当前位置:网站首页>Strengthen basic learning records
Strengthen basic learning records
2022-07-06 13:52:00 【I like the strengthened Xiaobai in Curie】
Strengthening learning Q-learning and Saras Comparison of
Multi agent reinforcement learning small white one , Recently, I am learning to strengthen the foundation of learning , Record here , In case you forget .
One 、Q-learning
Q-learing The most basic reinforcement learning algorithm , adopt Q Table storage status - Action value , namely Q(s,a), It can be used for problems with small state space , When the dimension of state space is large , Need to cooperate with neural network , Expanded into DQN Algorithm , Dealing with problems .
- Value-based
- Off-Policy
Read a lot about On-Policy and Off-Policy The blog of , I haven't quite understood the difference between the two , I'm confused , I read a blogger's answer two days ago , Only then have a deeper understanding , A link is attached here .
link : on-policy and off-policy What's the difference? ?
When Q-learning update , Although the data used is current policy Produced , But the updated strategy is not the one that generates this data ( Pay attention to the... In the update formula max), It can be understood here : there max The operation is to select a larger Q A worthy action , to update Q surface , But the actual round may not be changed , So it is Off-Policy Of . - Pseudo code

- Realization
The environment used here is the treasure hunt game in the teacher's tutorial , Maintain through lists ,—#-T, The last position T It's a treasure ,# Represents the current position of the player , Go to the rightmost grid , Find the treasure , Game over .
The code implementation refers to a blogger , Can't find the link .....
import numpy as np
import pandas as pd
import time
N_STATES = 6 # 6 Status , One dimensional array length
ACTIONS = [-1, 1] # Two states ,-1:left, 1:right
epsilon = 0.9 # greedy
alpha = 0.1 # Learning rate
gamma = 0.9 # Diminishing reward value
max_episodes = 10 # Maximum rounds
fresh_time = 0.3 # Move interval
# q_table
q_table = pd.DataFrame(np.zeros((N_STATES, len(ACTIONS))), columns=ACTIONS)
# choose action: 1. Explore randomly and explore locations that have not been explored , Otherwise select reward The biggest move
def choose_action(state, table):
state_actions = table.iloc[state, :]
if np.random.uniform() > epsilon or state_actions.all() == 0:
action = np.random.choice(ACTIONS)
else:
action = state_actions.argmax()
return action
def get_env_feedback(state, action):
# New status = current state + Move status
new_state = state + action
reward = 0
# Shift right plus 0.5
# Move to the right , Closer to the treasure , get +0.5 Reward
if action > 0:
reward += 0.5
# Move to the left , Stay away from the treasure , get -0.5 Reward
if action < 0:
reward -= 0.5
# The next step is to reach the treasure , Give the highest reward +1
if new_state == N_STATES - 1:
reward += 1
# If you go all the way to the left , And move left , Get the lowest negative reward -1
# At the same time pay attention to , It's still here to define the new state , Otherwise, it will report a mistake
if new_state < 0:
new_state = 0
reward -= 1
return new_state, reward
def update_env(state, epoch, step):
env_list = ['-'] * (N_STATES - 1) + ['T']
if state == N_STATES - 1:
# Reach your destination
print("")
print("epoch=" + str(epoch) + ", step=" + str(step), end='')
time.sleep(2)
else:
env_list[state] = '#'
print('\r' + ''.join(env_list), end='')
time.sleep(fresh_time)
def q_learning():
for epoch in range(max_episodes):
step = 0 # Move steps
state = 0 # The initial state
update_env(state, epoch, step)
while state != N_STATES - 1:
cur_action = choose_action(state, q_table)
new_state, reward = get_env_feedback(state, cur_action)
q_pred = q_table.loc[state, cur_action]
if new_state != N_STATES - 1:
q_target = reward + gamma * q_table.loc[new_state, :].max()
else:
q_target = reward
q_table.loc[state, cur_action] += alpha * (q_target - q_pred)
state = new_state
update_env(state, epoch, step)
step += 1
return q_table
q_learning()
Two 、Saras
Saras It is also the most basic algorithm in reinforcement learning , Also use Q Table is stored Q(s,a), The reason why it's called Saras, It's because of one transition contain (s,a,r,a,s) Quintuples , namely Saras.
