当前位置:网站首页>2、TD+Learning
2、TD+Learning
2022-07-08 01:26:00 【C--G】
Discounted Return
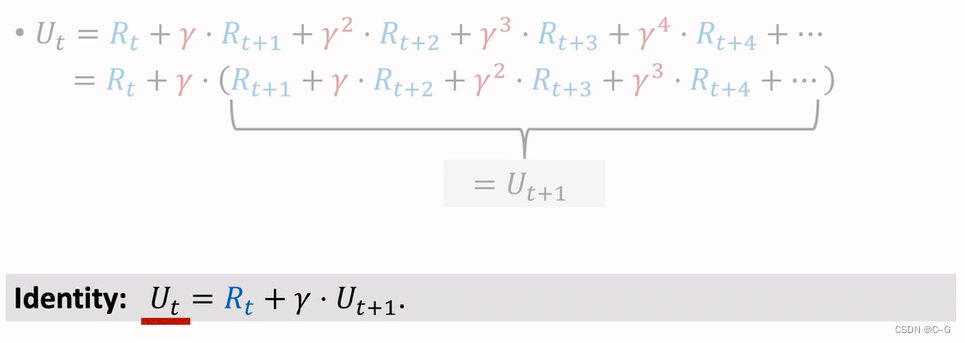


Sarsa
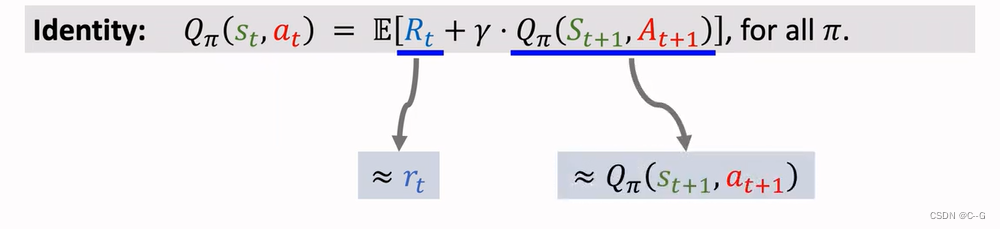
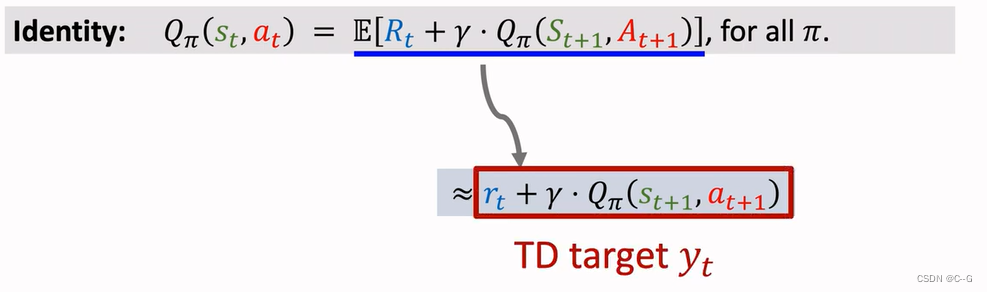
TD Algorithm , Used to learn the action value function QΠ
Sarsa:Tabular Version


Sarsa’s Name
Table status Sarsa Applicable to less States and actions , As the state and action increase , It is difficult to learn when the table is enlarged
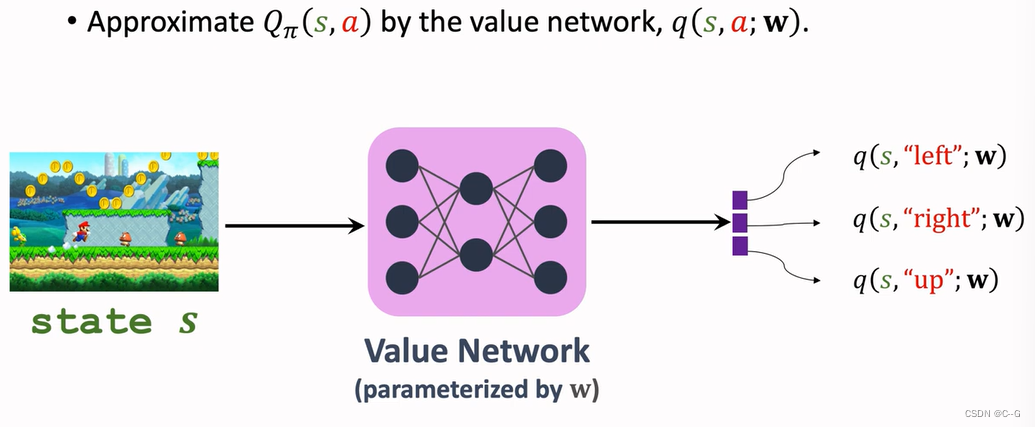
Sarsa:Neural Network Version



