当前位置:网站首页>2、TD+Learning
2、TD+Learning
2022-07-07 23:21:00 【C--G】
Discounted Return
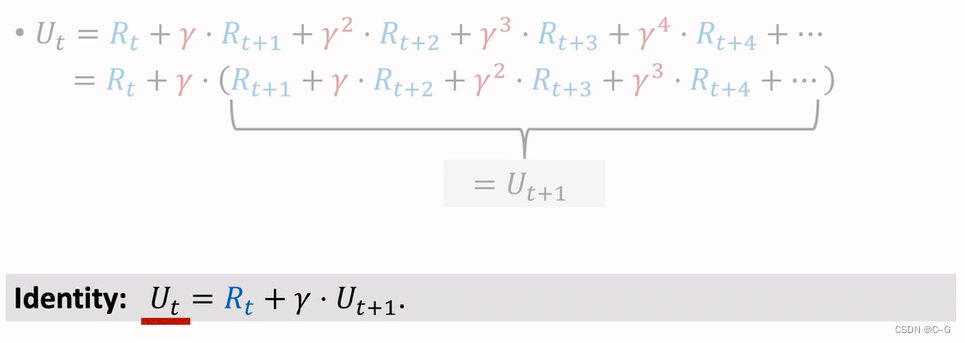


Sarsa
TD算法,用来学习动作价值函数QΠ
Sarsa:Tabular Version


Sarsa’s Name
表格状态的Sarsa适用于状态和动作较少,随着状态和动作的增大,表格增大就很难学习
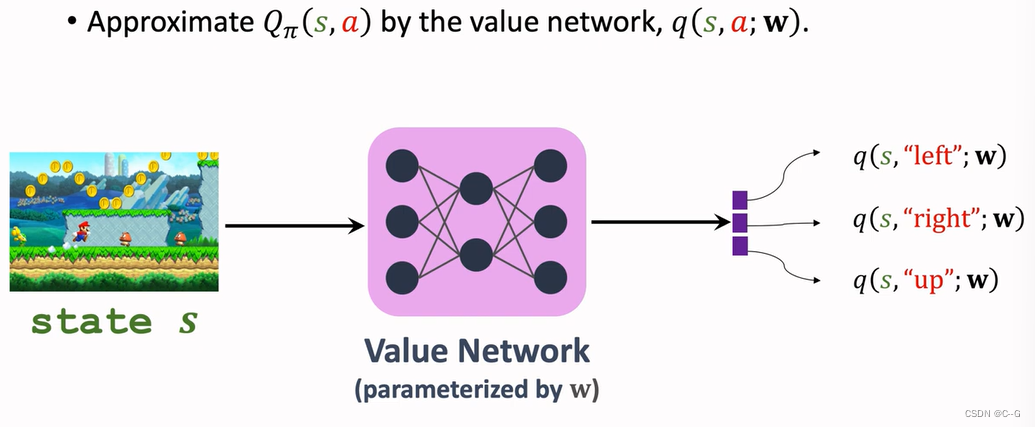
Sarsa:Neural Network Version



Q-Learning
TD算法,学习最优动作算法
Sarsa与Q-Learning

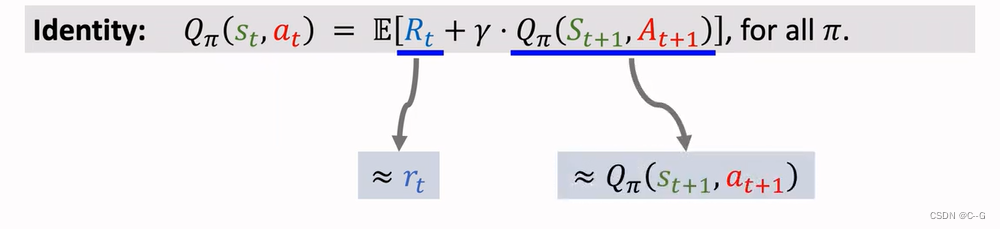
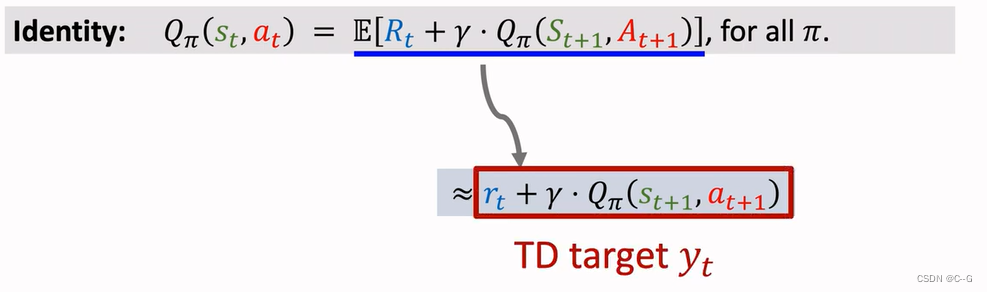
Derive TD Target


