当前位置:网站首页>4. Strategic Learning
4. Strategic Learning
2022-07-08 01:14:00 【C--G】
Policy Gradient with Baseline
Policy Gradient
- BaseLine


- Monte Carlo Approximation



- Choices of Baselines
Choice 1: b=0
**Choice 2:b is state-value **
- b = VΠ(St)




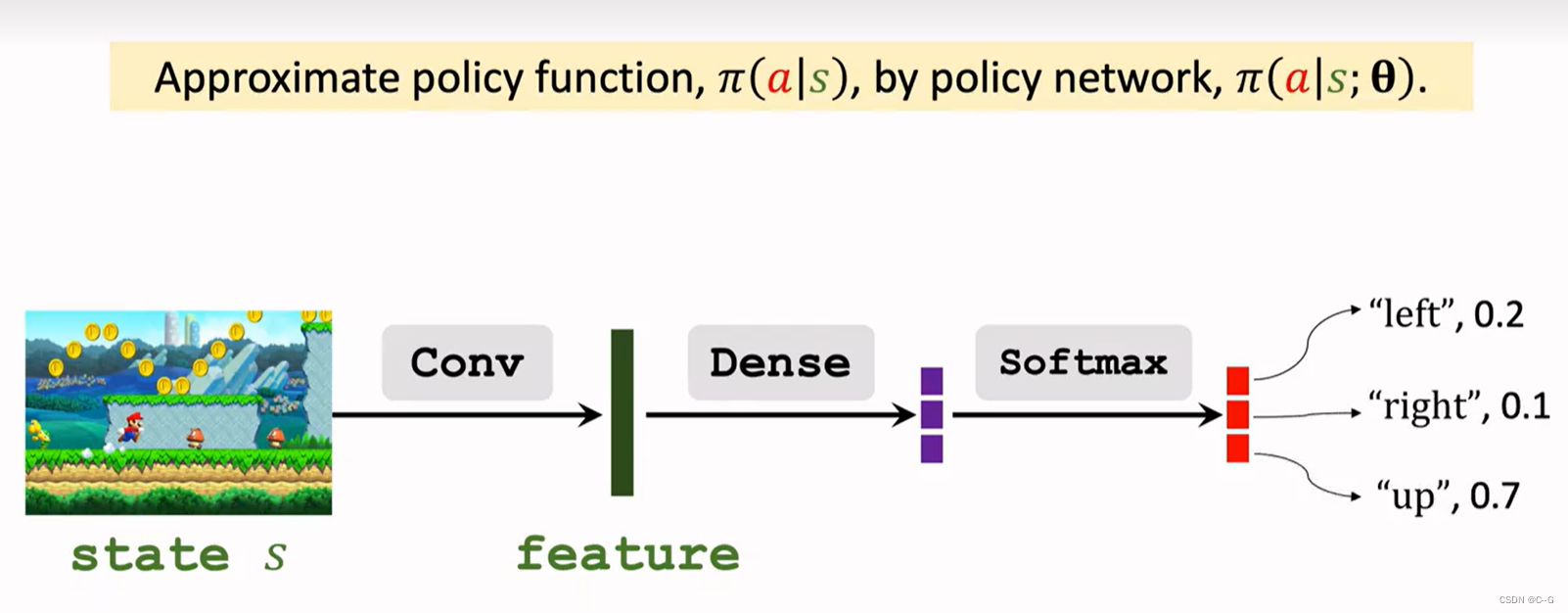
- Policy Network
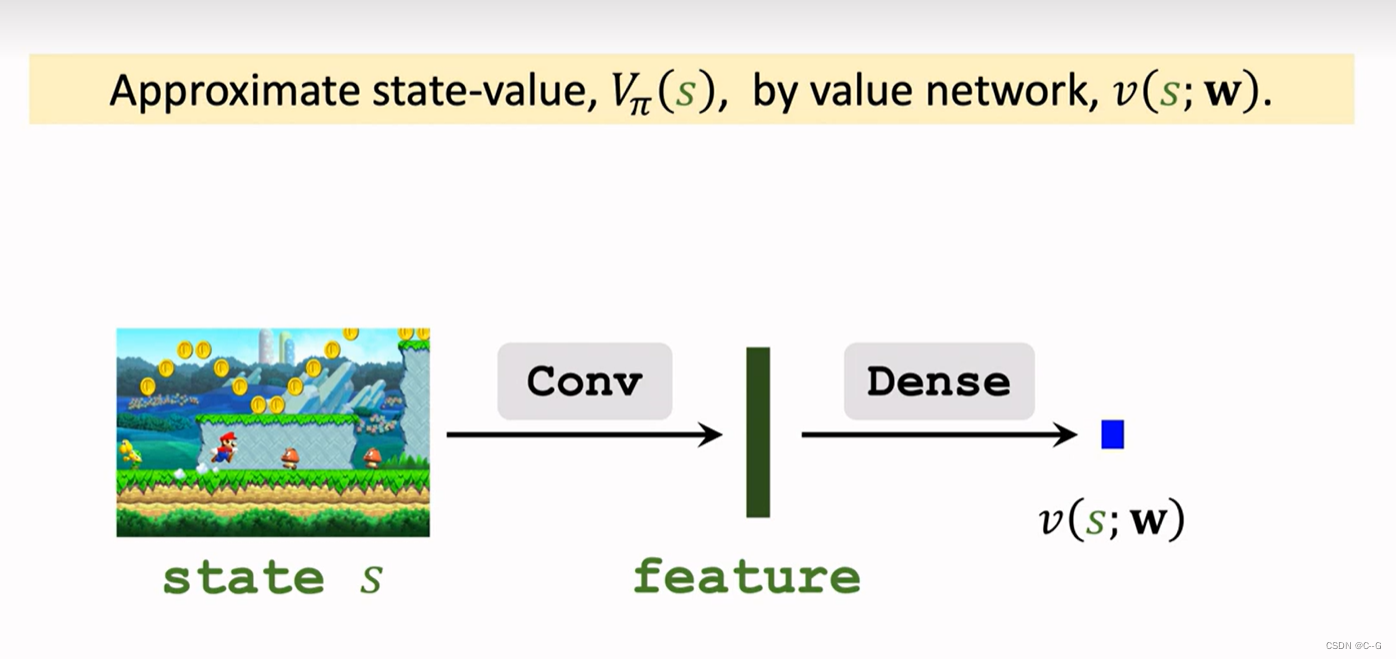
- Value Network
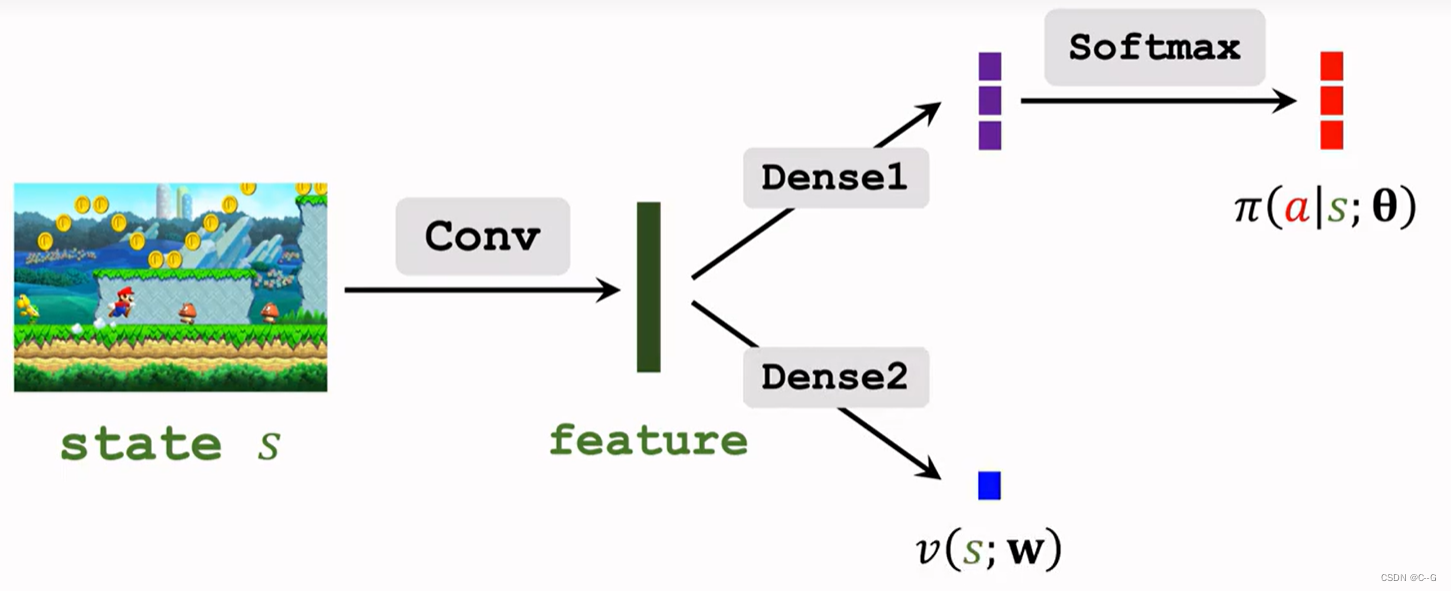
- Parameter Sharing
Reinforce with Baseline
- Updating the policy network

