当前位置:网站首页>Lecture 4 of Data Engineering Series: sample engineering of data centric AI
Lecture 4 of Data Engineering Series: sample engineering of data centric AI
2022-07-06 02:13:00 【Amazon cloud developer】

Preface
We introduced it to you through three lectures Data-centric AI Characteristic engineering of , It mainly includes Continuous features and category Characteristics of characteristics , The detailed steps of feature engineering are feature preprocessing , Feature generation , Feature selection and feature dimensionality reduction , Let us have more and deeper understanding of Feature Engineering . Next, we introduce the sample engineering closely related to feature Engineering , What is discussed here is the sample project for structured data .
From the many I participated in ML Project view , The sample project can involve people of different roles ( For example, the project leader , Business operators , Algorithm engineer , Machine learning Product Manager , Machine learning technology consulting experts , Solution architects, etc ), So as to form an all-round brainstorming , More transparent machine learning modeling .
Sample engineering will involve combing the modeling ideas , Unlike Feature Engineering, it also has some typical methodologies , It's more artistic , It's more like a thought trip , It is a process that requires repeated brain walking , Let's experience it slowly later .
More detailed data-centric AI For relevant contents, please refer to this github repo.(https://github.com/yuhuiaws/ML-study/tree/main/Data-centric%20AI)
Outline of this article
One 、 What is sample Engineering
Two 、 The abstraction and definition of the target task
3、 ... and 、 Representation of samples
Four 、 Construction of sample set
5、 ... and 、 give an example : User churn prediction task
What is sample Engineering
Let's first look at what is a sample , Simply put, it means multiple independent variables and one or more dependent variables / A representation of the target variables , Or feature represents set + mark /label It is considered as a sample . The above refers to the training with supervision signals ( Supervision signal refers to marking ) The sample of , The sample at the time of prediction does not need a dependent variable / mark , For unsupervised tasks, there is no need for dependent variables in training and prediction / mark .
The sample project does not see any formal definition , Here my rough definition is as follows , Sample engineering is the whole engineering process of modeling a certain target task or multiple related targets to prepare the sample set . And I think the three elements of the sample project are , The abstraction and definition of the target task , Representation of samples and construction of sample sets , Next we discuss each element .
The abstraction and definition of the target task
Machine learning modeling can be simply regarded as the process of transforming a business problem into a mathematical problem . In many cases , This process is not so obvious and direct , Therefore, it is very important to express exactly and unambiguously what the goal and task we want to achieve at present , It may be more effective to express this goal task with examples .
In actual projects , The process of abstracting and defining the target task may not be achieved overnight , It may be an iterative process , I summarize the experience of the project as follows : First of all, at the beginning of the project, at least 1-2 Face to face brainstorming , This brainstorming is best for people with various roles ( At least algorithm engineers are needed , Machine learning technology consulting experts , Business operations ) Join in , Preliminarily determine the objectives and tasks ; Then do it at each node below review.
review node | Introduce | remarks |
Raw data review | All available original tables or logs at present , The purpose is to discuss the extraction of original features / Generate . | It needs to be discussed in depth field by field , And mining some possible candidate features according to the current understanding of the target task . |
The first version of the feature set after data cleaning is the original feature review | The purpose is to select the model according to the currently available features , For example, there are still too few features that can be directly used and generated by other methods , It may not be appropriate to use a deep learning model , Even machine learning is not appropriate ( For example, when there are few available features , Calculate the aggregated eigenvectors for fee paying and non fee paying people , It may be better to predict whether new users pay based on vector similarity ). | You may need to reset your goals and tasks : Or split the target task into multiple subtasks , At present, first implement one of the subtasks ; Or turn the target task into a similar task , Or at this time, we can figure out what the target task really wants to do . |
The first version after modeling review | Analyze according to the actual prediction effect , Look at the current model / Whether the algorithm meets the expectation . If it doesn't meet expectations , May need to be in the sample / features , Model / Rethink algorithm selection or goal task setting . | Regression tasks may be more difficult to fit than classification tasks , Consider whether the regression task can be transformed into a classification task to approximately meet the target task . |