- Value-based
- On-Policy
Here's a comparison Q-learning, Then we can know , The data used here is the current policy Produced , And updated Q When it's worth it , It is based on new actions and new States Q value , New actions will be performed ( Note that there is no max), So it is On-Policy. - Pseudo code

- Realization
Reference here Q-learning Made simple changes , This is based on the new state , Choose another action , And perform the action , In addition, update Q When it's worth it , Directly based on the corresponding Q Value update .
import numpy as np
import pandas as pd
import time
N_STATES = 6 # 6 Status , One dimensional array length
ACTIONS = [-1, 1] # Two states ,-1:left, 1:right
epsilon = 0.9 # greedy
alpha = 0.1 # Learning rate
gamma = 0.9 # Diminishing reward value
max_episodes = 10 # Maximum rounds
fresh_time = 0.3 # Move interval
# q_table
# Generate (N_STATES,len(ACTIONS))) Of Q Empty value table
q_table = pd.DataFrame(np.zeros((N_STATES, len(ACTIONS))), columns=ACTIONS)
# choose action:
#0.9 Probability greed ,0.1 Probabilistic random selection of actions , Be exploratory
def choose_action(state, table):
state_actions = table.iloc[state, :]
if np.random.uniform() > epsilon or state_actions.all() == 0:
action = np.random.choice(ACTIONS)
else:
action = state_actions.argmax()
return action
def get_env_feedback(state, action):
# New status = current state + Move status
new_state = state + action
reward = 0
# Shift right plus 0.5
# Move to the right , Closer to the treasure , get +0.5 Reward
if action > 0:
reward += 0.5
# Move to the left , Stay away from the treasure , get -0.5 Reward
if action < 0:
reward -= 0.5
# The next step is to reach the treasure , Give the highest reward +1
if new_state == N_STATES - 1:
reward += 1
# If you go all the way to the left , And move left , Get the lowest negative reward -1
# At the same time pay attention to , It's still here to define the new state , Otherwise, it will report a mistake
if new_state < 0:
new_state = 0
reward -= 1
return new_state, reward
# Maintain the environment
def update_env(state, epoch, step):
env_list = ['-'] * (N_STATES - 1) + ['T']
if state == N_STATES - 1:
# Reach your destination
print("")
print("epoch=" + str(epoch) + ", step=" + str(step), end='')
time.sleep(2)
else:
env_list[state] = '#'
print('\r' + ''.join(env_list), end='')
time.sleep(fresh_time)
# to update Q surface
def Saras():
for epoch in range(max_episodes):
step = 0 # Move steps
state = 0 # The initial state
update_env(state, epoch, step)
cur_action = choose_action(state, q_table)
while state != N_STATES - 1:
new_state, reward = get_env_feedback(state, cur_action)
new_action = choose_action(new_state,q_table)
q_pred = q_table.loc[state, cur_action]
if new_state != N_STATES - 1:
q_target = reward + gamma * q_table.loc[new_state, new_action]
else:
q_target = reward
q_table.loc[state, cur_action] += alpha * (q_target - q_pred)
state,cur_action = new_state,new_action
update_env(state, epoch, step)
step += 1
return q_table
Saras()
Blog for the first time , It may be understood that there is a problem , Please correct your mistakes .
边栏推荐
- This time, thoroughly understand the MySQL index
- 简述xhr -xhr的基本使用
- Redis实现分布式锁原理详解
- Using qcommonstyle to draw custom form parts
- String ABC = new string ("ABC"), how many objects are created
- Service ability of Hongmeng harmonyos learning notes to realize cross end communication
- Relationship between hashcode() and equals()
- Mortal immortal cultivation pointer-2
- 优先队列PriorityQueue (大根堆/小根堆/TopK问题)
- Canvas foundation 1 - draw a straight line (easy to understand)
猜你喜欢
甲、乙机之间采用方式 1 双向串行通信,具体要求如下: (1)甲机的 k1 按键可通过串行口控制乙机的 LEDI 点亮、LED2 灭,甲机的 k2 按键控制 乙机的 LED1
Nuxtjs快速上手(Nuxt2)
3. Input and output functions (printf, scanf, getchar and putchar)
![[面試時]——我如何講清楚TCP實現可靠傳輸的機制](/img/d6/109042b77de2f3cfbf866b24e89a45.png)
[面試時]——我如何講清楚TCP實現可靠傳輸的機制
. How to upload XMIND files to Jinshan document sharing online editing?