Q-Learning
TD Algorithm , Learn the optimal action Algorithm
Sarsa And Q-Learning

Derive TD Target


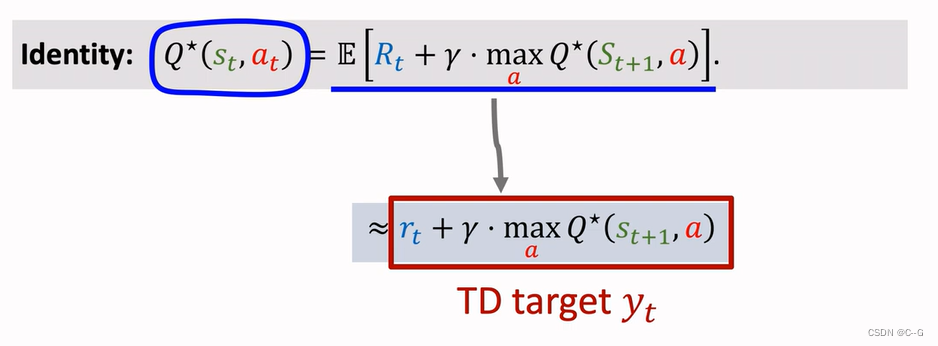
Q-Learning(tabular version)
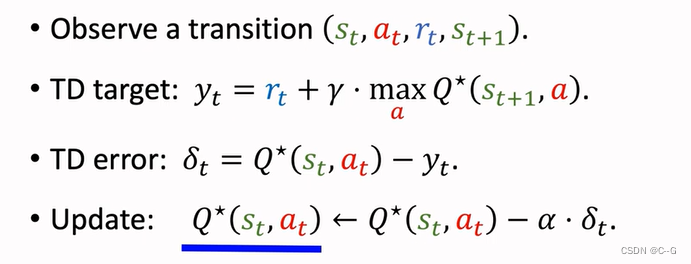
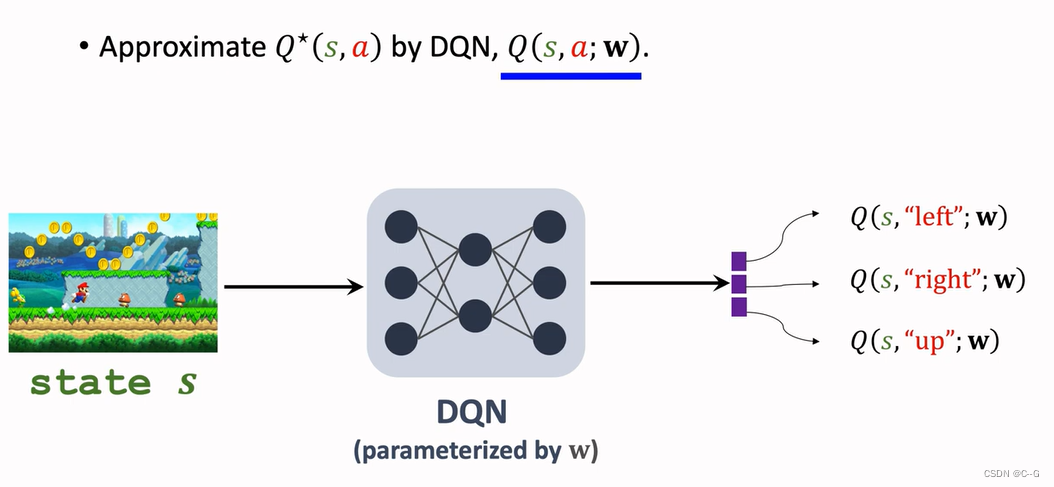
Q-Learning(DQN Version)