For target tasks with supervisory signals , We need to judge the annotation /label How to determine the ( This thing is not as simple as expected ), That is to say, there needs to be a reasonable logic to annotate . Here are two examples to illustrate :
_ | Introduce |
Recommended by e-commerce CTR Click through rate estimation sorting task | It's not an object item If it is clicked, it will be marked as 1, Understand that we essentially want to model whether the user is right item Interested rather than clicking . For example, click a item( Maybe it was clicked by mistake ) And quickly closed this item Details page , This situation may be marked 0 instead of 1; For example, click a item But take this item Joined the blacklist or click ” Step on ” 了 , At this time, it needs to be marked as 0. |
Recommended video CTR Click through rate estimation sorting task | hit label when , We need to consider whether long video and short video are modeled separately . If modeling separately , How to determine the dividing line between long video and short video ; If unified modeling , How to treat long videos and short videos fairly , It may be more reasonable to use playback ratio and playback duration as conditions or ( hear Netflix The threshold used in the playback duration judgment logic is 10 minute ) |
Representation of samples
After the preliminary determination of the target task , We need to think about how to represent a sample . Representation of samples and samples id Two different things. , sample id For alignment and tracking , The representation of samples refers to the connotation display of samples . The representation of samples can be seen from many perspectives :
_ | Introduce | give an example |
features species | For the current target task , In depth analysis of the large categories of features that can be covered . | For the task of predicting stock prices , The category has stock side characteristics , Contextual features , Cross features ; For fraud detection tasks , The category has user side features , Business side features , Contextual features , Cross features . |
Is there a “ people ” Such a subject | If the target task is ” people ” As the main body , There will be interaction between people and things , Such characteristics are strong characteristics , Don't miss it. . in addition , In the “ people ” As the main task , It is necessary to consider whether each person has one sample or multiple samples , So as to have a rational grasp of the overall size of the sample . | Smart Location ( Predict that a certain geographical area is suitable for the establishment of schools , Such tasks as hospitals or hotels ) The task of , One geographical range, one sample . Recommended tasks for game equipment , One user has multiple samples . The task of fraud detection , If you want to judge whether a user is a fraud user according to some recent behaviors of a user , One user, one sample ; If you want to determine whether a user's behavior is fraudulent , Then a user will have multiple samples . |
Whether the sample is constructed based on timestamp | There are two kinds of samples based on timestamp organization : One is the sample of time series prediction task ; One is to add timestamp and subject as samples . | The task of predicting clothing sales , Target variables can be organized according to the frequency of days , Independent variables related to the target variable ( Including dynamic ), It is also organized according to the same frequency . Predict the total revenue that new users may bring in the next three months on each advertising day , Each timestamp + Every advertisement ID To organize a sample . |
The purpose of the fields in the sample | Some fields in the sample are used for model learning ; Some fields are not used for model learning ( For example, the sample used for alignment mentioned above id). | Intelligent assignment , Every jobid Only once , You don't need to model it as a feature . If you use LightGBM If the model runs the sorting task , that usrid and itemid Such fields can be considered not to be modeled as features , Or right usrid and itemid Did embedding Send it later LightGBM; But if you use the depth model to run the same task ,usrid and itemid It is best to model as a feature . |
Construction of sample set
1. Segmentation of sample set
As long as there is a supervisory signal , Whether it's modeling with supervised learning or not , Can be divided into training set and verification set ( For example, sometimes we turn supervised learning tasks into unsupervised learning tasks , At this time, the verification set is segmented because supervised signals are easier to evaluate for unsupervised learning ).
The segmentation criterion of training set and verification set is , The sample size of each set should be sufficient , If it is a classification task, it is also necessary to ensure that the number of small category samples in the training set and verification set is sufficient .
Common segmentation methods of training set and verification set : Divide according to the time window , Training set before , Validation set after ; Divide randomly in proportion , If it's a classification task , It is best to divide randomly according to the classification ( The purpose of hierarchical segmentation according to categories is to make the training set and verification set have the same category sample proportion as the original data set ).