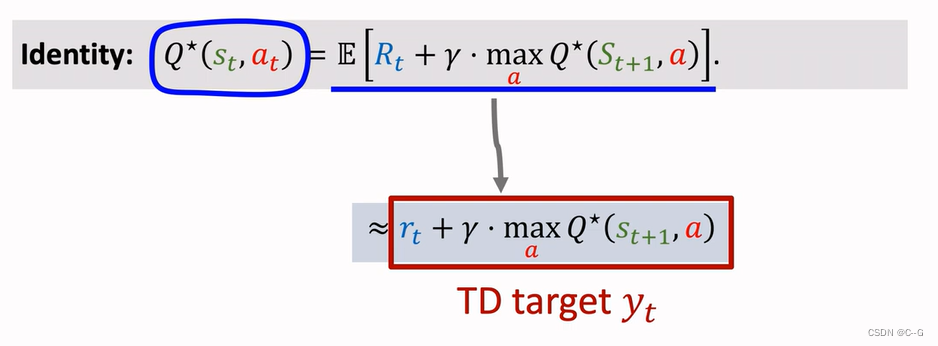
Q-Learning(tabular version)
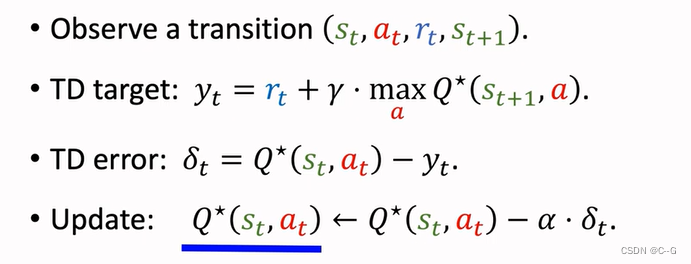
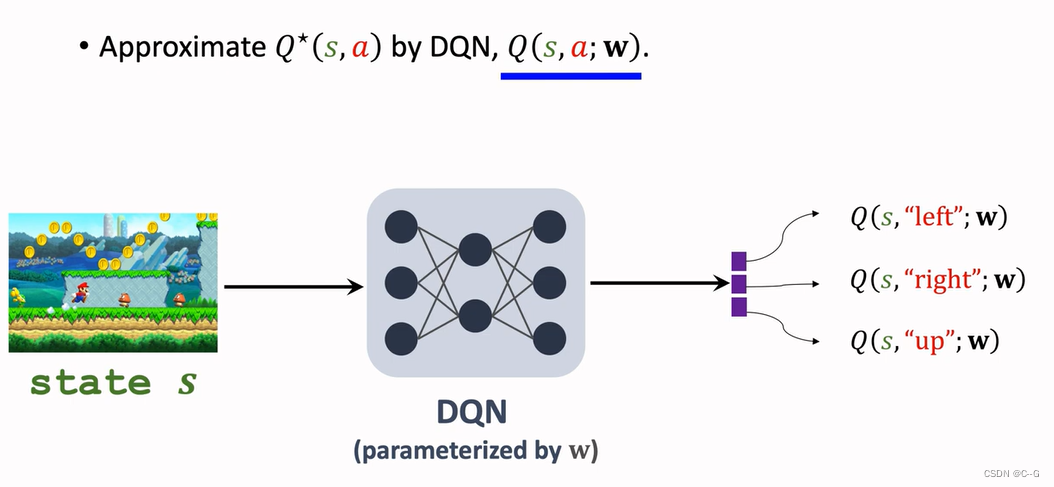
Q-Learning(DQN Version)