7-7 7003 组合锁(PTA程序设计)
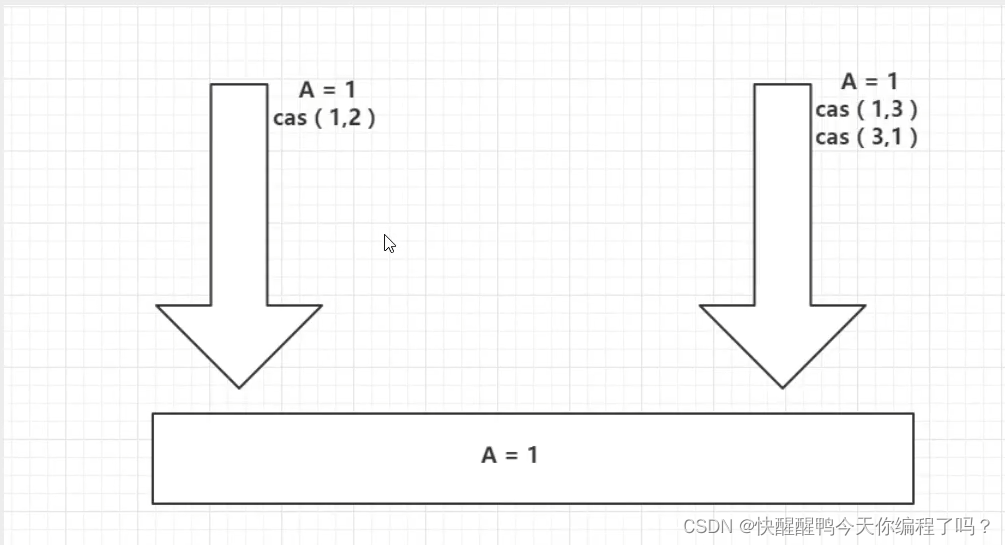
ABA问题遇到过吗,详细说以下,如何避免ABA问题
Record a penetration of the cat shed from outside to inside. Library operation extraction flag
Matlab opens M file garbled solution
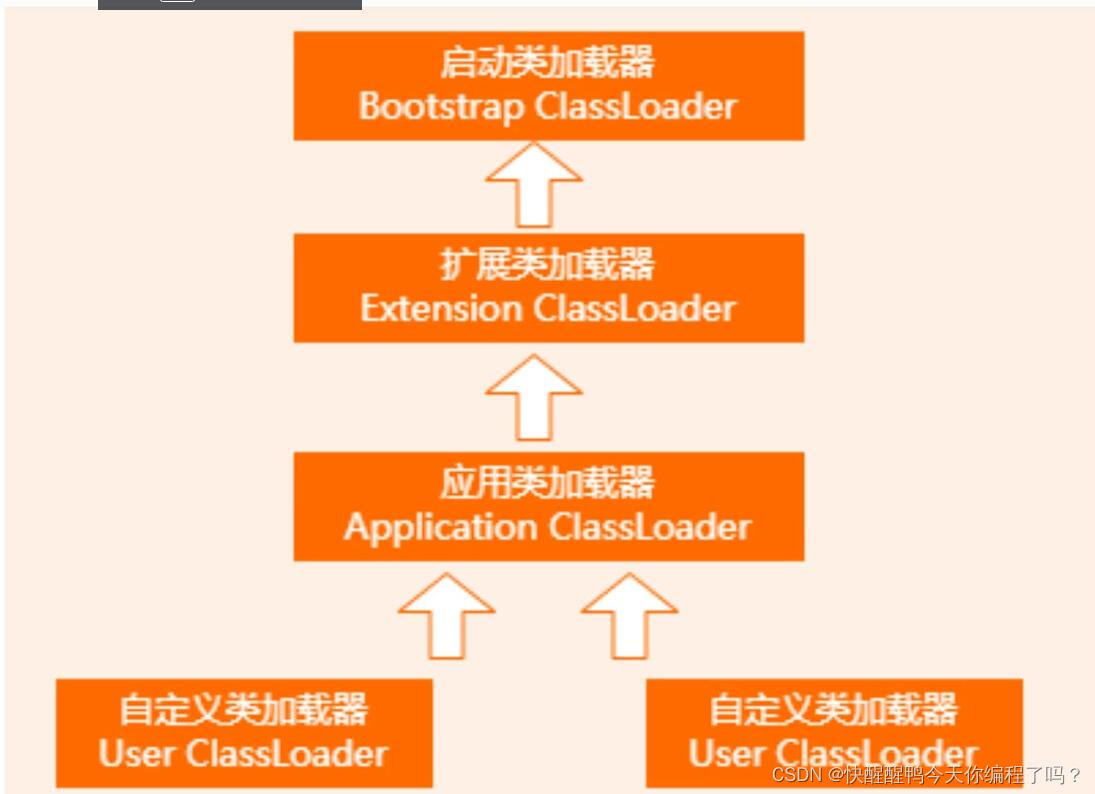
About the parental delegation mechanism and the process of class loading
随机推荐
fianl、finally、finalize三者的区别
简单理解ES6的Promise
【黑马早报】上海市监局回应钟薛高烧不化;麦趣尔承认两批次纯牛奶不合格;微信内测一个手机可注册俩号;度小满回应存款变理财产品...
Reinforcement learning series (I): basic principles and concepts
1143_ SiCp learning notes_ Tree recursion
6. Function recursion
[modern Chinese history] Chapter 6 test
5月14日杂谈
Beautified table style
渗透测试学习与实战阶段分析
Implementation principle of automatic capacity expansion mechanism of ArrayList
Redis实现分布式锁原理详解
【MySQL-表结构与完整性约束的修改(ALTER)】
Analysis of penetration test learning and actual combat stage
【educoder数据库实验 索引】
Cookie和Session的区别
7-8 7104 约瑟夫问题(PTA程序设计)
hashCode()与equals()之间的关系
Yugu p1012 spelling +p1019 word Solitaire (string)
Miscellaneous talk on May 27