当前位置:网站首页>Three questions TDM
Three questions TDM
2022-07-07 23:24:00 【kaiyuan_ sjtu】
Preface
Advance declaration , there “ ask ” Not questioning , But ask for advice , Lest anyone scold me for being a spray .
I have long heard of Ali TDM The name of the recall , I have also read the article for a long time .TDM Breaking the traditional recall ,user Side and side item The side must isolate the limitations of decoupling modeling ( you 're right , Two towers , It's about you ), send item Yes user history Conduct Attention Such a cross structure can also be applied to recall , It greatly improves the expression ability of the recall model .
But recently reread TDM, Think carefully from the perspective of actual combat , I found that I couldn't figure out three problems , The details are not given in the original paper . Write this article today , List these three questions , And give me some guesses , Consult and verify with masters on the Internet , Also help other students broaden their thinking .
Know the answer , You can write the answers in the comments . That's true. TDM It has developed to TDM 3.0, Maybe from TDM 1.0->TDM 3.0 In an article of , Has answered my question , But maybe I don't read the article carefully , It's missing . If any , Please point it out .
Students who don't know the answer , Also think about it , It can deepen your understanding of the recommended algorithm . At least let you know , From thesis to practice , To achieve results , There is still a long way to go . The key to the success of many algorithms , It may not lie in the new theory of paper packaging 、 New concepts , But lies in the small outside the paper Trick. these trick Are valuable experiences from stepping on the pit , It's about a layer of window paper , But people don't say , You never know where to poke .
Item Can I only take the side item id When features ?
item Of course, the side has very rich features , Such as static portraits ( Such as classification 、 label ), And dynamic portraits ( For example, in the past period CTR etc. ). But each item Just leaf nodes of the tree .
There are also non leaf nodes in the tree , They are built dynamically 、 The concept of virtual reality , It does not correspond to specific materials , They can only have ID features , Having no other characteristics .
TDM It's the same one DNN Model to judge ctr Of , namely
402 Payment Required
In the above formula Node Both include leaf node, Specifically item, Also include non-leaf node, That is, the concept of virtual . I think TDM It will not be aimed at node Whether it is leaf And two sets dnn Of , Therefore, in the above formula , It can only be the intersection of the characteristics of two types of nodes , Only use id features .
One possibility is not ruled out , Namely non-leaf Node non-id Class characteristics , It can be aggregated from the features on its child nodes , such as :
non-leaf node Of “ label ” The characteristic is its subordinate leaf node( That's the truth item) A collection of tags
non-leaf node Of ctr Characteristics are subordinate to it leaf node Of ctr, According to what formula , Average .
But it's obviously too troublesome .
So I guess , It's usually used TDM, Only use item id When features . If so , When selecting models, we should make choices :
TDM Break through the point product limit , allow item And user Conduct complex crossing , Is the advantage
however item Side can only be used item id, Limited sources of information , It is not conducive to cold start , It's a shortcoming
How to train incrementally ?
Training from scratch
The training process described in the paper is :
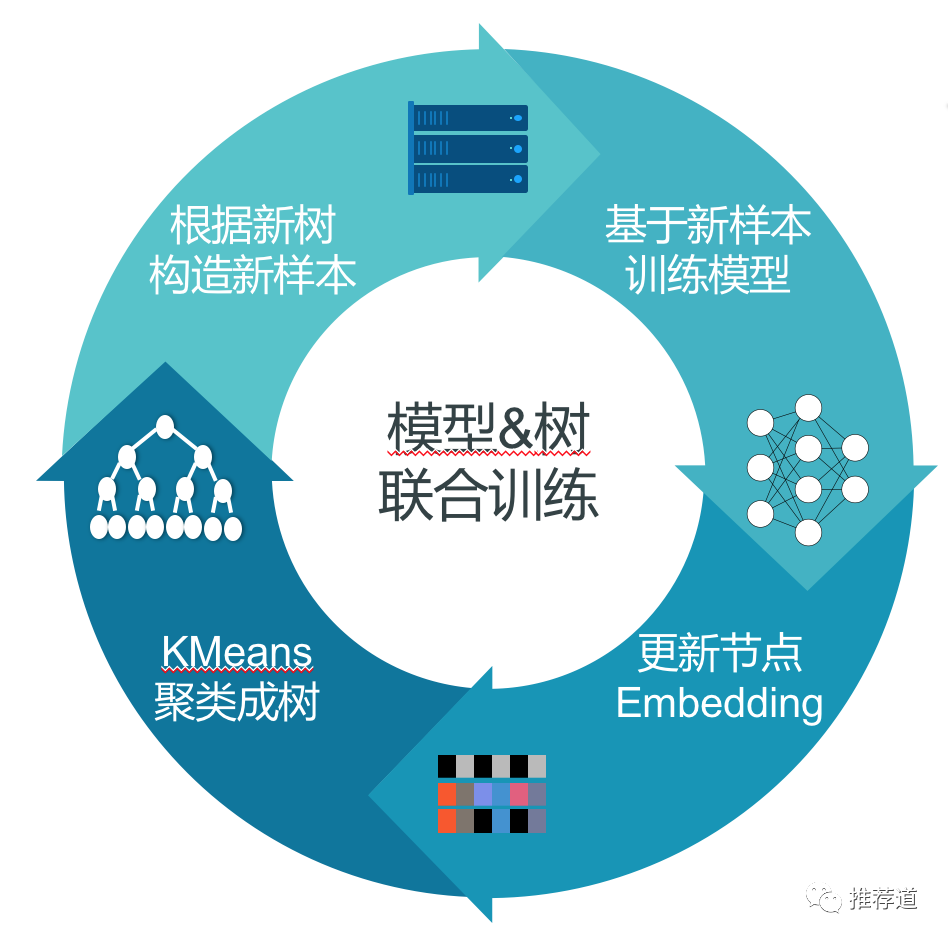
Make use of the results of the last round of training item embedding, adopt k-means Build trees