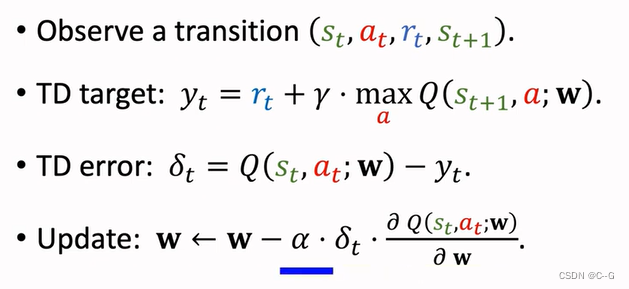

Multi-Setp TD Target
- Using One Reward

- Using Multiple Rewards

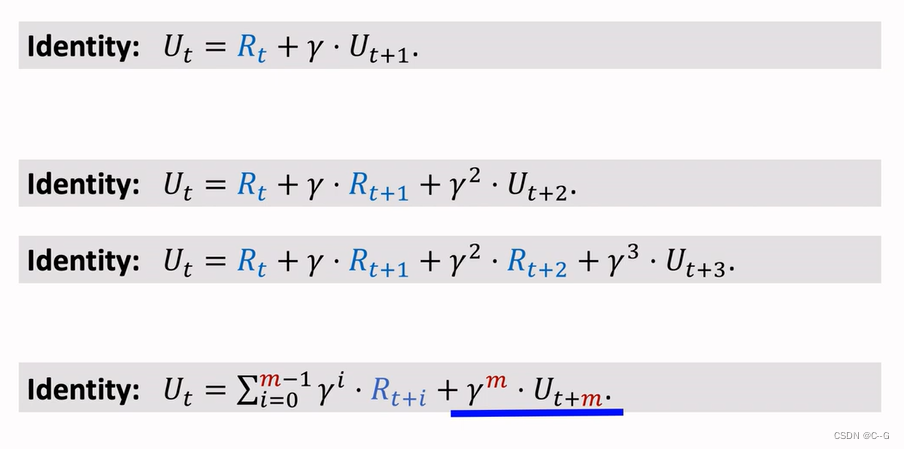



价值回放(Revisiting DQN and TD Learning)
- Shortcoming 1:Waste of Experience

- Shortcoming2:Correlated Updates

- 经验回放
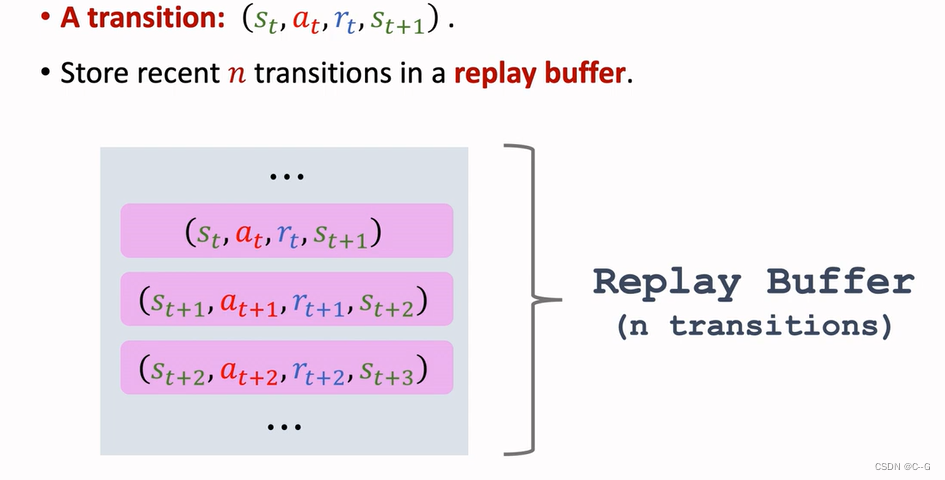



- History

Prioritized Experience Replay



左边是马里奥常见场景,右边是boos关场景,相对于左边而言,右边更少见,因此要加大右边场景的权重,TD error越大,那么该场景就越重要

随机梯度下降的学习率应该根据抽样的重要性进行调整


一条样本的TD越大,那么抽样权重就越大,学习率就越小
高估问题
Bootstrapping:自举问题,拽自己的鞋子将自己提起来
类似左脚踩右脚上天方法,现实中是不存在,强化学习中存在