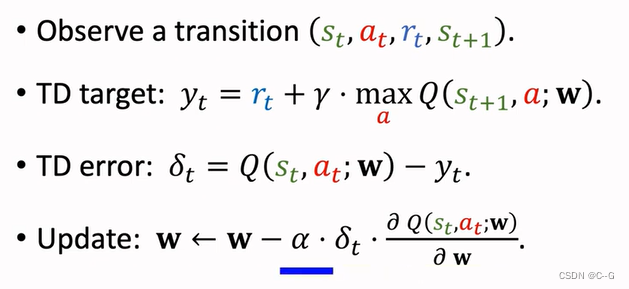

Multi-Setp TD Target
- Using One Reward

- Using Multiple Rewards

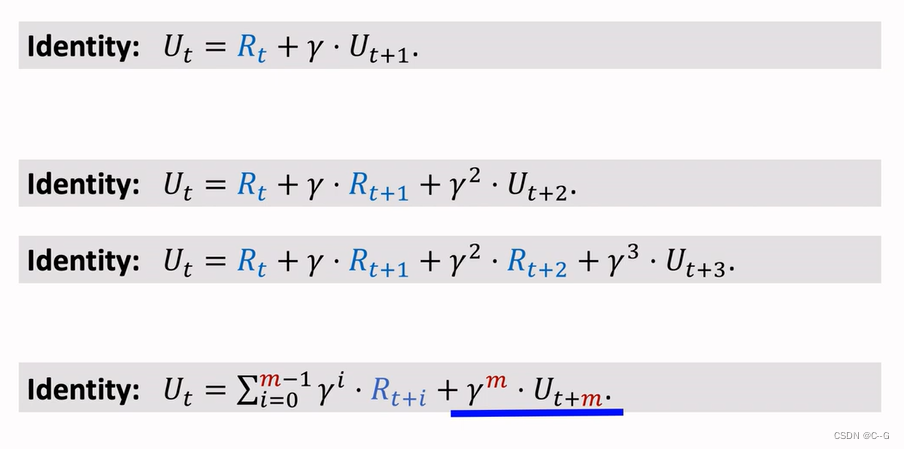



Value playback (Revisiting DQN and TD Learning)
- Shortcoming 1:Waste of Experience

- Shortcoming2:Correlated Updates

- Experience playback
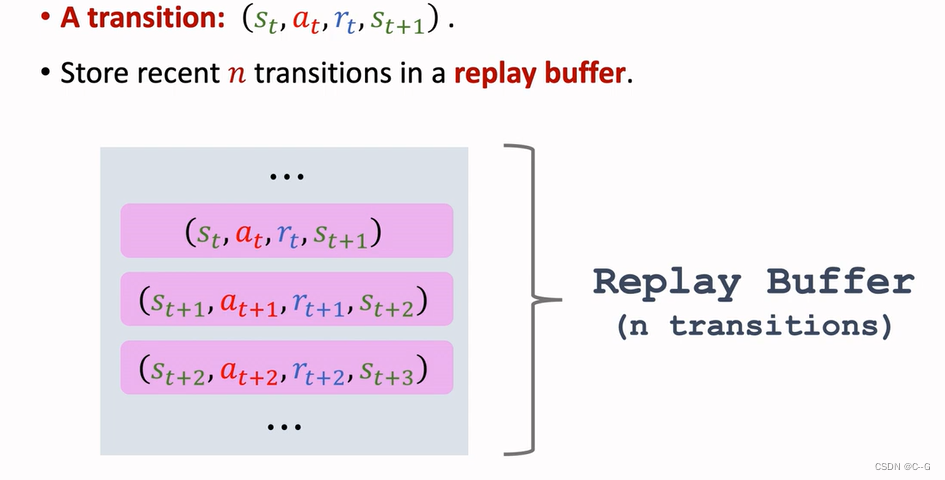



- History

Prioritized Experience Replay



On the left is a common scene of Mario , On the right is boos Off scene , Relative to the left , The right side is more rare , Therefore, we should increase the weight of the scene on the right ,TD error The bigger it is , Then the more important the scene is 

The learning rate of random gradient descent should be adjusted according to the importance of sampling 


Of a sample TD The bigger it is , Then the greater the sampling weight , The lower the learning rate
Overestimation problem
Bootstrapping: Bootstrap problem , Pull your shoes and lift yourself up
Similar to the method of stepping on the right foot with the left foot , It doesn't exist in reality , There exist in reinforcement learning 