In the tree , Get the positive and negative samples of each layer
On each positive and negative node on each layer , use dnn forecast ctr,, Refeeding binary cross-entropy Calculation loss
After training , obtain “ new embedding”, return step 1, Start the next round of training
It's easy to see 、 Very intuitive , But you think carefully , Found “ Update node embedding” This step , A bit of a problem. , Which nodes are updated embedding?
Update leaf nodes , b. , Because leaf nodes correspond to real item.item embedding, That is to say leaf node embedding, Is able to inherit the results of the previous round of training , And incrementally updated .
however , about non-leaf node, It's all through k-means Dynamically constructed , Is it necessary to update ? Is there any possibility of inheritance ?
non-leaf node The corresponding is not a specific material , It's just a virtual concept . I haven't read it carefully TDM Source code , Don't understand TDM For non leaf nodes ID The coding rules of . however , If there are two non leaf nodes in the two rounds of training , Share because of the same location ID, In the next round of training “ The first 2 Layer 1 Nodes ” Who can inherit the previous round of training “ The first 2 Layer 1 Nodes ” Of embedding, Based on this, incremental update , I don't think it makes sense .
Two non-leaf node The semantics of does not depend on their position in the tree , It depends on their subordinates leaf node( Real item). Two of the two rounds of training non-leaf node, Only under their jurisdiction leaf node When they completely coincide , these two items. non-leaf node The semantics of is the same , To inherit embedding, Continue incremental training . But this is unlikely , Especially the higher the level non-leaf node, They govern leaf node The greater the possibility of change , Front and rear wheels non-leaf node Inherit embeding And the less likely it is to update incrementally .
therefore , I guess , Every round dnn After training , Only keep leaf node embedding,non-leaf node embedding It is directly discarded , Because anyway, the next round of training will not be used .
After the next round of training , Use the last round item embedding Reconstruct the tree
leaf node embedding It can be inherited from the training results of the last round
In the current tree non-leaf node In the same position as the tree in the previous round non-leaf node It doesn't matter , Cannot inherit their embedding, In this tree non-leaf node embedding Should be initialized randomly
But do it , Bring a problem , Namely non-leaf node Often training is insufficient , Because they all have “ Fish like memory ”,non-leaf node The training achievements of cannot be inherited . Even though it seems , Training for several rounds , Until the final model to be delivered ,non-leaf node embedding It's just a round of training !!!???
If it's really like what I said above ,non-leaf node Training for , image “ A bear breaks a stick ” equally , Training is so inadequate , It's hard for me to imagine TDM What good results can be achieved .
therefore , I guess ,non-leaf node embedding It should be like this
Use what you got from the last round of training item embedding Conduct k-means Clustering time , The center of clustering is each layer non-leaf node, therefore these non-leaf node Initial embedding It's the cluster item embedding The average of
thus , Building a good tree , When you start training , various non-leaf node embedding It is no longer randomly initialized , Instead, there is a reasonable The initial value of the
In this round of training ,non-leaf node embedding It will also be updated . But after this round of training , There is no need to save it .