Problem of Overestimation

- Reason 1:Maximization


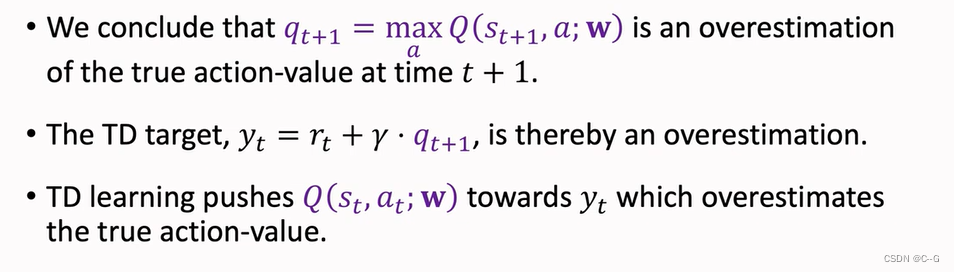
- Reason 2:Bootstrapping

- Why does overestimation happen
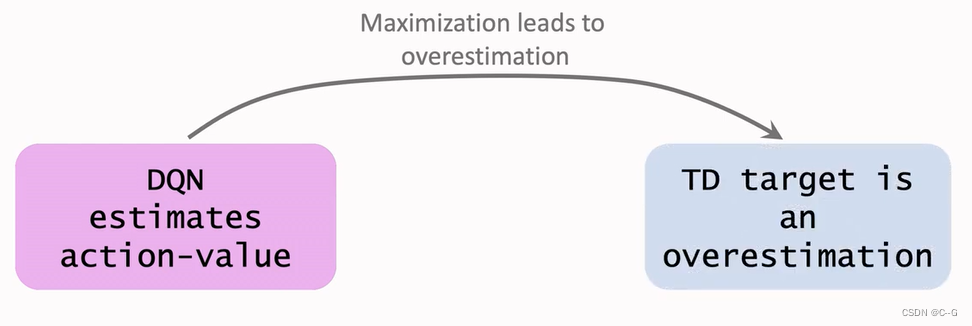

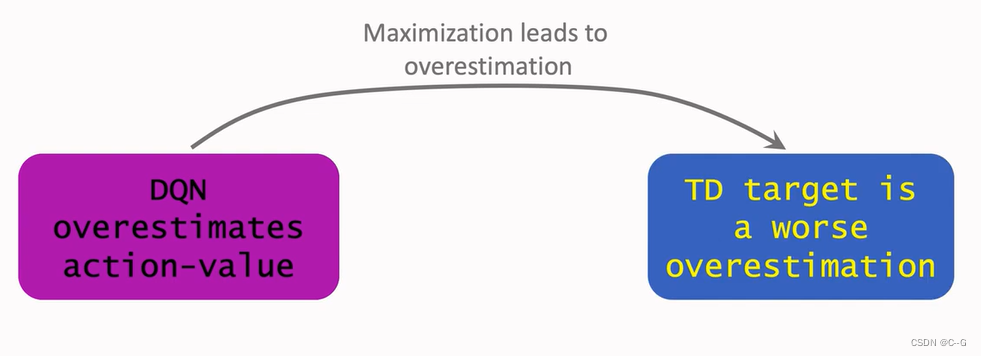

- Why overestimation is a shortcoming
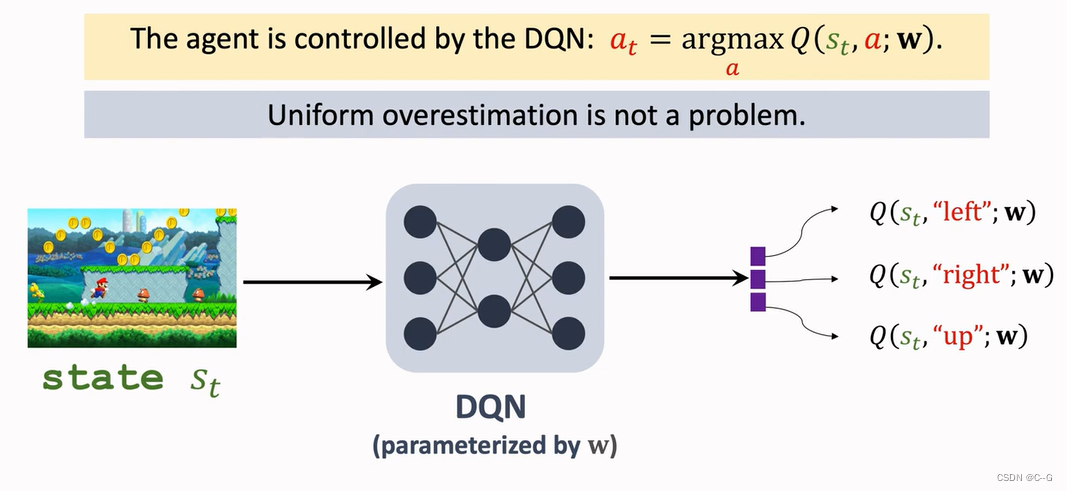



- Solutions

Target Network

TD Learning with Target Network
Update Target Network
Comparisons
Target Network虽然好了一点,但仍然无法摆脱高估问题
Double DQN
Naive Update

