当前位置:网站首页>Do you know about autorl in intensive learning? A summary of articles written by more than ten scholars including Oxford University and Google
Do you know about autorl in intensive learning? A summary of articles written by more than ten scholars including Oxford University and Google
2022-07-04 07:42:00 【PaperWeekly】

author | Boat 、 Chen Ping
source | Almost Human
From Oxford University 、 University of Freiburg 、 More than ten researchers from Google Research Institute and other institutions wrote a summary AutoRL.
Reinforcement learning (RL) The combination with deep learning has brought a series of impressive results , Many people think that ( depth ) Reinforcement learning provides a way to universal agent . However ,RL The success of agent is usually highly sensitive to the design selection in the training process , Tedious and error prone manual adjustments may be required . This makes it possible to RL Challenging for new problems , It also limits RL The full potential of .
In many other areas of machine learning ,AutoML It has been shown that such design choices can be automated , And applied to RL It also produced promising preliminary results . However , Self reinforcement learning (AutoRL) It's not just about AutoML The standard application of , It also includes RL Unique additional challenges , This makes researchers naturally develop some different methods .
AutoRL Has become RL An important area of research , For from RNA Various applications from design to go and other games provide hope . because RL The methods and environments considered in are diverse , So many researches are carried out in different sub fields . From Oxford University 、 University of Freiburg 、 More than a dozen researchers from Google Research Institute and other institutions have written articles trying to unify AutoRL field , And provides a general classification , The study discusses each area in detail and raises issues that may be of interest to future researchers .

Address of thesis :
https://arxiv.org/pdf/2201.03916.pdf
AutoRL Method
Reinforcement learning can theoretically be used for any task , Including environments where the world model is unknown . However , This versatility comes at a price , Its biggest disadvantage is that agents often cannot obtain the real model of the environment . If an agent wants to use a model in a scenario , Then it has to learn completely from experience , It's going to bring a lot of challenges . There is an error between the model explored by the agent and the real model , And this kind of error will cause the agent to perform well in the learned model , But not in the real world ( Even worse ).
The purpose of this research survey is to introduce AutoRL field ,AutoRL Can meet all kinds of challenges : One side ,RL The fragility of the algorithm hinders its application in new fields , Especially those practitioners who lack a lot of resources to search for the best configuration . in many instances , For completely invisible problems , Manually finding a set of moderately strong superparameters can be very expensive .AutoRL It has been proved that it can help solve important problems in this situation , For example, design RNA. On the other hand , For those who benefit from more computing , Obviously, increasing the flexibility of the algorithm can improve the performance . The famous AlphaGo Agents have shown this , The agent has been significantly improved by using Bayesian optimization .
As early as 1980 years ,AutoRL The algorithm is proved to be effective . However , lately AutoML The popularity of has led to the new application of more advanced technology . meanwhile , The recent popularity of meta learning has led to a series of initiatives aimed at Automation RL The work of the process .
This paper attempts to provide a classification of these methods , They hope to open up a series of future work through the cross integration of ideas , At the same time RL Researchers introduce a set of techniques to improve their algorithm performance . The study believes that AutoRL It plays an important role in improving the potential impact of reinforcement learning , Whether in open research or in practical applications .
Besides , The study hopes to have a positive impact on AutoML Interested researchers attract AutoRL Community , Specially ,RL Non stationarity (non-stationarity), Because the data that the agent is training is a function of the current strategy . Besides , The study also introduces AutoRL Be specific to RL Problem environment and algorithm design .
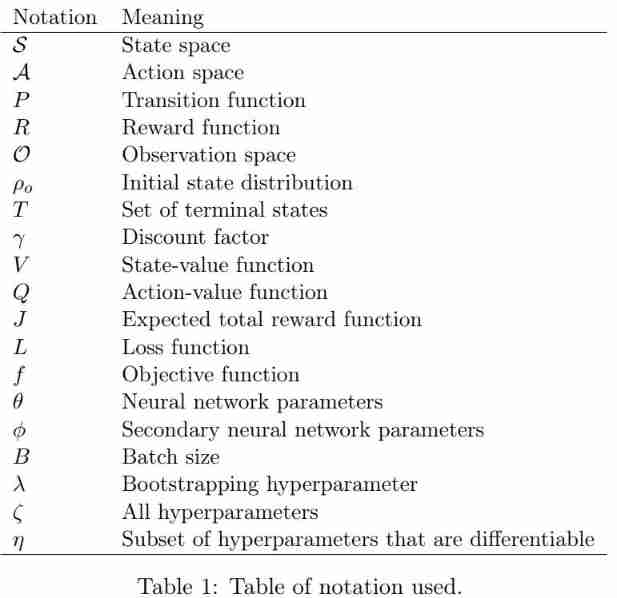
The study investigated AutoRL Community and Technology . Generally speaking ,AutoRL Most methods can be organized by combining internal and external loops . Each cycle can be optimized by black box or gradient based methods , However, the gradient of external circulation and the black box of internal circulation cannot be combined , Because the internal circulation black box setting will make the gradient unavailable , As shown in the table 2 Sum graph 2 Shown :
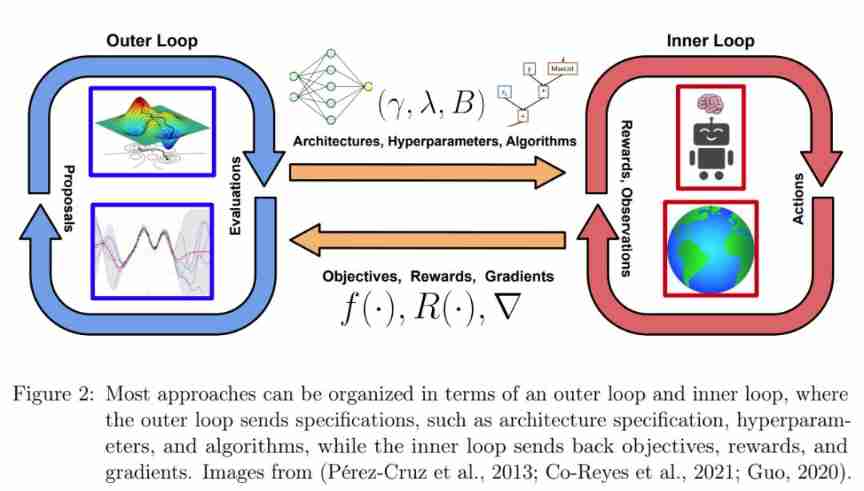