Problem of Overestimation

- Reason 1:Maximization


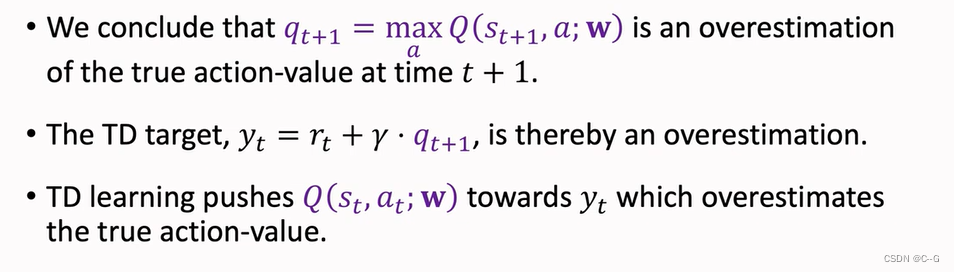
- Reason 2:Bootstrapping

- Why does overestimation happen
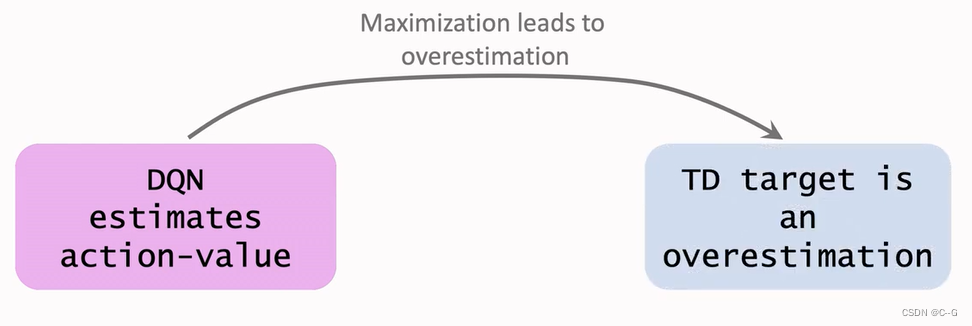

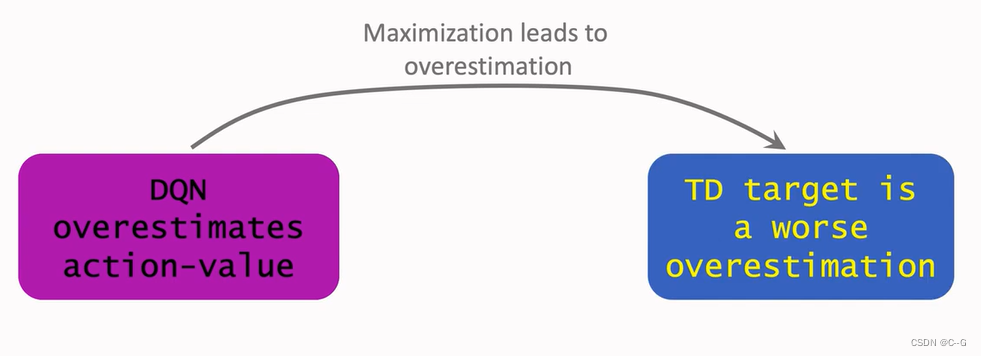

- Why overestimation is a shortcoming
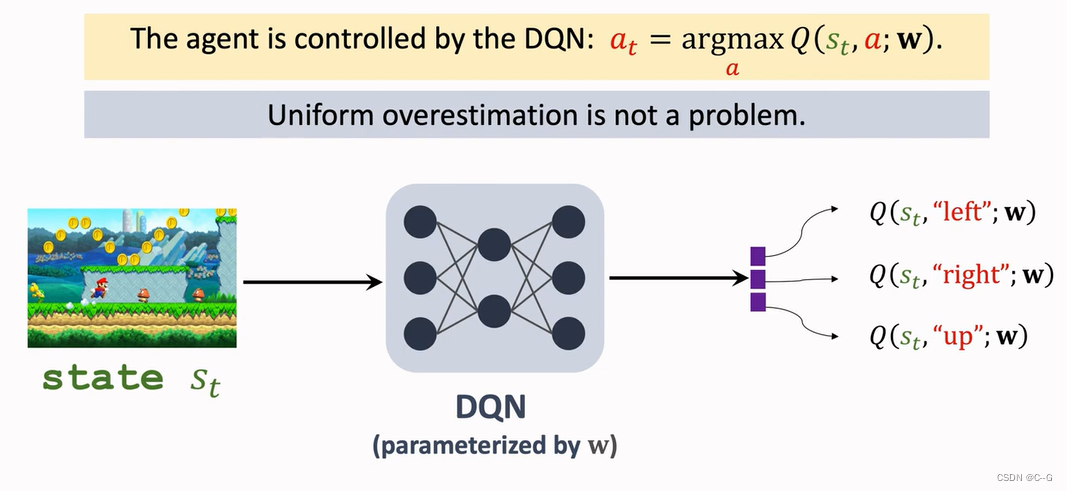



- Solutions

Target Network

TD Learning with Target Network
Update Target Network
Comparisons
Target Network Although a little better , But we still cannot get rid of the problem of overestimation
Double DQN
Naive Update

Using Target Network

Double DQN

Why does Double DQN work better
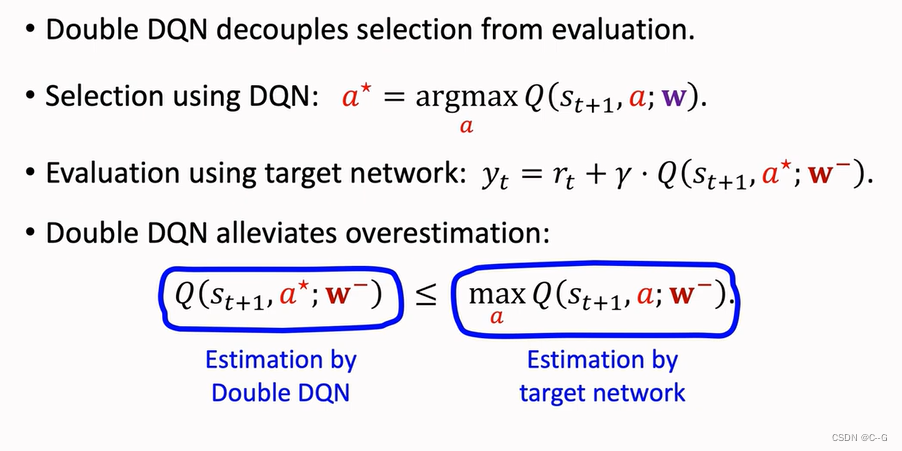
Dueling Network
Advantage Function( Dominance function )
Value Functions

