当前位置:网站首页>Using transformer for object detection and semantic segmentation
Using transformer for object detection and semantic segmentation
2022-07-02 07:59:00 【MezereonXP】
Introduce
This time it's about Facebook AI An article from “End-to-End Object Detection with Transformers”
Just recently Transformer It's also popular , Here's how to use Transformer For object detection and semantic segmentation .
About Transformer, You can refer to my article article .
Let me briefly introduce Transformer, This is a model architecture for sequence to sequence modeling , It is widely used in natural language translation and other fields .Transformer Abandon the previous modeling of sequence RNN Form of network architecture , The attention mechanism is introduced , Achieved a good sequence modeling and transformation capabilities .
General structure and process

As shown in the figure above , It's mainly divided into two parts :
- Backbone: Mainly CNN, Used to extract advanced semantic features
- Encoder-Decoder: Make use of advanced semantic features and give target prediction
In more detail , The architecture is as follows
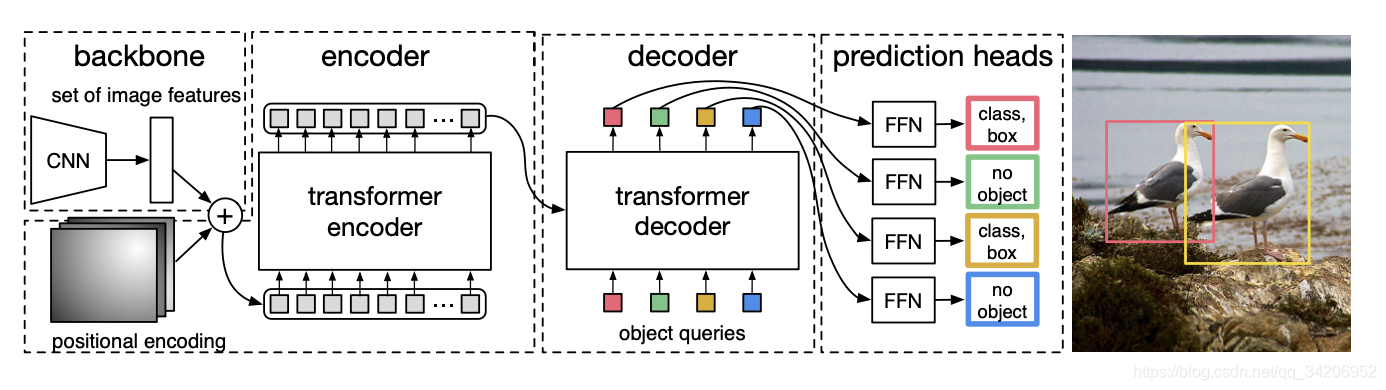
We give the process in sequence :
- Input picture , Shape is ( C 0 , H 0 , W 0 ) (C_0, H_0,W_0) (C0,H0,W0), among C 0 = 3 C_0 = 3 C0=3 Represents the number of channels
- CNN After feature extraction , obtain ( C , H , W ) (C,H,W) (C,H,W) The tensor of shape , among C = 2048 , H = H 0 32 , W = W 0 32 C=2048, H=\frac{H_0}{32}, W=\frac{W_0}{32} C=2048,H=32H0,W=32W0
- utilize 1x1 Convolution of , Reduce the size of the feature , obtain ( d , H , W ) (d, H, W) (d,H,W) Tensor , among d < < C d<< C d<<C
- Compress the tensor (squeeze), The shape becomes ( d , H W ) (d, HW) (d,HW)
- Got it d d d Vector sequence , Enter as a sequence into Encoder In
- Decoder Get the output vector sequence , adopt FFN(Feed Forward Network) Get the bounding box prediction and category prediction , among FFN It's simple 3 Layer perceptron , The bounding box prediction includes the normalized center coordinates and width and height .