The following table 3 Shown , The study is summarized by categories AutoRL Classification of methods , The classification of methods will be reflected in each subsection of Chapter 4

Random / Grid search driven method
The study first discusses the simplest method : Random search and grid search . Random search randomly samples the hyperparametric configuration from the search space , Grid search divides the search space into fixed grid points , And evaluate it . Because of its simplicity , Random search and grid search can be used to select the list of super parameters , Evaluate the super parameters and choose the best configuration . in fact , Grid search is still RL It's the most common method in , In most cases, grid search will adjust the super parameters , But it should not be regarded as the most effective method . However, these classical methods do not consider the potential non stationarity of the optimization problem , The figure below 3 Describes the problem :
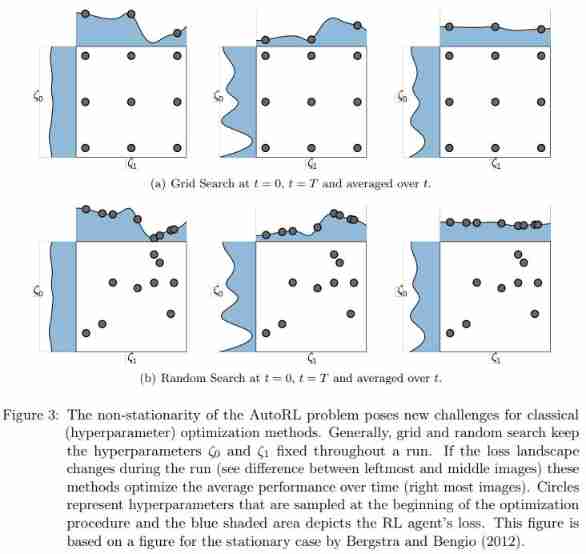
A common way to improve random search performance is to use Hyperband, This is a configuration evaluation for hyperparametric optimization . It focuses on adaptive resource allocation and early stop (early-stopping) To speed up random search . Special ,Hyperband Use 「Successive Halving」 Allocate the budget to a set of superparametric configurations .Zhang Et al. Used random search and Hyperband To adjust its MBRL Hyperparameters of the algorithm .
Bayesian optimization
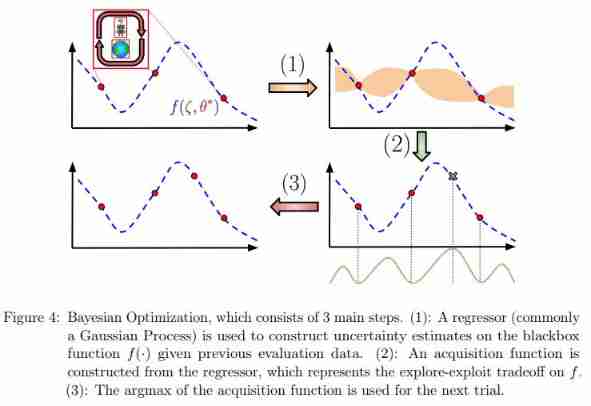
Bayesian optimization (Bayesian Optimization ,BO) Is by far one of the most popular methods , It is mainly used in industrial applications and various scientific experiments . about RL Applications ,BO One of the most prominent uses is to adjust AlphaGo Hyperparameters , This includes Monte Carlo tree search (MCTS) Super parameter and time control settings . This leads to AlphaGo The winning rate in self chess starts from 50% Up to 66.5%. chart 4 It shows RL The general concept of Bayesian Optimization in the case :
Evolutionary algorithms
Evolutionary algorithms are widely used in various optimization tasks , The mechanism is shown in the figure 5 Shown :
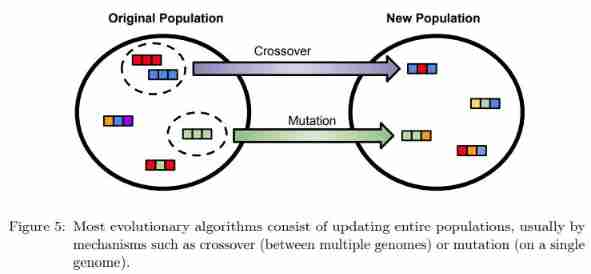
Evolutionary algorithms are often used to search RL Hyperparameters of the algorithm .Eriksson Et al. Used real genetic algorithm (GA), Through the genetic coding of each individual in the population RL Hyperparameters of the algorithm , To adjust SARSA Hyperparameters , Researchers applied this method to control mobile robots .Cardenoso Fernandez and Caarls Use GA Adjust in simple settings RL Hyperparameters of the algorithm , And by combining the automatic restart strategy to get rid of the local minimum , Achieved good performance .Ashraf Used by others Whale optimization algorithm (WOA), Its inspiration comes from the hunting strategy of humpback whales , In all kinds of RL Optimize in the task DDPG Super parameters to improve performance .
Meta gradient for online tuning