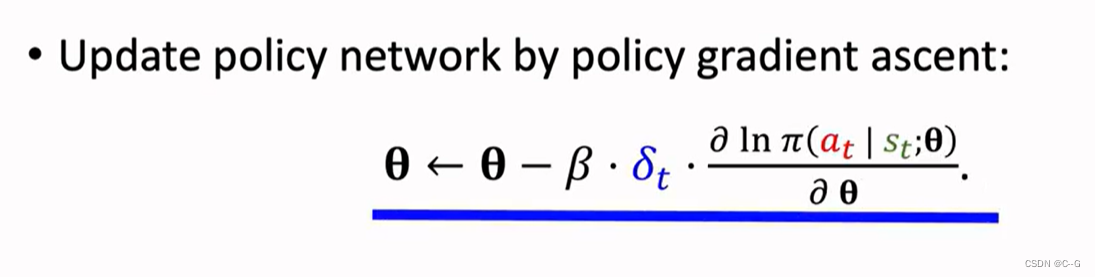

Advantage Actor-Critic(A2C)


Reinforce versus A2C
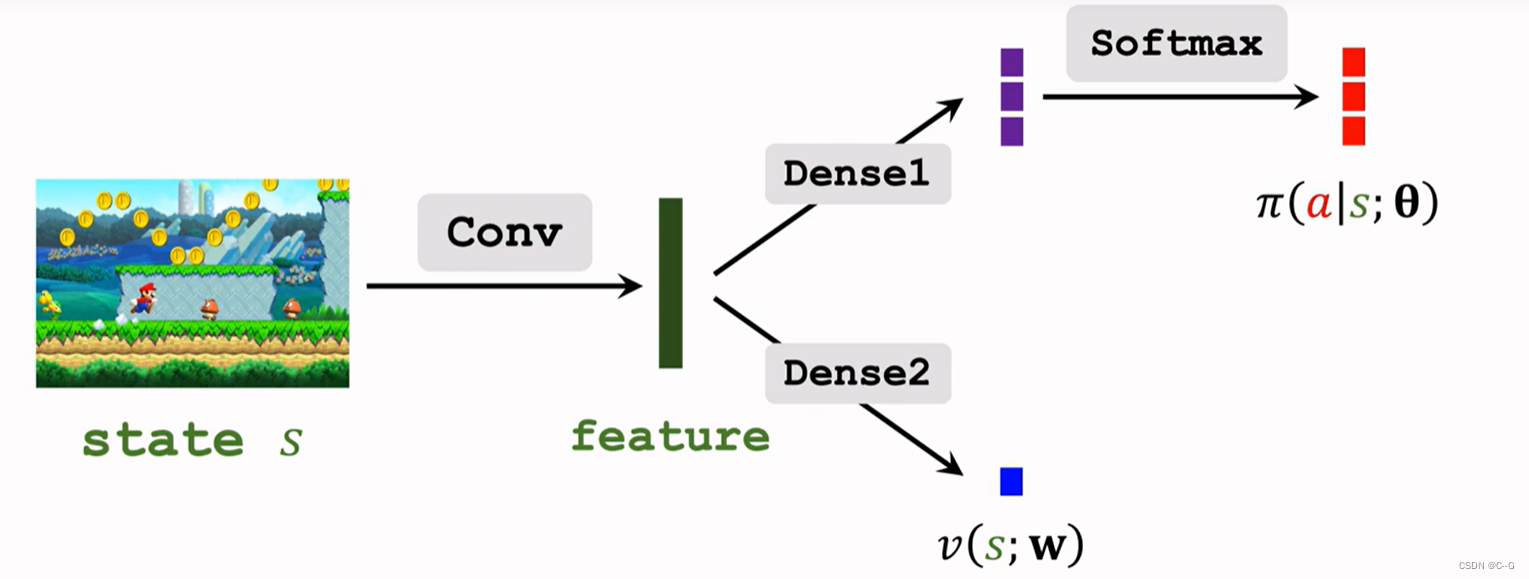