The effect of target detection
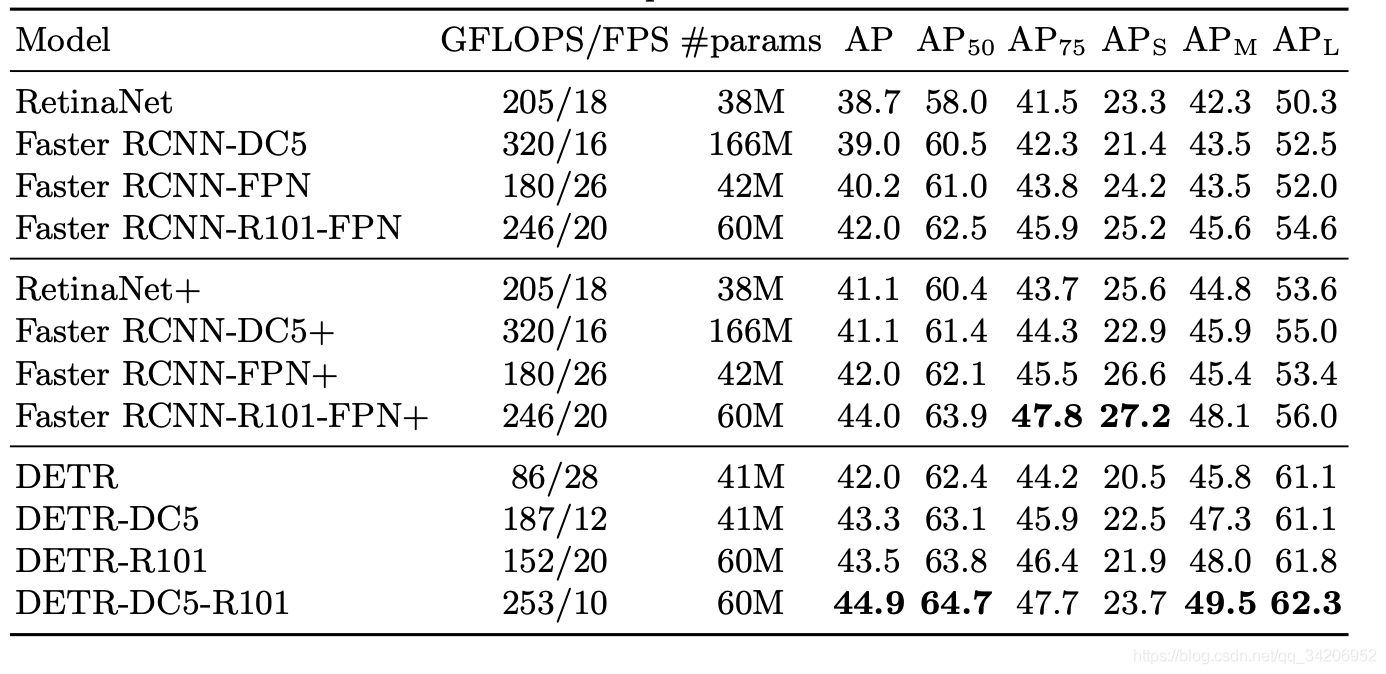
As shown in the figure above , You can see DETR It's not a lot of calculations , however FPS It's not high , It's just in order .
So semantic segmentation ?
Here is the general framework of semantic segmentation , As shown in the figure below :
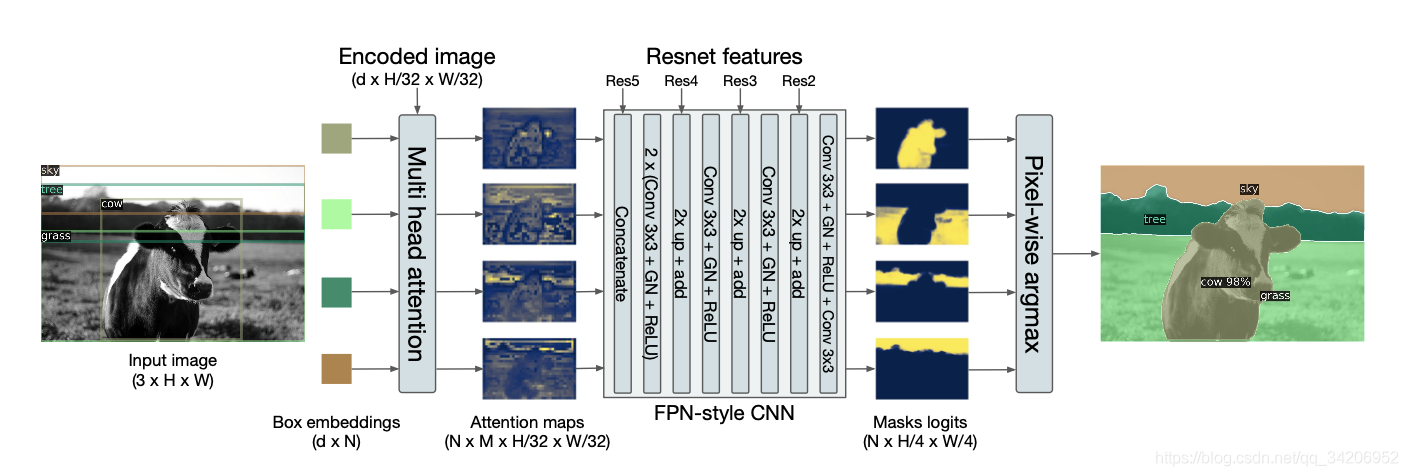
be aware , What's depicted in the picture , Bounding box embedding (Box Embedding) In essence decoder Output ( stay FFN Before ).
