当前位置:网站首页>Kafka-connect将Kafka数据同步到Mysql
Kafka-connect将Kafka数据同步到Mysql
2022-07-07 23:23:00 【W_Meng_H】
一、背景信息
Kafka Connect主要用于将数据流输入和输出消息队列Kafka版。Kafka Connect主要通过各种Source Connector的实现,将数据从第三方系统输入到Kafka Broker,通过各种Sink Connector实现,将数据从Kafka Broker中导入到第三方系统。
官方文档:How to use Kafka Connect - Getting Started | Confluent Documentation
二、开发环境
| 中间件 | 版本 |
| zookeeper | 3.7.0 |
| kafka | 2.10-0.10.2.1 |
三、配置Kafka Connect
1、进到kafka的config文件夹下,修改connect-standalone.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# These are defaults. This file just demonstrates how to override some settings.
bootstrap.servers=kafka-0:9092
# The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will
# need to configure these based on the format they want their data in when loaded from or stored into Kafka
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# Converter-specific settings can be passed in by prefixing the Converter's setting with the converter we want to apply
# it to
key.converter.schemas.enable=false
value.converter.schemas.enable=false
# The internal converter used for offsets and config data is configurable and must be specified, but most users will
# always want to use the built-in default. Offset and config data is never visible outside of Kafka Connect in this format.
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.storage.file.filename=/tmp/connect.offsets
# Flush much faster than normal, which is useful for testing/debugging
offset.flush.interval.ms=10000
# 核心配置
#plugin.path=/home/kafka/plugins如果Mysql数据同步到Kafka,需要修改如下信息:
# The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will
# need to configure these based on the format they want their data in when loaded from or stored into Kafka
key.converter=io.confluent.connect.json.JsonSchemaConverter
value.converter=io.confluent.connect.json.JsonSchemaConverter
# Converter-specific settings can be passed in by prefixing the Converter's setting with the converter we want to apply
# it to
key.converter.schemas.enable=true
value.converter.schemas.enable=true注意:Kafka Connect的早期版本不支持配置plugin.path,您需要在CLASSPATH中指定插件位置
vi /etc/profile
export CLASSPATH=/home/kafka/*
source /etc/profile2、修改connect-mysql-source.properties(mysql-kafka)
#
# Copyright 2018 Confluent Inc.
#
# Licensed under the Confluent Community License (the "License"); you may not use
# this file except in compliance with the License. You may obtain a copy of the
# License at
#
# http://www.confluent.io/confluent-community-license
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OF ANY KIND, either express or implied. See the License for the
# specific language governing permissions and limitations under the License.
#
# A simple example that copies all tables from a SQLite database. The first few settings are
# required for all connectors: a name, the connector class to run, and the maximum number of
# tasks to create:
name=test-source-mysql
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
# The remaining configs are specific to the JDBC source connector. In this example, we connect to a
# SQLite database stored in the file test.db, use and auto-incrementing column called 'id' to
# detect new rows as they are added, and output to topics prefixed with 'test-sqlite-jdbc-', e.g.
# a table called 'users' will be written to the topic 'test-sqlite-jdbc-users'.
connection.url=jdbc:mysql://localhost:3306/demo?user=root&password=root
table.whitelist=test
mode=incrementing
incrementing.column.name=id
topic.prefix=mysql-
# Define when identifiers should be quoted in DDL and DML statements.
# The default is 'always' to maintain backward compatibility with prior versions.
# Set this to 'never' to avoid quoting fully-qualified or simple table and column names.
#quote.sql.identifiers=always
相关驱动jar包:
3、修改connect-mysql-sink.properties(kafka-mysql)
#
# Copyright 2018 Confluent Inc.
#
# Licensed under the Confluent Community License (the "License"); you may not use
# this file except in compliance with the License. You may obtain a copy of the
# License at
#
# http://www.confluent.io/confluent-community-license
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OF ANY KIND, either express or implied. See the License for the