Optimal Value Functions

Properties of Advantage Function

Dueling Network

Revisiting DQN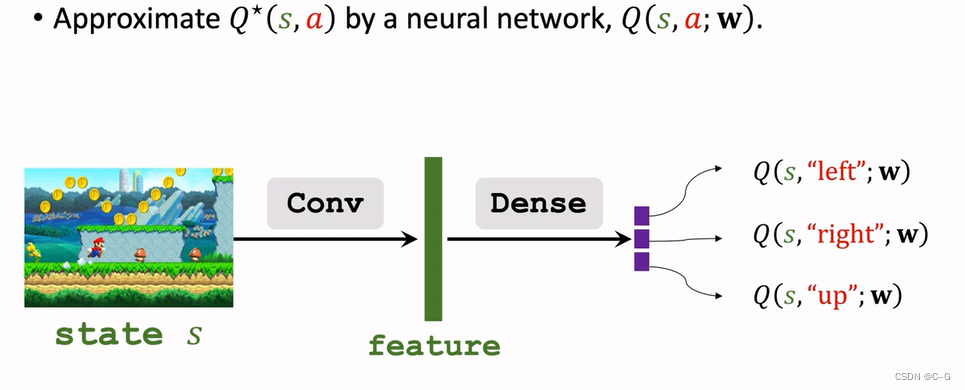
Approximating Advantage Function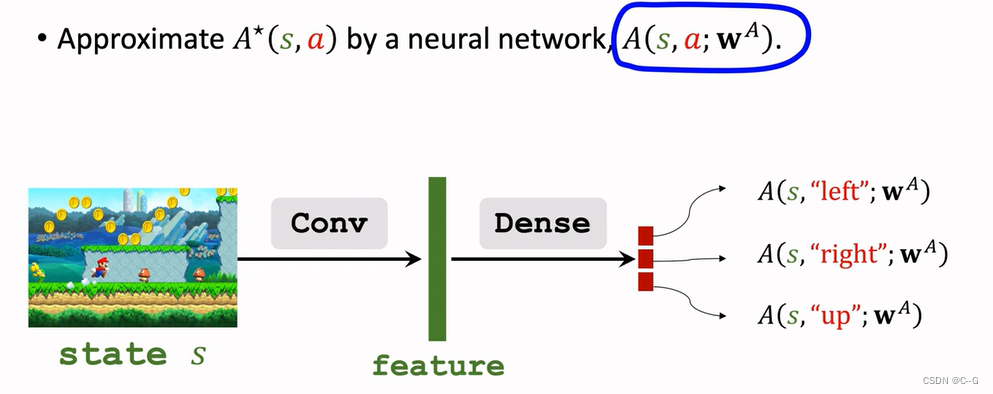
Approximating State-Value Function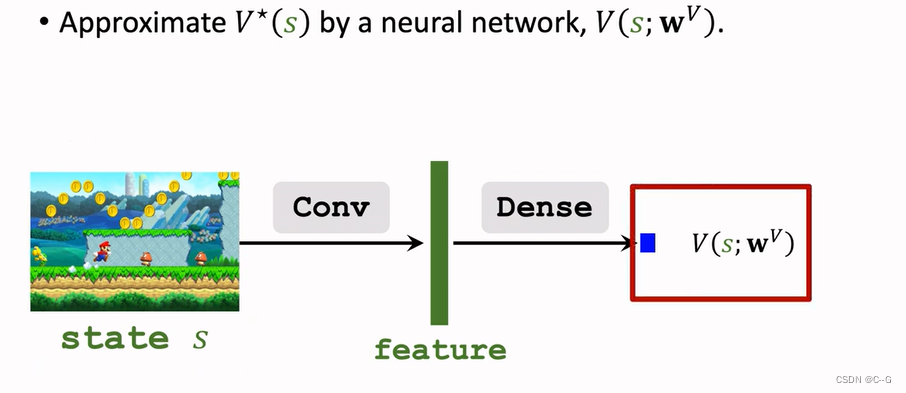
