当前位置:网站首页>Cvpr19 deep stacked hierarchical multi patch network for image deblurring paper reproduction
Cvpr19 deep stacked hierarchical multi patch network for image deblurring paper reproduction
2022-07-02 07:59:00 【MezereonXP】
CVPR19-Deep Stacked Hierarchical Multi-patch Network for Image Deblurring Paper recurrence
This work mainly focuses on using depth network to realize image deblurring , Here we aim at GoPro Data set for paper reproduction .
This paper presents a new model architecture , To learn the characteristics at different levels , And realize the effect of deblurring .
First of all, here we give the framework of the overall model 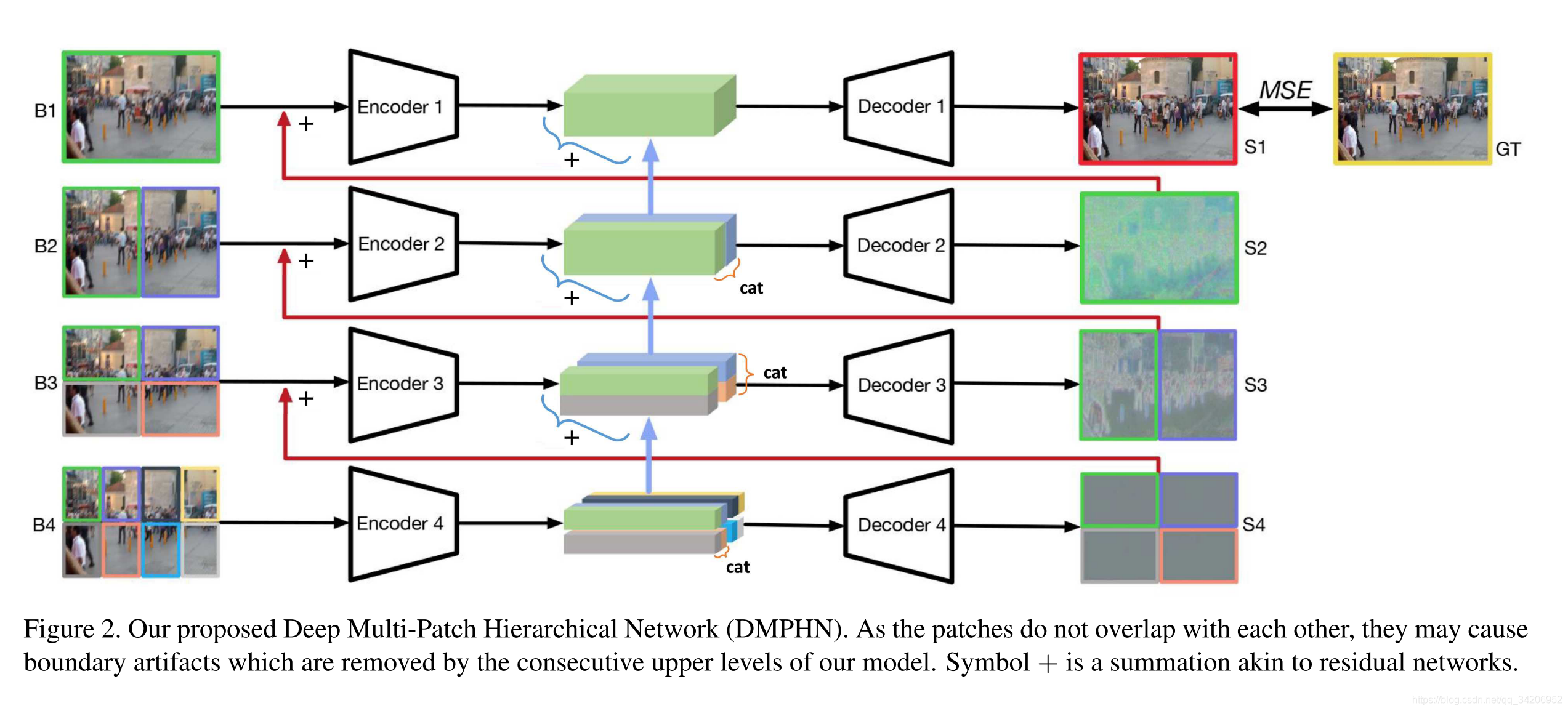
As shown in the figure above , The whole model consists of 4 Codec composition , Spread from bottom to top .
You can see , Start with the bottom input , We input the blurred picture , Will divide the picture into 8 Regions , Each area passes the encoder 4, obtain 8 The middle feature indicates , take 8 The two middle features are connected in pairs to get 4 Two features represent , And input to the decoder 4, And then you get 4 Outputs .
Input to encoder 3 Before , Will divide the pictures 4 block , Then put the previous decoder 4 The output of is added to the 4 On block area , By encoder 3 obtain 4 Intermediate features indicate , Here we will 4 The two intermediate feature representations are added to the previous two connected feature representations , After adding, connect two to get 2 Two features represent , And input to the decoder 3.