Incremental training after online
In the paper, the tree and the model , Train from scratch , But actually , such “ Training from scratch ” It doesn't make sense
First , There is too much data in the large recommendation system , It is unlikely to be like “ Training from scratch ” like that , Repeat the same data several times
secondly , Any model of Dachang , Must be updated online continuously and incrementally , Put new users 、 Consider new materials . Incremental updating , The slowest must also be hourly . Think , If every hour , All new materials are taken into account ( The set of leaf nodes has changed ), Go back “ Build up trees -> Training models -> Make a new contribution -> Retraining the model ......” The cycle of , It's not that I can't , That's it. The timeliness of the model is too poor , Maybe it's out of date to push it online .
therefore , I heard that TDM In practice , That's true :
The tree architecture does not need to be updated in real time , Just update it once a day . When it's updated , It's not like what is written in the paper , need “ Build up trees -> Training models ” Alternate . Instead, take the ready-made item embedding Build the tree . Those used to build trees item embedding Where are from ? It may be from the previous edition TDM In the model item embedding( That is to say, each leaf node Of embedding), You can also take the latest rough row Twin Towers item embedding( The advantage is that these item embedding Compressed except item id Other than item profile Information ).
Then in this day , This tree will not change
In a day ,TDM Can accept the latest user feedback , Conduct online learning.user feature embedding, Old material feature embedding, also dnn Those of weight Equal parameter , Will be updated by the latest feedback data of users .
According to the above method , New users are not affected , But what about new materials ? If for the second 1 A question , My guess is right , namely TDM Just take it item id When features , New materials are equivalent to no features available , So this The new material is on the tree “ Nowhere to go ”, Cannot be retrieved , Can't be trained .
Is that all ? In a day ,TDM Can't recall new item 了 ?? This is a little unbearable .
The method I heard is :
New materials are just TDM There is no embedding, But it usually has embedding. This is because , Twin tower online learning It's simple , Even new materials , Because the twin towers can use division id Other features besides , Get new materials item embedding And it's easy .
New materials are coming A, Go to the twin towers item embedding Check for new materials embedding, And then in the twin towers item embedding Of faiss Find an old material closest to this new material B
hold A insert B Of parent node Next , this time A There is a place in the tree , Also have been searched 、 Opportunities to be trained .
For the next day ,A Just stay in the tree , It may not be the most suitable location . Until the next morning , Today's tree is abandoned , Use one of the twin towers item embedding Build a new tree ,A Maybe there is a new position more suitable for it .
If in the way I heard , Just one question :
Even though TDM It breaks through the limit that two towers can only dot product , But because of TDM In increment 、 Deficiencies in cold start , It cannot replace the status of the twin towers in the recall . The twin towers are recalled YYDS!!!
TDM It's a system , Can't get rid of other recalls , fight alone—do sth. on one's own .
I don't know everyone is practicing TDM when , How to solve the problem of online incremental learning ? Can you make TDM“ Stand alone ”?
Different weights for non leaf nodes ?
TDM Is to calculate on each node binary cross entropy, Add it up
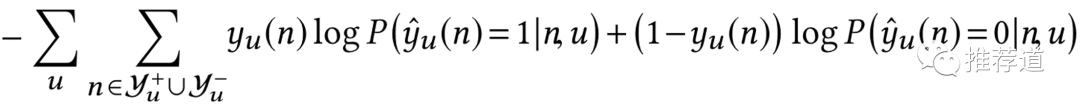
The sum in the formula does not distinguish the level of the node , Positive and negative nodes at different levels , stay loss Equal treatment in .
But this kind of “ Make no exception ” Should I ? I've thought about two completely different views .
