common knowledge of one-dimensional array and two-dimensional array
Several methods of checking JS to judge empty objects
(to be deleted later) yyds, paid academic resources, please keep a low profile!
Typescript interface inheritance
Charles: four ways to modify the input parameters or return results of the interface
Epp+dis learning road (2) -- blink! twinkle!
[爬虫]使用selenium时,躲避脚本检测
leetcode刷题:二叉树26(二叉搜索树中的插入操作)
RHSA first day operation
Day-18 hash table, generic
Configure an encrypted web server
mysql怎么创建,删除,查看索引?
2022广东省安全员A证第三批(主要负责人)考试练习题及模拟考试
About IPSec
PHP调用纯真IP数据库返回具体地址
Day-17 connection set