当前位置:网站首页>Multi site high availability deployment
Multi site high availability deployment
2022-07-02 08:04:00 【Kun Yu】
When a cluster spans multiple sites , Network connection problems between sites may lead to brain splitting . When the connection is disconnected , A node at one site cannot determine whether a node at another site has failed or is still operating with the failed site interconnect . Besides , Providing high availability services between two sites that are too far apart to be synchronized may cause problems . To solve these problems ,Pacemaker By using Booth Cluster ticket manager , Fully support the ability to configure high availability clusters across multiple sites .
Booth Overview of cluster ticket manager
Booth Ticket manager is a distributed service , It is designed to run on a physical network different from the network connecting the cluster nodes of a specific site . It produces another loose cluster , namely Booth structure , Located on the regular cluster of the site . This aggregated communication layer facilitates the consensus based decision-making process for individual booth tickets .
Booth The ticket is Booth A single example in the structure , Represents a time sensitive 、 Mobile authorization unit . Resources can be configured to require specific tickets to run . This ensures that resources run on only one site at a time , And one or more tickets have been granted .
You can use Booth The structure is regarded as an overlay cluster composed of clusters running at different sites , All the original clusters are independent of each other . yes Booth Services communicate with the cluster whether they have obtained tickets , And is Pacemaker according to Pacemaker Ticket constraints determine whether resources run in the cluster . This means that when using the ticket manager , Each cluster can run its own resources and share resources . for example , There can be resources A、B and C Run in only one cluster , resources D、E and F Run only in another cluster , And resources G and H Run in either of the two clusters , Determined by ticket .
Use Pacemaker Configure a multi site cluster
Five machines are expected ( It depends on the actual situation ), Cluster one and cluster two need two machines respectively ,Booth Site ( Arbitration node ) You need a machine , And these five machines are installed HA Installation package .
1. Create clusters
Cluster one ( Main cluster ) Include cluster1-node1 and cluster1-node2, Cluster 2 ( Standby cluster ) Include cluster2-node1 and cluster2-node2.
explain :
The names of the two clusters should not be the same , For testing purposes, the firewall of these five machines can be closed , If it is used in the actual project, it should be determined according to the actual situation .
2. install Booth Ticket manager package
Install on each node of both clusters booth-core And booth-site
Booth Site installation booth-core And booth-arbitrator
3. establish Booth To configure
[cluster1-node1 ~] # pcs booth setup sites 192.168.11.100 192.168.22.100 arbitrators 192.168.99.100
This command creates a configuration file /etc/booth/booth.conf And /etc/booth/booth.key file .
Create on a node of one of the clusters Booth To configure ( Such as cluster one cluster1-node1 node )
4. Create ticket (ticket)
[cluster1-node1 ~] # pcs booth ticket add superticket
by Booth Configure create ticket (superticket Custom ticket name ). This is the ticket you will use to define resource constraints , This restriction will allow resources to run only when this ticket is granted to the cluster .
explain :
After adding ticket constraint , All node resources of the two clusters are changed to the stopped state ( Refer to the following constraints ), If be in, cluster1-node1 Create ticket ,cluster1-node1 The resources in the cluster can be started normally ( Usually, tickets are created for only one node in all clusters , When this node is abnormal or the cluster in which this node is located is abnormal ( Two cluster machines shut down ), Resources will be started on another node or a node in another cluster ).
5. Configuration synchronization
[cluster1-node1 ~] # pcs booth sync
take Booth Configure synchronization to all nodes in the current cluster
[ Arbitration node ~] # pcs host auth cluster1-node1
[ Arbitration node ~] # pcs booth pull cluster1-node1
take Booth Configure the sending arbitration node
[cluster2-node1 ~] # pcs host auth cluster1-node1
[cluster2-node1 ~] # pcs booth pull cluster1-node1
[cluster2-node1 ~] # pcs booth sync
take Booth Configure to send another cluster and synchronize to all nodes of the cluster
6. Start and enable at the arbitration node Booth
[ Arbitration node ~] # pcs booth start
[ Arbitration node ~] # pcs booth enable
take Booth It is configured to run as a cluster resource on two cluster sites . This will create a resource group ,booth-ip And booth-service As a member of this group .
Do not manually start or enable on any node of the cluster Booth, because Booth In these clusters as Pacemaker Resource operation .
7. Create floats for each cluster IP( fictitious IP)
[cluster1-node1 ~] # pcs booth create ip 192.168.11.100
[cluster2-node1 ~] # pcs booth create ip 192.168.22.100
Create on one of the nodes of each cluster Booth float IP( Use 《3. establish Booth To configure 》 Medium IP)
8. Add ticket constraints
[cluster1-node1 ~] # pcs constraint ticket add superticket newgroup
[cluster2-node1 ~] # pcs constraint ticket add superticket newgroup
Add ticket constraints to the resource groups you define for each cluster .