2. Sampling of samples
Whether it is necessary to sample some samples from the collected sample set , You need to consider : If it is because the data set is too large and the single machine training time is too long, do sampling , Then it is suggested to give priority to using distributed training to accelerate rather than sampling ; If it is to alleviate the imbalance of sample categories , You can try to sample large categories of samples to see the effect of the model ; If you want to sample , It is for training set to do sampling , Do not sample the validation set ( Because we need to try to make the validation set consistent with the online data distribution ); The data distribution of the training set changes after sampling , If it is a simple sort, such as in the recommendation system CTR Estimate sorting tasks , It only cares about relative order , This relative order will not be changed before and after sampling , If it is similar to bidding advertising CTR Estimate sorting tasks , It USES ECPM Sorting formula , It needs to pay attention to click probability pctr The absolute value of ( Because it needs to use pctr multiply bidding Price and dynamic ranking factor ), So before and after sampling pctr The absolute value of may vary , So calibration is needed in this case .
Sample large categories , In addition to random sampling , You can also consider sampling according to the time window , There are two ways : Do the same amount of sampling according to the fixed sampling rate every day or increase the sampling according to the weight of time ( When determining the overall sampling proportion , Calculate the amount to be sampled according to the total negative sample size , Then calculate the sampling specific gravity every day . The condition to be satisfied is , The closer we are to the present , The larger the sampling proportion ).
give an example : User churn prediction task
Determine whether a user has lost 2 Ideas : The first way of thinking , Set a time anchor ( such as 5 month 10 Number ), As long as the user's last key behavior ( Like login behavior ) The length of the timestamp from the time anchor is greater than or equal to a set fixed length of time ( such as 7 God ), It is considered that the user is lost ; The second way of thinking , Set an observation period time window ( For instance from 5 month 1 The day is coming 5 month 7 Japanese Communist Party 7 God ), Only care about whether users have key behaviors in the observation period time window ( Like login behavior ), If not, the user will be lost ( The second idea may be used more , Therefore, our discussion below is based on the second idea ).
The goal here is to predict whether the old users of a game will be lost , Sorting out this goal and task , At least we need to consider the following questions : How to define a lost user , After the model is trained, how to use the model to predict the loss of users , Time window selection of dataset , How to segment training set and verification set , Training iteration of user churn prediction model .
1. How to define a lost user
First explain the loss cycle , It defines the minimum time interval when a user does not have some key behavior ( In other words, the lost time of users is greater than or equal to the loss cycle ). The classic definition of loss is “ Users who have not performed key behaviors for more than a period of time ”, The key point is how to define this time interval ( Namely, the loss cycle ) And key behaviors ( Namely, loss behavior ). Different business scenarios , This key behavior will generally be different .
For the loss of users in the game scene , You can choose “ Effective login ” This behavior is the key behavior of whether to lose . Here we need to consider how to determine whether a user is logged in effectively : If you log out immediately after logging in, you may not be counted as an effective login ; Or switch this application to the background immediately after logging in to hang up , This should not be regarded as an effective login . in other words , The user should be logged in , And put the application on the front desk , And stay long enough ( such as 10 minute ) Just think it's a “ Effective login ”.
The definition of the loss cycle , There are two common ways :
Quantile definition : have access to 90% Quantile method to select the loss cycle , That is, according to the user's recent two consecutive key behaviors ( For example, login. ) The time interval is sorted from small to large ,90% The time interval corresponding to the quantile is regarded as the loss period .
Inflection point definition ( Maybe this method should be preferred )
Refer to the following :
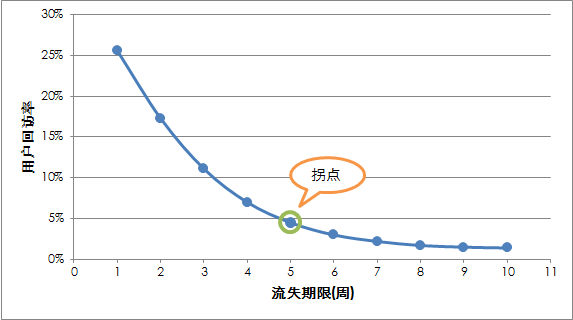
The calculation of the return visit rate of users corresponding to each loss cycle requires the calculation of the number of lost users and the number of return visits ( User follow-up rate = Number of follow-up users ÷ The number of lost users × 100%), The specific calculation process is as follows : The calculation of lost users is relatively direct , Set the start and end positions of the observation period window according to the loss cycle , Users who do not log in in the window are considered lost ( Here, for the convenience of comparing different loss cycles , The starting position of the observation period window is set to the same , Different loss cycles get different end positions ).