Metagradient provides an alternative way to deal with RL Nonparametric nonstationarity . The inspiration of meta gradient formula comes from meta learning method , for example MAML, It uses gradients to optimize internal and external loops . especially , Meta gradient method makes it ( Differentiable ) A subset of the hyperparameters is specified as a meta parameter η. In the inner loop , Agents use fixed η To optimize , Adopt gradient step To minimize ( It's usually fixed ) Loss function . In the external loop , By taking gradients step To optimize η, To minimize the external loss function . Each specific choice of internal and external loss functions defines a new meta gradient algorithm .
Black box online tuning
PBT The advantage of Heyuan gradient lies in its ability to dynamically adjust super parameters , However , This is not the only way . in fact , Researchers have considered various other methods , From black box method to online learning heuristic method . This section focuses on the single agent method for dynamic adaptation in settings where the hyperparameter is not differentiable .
The method of adaptive selection of hyperparameters is self 20 century 90 It has been important since the s .Sutton and Singh (1994) Put forward TD Three alternative methods of adaptive weighting scheme in the algorithm ,Kearns and Singh (2000) The upper error limit of the timing difference algorithm is derived , And use these boundaries to derive λ The schedule of .Downey and Sanner (2010) Bayesian model is used to average TD Method selection λ bootstrapping Hyperparameters . lately , White (2016) Put forward λ-greedy To adapt to λ As a function of state , And realize the approximate optimal deviation - Variance tradeoff ,Paul wait forsomeone (2019) Put forward HOOF, It uses random search with non strategic data to periodically select new hyperparameters for the strategic gradient algorithm .
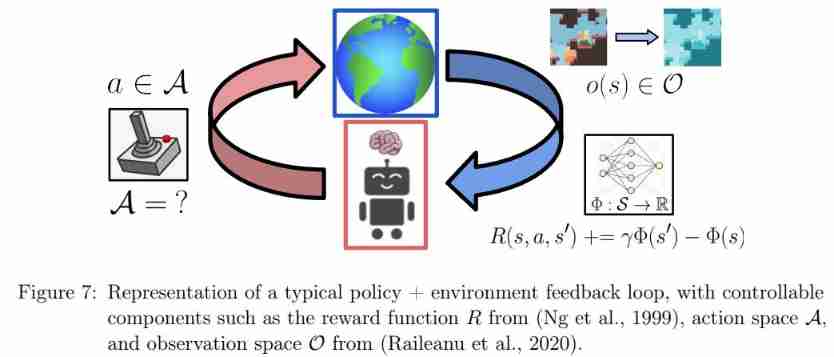
environmental design
Environment design is an important part of reinforcement learning agent automatic learning . From course learning to synthetic environment learning and generation , To combine course learning with environment generation , The goal here is to speed up the learning speed of machine learning agents through environment design . Pictured 7 Shown :
Hybrid method
Inevitably , Some methods do not belong to a single category . in fact , Many methods try to take advantage of different methods , It can be called a hybrid method . In this study , These hybrid methods are defined as using tables 3 Methods of more than one kind of Technology , for example BOHB、DEHB etc. .
Thank you very much
thank TCCI Tianqiao Academy of brain sciences for PaperWeekly Support for .TCCI Focus on the brain to find out 、 Brain function and brain health .
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
- 墨者学院-phpMyAdmin后台文件包含分析溯源
- Google's official response: we have not given up tensorflow and will develop side by side with Jax in the future
- flask-sqlalchemy 循环引用
- Zhanrui tankbang | jointly build, cooperate and win-win zhanrui core ecology
- Is l1-029 too fat (5 points)
- 墨者学院-Webmin未经身份验证的远程代码执行
- L1-021 important words three times (5 points)
- Node foundation ~ node operation
- Zephyr 學習筆記2,Scheduling
- Système de surveillance zabbix contenu de surveillance personnalisé
猜你喜欢
The frost peel off the purple dragon scale, and the xiariba people will talk about database SQL optimization and the principle of indexing (primary / secondary / clustered / non clustered)