9. Commonly used instructions
[cluster1-node1 ~] # pcs constraint ticket
View ticket group name
[cluster1-node1 ~] # pcs booth config
View ticket group information
[cluster1-node1 ~] # pcs booth status
see booth Communication status between nodes
[cluster1-node1 ~] # pcs booth ticket grant superticket
Ticket authorization at a node ( After adding constraints , Start the resources in the node through ticket authorization )
边栏推荐
- 联邦学习下的数据逆向攻击 -- GradInversion
- 【MagNet】《Progressive Semantic Segmentation》
- Open3d learning notes II [file reading and writing]
- Data reverse attack under federated learning -- gradinversion
- Open3d learning note 4 [surface reconstruction]
- 利用Transformer来进行目标检测和语义分割
- Jetson nano installation tensorflow stepping pit record (scipy1.4.1)
- Nacos service registration in the interface
- 力扣方法总结:滑动窗口
- Summary of solving the Jetson nano installation onnx error (error: failed building wheel for onnx)
猜你喜欢
![Open3d learning notes 1 [first glimpse, file reading]](/img/68/68ea87817dbf788591216a32c9375b.png)
Open3d learning notes 1 [first glimpse, file reading]
How to back up the configuration before the idea when reinstalling the idea
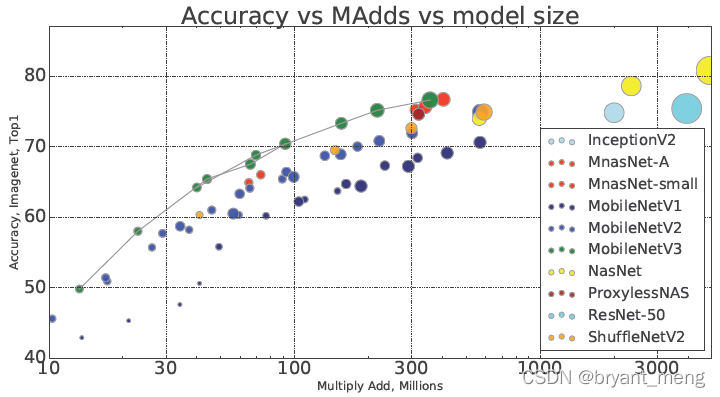
【MobileNet V3】《Searching for MobileNetV3》
OpenCV3 6.3 用滤波器进行缩减像素采样
Jetson nano installation tensorflow stepping pit record (scipy1.4.1)
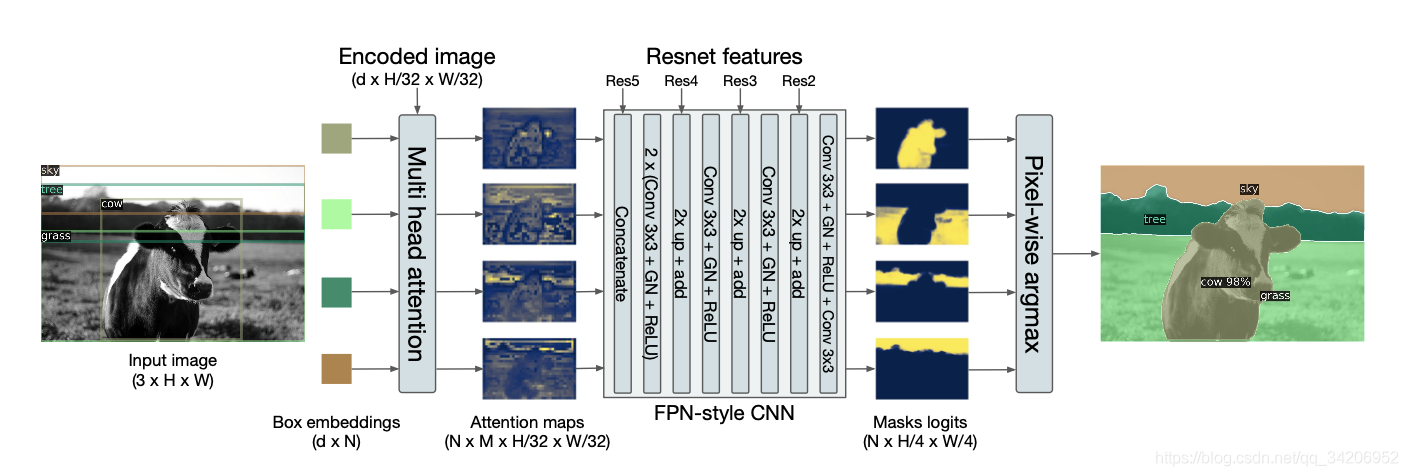
Using transformer for object detection and semantic segmentation
简易打包工具的安装与使用
利用Transformer来进行目标检测和语义分割

【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》

Specification for package drawing
随机推荐
It's great to save 10000 pictures of girls
Media query usage
[C # note] the data in DataGridView saved in WinForm is excel and CSV
Open3d learning notes 1 [first glimpse, file reading]
Global and Chinese market of recovery equipment 2022-2028: Research Report on technology, participants, trends, market size and share
Get the width and height of the screen in real time (adaptive)
C#与MySQL数据库连接
Daily practice (19): print binary tree from top to bottom
C语言实现XML生成解析库(XML扩展)
How to turn on night mode on laptop
Eklavya -- infer the parameters of functions in binary files using neural network
Summary of open3d environment errors
乐理基础(简述)
Global and Chinese market of medicine cabinet 2022-2028: Research Report on technology, participants, trends, market size and share
静态库和动态库
[Sparse to Dense] Sparse to Dense: Depth Prediction from Sparse Depth samples and a Single Image
解决jetson nano安装onnx错误(ERROR: Failed building wheel for onnx)总结
【Cutout】《Improved Regularization of Convolutional Neural Networks with Cutout》
Array and string processing, common status codes, differences between PHP and JS (JS)
利用Transformer来进行目标检测和语义分割