How to calculate the number of follow-up users , I understand that we should first define a relatively long cycle , For the example here , Because the maximum loss period of data points in the abscissa is 10 Zhou , Here, set the user reflow cycle to 10 Zhou , The loss cycle is 1 Weeks and is judged as lost users if in the follow-up 10 As long as there is a valid login within a week, it is considered as a reflow user ; Empathy , The loss cycle is 10 Zhou and determined that the lost users are in the follow-up 10 As long as there is a valid login within a week, it is considered as a reflow user ( Here I assume that a consistent reflux cycle is used for different loss cycles , Whether this setting is reasonable and how long the reflux cycle is , It is best to confirm with the business operation personnel ).
If the curve has no inflection point , You can also pat your head according to product experience , Return visit rate of general products 5%-10%( By fixing the return visit rate, find the corresponding loss cycle in the curve ), No matter how long the time cycle is divided, there will be a return visit as a loss cycle , Errors are inevitable .
2. After training the model ,
How to use this model to predict the loss of users
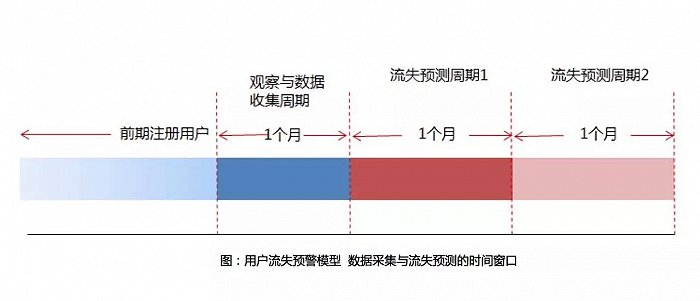
As shown in the figure above , The loss cycle set here is 1 Months , Then push forward one month at the time when we are ready to start training. This time window is used to observe what we are interested in “ Old users ” Whether there is effective login behavior within this time window , If any , Indicates that the user is a retained user , If not, it means that the user has more than 1 There has been no effective login behavior for months , Mark as lost users .
After the model training, it can immediately predict those users who have key behaviors in the observation window , It is predicted that they will extrapolate from the end of training to the future for a period of time to see whether they have key behaviors . This extrapolation period is the loss prediction cycle , The loss prediction cycle should be set to be consistent with the loss cycle , Because we should try to ensure that the prediction is consistent with the training ( in other words , Play during training label The length of the given observation period window, that is, the loss period, needs to be as long as the extrapolation period given in the prediction ).
As you can see in the above figure : At the beginning of the first churn prediction cycle window, it predicts whether those users who have key behaviors in the observation period window have key behaviors in the first churn prediction time window ; The beginning of the second churn prediction cycle window predicts whether those users who have key behaviors in the first churn prediction time window have key behaviors in the second churn prediction time window , And so on !
3. Time window selection of dataset
After the loss cycle is determined , We need to choose the time window of the dataset . The time window here includes two :
From which day do you start to collect users' login logs : First, consider whether it is for all users or regular users , Generally, churn prediction is more targeted at old users , New users generally need time to grow into old users ( And the judgment conditions of new and old users are also specifically set according to the business , For example, the accumulated playing time exceeds 1 Months of new users can be regarded as old users ); Then consider how to choose the earliest time that needs to be included in the data set for training .
For the early registered users mentioned in the above figure, that's what I'm talking about here “ Old users ”, How much is it appropriate to push this time window forward ? I think there are two main principles : One is data Samples should be sufficient ( In particular, positive samples, that is, samples of lost users, should be sufficient ); Two is The time window for pushing forward should not be too long ( If the forward time window is too long , Some samples of old users who have been lost for a long time will also be included in the model to learn , Maybe because of timeliness and other factors, these old users who have been lost for a long time are not the people concerned by our loss prediction model . Some businesses may only care about, for example, pushing the window from the beginning of the observation period to the past for one month , See whether the active users in this month have key behaviors in the observation period window , That is, the push forward window is fixed to 1 Months , The data set thus obtained may be too small , In particular, there are too few lost samples , At this time, you can use multiple observation period windows to get more lost samples ).
