Paper information
Paper title :Rethinking the Setting of Semi-supervised Learning on Graphs
Author of the paper :Ziang Li, Ming Ding, Weikai Li, Zihan Wang, Ziyu Zeng, Yukuo Cen, Jie Tang
Source of the paper :2022, arXiv
Address of thesis :download
Paper code :download
1 Introduction
This paper mainly studies semi supervised GNNs Overshoot in the model (over-tuning phenomenon), A fair model comparison framework is proposed .
2 The Risk of Over-tuning of Semi-supervised Learning on Graphs
2.1 Semi-Supervised Learning on Graphs
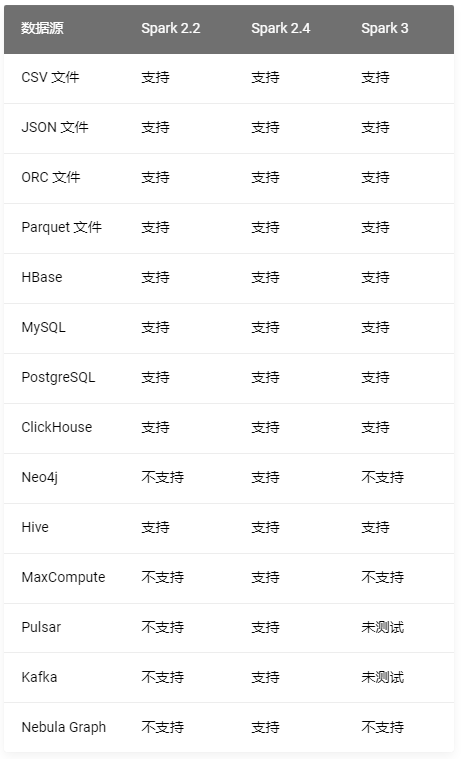
Three commonly used data sets :

2.2 An Analysis of Over-tuning in Current GNNs
Overshoot (over-tuning phenomenon) ubiquitous GNNs in , namely GNN The hyperparametric over fitting validation set of the model .
This paper tests 5 It's representative of GNNs frame (GCN, GAT, APPNP, GDC-GCN, ADC) stay Cora Comparison of accuracy rates of different verification set sizes on the data set . In this paper, grid search is used to select the optimal hyperparameter for each model . Change the size of the validation set from 100 To 500. For each validation set , After using the super parameter training model of the best search , Report the results on the test set . The result is as follows Figure1 Shown .

Figure 1 Show ,GNN Models with larger validation sets usually perform better . Because the validation set can only affect the model through hyperparameters , So we can come to a conclusion , The model can benefit from validation tags by using super parameters . If we change the size of the validation set from 100 Add to 500, The accuracy is improved as high as 1%∼3% , This is enough to show that over tuning already exists .
2.3 ValidUtil: Exploring the Limits of Over-tuning
It is usually not possible to add validation sets to training sets , This is considered a data leak . What this article puts forward ValidUtil Such as :

Results found : Only when $\hat{y}_{i}=y_{i}$ when , The model can achieve the best results .Figure 2 Shows hyper-parameters The impact on the experiment :

We found that , Even from ValidUtil There are only 20 individual ∼60 A super parameter , It can also bring a leap in performance to some models . When we verify all in the set 500 When adding super parameters to nodes ,PPNP Comparable Table 2 Medium SOTA Method .

