当前位置:网站首页>Replace self attention with MLP
Replace self attention with MLP
2022-07-02 07:51:00 【MezereonXP】
List of articles
use MLP Instead of Self-Attention
This is a job of Tsinghua University “Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks”
Replace... With two linear layers Self-Attention Mechanism , In the end, it can improve the speed while maintaining the accuracy .
What's surprising about this job is , We can use MLP Instead of Attention Mechanism , This makes it necessary for us to reconsider Attention The nature of the performance improvement .
Transformer Medium Self-Attention Mechanism
First , As shown in the figure below :

We give its formal result :
A = softmax ( Q K T d k ) F o u t = A V A = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})\\ F_{out} = AV A=softmax(dkQKT)Fout=AV
among , Q , K ∈ R N × d ′ Q,K \in \mathbb{R}^{N\times d'} Q,K∈RN×d′ meanwhile V ∈ R N × d V\in \mathbb{R}^{N\times d} V∈RN×d
here , We give a simplified version , As shown in the figure below :
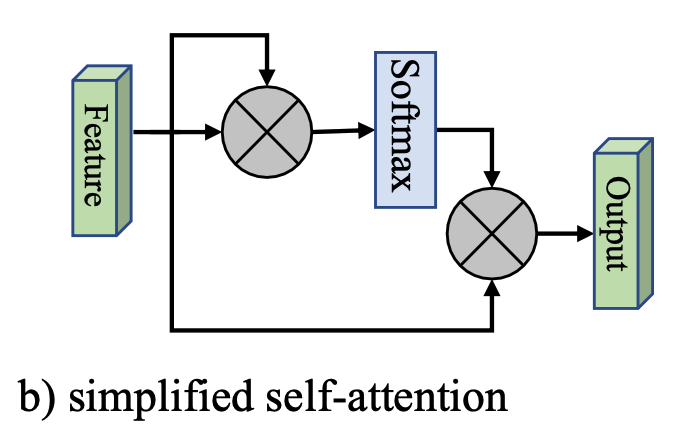
Also is to Q , K , V Q,K,V Q,K,V All based on input features F F F Instead of , It is formalized as :
A = softmax ( F F T ) F o u t = A F A = \text{softmax}(FF^T)\\ F_{out} = AF A=softmax(FFT)Fout=AF
However , The computational complexity is O ( d N 2 ) O(dN^2) O(dN2), This is a Attention A big drawback of the mechanism .
External attention (External Attention)
As shown in the figure below :
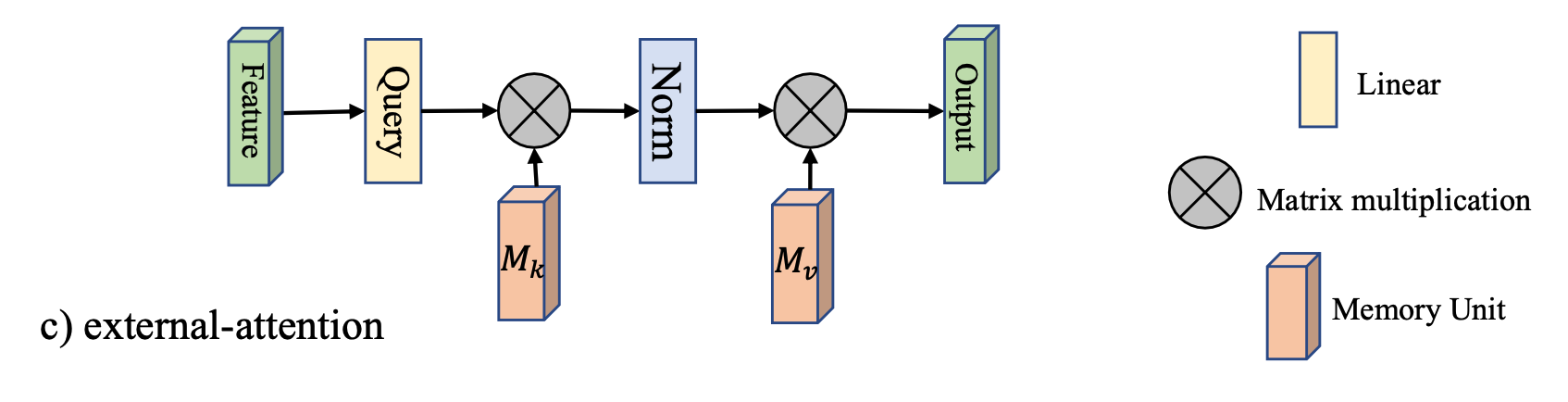
Two matrices are introduced M k ∈ R S × d M_k\in \mathbb{R}^{S\times d} Mk∈RS×d as well as $M_v \in\mathbb{R}^{S\times d} $, Instead of the original K , V K,V K,V
Here we give its formalization directly :
A = Norm ( F M k T ) F o u t = A M v A = \text{Norm}(FM_k^T)\\ F_{out} = AM_v A=Norm(FMkT)Fout=AMv
This design , Reduce the complexity to O ( d S N ) O(dSN) O(dSN), The work found that , When S ≪ N S\ll N S≪N When , Still able to maintain enough accuracy .
Among them Norm ( ⋅ ) \text{Norm}(\cdot) Norm(⋅) The operation is to start with the column Softmax, Then normalize the rows .
experimental analysis
First , The article will Transformer Medium Attention The mechanism replaced , And then test on all kinds of tasks , Include :
- Image classification
- Semantic segmentation
- Image generation
- Point cloud classification
- Point cloud segmentation
Only partial results are given here , Briefly explain the accuracy loss after replacement .
Image classification