Repeat the operation accordingly , Up to the top , The mean square error between the final output and the corresponding clear picture MSE The calculation of , Then back propagation is used to train the model .
Here is the corresponding pytorch Code
import torch.nn as nn
import torch
from decoder import Decoder
from encoder import Encoder
class DMPHNModel(nn.Module):
def __init__(self, level=4, device='cuda'):
super(DMPHNModel, self).__init__()
self.encoder1 = Encoder().to(device)
self.decoder1 = Decoder().to(device)
self.encoder2 = Encoder().to(device)
self.decoder2 = Decoder().to(device)
self.encoder3 = Encoder().to(device)
self.decoder3 = Decoder().to(device)
self.encoder4 = Encoder().to(device)
self.decoder4 = Decoder().to(device)
self.level = level
def forward(self, x):
# x structure (B, C, H, W)
# from bottom to top
tmp_out = []
tmp_feature = []
for i in range(self.level):
currentlevel = self.level - i - 1 # 3,2,1,0
# For level 4(i.e. i = 3), we need to divide the picture into 2^i parts without any overlaps
num_parts = 2 ** currentlevel
rs = []
if currentlevel == 3:
rs = self.divide(x, 2, 4)
for j in range(num_parts):
tmp_feature.append(self.encoder4(rs[j])) # each feature is [B, C, H, W]
# combine the output
tmp_feature = self.combine(tmp_feature, comb_dim=3)
for j in range(int(num_parts/2)):
tmp_out.append(self.decoder4(tmp_feature[j]))
elif currentlevel == 2:
rs = self.divide(x, 2, 2)
for j in range(len(rs)):
rs[j] = rs[j] + tmp_out[j]
tmp_feature[j] = tmp_feature[j] + self.encoder3(rs[j])
tmp_feature = self.combine(tmp_feature, comb_dim=2)
tmp_out = []
for j in range(int(num_parts/2)):
tmp_out.append(self.decoder3(tmp_feature[j]))
elif currentlevel == 1:
rs = self.divide(x, 1, 2)
for j in range(len(rs)):
rs[j] = rs[j] + tmp_out[j]
tmp_feature[j] = tmp_feature[j] + self.encoder2(rs[j])
tmp_feature = self.combine(tmp_feature, comb_dim=3)
tmp_out = []
for j in range(int(num_parts/2)):
tmp_out.append(self.decoder2(tmp_feature[j]))
else:
x += tmp_out[0]
x = self.decoder1(self.encoder1(x)+tmp_feature[0])
return x
def combine(self, x, comb_dim=2):
"""[ Merge the array two elements at a time and return ] Args: x ([tensor array]): [ Output tensor Array ] comb_dim (int, optional): [ Merged dimensions , Merging from a high level is 2, Width merging is 3]. Defaults to 2. Returns: [tensor array]: [ Combined array , The length becomes half ] """
rs = []
for i in range(int(len(x)/2)):
rs.append(torch.cat((x[2*i], x[2*i+1]), dim=comb_dim))
return rs
def divide(self, x, h_parts_num, w_parts_num):
""" This function will BxHxWxC Input for segmentation , In essence, each picture is partitioned Here, we directly operate on multidimensional arrays Args: x (Torch Tensor): input torch tensor (e.g. [Batchsize, Channels, Heights, Width]) h_parts_num (int): The number of divided parts on heights w_parts_num (int): The number of divided parts on width Returns: [A list]: h_parts_num x w_parts_num 's tensor list, each one has [B, Channels, H/h_parts_num, W/w_parts_num] structure """
rs = []
for i in range(h_parts_num):
tmp = x.chunk(h_parts_num, dim=2)[i]
for j in range(w_parts_num):
rs.append(tmp.chunk(w_parts_num,dim=3)[j])
return rs
The above code is the input process of the whole model , We also need to implement the structure of codec
Here is the structure description in the paper

There are some mistakes in the pictures given in this paper , The last layer of the decoder should be [32,3,3,1], Otherwise, you cannot output 3 Pictures of channels .
