当前位置:网站首页>机器学习植物叶片识别
机器学习植物叶片识别
2022-07-06 06:29:00 【啥也不会(sybh)】
植物叶片的识别:给出叶片的数据集”叶子形状.csv”,描述植物叶片的边缘、形状、纹理这三个特征的数值型变量各有64个(共64*3=192个变量)。此外,还有1个记录每片叶片所属植物物种的分类型变量,共193个变量。请采用特征选择方法进行特征选择,并比较各特征选择结果的异同(20分)。通过数据建模,完成叶片形状的识别(30分)。
目录
目录
2画出相关性矩阵(需要根据相关性矩阵,选择特征进行特征工程)
思路
1.数据分析 可视化
2.建立特征工程(需要根据相关性矩阵,选择特征进行特征工程。包括对数据进行预处理,补充缺失值,归一化数据等)
3.机器学习算法模型去验证分析
1导入包
import pandas as pd
from sklearn import svm
import numpy as np
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
2画出相关性矩阵(需要根据相关性矩阵,选择特征进行特征工程)
Train= pd.read_csv("叶子形状.csv")
X = Train.drop(['species'], axis=1)
Y = Train['species'] 
Train['species'].replace(map_dic.keys(), map_dic.values(), inplace=True)
Train.drop(['id'], inplace = True, axis = 1)
Train_ture = Train['species']
#画出相关性矩阵
corr = Train.corr()
f, ax = plt.subplots(figsize=(25, 25))
cmap = sns.diverging_palette(220, 10, as_cmap=True)
sns.heatmap(corr, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5)
plt.show()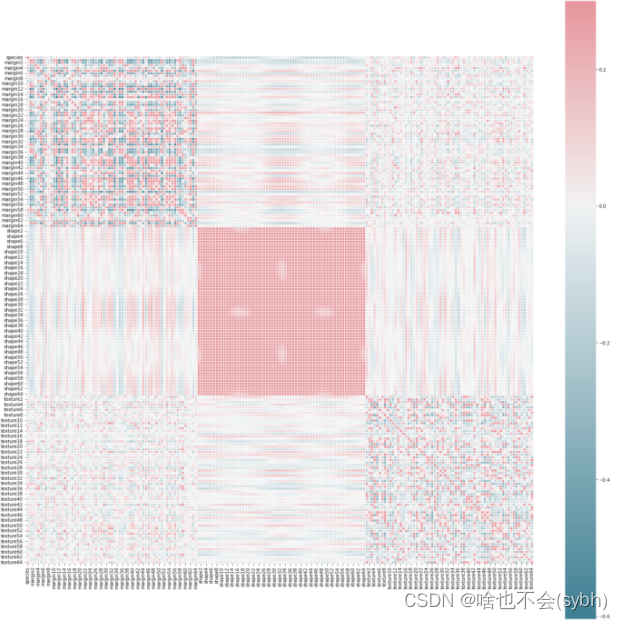
补充缺失值
np.all(np.any(pd.isnull(Train)))
#false
训练集测试集划分(80%训练集、20%测试集)
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=123)
对数据归一化处理
standerScaler = StandardScaler()
x_train = standerScaler.fit_transform(x_train)
x_test = standerScaler.fit_transform(x_test)
3进行PCA降维
pca = PCA(n_components=0.9)
x_train_1 = pca.fit_transform(x_train)
x_test_1 = pca.transform(x_test)
## 44个特征
4 KNN网格搜索优化 ,PCA前后
from sklearn.neighbors import KNeighborsClassifier
knn_clf0 = KNeighborsClassifier()
knn_clf0.fit(x_train, y_train)
print('KNeighborsClassifier')
y_predict = knn_clf0.predict(x_test)
score = accuracy_score(y_test, y_predict)
print("Accuracy: {:.4%}".format(score))
print("PCA后")
knn_clf1 = KNeighborsClassifier()
knn_clf1.fit(x_train_1, y_train)
print('KNeighborsClassifier')
y_predict = knn_clf1.predict(x_test_1)
score = accuracy_score(y_test, y_predict)
print("Accuracy: {:.4%}".format(score))
5 SVC
svc_clf = SVC(probability=True)
svc_clf.fit(x_train, y_train)
print("*"*30)
print('SVC')
y_predict = svc_clf.predict(x_test)
score = accuracy_score(y_test, y_predict)
print("Accuracy: {:.4%}".format(score))
svc_clf1 = SVC(probability=True)
svc_clf1.fit(x_train_1, y_train)
print("*"*30)
print('SVC')
y_predict1 = svc_clf1.predict(x_test_1)
score = accuracy_score(y_test, y_predict1)
print("Accuracy: {:.4%}".format(score))

6.逻辑回归
from sklearn.linear_model import LogisticRegressionCV
lr = LogisticRegressionCV(multi_class="ovr",
fit_intercept=True,
Cs=np.logspace(-2,2,20),
cv=2,
penalty="l2",
solver="lbfgs",
tol=0.01)
lr.fit(x_train,y_train)
print('逻辑回归')
y_predict = lr.predict(x_test)
score = accuracy_score(y_test, y_predict)
print("Accuracy: {:.4%}".format(score))
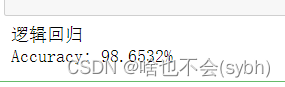
逻辑回归准确率最高98.65
经过特征选择和主成分分析不一定会提高准确率
边栏推荐
- 英语论文翻译成中文字数变化
- SQL Server manager studio(SSMS)安装教程
- Convert the array selected by El tree into an array object
- Technology sharing | common interface protocol analysis
- SSO流程分析
- 今日夏至 Today‘s summer solstice
- The pit encountered by keil over the years
- CS通过(CDN+证书)powershell上线详细版
- Is the test cycle compressed? Teach you 9 ways to deal with it
- 如何将flv文件转为mp4文件?一个简单的解决办法
猜你喜欢
基于JEECG-BOOT的list页面的地址栏参数传递

LeetCode 729. My schedule I

Cobalt Strike特征修改

Financial German translation, a professional translation company in Beijing
Classification des verbes reconstruits grammaticalement - - English Rabbit Learning notes (2)

Past and present lives of QR code and sorting out six test points
org.activiti.bpmn.exceptions.XMLException: cvc-complex-type.2.4.a: 发现了以元素 ‘outgoing‘ 开头的无效内容
(practice C language every day) reverse linked list II

mysql按照首字母排序
Summary of leetcode's dynamic programming 4
随机推荐
Today's summer solstice
Esp32 esp-idf watchdog twdt
钓鱼&文件名反转&office远程模板
LeetCode每日一题(971. Flip Binary Tree To Match Preorder Traversal)
Error getting a new connection Cause: org. apache. commons. dbcp. SQLNestedException
SSO流程分析
PHP uses redis to implement distributed locks
Biomedical localization translation services
Phishing & filename inversion & Office remote template
Summary of leetcode's dynamic programming 4
LeetCode 732. My schedule III
如何做好金融文献翻译?
LeetCode 729. My schedule I
My seven years with NLP
端午节快乐Wish Dragon Boat Festival is happy
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Set the print page style by modifying style
In English translation of papers, how to do a good translation?
Cobalt strike feature modification
Lecture 8: 1602 LCD (Guo Tianxiang)