It is necessary to count the user's behavior for how long : There is no final conclusion about this , This period is the user before the observation window last-login The last login timestamp is pushed forward . One method is to model the characteristics of multiple statistical cycles separately , Then look at the verification set ROC Which area is larger means the prediction effect is better , We also need to consider the time cost and fairness of data ( The people we pay attention to will include those who have changed from new users to old users , Therefore, it is not suitable to make this statistical time window very long , Because these people only act in a relatively short time , If the statistical time is too long, it is unfair to these people .
For example, use 6 Weekly data ROC The area is larger than 1 Months of data , and 2 The monthly data is only slightly better than 6 Weekly data , While considering the time cost of data , In the case of fairness and prediction effect , Choose here 6 Week instead of 2 Months is a better period for data extraction ).
4. How to segment training set and verification set
For scenarios such as user churn prediction , It may not be necessary to segment the training set and the verification set according to the timeline , Because the scenario of user churn prediction may not be a time-dependent task , Then for such a data set Divide according to proportion ( Specifically, considering the loss / Imbalances in retained category samples , It is best to do hierarchical and proportional segmentation when doing segmentation of training set and verification set ).
Of course, for the task of user churn prediction , It is also possible to construct training sets and verification sets according to the timeline . For example, the loss cycle is 7 God , The training set is 4 month 1 Number to 4 month 30 These active users of , These users are in 5 month 1 Number to 5 month 7 Is there any key behavior in this window as their label; Verify set fetch 5 month 1 Number to 5 month 7 Active users of , These users are in 5 month 8 Number to 5 month 14 Is there any key behavior in this window as their label.
5. Training iteration of user churn prediction model
For this scenario , The training iteration of the model can be selected in : Do full data retraining every once in a while ; Incremental training . If you use incremental training , The knowledge of users in each training cycle may be learned ( Suppose the capacity of the model is large enough ); If you retrain with full data at regular intervals , Although the user's old prior knowledge can be modeled as features , But even in this way, the learning of users' old knowledge may not be as good as incremental training , And every other period of time to do the full amount of data retraining, more importantly, the recent period of data has a greater impact on the model ( This is the most commonly used training method for ranking models in the three fields of search and promotion ), For the scenario of user churn prediction , Maybe this factor is not important . Therefore, I think incremental training may be more suitable for this scenario of user churn prediction .
in addition , Whether to use incremental training or full training depends on the selected model : image XGBoost,LightGBM In this way boosting The model of the way , Not very suitable for incremental training ( Although they support ), Because their model connotation is more suitable for full data training ; If the depth model is used , Naturally support incremental training .
If you choose incremental training , Incremental training needs to be considered frequency , For user churn scenarios, it may not be suitable to do incremental work on a daily basis , Because it takes a certain number of days to accumulate new samples , Incremental training frequency ( Or we call it training cycle ) There is no inevitable connection with the loss prediction cycle , However, if the incremental training cycle is set to be consistent with the loss cycle and loss prediction cycle , Data processing may be more convenient ; If you choose full training , For the task of user churn prediction , It may be appropriate to train every few days or a week .
summary
Data-centric AI This completes the introduction of the sample project , This paper introduces the basic concept of sample engineering and three elements , namely The abstraction and definition of the target task , Representation of samples and Construction of sample set , On this basis, it explains Sample project of user churn prediction task .
I believe you are beginning to feel the charm of the sample project and are eager to try , Let's talk about Data-centric AI The quality of the data set . Thank you for your patience in reading .
Author of this article

Liang Yuhui
Amazon cloud technology
Machine learning product technologist
Responsible for consulting and designing machine learning solutions based on Amazon cloud technology , Focus on the promotion and application of machine learning , Deeply participated in the construction and optimization of machine learning projects of many real customers . For deep learning model, distributed training , Rich experience in recommendation system and computing advertising .

hear , Click below 4 Button
You won't encounter bug 了 !