Using Target Network

Double DQN

Why does Double DQN work better
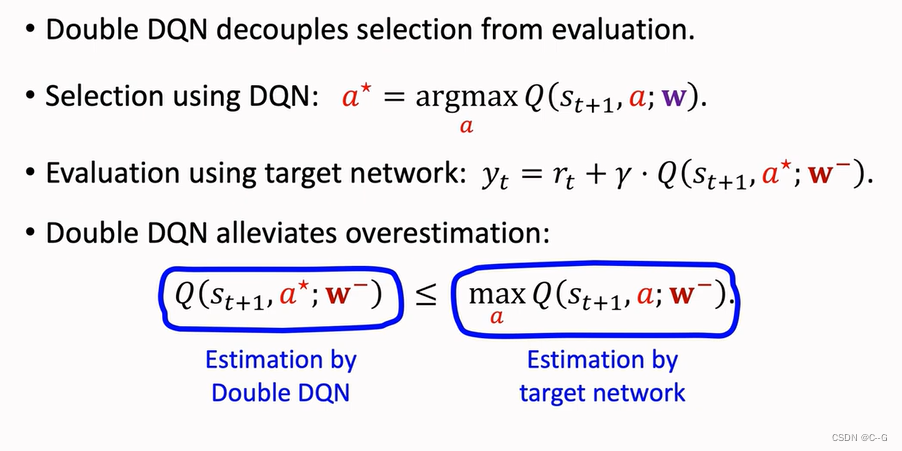
Dueling Network
Advantage Function(优势函数)
Value Functions