Introduction to rce in attack and defense world

Linear algebra 1.1
Flask 常用组件
Easy to understand: understand the time series database incluxdb
线性代数1.1

手写简易版flexible.js以及源码分析

博客停更声明
节点基础~节点操作

Heap concept in JVM
随机推荐
BUUCTF(3)
Technical experts from large factories: common thinking models in architecture design
Improve the accuracy of 3D reconstruction of complex scenes | segmentation of UAV Remote Sensing Images Based on paddleseg
Advanced MySQL: Basics (5-8 Lectures)
Xcode 14之大变化详细介绍
OKR vs. KPI 一次搞清楚这两大概念!
Activiti常见操作数据表关系
Flask 常用组件
深入浅出:了解时序数据库 InfluxDB
[Android reverse] function interception (use cache_flush system function to refresh CPU cache | refresh CPU cache disadvantages | recommended time for function interception)
[gurobi] establishment of simple model
flask-sqlalchemy 循环引用
果果带你写链表,小学生看了都说好
ZABBIX 5.0 monitoring client
One of the general document service practice series
zabbix监控系统部署
Enter the year, month, and determine the number of days
Zephyr 学习笔记2,Scheduling
L2-013 red alarm (C language) and relevant knowledge of parallel search
Electronic Association C language level 1 34, piecewise function