And then use a multi head attention mechanism , This mechanism is essentially right Q,K,V Do many linear transformations , In this ,K and V yes Encoder The input of ,Q yes decoder Output .
among M It's the number of heads for multi head attention .
after , Through a simple CNN, Get one Mask matrix , Used to generate the result of semantic segmentation .
Semantic segmentation results analysis
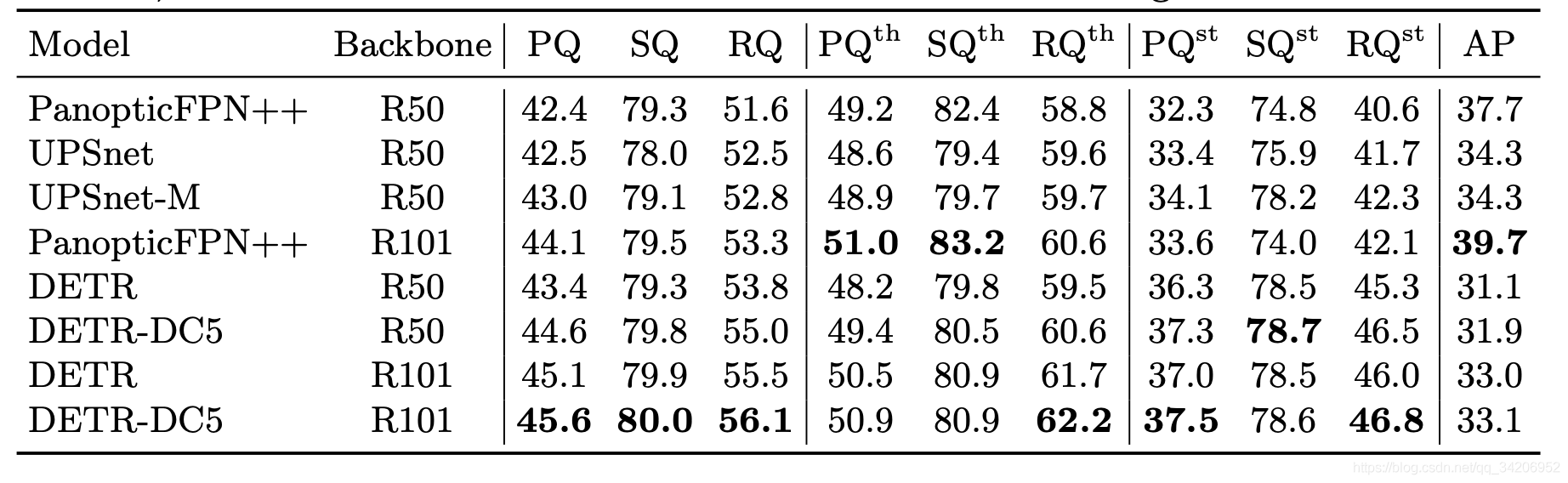
We can see that compared with PanopticFPN++ Come on , The improvement of effect is limited , especially AP It's not good , General performance .
Conclusion
The article will Transformer It is applied to the field of object detection and semantic segmentation , Good results have been achieved , But the performance is better than FastRCNN Architecture like approach , There is no obvious improvement , But it shows that this sequence model has good scalability . Using one architecture to solve multiple problems , The goal of a unified model is just around the corner .
边栏推荐
- Open3D学习笔记一【初窥门径,文件读取】
- Meta learning Brief
- Network metering - transport layer
- 【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》
- open3d学习笔记五【RGBD融合】
- SQL server如何卸载干净
- open3d学习笔记二【文件读写】
- Where do you find the materials for those articles that have read 10000?