Optimal Value Functions

Properties of Advantage Function

Dueling Network

Revisiting DQN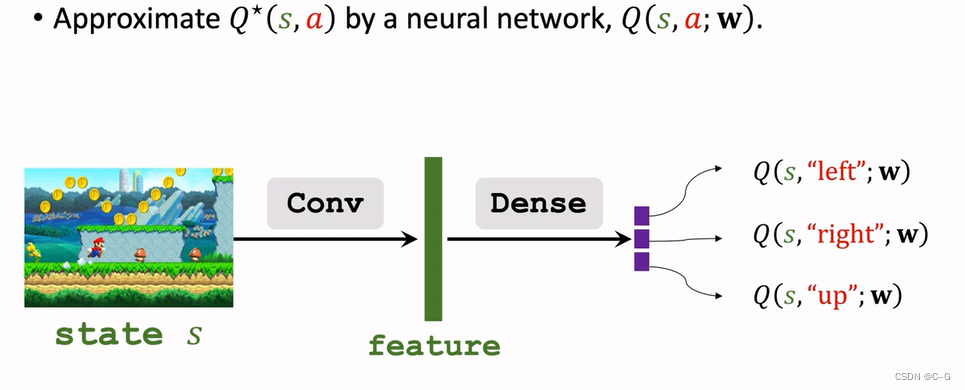
Approximating Advantage Function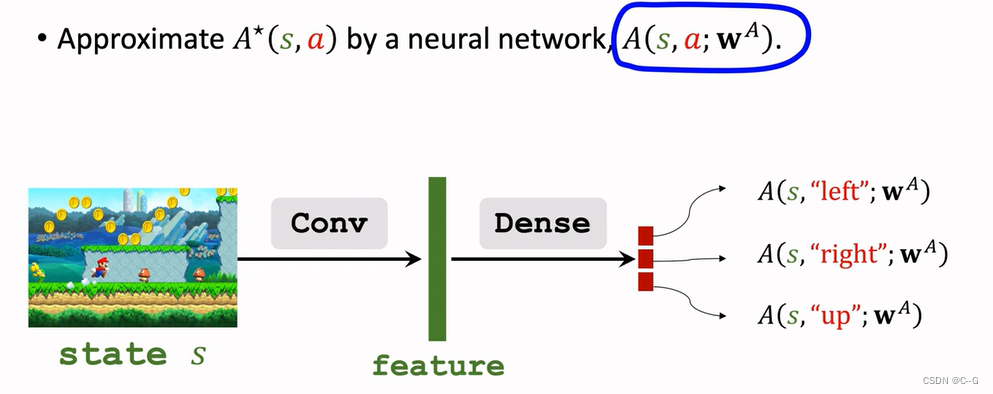
Approximating State-Value Function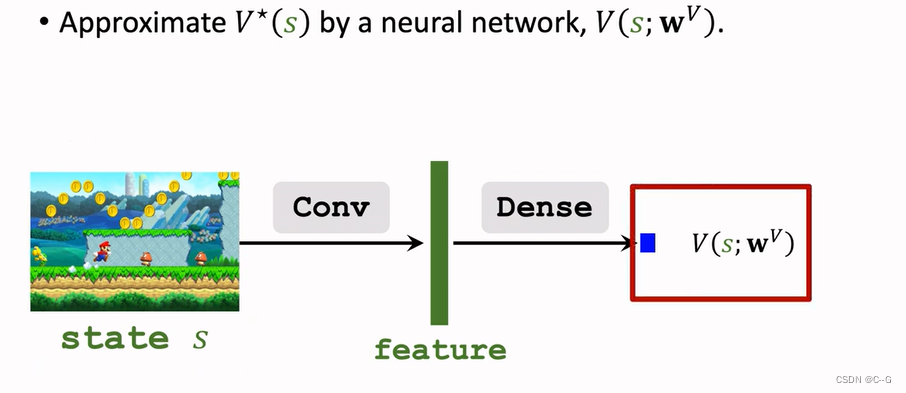
Dueling Network:Formulation
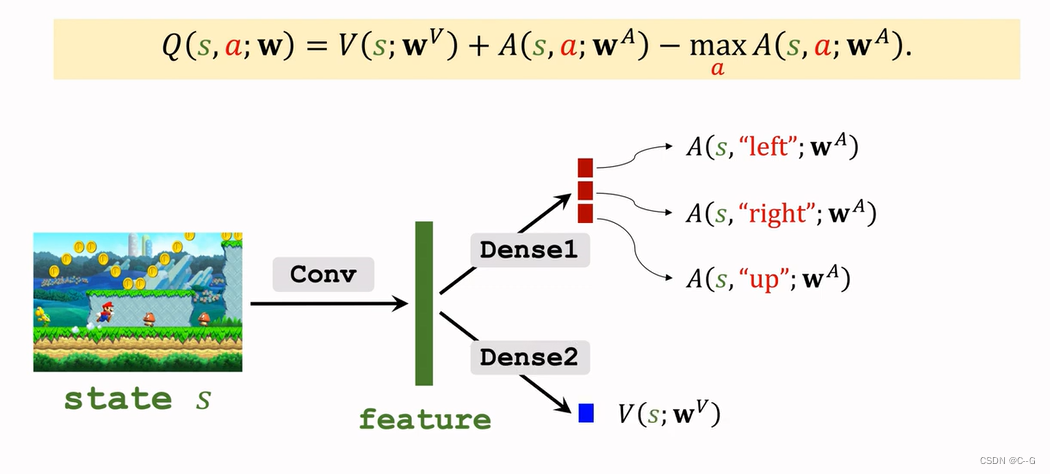
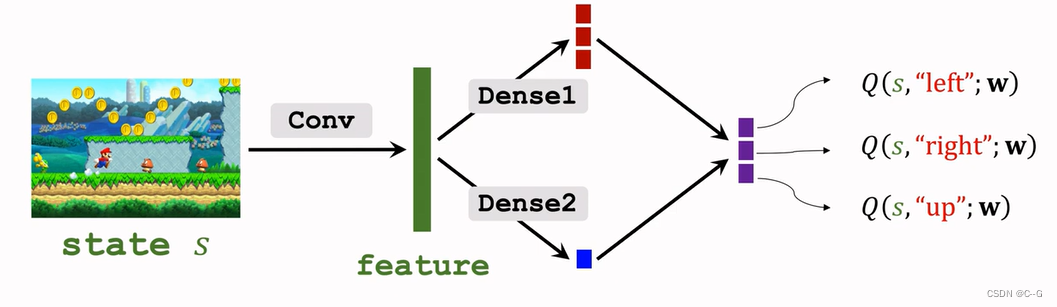
蓝色加上红色再减去红色的最大值就得到紫色最后Dueling Network输出
Problem of Non-identifiability