The network structure of the two is almost the same , Different value networks 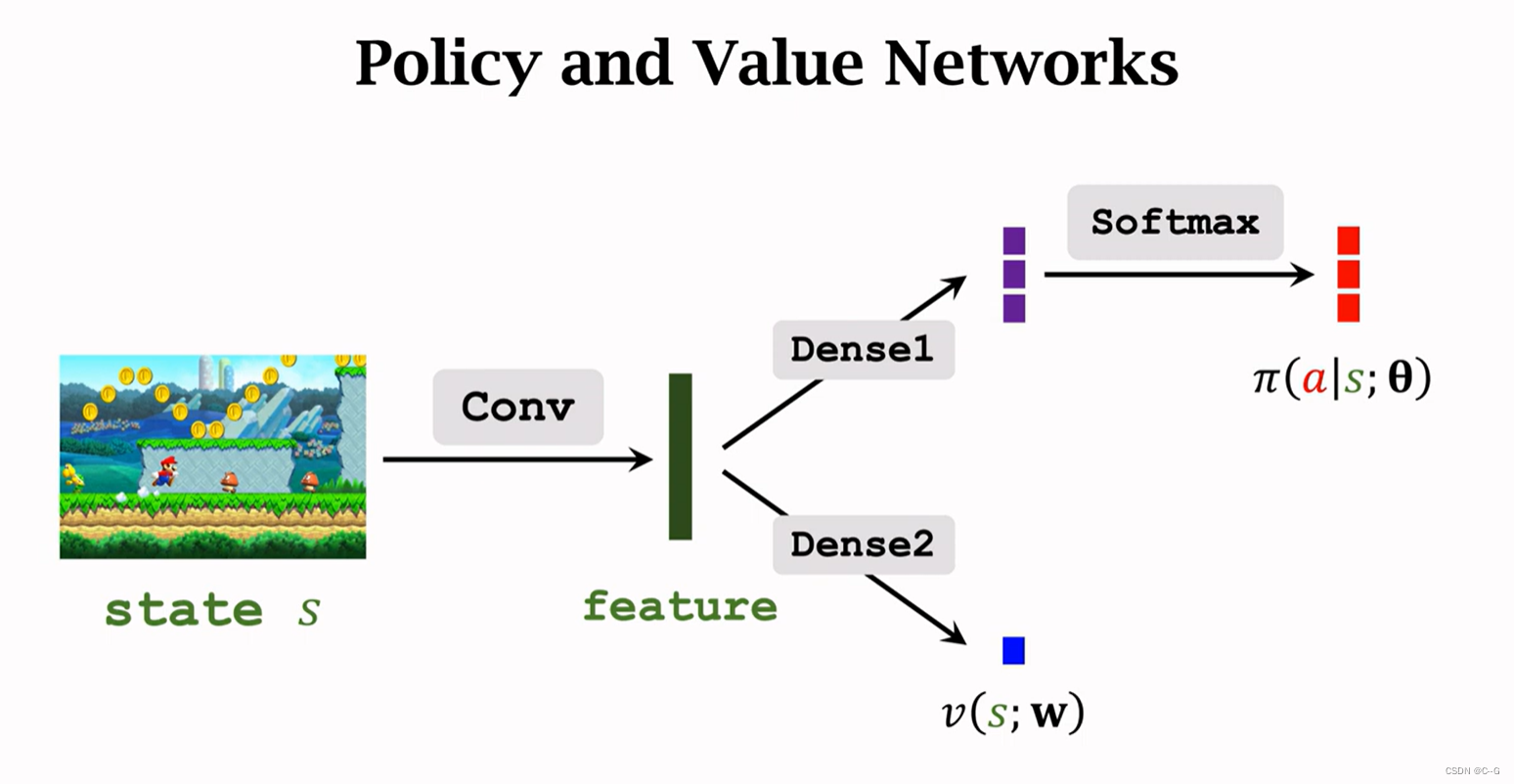
A2C with Multi-Step TD Target
one tep