- Income in the first month of naked resignation
- 针对语义分割的真实世界的对抗样本攻击
猜你喜欢

What if the laptop task manager is gray and unavailable
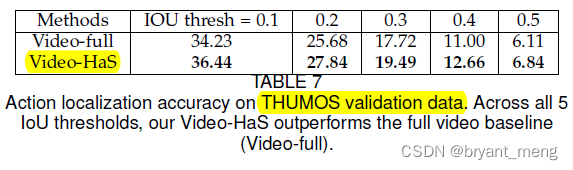
【Hide-and-Seek】《Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization xxx》

Semi supervised mixpatch

联邦学习下的数据逆向攻击 -- GradInversion
w10升级至W11系统,黑屏但鼠标与桌面快捷方式能用,如何解决
![[binocular vision] binocular correction](/img/fe/27fda48c36ca529eec21c631737526.png)
[binocular vision] binocular correction
![[learning notes] matlab self compiled Gaussian smoother +sobel operator derivation](/img/f1/4afde3a4bf01254b3e3ff8bc659f9c.png)
[learning notes] matlab self compiled Gaussian smoother +sobel operator derivation
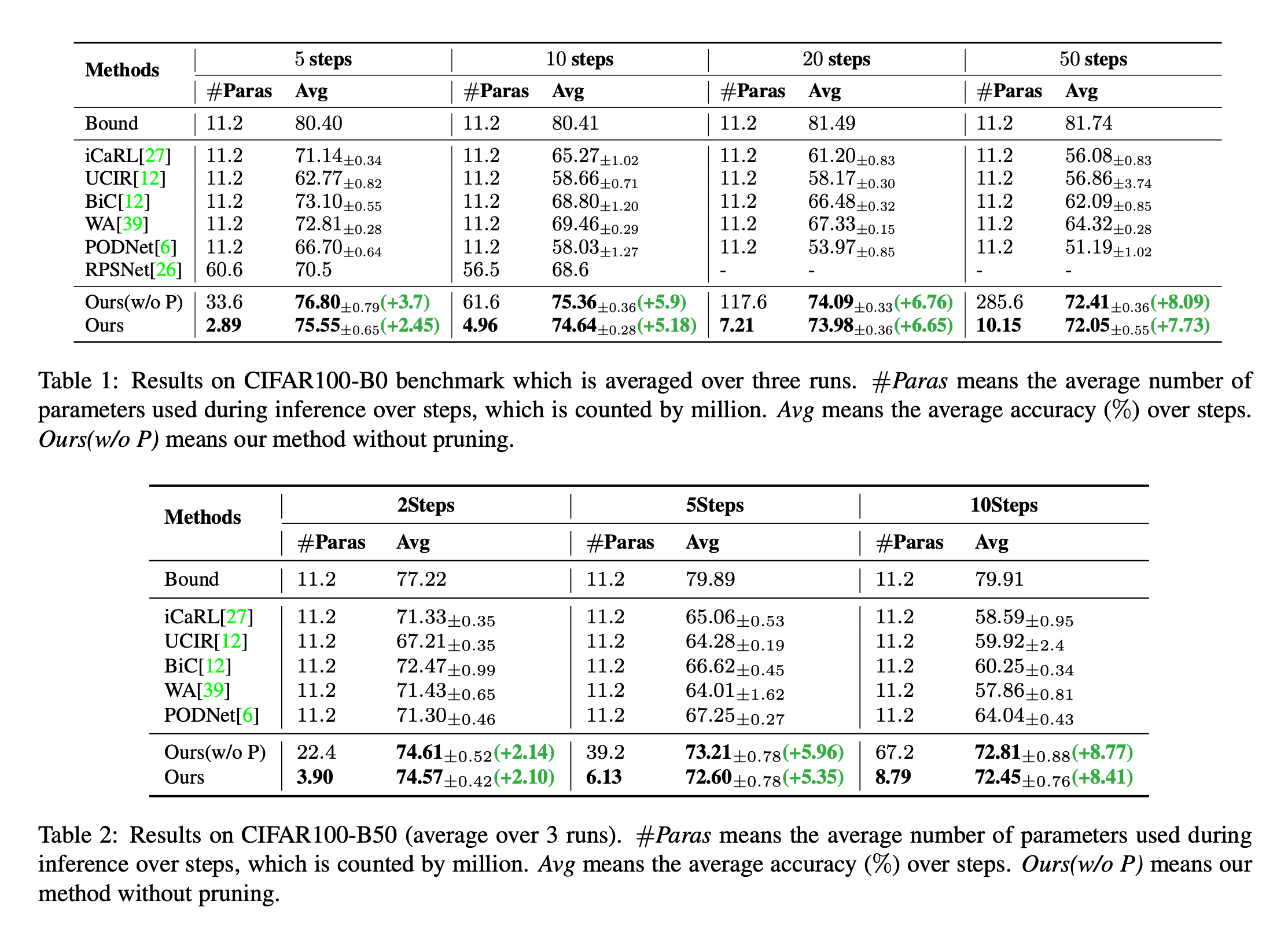
Dynamic extensible representation for category incremental learning -- der
用于类别增量学习的动态可扩展表征 -- DER

Network metering - transport layer
随机推荐
w10升级至W11系统,黑屏但鼠标与桌面快捷方式能用,如何解决
【Paper Reading】
JVM instructions
open3d学习笔记五【RGBD融合】
【TCDCN】《Facial landmark detection by deep multi-task learning》
In the era of short video, how to ensure that works are more popular?
AR system summary harvest
【Programming】
Jetson nano installation tensorflow stepping pit record (scipy1.4.1)
针对tqdm和print的顺序问题
Target detection for long tail distribution -- balanced group softmax
Embedding malware into neural networks
Replace self attention with MLP
Yolov3 trains its own data set (mmdetection)
[mixup] mixup: Beyond Imperial Risk Minimization
What if the laptop can't search the wireless network signal
【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》
One book 1078: sum of fractional sequences
解决jetson nano安装onnx错误(ERROR: Failed building wheel for onnx)总结
SQL server如何卸载干净