Semantic segmentation

Image generation

You can see , On different tasks , There's basically no loss of accuracy .
边栏推荐
- What if the laptop can't search the wireless network signal
- Tencent machine test questions
- One book 1078: sum of fractional sequences
- Faster-ILOD、maskrcnn_ Benchmark training coco data set and problem summary
- 【Random Erasing】《Random Erasing Data Augmentation》
- Implementation of yolov5 single image detection based on onnxruntime
- 【C#笔记】winform中保存DataGridView中的数据为Excel和CSV
- 【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》
- CONDA common commands
- 基于onnxruntime的YOLOv5单张图片检测实现
猜你喜欢
Using compose to realize visible scrollbar
【学习笔记】Matlab自编图像卷积函数

【Random Erasing】《Random Erasing Data Augmentation》

Machine learning theory learning: perceptron
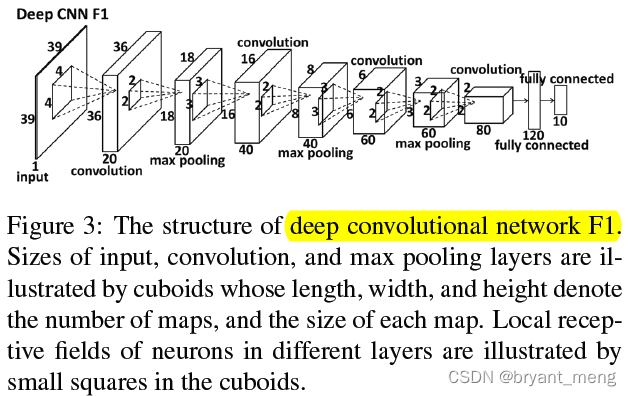
【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》
Installation and use of image data crawling tool Image Downloader
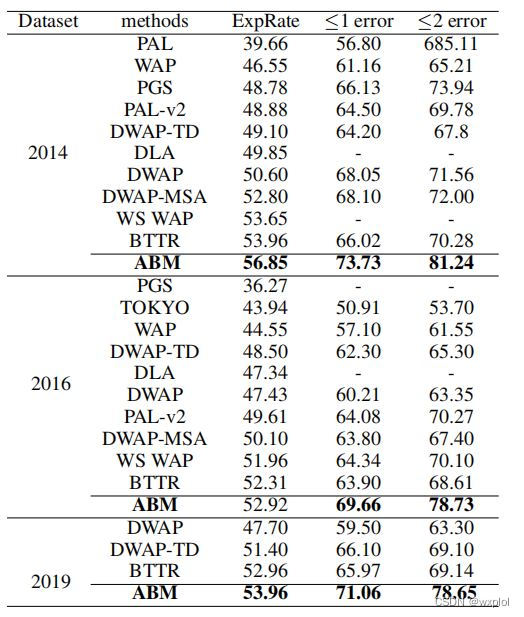
ABM论文翻译
基于onnxruntime的YOLOv5单张图片检测实现
【MobileNet V3】《Searching for MobileNetV3》

超时停靠视频生成
随机推荐
Thesis tips
Open failed: enoent (no such file or directory) / (operation not permitted)
Nacos service registration in the interface
[multimodal] clip model
自然辩证辨析题整理
iOD及Detectron2搭建过程问题记录
The difference and understanding between generative model and discriminant model
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
open3d环境错误汇总
Timeout docking video generation
Point cloud data understanding (step 3 of pointnet Implementation)
conda常用命令
【双目视觉】双目矫正
ABM thesis translation
Yolov3 trains its own data set (mmdetection)
Conversion of numerical amount into capital figures in PHP
【DIoU】《Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression》
Implementation of yolov5 single image detection based on pytorch
【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》
《Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer》论文翻译