remarks : although ValidUtil Work purely by using validation tags , But it is fully effective under the current setting . If we were to GNN+ValidUtil As a black box model , Then the training process is quite normal .ValidUtil In fact, the efficiency of using labels is very low , Because each super parameter can only learn the information of one node —— But this is enough to test our hypothesis . The current setting cannot prevent the validation tag from being used during hyper parameter tuning “ leak ”. We think there are some more effective ways to define influential hyperparameters . These hyperparameters may be entangled with features or model structures , They can get information from multiple authentication tags . according to Figure 1, Such influential hyperparameters may already exist in some models , Not easy to detect . therefore , There is an urgent need to build a new semi supervised learning benchmark on graphs , To avoid over tuning and fairness 、 Compare steadily GNN Model .
3 IGB: An Independent and Identically Distributed Graph Benchmark
3.1 Overview
Two goals of the new benchmark : Avoid over tuning and be more robust .
To avoid over tuning , In this paper, nodes are divided into labeled nodes and unlabeled nodes . You can learn the best model of labeled data sets in any way , And evaluate unlabeled sets ( Test set ) Performance on . If you need to search for super parameters , A part of the marked data set can be regarded as a verification set . Because the verification label has been exposed , Therefore, the problem of over tuning is eliminated . This setting is closer to the real scene , Be able to make a fair comparison between models with different superparameters . In order to easily GNN Migrate to this new setting , We will be in the 3.2 Section introduces a simple and powerful way to create validation sets .
This paper expects that under different random seeds , The performance of the model is stable . A common method of reporting performance in machine learning is : Repeat testing and reporting average performance . So this article expects to be in multiple i.i.d Test the performance of the model on the graph , These are many i.i.d chart It's from sampling .
- 1. Divide the labeled set into training and validation sets.
- 2. Find the best hyper-parameters using grid search on the training and validation sets from the first step.
- 3. Train the model with the best hyper-parameters on the full labeled nodes.
- 4. Test the performance of the model from the third step on the unlabeled (test) sets.
- 5. Repeat the above steps on each graph in a dataset and report the average accuracy
The first two steps aim to find GNN The best hyperparameter of the model . We think this method is applicable to many GNN The model obtains satisfactory hyperparameters . If there are other reasonable methods to determine the optimal hyperparameter with a marked set , They will also be encouraged to replace the first two steps in this pipeline . In this way , You can avoid over tuning by directly exposing all tag information in the validation set in the third step .
3.3 Datasets
IGB It consists of four data sets :Aminer,Facebook,Nell,Flickr. Each dataset contains 100 An undirected connected graph , According to the first 3.4 The random walk method in the section samples from the original large image . We also report the average node overlap rate of a pair of sampled graphs , That is, the ratio of public nodes to the total size of nodes . Coverage is defined as 100 The ratio of the union of the sampled graph and the original large graph . Low overlap and high coverage are preferred . The statistical data of the data set is shown in table 3.

3.4 Sampling Algorithm
The simplest way to make the node label distribution of a subgraph similar to the original graph is vertex sampling . However , It doesn't meet our expectations , Because it generates disconnected subgraphs . To get close i.i.d. Benchmark of subgraph , We must carefully design sampling strategies and principles . say concretely , We expect the sampling strategy to have the following characteristics :
- 1. The sampled subgraph is a connected graph.
- 2. The distribution of the subgraph’s node labels is close to that of the original graph.
- 3. The distribution of the subgraph’s edge categories (edge category is defined by the combination of its two endpoints’ labels) is close to that of the original graph.
First , Random walk well satisfies the first point , We start from the node $u=n_0$ Start sampling , The following nodes can be selected through the possibility of conversion :
$P_{u, v}=\left\{\begin{array}{ll}\frac{1}{d_{u}}, & \text { if }(u, v) \in E \\0, & \text { otherwise }\end{array}\right.$
among ,$P_{u, v}$ It's from $u$ To $v$ The probability of transfer ,$d_{u}$ Represents the node $u$ Degree .
We refuse to adopt a similar sampling method , To ensure the second and third properties . ad locum , We introduced KL The divergence As a measure to measure the difference between two different distributions . In order to get the node label distribution (“Node KL”) And marginal category distribution (“Edge KL”)KL Subgraphs with relatively low divergence , We set a predefined threshold to decide whether to accept the sampling map . The results before and after adding the threshold are compared as Table 4 Shown .

3.5 Benchmarking Results
Results on these four datasets :

3.6 The Stability of IGB
This paper uses two methods to verify IGB The stability of . First , Verify its stability when evaluating the model on different graphs , Because of every IGB Data set containing 100 Close i.i.d. chart . say concretely , We compared 100 individual AMiner Subgraphs and 100 individual Cora Precision variance in random data segmentation .Figure 3 It turns out that , Even if each AMiner The graph uses random data segmentation , Yes IGB Is also better than Cora More stable style .

secondly , Focus on IGB Stability in evaluating models with different random seeds . In a stable benchmark , The ranking of different models should not be easily changed when changing random seeds . To test this , We use ranked “inversion number” As a measure .