# specific language governing permissions and limitations under the License.
#
# A simple example that copies from a topic to a SQLite database.
# The first few settings are required for all connectors:
# a name, the connector class to run, and the maximum number of tasks to create:
name=test-sink
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
tasks.max=1
# The topics to consume from - required for sink connectors like this one
topics=mysql-test_to_kafka
# Configuration specific to the JDBC sink connector.
# We want to connect to a SQLite database stored in the file test.db and auto-create tables.
connection.url=jdbc:mysql://localhost:3306/demo?user=root&password=root
auto.create=false
pk.mode=record_value
pk.fields=id
table.name.format=test_kafka_to
#delete.enabled=true
# 写入模式
insert.mode=upsert
# Define when identifiers should be quoted in DDL and DML statements.
# The default is 'always' to maintain backward compatibility with prior versions.
# Set this to 'never' to avoid quoting fully-qualified or simple table and column names.
#quote.sql.identifiers=always
四、启动命令
bin/connect-standalone.sh config/connect-standalone.properties config/connect-mysql-source.properties config/connect-mysql-sink.properties边栏推荐
- How to write mark down on vscode
- On the concept and application of filtering in radar signal processing
- 基础篇——整合第三方技术
- Frequency probability and Bayesian probability
- 6. Dropout application
- String usage in C #
- 133. 克隆图
- 2022 low voltage electrician examination content and low voltage electrician simulation examination question bank
- HDMI to VGA acquisition HD adapter scheme | HDMI to VGA 1080p audio and video converter scheme | cs5210 scheme design explanation
- 利用GPU训练网络模型
猜你喜欢
General configuration toolbox
2022 chemical automation control instrument examination summary and chemical automation control instrument simulation examination questions

How to use education discounts to open Apple Music members for 5 yuan / month and realize member sharing
4、策略學習
Basic implementation of pie chart
A speed Limited large file transmission tool for every major network disk

Blue Bridge Cup embedded (F103) -1 STM32 clock operation and led operation method
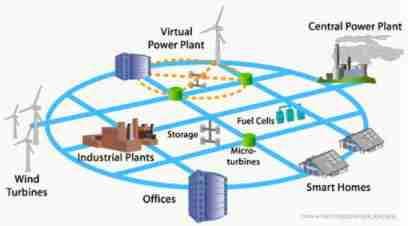
Smart grid overview
High quality USB sound card / audio chip sss1700 | sss1700 design 96 kHz 24 bit sampling rate USB headset microphone scheme | sss1700 Chinese design scheme explanation
Y59. Chapter III kubernetes from entry to proficiency - continuous integration and deployment (III, II)
随机推荐
Cs5212an design display to VGA HD adapter products | display to VGA Hd 1080p adapter products
1. Linear regression
The Ministry of housing and urban rural development officially issued the technical standard for urban information model (CIM) basic platform, which will be implemented from June 1
Two methods for full screen adaptation of background pictures, background size: cover; Or (background size: 100% 100%;)
Design method and application of ag9311maq and ag9311mcq in USB type-C docking station or converter
14. Draw network model structure
2021 tea master (primary) examination materials and tea master (primary) simulation test questions
Su embedded training - Day7
How to use education discounts to open Apple Music members for 5 yuan / month and realize member sharing
How to get the first and last days of a given month
Chapter VIII integrated learning
解决报错:npm WARN config global `--global`, `--local` are deprecated. Use `--location=global` instead.
Get started quickly using the local testing tool postman
Su embedded training - Day8
Basic realization of line chart (II)
6. Dropout application
Ag9310meq ag9310mfq angle two USB type C to HDMI audio and video data conversion function chips parameter difference and design circuit reference
Blue Bridge Cup embedded (F103) -1 STM32 clock operation and led operation method
How to write mark down on vscode
Y59. Chapter III kubernetes from entry to proficiency - continuous integration and deployment (III, II)