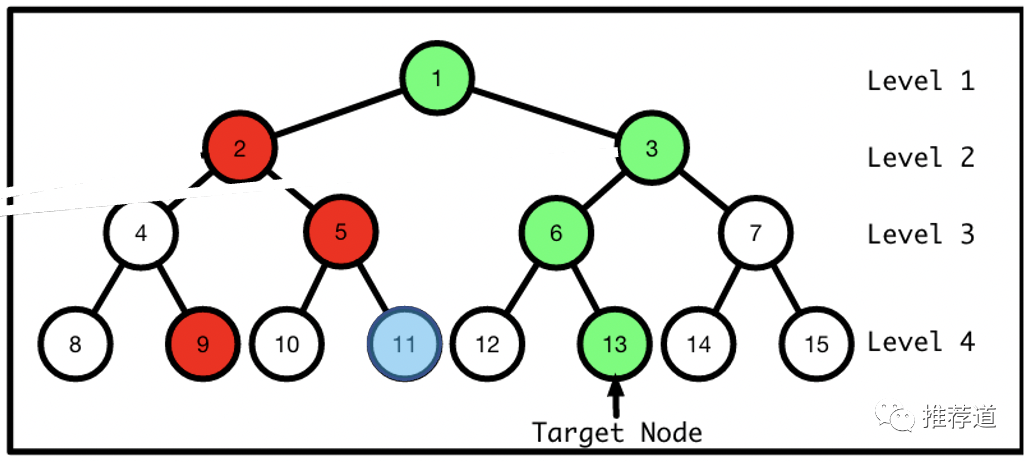
One idea is , The higher the level of nodes , If the prediction is wrong , The more serious the consequences , So the weight should be larger . Like in the picture above , If the model puts 3 Node number is wrong , Even if the model can 6、13 The number is right , It doesn't help .
Another idea is , The upper node , its label The more water you have , Should not be taken seriously . Like in the picture above 13 Node number is target node, Go back all the way , therefore 3 Node number is a positive sample ,2 No. is a negative sample ; If the next sample , The same user clicked 11 Number , Then in the first place 2 layer , It should be 2 No. is a positive sample ,3 No. is a negative sample , This will make the model at a loss . This idea is also very intuitive , The nodes in the upper layer represent the coarser grained interests , A user can be sure whether he likes 《 Kill the Wolf 》, But ask him if he likes “ Action movies ”、 Do you like “ Hong Kong film ”、 Do you like “ The movie ”, This user may say it depends.
Maybe it's because both sides have opinions , So at present, the positive and negative nodes at all levels are treated equally , That's enough .
summary
Recently, I revisited TDM Algorithm , Put forward three questions from the perspective of actual combat .
First of all ,TDM Medium item Can I only use item id This feature ?
I guess , Yes . because non-leaf node Only id features .
second ,TDM How to realize online learning 、 Incremental updating ?
I've heard of a practice :
Using the twin towers item embeding, Build the tree every morning , Then keep it for a day , The tree structure is not updated
TDM Connect kafka, With the latest data , to update user feature embedding、 Old material feature embedding、dnn Those of weight Equal parameter .
about new item, Get its... Through the twin towers embedding And find the closest old item, Give Way new item And nearest old item Become brothers , Connect to the same parent below . such new item I found my place in the tree , You get the retrieved 、 Opportunities to be trained .
Third , Whether it should be given according to the level non-leaf Different weights of nodes ?
I thought about , Give different weights according to the hierarchy , Cut both ways . It seems , Maintain the status quo , Just treat nodes at all levels equally .
These are my personal views , Please practice TDM The boss of .
Communicate together
I want to learn and progress with you !『NewBeeNLP』 At present, many communication groups in different directions have been established ( machine learning / Deep learning / natural language processing / Search recommendations / Figure network / Interview communication / etc. ), Quota co., LTD. , Quickly add the wechat below to join the discussion and exchange !( Pay attention to it o want Notes Can pass )


边栏推荐
- Dynamics 365 find field filtering
- leetcode-520. 检测大写字母-js
- JS get the key and value of the object
- HDU 4747 Mex「建议收藏」
- MySQL Index Optimization Practice II
- Ros2 topic (03): the difference between ros1 and ros2 [02]
- UE4_UE5蓝图command节点的使用(开启关闭屏幕响应-log-发布全屏显示)
- CXF call reports an error. Could not find conduct initiator for address:
- Unity3D学习笔记5——创建子Mesh
- Network security -beef
猜你喜欢




随机推荐
Opencv scalar passes in three parameters, which can only be displayed in black, white and gray. Solve the problem
13、 System optimization
PMP项目管理考试过关口诀-1
Introduction to redis and jedis and redis things
十三、系统优化
Dynamics 365 find field filtering
2022 届的应届生都找到工作了吗?做自媒体可以吗?
高级程序员必知必会,一文详解MySQL主从同步原理,推荐收藏
Network security -burpsuit
Network security - joint query injection
智慧社區和智慧城市之間有什麼异同
Ros2 topic (03): the difference between ros1 and ros2 [01]
Archlinux install MySQL
UE4_UE5全景相机
USB(十四)2022-04-12
Unity3D学习笔记5——创建子Mesh
Description of longitude and latitude PLT file format
JMeter-接口自动化测试读取用例,执行并结果回写
USB (十八)2022-04-17
Network security - install CentOS