边栏推荐
- Selenium waiting mode
- Campus second-hand transaction based on wechat applet
- Numpy array index slice
- 【机器人手眼标定】eye in hand
- Leetcode sum of two numbers
- 阿里测开面试题
- 使用npm发布自己开发的工具包笔记
- [flask] official tutorial -part2: Blueprint - view, template, static file
- Global and Chinese markets of general purpose centrifuges 2022-2028: Research Report on technology, participants, trends, market size and share
- Cadre du Paddle: aperçu du paddlelnp [bibliothèque de développement pour le traitement du langage naturel des rames volantes]
猜你喜欢

Audio and video engineer YUV and RGB detailed explanation

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
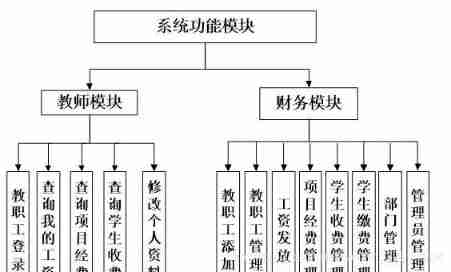
PHP campus financial management system for computer graduation design

Redis-列表

插卡4G工业路由器充电桩智能柜专网视频监控4G转以太网转WiFi有线网速测试 软硬件定制

Know MySQL database
![[flask] official tutorial -part2: Blueprint - view, template, static file](/img/bd/a736d45d7154119e75428f227af202.png)
[flask] official tutorial -part2: Blueprint - view, template, static file
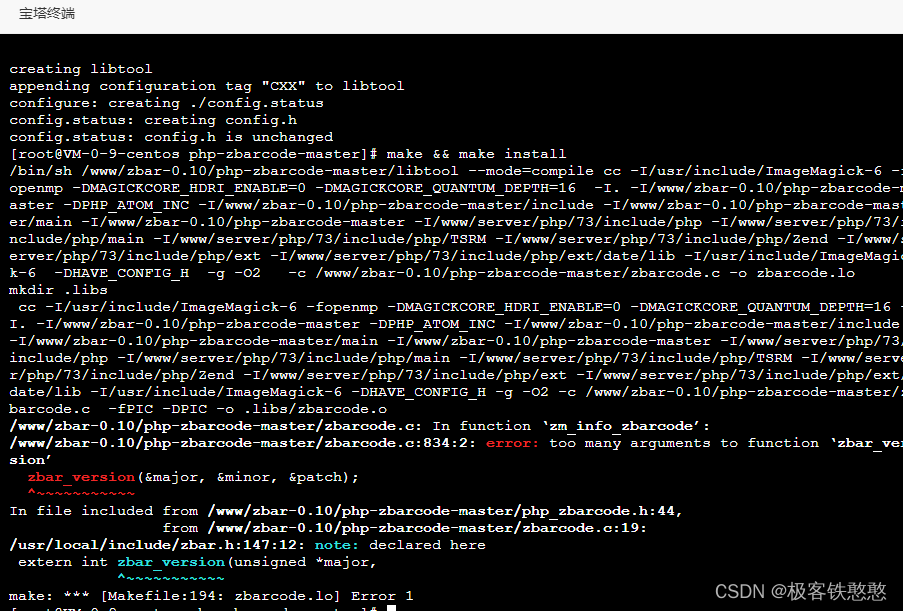
安装php-zbarcode扩展时报错,不知道有没有哪位大神帮我解决一下呀 php 环境用的7.3
Use the list component to realize the drop-down list and address list
leetcode-两数之和
随机推荐
Sword finger offer 12 Path in matrix
NLP fourth paradigm: overview of prompt [pre train, prompt, predict] [Liu Pengfei]
安装Redis
TrueType字体文件提取关键信息
Computer graduation design PHP animation information website
Accelerating spark data access with alluxio in kubernetes
[width first search] Ji Suan Ke: Suan tou Jun goes home (BFS with conditions)
【社区人物志】专访马龙伟:轮子不好用,那就自己造!
Visualstudio2019 compilation configuration lastools-v2.0.0 under win10 system
I like Takeshi Kitano's words very much: although it's hard, I will still choose that kind of hot life
Regular expressions: examples (1)
Pangolin Library: subgraph
Cadre du Paddle: aperçu du paddlelnp [bibliothèque de développement pour le traitement du langage naturel des rames volantes]
[flask] official tutorial -part2: Blueprint - view, template, static file
Overview of spark RDD
Text editing VIM operation, file upload
National intangible cultural heritage inheritor HD Wang's shadow digital collection of "Four Beauties" made an amazing debut!
Selenium waiting mode
It's wrong to install PHP zbarcode extension. I don't know if any God can help me solve it. 7.3 for PHP environment
Multi function event recorder of the 5th National Games of the Blue Bridge Cup