4 Conclusion
In this paper, we discuss the semi supervised setting on graph again , It also expounds the problem of over optimization , And through VallidUtil Verified his significance . This paper also proposes a new benchmark IGB, A more stable evaluation pipeline . A method based on RW Sampling algorithm to improve the stability of evaluation , This paper hopes to pass IGB It can benefit the society .
Revise history
2022-07-07 Create articles
Contents of thesis interpretation
Interpretation of the thesis (ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》 More articles about
- Interpretation of the thesis (node2vec)《node2vec Scalable Feature Learning for Networks》
Thesis title :<node2vec Scalable Feature Learning for Network> Time of publication : KDD 2016 Author of the paper : Aditya Grover;Adit ...
- Interpretation of the thesis (ClusterSCL)《ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs》
Paper information Paper title :ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs Author of the paper :Yanling Wang, Jing ...
- Interpretation of the thesis 《Momentum Contrast for Unsupervised Visual Representation Learning》 Be commonly called MoCo
Thesis title :<Momentum Contrast for Unsupervised Visual Representation Learning> Author of the paper : Kaiming He.Haoq ...
- Interpretation of the thesis (MLGCL)《Multi-Level Graph Contrastive Learning》
Paper information Paper title :Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- Self supervised learning (Self-Supervised Learning) Interpretation of multiple papers ( On )
Self supervised learning (Self-Supervised Learning) Interpretation of multiple papers ( On ) Preface Supervised deep learning Due to the large amount of annotation information , At the same time, a large number of previous studies have solved many problems . therefore ...
- This paper interprets the third generation GCN《 Deep Embedding for CUnsupervisedlustering Analysis》
Paper Information Titlel:<Semi-Supervised Classification with Graph Convolutional Networks>Aut ...
- itemKNN The history of ---- Three important papers on recommender system
itemKNN The history of ---- Three important papers on recommender system The symbols used in this article are 1.Item-based CF Basic process : Calculate similarity matrix Cosine Similarity degree Pearson's similarity coefficient Parameter aggregation for recommendation According to the user ...
- CVPR2019 | Mask Scoring R-CNN Interpretation of the thesis
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN Interpretation of the thesis author | Wen Yongliang Research direction | object detection .GAN Recommended reasons : This article interprets an article published in CVPR ...
- AAAI2019 | Target detection based on domain decomposition and integration Interpretation of the thesis
Object Detection based on Region Decomposition and Assembly AAAI2019 | Target detection based on domain decomposition and integration Interpretation of the thesis author | Wen Yongliang learn ...
- Gaussian field consensus Interpretation of the paper and its application MATLAB Realization
Gaussian field consensus Interpretation of the paper and its application MATLAB Realization author : Kaluga Gio - Blog Garden http://www.cnblogs.com/kailugaji/ One .Introduction ...
Random recommendation
- JAVA Security model
As a language born in the era of the rise of the Internet ,Java From the beginning, there were safety considerations , How to ensure downloading to local through the Internet Java The program is secure , How to Java The program has limited access to local resources , These safety considerations ...
- turn : to C# Developer's code review checklist
to C# Developer's code review checklist [ thank @L Namely L My enthusiastic translation . If other friends have good original or translation , You can try to recommend it to Bole online .] This is for C# A generic code review list prepared by the developer , It can be used as a reference in the development process . ...
- windows 8 install wp8 After that, the mouse didn't respond
Notebook is windows 8 System , Yesterday installed windows phone 8.0 SDK after , I found that the wireless mouse didn't respond , But the touch screen mouse can move normally ! It's strange , The students nearby also installed this sdk, But nothing's wrong ! ...
- js Create the object's 6 Ways of planting
One . Factory mode function createStudent(name,age){ var o=new Object(); o.name=name; o.age=age; o.myName=functi ...
- vim Find and replace in
( The article is pasted from my personal homepage , You can also visit my home page www.iwangzheng.com) lookup : Gsearch -F 'aa' -R --include=*rb Replace : (1) In the search results ...
- NhibernateProfiler- Write an automatic cracking tool ( Source code )
04 2013 archives [ Loser's counter attack series ] It's the end of being able to crack all of us NhibernateProfiler- Write an automatic cracking tool ( Source code ) Abstract : Analysis of cracking ideas and manual cracking increase “ Attach to process ” function -- Function introduction added “ ...
- vue Use of scaffolding swiper / introduce js file / introduce css file
1. install vue-cli Reference address :https://github.com/vuejs/vue-cli If you don't use strict grammar, you need to type in the last three items no:( It's a headache , Always report mistakes , But it's also very helpful to the normalization of your own code ...
- CentOS Next SVN Version control installation ( Include yum And non yum) Record the steps of .
One .yum install rpm -qa subversion // Check if the lower version of SVN yum remove subversion // If you store older versions , Uninstall old version SVN Start installation yum -y ins ...
- Subsequence Count 2017ccpc Online games 1006 dp+ Segment tree maintenance matrix
Problem Description Given a binary string S[1,...,N] (i.e. a sequence of 0's and 1's), and Q queries ...
- About TP5 One on one 、 One to many simultaneous association queries
Main table SQL(tp_member) CREATE TABLE `tp_member` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT ' Primary key id', `us ...