Gray block ReLU Activation function , The directed connection between blocks is residual connection , It's convolution first and then addition
Directly give the code of the corresponding encoder and decoder
import torch.nn as nn
import torch.nn.functional as F
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1, stride=1)
self.conv2 = nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1)
self.conv3 = nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1)
self.conv4 = nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1)
self.conv5 = nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1)
self.conv6 = nn.Conv2d(32, 64, kernel_size=3, padding=1, stride=2)
self.conv7 = nn.Conv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.conv8 = nn.Conv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.conv9 = nn.Conv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.conv10 = nn.Conv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.conv11 = nn.Conv2d(64, 128, kernel_size=3, padding=1, stride=2)
self.conv12 = nn.Conv2d(128, 128, kernel_size=3, padding=1, stride=1)
self.conv13 = nn.Conv2d(128, 128, kernel_size=3, padding=1, stride=1)
self.conv14 = nn.Conv2d(128, 128, kernel_size=3, padding=1, stride=1)
self.conv15 = nn.Conv2d(128, 128, kernel_size=3, padding=1, stride=1)
def forward(self, x):
tmp = self.conv1(x)
x1 = F.relu(self.conv2(tmp))
x1 = self.conv3(x1)
tmp = x1 + tmp # residual link
x1 = F.relu(self.conv4(tmp))
x1 = self.conv5(x1)
x1 = x1 + tmp # residual link
tmp = self.conv6(x1)
x1 = F.relu(self.conv7(tmp))
x1 = self.conv8(x1)
tmp = x1 + tmp # residual link
x1 = F.relu(self.conv9(tmp))
x1 = self.conv10(x1)
x1 = x1 + tmp # residual link
tmp = self.conv11(x1)
x1 = F.relu(self.conv12(tmp))
x1 = self.conv13(x1)
tmp = x1 + tmp # residual link
x1 = F.relu(self.conv14(tmp))
x1 = self.conv15(x1)
x1 = x1 + tmp # residual link
return x1
The code of the decoder is :
import torch.nn as nn
import torch.nn.functional as F
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.conv1 = nn.Conv2d(128, 128, kernel_size=3, padding=1, stride=1)
self.conv2 = nn.Conv2d(128, 128, kernel_size=3, padding=1, stride=1)
self.conv3 = nn.Conv2d(128, 128, kernel_size=3, padding=1, stride=1)
self.conv4 = nn.Conv2d(128, 128, kernel_size=3, padding=1, stride=1)
self.deconv1 = nn.ConvTranspose2d(128, 64, kernel_size=4, padding=1, stride=2)
self.conv5 = nn.Conv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.conv6 = nn.Conv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.conv7 = nn.Conv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.conv8 = nn.Conv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.deconv2 = nn.ConvTranspose2d(64, 32, kernel_size=4, padding=1, stride=2)
self.conv9 = nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1)
self.conv10 = nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1)
self.conv11 = nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1)
self.conv12 = nn.Conv2d(32, 32, kernel_size=3, padding=1, stride=1)
self.conv13 = nn.Conv2d(32, 3, kernel_size=3, padding=1, stride=1)
def forward(self, x):
tmp = x
x1 = F.relu(self.conv1(tmp))
x1 = self.conv2(x1)
tmp = x1 + tmp # residual link
x1 = F.relu(self.conv3(tmp))
x1 = self.conv4(x1)
x1 = x1 + tmp # residual link
tmp = self.deconv1(x1)
x1 = F.relu(self.conv5(tmp))
x1 = self.conv6(x1)
tmp = x1 + tmp # residual link
x1 = F.relu(self.conv7(tmp))
x1 = self.conv8(x1)
x1 = x1 + tmp # residual link
tmp = self.deconv2(x1)
x1 = F.relu(self.conv9(tmp))
x1 = self.conv10(x1)
tmp = x1 + tmp # residual link
x1 = F.relu(self.conv11(tmp))
x1 = self.conv12(x1)
x1 = x1 + tmp # residual link
return self.conv13(x1)
Here I train 1500 individual epoch,lr Set to 1e-4,batch_size=6. The effect of training is shown in the figure below
| Input | Output |
|---|---|
 |  |
I have put the complete training code github On , Welcome to star and issue, Links are as follows :
github link
边栏推荐
猜你喜欢
![[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video](/img/bc/c54f1f12867dc22592cadd5a43df60.png)
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video

【DIoU】《Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression》
Embedding malware into neural networks

Programmers can only be 35? The 74 year old programmer in the United States has been programming for 57 years and has not retired
【Cutout】《Improved Regularization of Convolutional Neural Networks with Cutout》
Thesis writing tip2

Replace self attention with MLP
用于类别增量学习的动态可扩展表征 -- DER
How to turn on night mode on laptop
【Batch】learning notes
随机推荐
用MLP代替掉Self-Attention
Using super ball embedding to enhance confrontation training
【TCDCN】《Facial landmark detection by deep multi-task learning》
Correction binoculaire
Meta learning Brief
静态库和动态库
我的vim配置文件
【MnasNet】《MnasNet:Platform-Aware Neural Architecture Search for Mobile》
Sequence problem for tqdm and print
Memory model of program
Go functions make, slice, append
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
What if the laptop can't search the wireless network signal
【Hide-and-Seek】《Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization xxx》
Feature Engineering: summary of common feature transformation methods
【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
用C# 语言实现MYSQL 真分页
Rhel7 operation level introduction and switching operation
【Cutout】《Improved Regularization of Convolutional Neural Networks with Cutout》
【MagNet】《Progressive Semantic Segmentation》