Multi step
Reinforce with Baseline

versus


边栏推荐
- Ag9310 design USB type C to hdmi+u2+5v slow charging scheme design | ag9310 expansion dock scheme circuit | type-C dongle design data
- 10. CNN applied to handwritten digit recognition
- Cve-2022-28346: Django SQL injection vulnerability
- How does starfish OS enable the value of SFO in the fourth phase of SFO destruction?
- Introduction to ML regression analysis of AI zhetianchuan
- Leetcode notes No.21
- 13. Model saving and loading
- 13.模型的保存和载入
- How to transfer Netease cloud music /qq music to Apple Music
- 9. Introduction to convolutional neural network
猜你喜欢

From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run
HDMI to VGA acquisition HD adapter scheme | HDMI to VGA 1080p audio and video converter scheme | cs5210 scheme design explanation
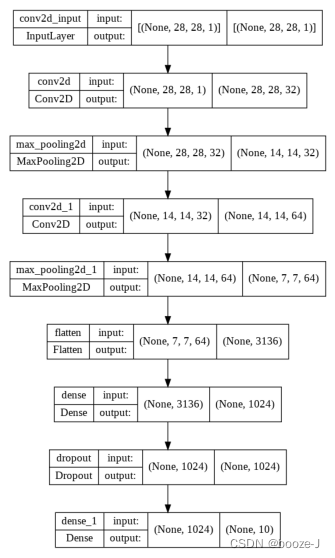
14. Draw network model structure
What does interface testing test?
9.卷积神经网络介绍
Chapter 16 intensive learning
6. Dropout application
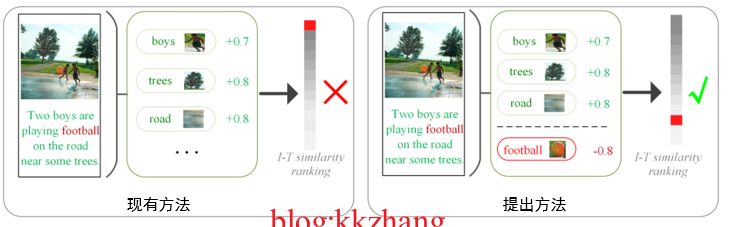
Cross modal semantic association alignment retrieval - image text matching
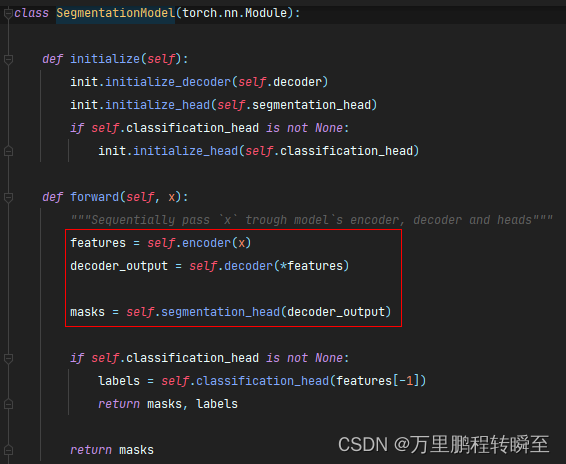
Semantic segmentation model base segmentation_ models_ Detailed introduction to pytorch
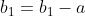
AI遮天传 ML-回归分析入门
随机推荐
Vscode is added to the right-click function menu
Mathematical modeling -- knowledge map
Ag9310 for type-C docking station scheme circuit design method | ag9310 for type-C audio and video converter scheme circuit design reference
13. Model saving and loading
How to transfer Netease cloud music /qq music to Apple Music
Chapter 16 intensive learning
1.线性回归
Get started quickly using the local testing tool postman
The combination of relay and led small night light realizes the control of small night light cycle on and off
Kuntai ch7511b scheme design | ch7511b design EDP to LVDS data | pin to pin replaces ch7511b circuit design
Connect to the previous chapter of the circuit to improve the material draft
3. MNIST dataset classification
C# ?,?.,?? .....
[necessary for R & D personnel] how to make your own dataset and display it.
swift获取url参数
Su embedded training - Day7
[deep learning] AI one click to change the sky
Complete model training routine
Redis, do you understand the list
Led serial communication