Dueling Network:Formulation
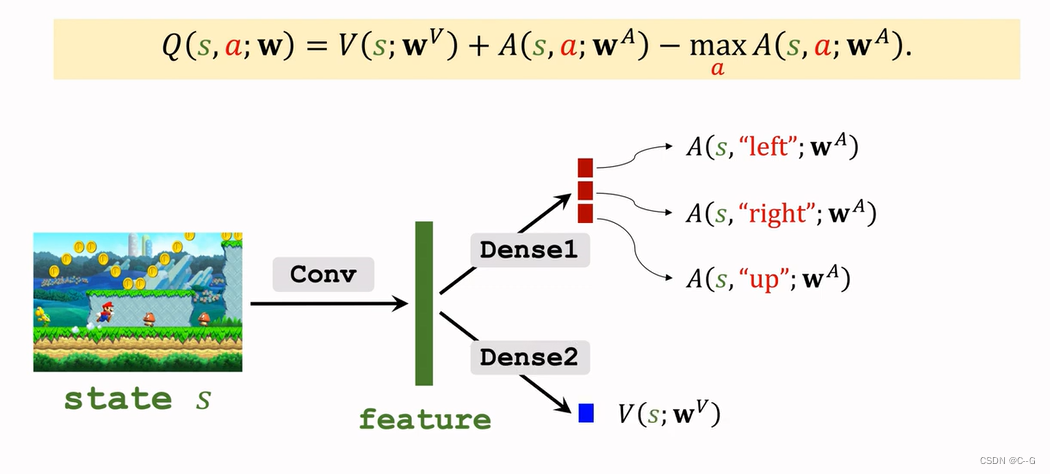
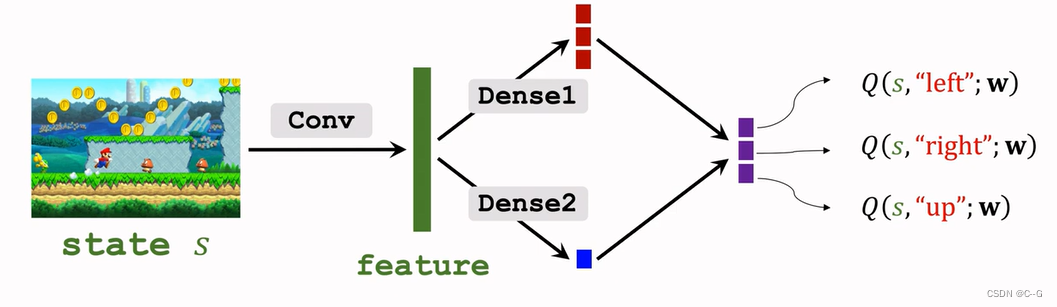
Blue plus red and then subtract the maximum value of red to get purple finally Dueling Network Output 
Problem of Non-identifiability