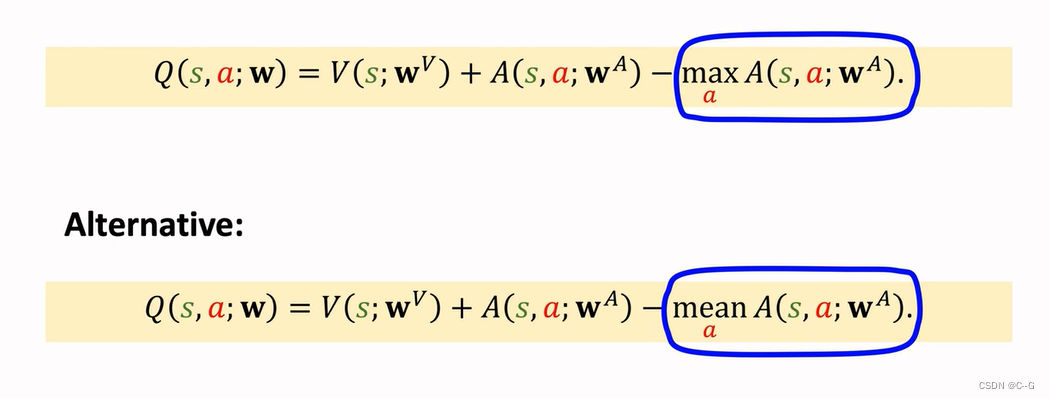
边栏推荐
- 9.卷积神经网络介绍
- Implementation of adjacency table of SQLite database storage directory structure 2-construction of directory tree
- Connect to the previous chapter of the circuit to improve the material draft
- 6. Dropout application
- Led serial communication
- New library online | information data of Chinese journalists
- High quality USB sound card / audio chip sss1700 | sss1700 design 96 kHz 24 bit sampling rate USB headset microphone scheme | sss1700 Chinese design scheme explanation
- Know how to get the traffic password
- [note] common combined filter circuit
- Chapter VIII integrated learning
猜你喜欢
6. Dropout application