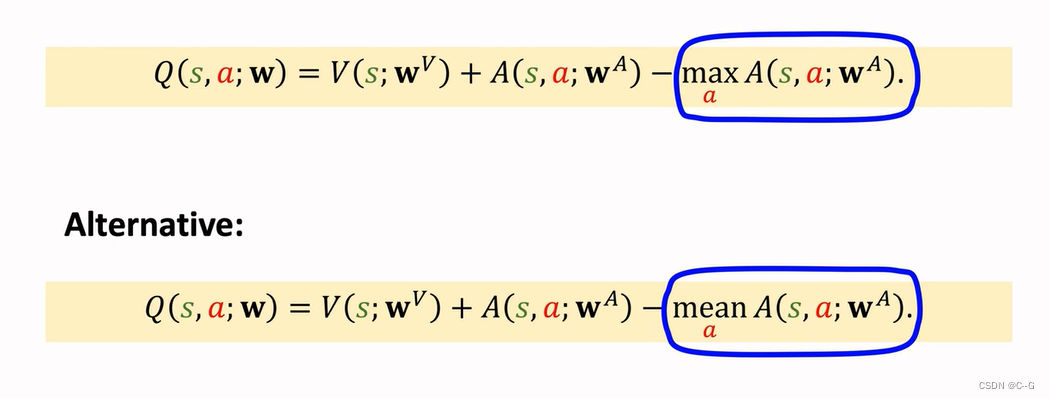
边栏推荐
- Gnuradio3.9.4 create OOT module instances
- 2、TD+Learning
- 2021 Shanghai safety officer C certificate examination registration and analysis of Shanghai safety officer C certificate search
- 2021-03-14 - play with generics
- Swift get URL parameters
- Problems of font legend and time scale display of MATLAB drawing coordinate axis
- Blue Bridge Cup embedded (F103) -1 STM32 clock operation and led operation method
- 5、離散控制與連續控制
- 5. Contrôle discret et contrôle continu
- npm 内部拆分模块
猜你喜欢
3. MNIST dataset classification

2021 tea master (primary) examination materials and tea master (primary) simulation test questions
Kuntai ch7511b scheme design | ch7511b design EDP to LVDS data | pin to pin replaces ch7511b circuit design
Recommend a document management tool mendely Reference Manager
Vs code configuration latex environment nanny level configuration tutorial (dual system)

2022 high voltage electrician examination skills and high voltage electrician reexamination examination

Gnuradio3.9.4 create OOT module instances
EDP to LVDS conversion design circuit | EDP to LVDS adapter board circuit | capstone/cs5211 chip circuit schematic reference
11. Recurrent neural network RNN
USB type-C docking design | design USB type-C docking scheme | USB type-C docking circuit reference
随机推荐
Generic configuration legend
Recommend a document management tool mendely Reference Manager
EDP to LVDS conversion design circuit | EDP to LVDS adapter board circuit | capstone/cs5211 chip circuit schematic reference
5. Over fitting, dropout, regularization
Kuntai ch7511b scheme design | ch7511b design EDP to LVDS data | pin to pin replaces ch7511b circuit design
npm 内部拆分模块
Saving and reading of network model
4、策略学习
Understanding of expectation, variance, covariance and correlation coefficient
Design method and reference circuit of type C to hdmi+ PD + BB + usb3.1 hub (rj45/cf/tf/ sd/ multi port usb3.1 type-A) multifunctional expansion dock
Four digit nixie tube display multi digit timing
[deep learning] AI one click to change the sky
4. Strategic Learning
General configuration title
Study notes of single chip microcomputer and embedded system
How to get the first and last days of a given month
5、離散控制與連續控制
11. Recurrent neural network RNN
Solve the error: NPM warn config global ` --global`, `--local` are deprecated Use `--location=global` instead.
2022 low voltage electrician examination content and low voltage electrician simulation examination question bank