From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run

The communication clock (electronic time-frequency or electronic time-frequency auxiliary device) writes something casually
Taiwan Xinchuang sss1700 latest Chinese specification | sss1700 latest Chinese specification | sss1700datasheet Chinese explanation
High quality USB sound card / audio chip sss1700 | sss1700 design 96 kHz 24 bit sampling rate USB headset microphone scheme | sss1700 Chinese design scheme explanation
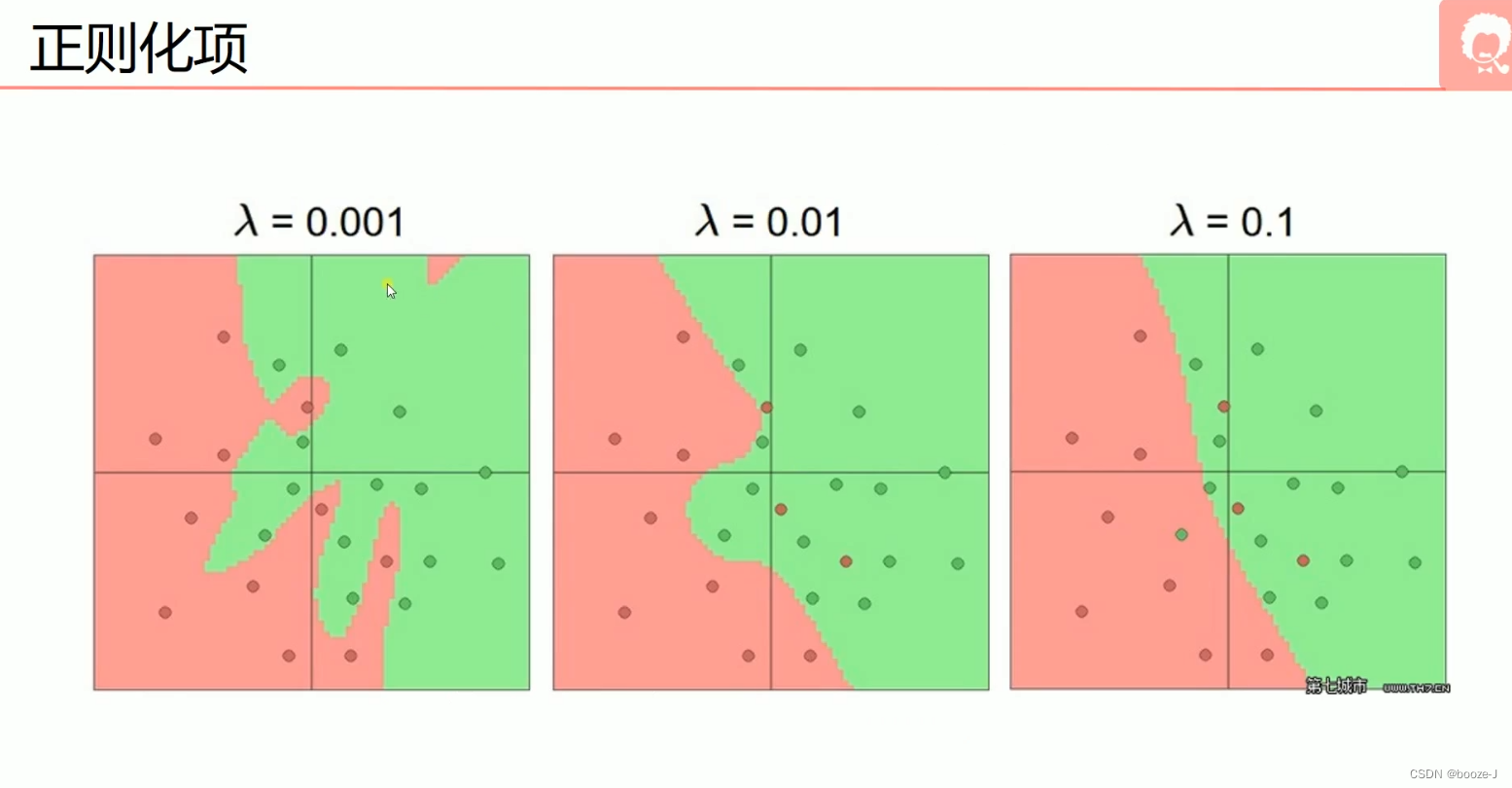
5.过拟合,dropout,正则化
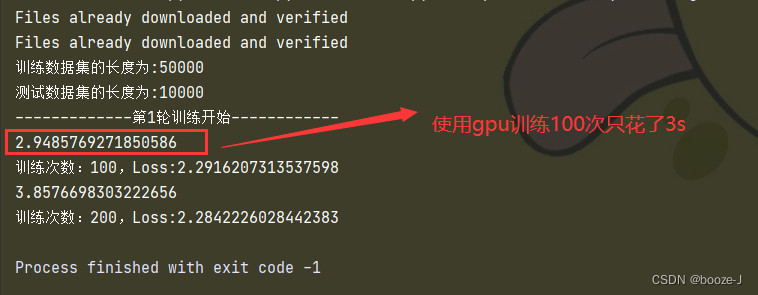
Using GPU to train network model
Vs code configuration latex environment nanny level configuration tutorial (dual system)
Common effects of line chart

Ag7120 and ag7220 explain the driving scheme of HDMI signal extension amplifier | ag7120 and ag7220 design HDMI signal extension amplifier circuit reference
随机推荐
What does interface testing test?
Implementation of adjacency table of SQLite database storage directory structure 2-construction of directory tree
完整的模型验证(测试,demo)套路
String usage in C #
Measure the voltage with analog input (taking Arduino as an example, the range is about 1KV)
4、策略學習
Chapter improvement of clock -- multi-purpose signal modulation generation system based on ambient optical signal detection and custom signal rules
Micro rabbit gets a field of API interface JSON
13. Enregistrement et chargement des modèles
Ag9310meq ag9310mfq angle two USB type C to HDMI audio and video data conversion function chips parameter difference and design circuit reference
Codeforces Round #804 (Div. 2)
1. Linear regression
Cs5212an design display to VGA HD adapter products | display to VGA Hd 1080p adapter products
Prediction of the victory or defeat of the League of heroes -- simple KFC Colonel
3. MNIST dataset classification
Generic configuration legend
133. 克隆图
New library online | information data of Chinese journalists
5、离散控制与连续控制
[go record] start go language from scratch -- make an oscilloscope with go language (I) go language foundation