当前位置:网站首页>Mobile heterogeneous computing technology - GPU OpenCL programming (basic)
Mobile heterogeneous computing technology - GPU OpenCL programming (basic)
2022-07-07 23:28:00 【Microservice technology sharing】
One 、 Preface
With the continuous improvement of mobile terminal chip performance , Real time computer graphics on the mobile terminal 、 Deep learning, model reasoning and other computing intensive tasks are no longer a luxury . On mobile devices ,GPU With its excellent floating-point performance , And good API Compatibility , Become a very important computing unit in mobile heterogeneous computing . At this stage , stay Android Equipment market , qualcomm Adreno And Huawei Mali Has occupied the mobile phone GPU The main share of chips , Both provide strong GPU Computing power .OpenCL, As Android System library of , It is well supported on both chips .
at present , Baidu APP Have already put GPU Computational acceleration means , It is applied to deep model reasoning and some computing intensive businesses , This article will introduce OpenCL Basic concepts and simple OpenCL Programming .
( notes :Apple about GPU The recommended way of use is Metal, Expansion is not done here )
Two 、 Basic concepts
2.1 Heterogeneous computing
Heterogeneous computing (Heterogeneous Computing), It mainly refers to the computing mode of the system composed of computing units with different types of instruction sets and architectures . Common cell categories include CPU、GPU And so on 、DSP、ASIC、FPGA etc. .
2.2 GPU
GPU(Graphics Processing Unit), Graphics processor , Also known as display core 、 The graphics card 、 Visual processor 、 Display chip or drawing chip , It's a special kind of PC 、 The workstation 、 Game consoles and some mobile devices ( Like a tablet 、 Smart phones and so on ) A microprocessor that performs drawing operations on . Improve... In traditional ways CPU The way to improve computing power based on clock frequency and the number of cores has encountered the bottleneck of heat dissipation and energy consumption . although GPU The working frequency of a single computing unit is low , But it has more cores and parallel computing power . Compared with CPU,GPU The overall performance of - Chip area ratio , performance - The power consumption is higher than that of the .
3、 ... and 、OpenCL
OpenCL(Open Computing Language) Is a non-profit technology organization Khronos Group In charge of the heterogeneous platform programming framework , The supported heterogeneous platforms cover CPU、GPU、DSP、FPGA And other types of processors and hardware accelerators .OpenCL It mainly consists of two parts , Part is based on C99 The standard language used to write the kernel , The other part is to define and control the platform API.
OpenCL Similar to two other open industrial standards OpenGL and OpenAL , They are used in three-dimensional graphics and computer audio respectively .OpenCL Mainly expanded GPU Computing power beyond graphics generation .
3.1 OpenCL Programming model
Use OpenCL Programming needs to know OpenCL Three core models of programming ,OpenCL platform 、 Execution and memory models .
Platform model (Platform Model)
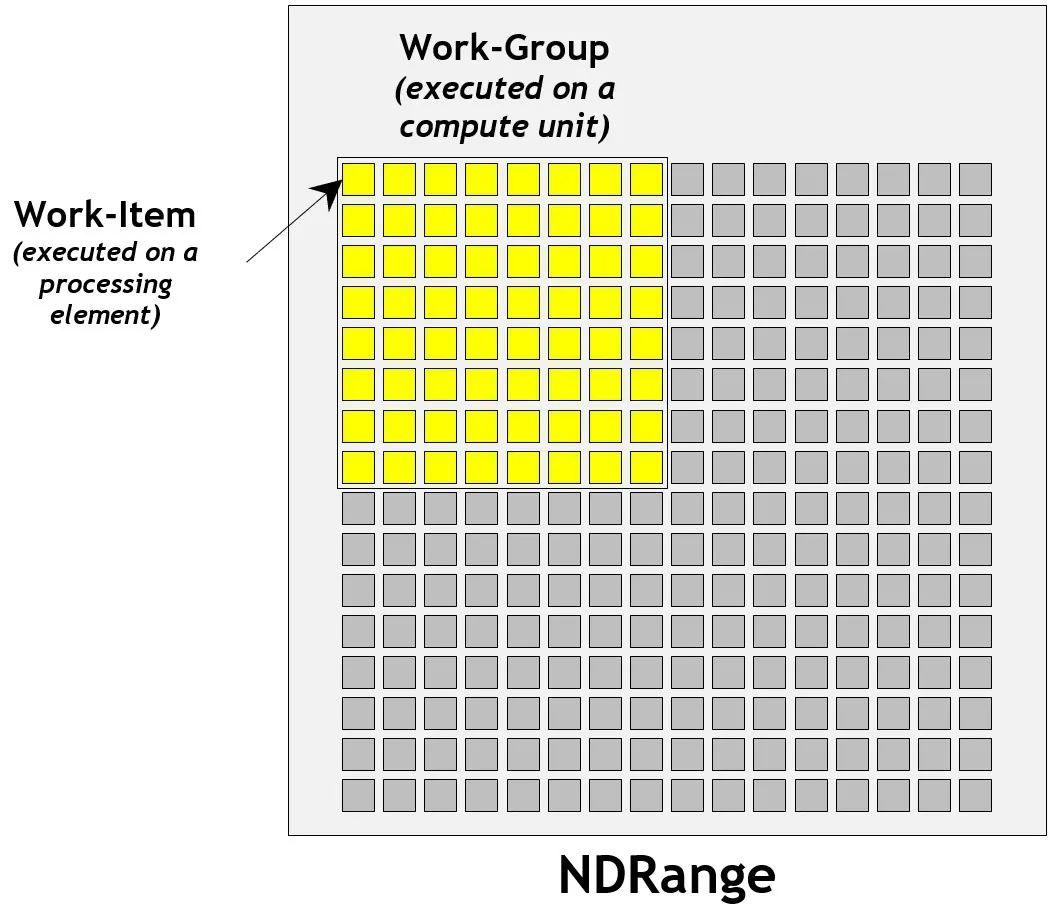
Platform representative OpenCL The topological relationship between computing resources in the system from the perspective of . about Android equipment ,Host That is CPU. Every GPU Computing equipment (Compute Device) Both contain multiple computing units (Compute Unit), Each cell contains multiple processing elements (Processing Element). about GPU for , Computing units and processing elements are GPU Streaming multiprocessor in .

Execution model (Execution Model)
adopt OpenCL Of clEnqueueNDRangeKernel command , You can start precompiled OpenCL kernel ,OpenCL The architecture can support N Dimensional data parallel processing . Take a two-dimensional picture as an example , If you take the width and height of the picture as NDRange, stay OpenCL The kernel of can put each pixel of the picture on a processing element to execute , Thus, the goal of parallel execution can be achieved .
From the platform model above, we can know , In order to improve the efficiency of execution , Processors usually allocate processing elements to execution units . We can do it in clEnqueueNDRangeKernel Specify workgroup size in . Work items in the same workgroup can share local memory , Barriers can be used (Barriers) To synchronize , You can also use specific workgroup functions ( such as async_work_group_copy) To collaborate .

Memory model (Memory Model)
The following figure describes OpenCL Memory structure :
Host memory (Host Memory): host CPU Directly accessible memory .
overall situation / Constant memory (Global/Constant Memory): It can be used for all computing units in the computing device .
Local memory (Local Memory): Available for all processing elements in the computing unit .
Private memory (Private Memory): For a single processing element .

3.2 OpenCL Programming
OpenCL Some engineering encapsulation is needed in the practical application of programming , This article only takes the addition of two arrays as an example , And provide a simple example code as a reference ARRAY_ADD_SAMPLE (https://github.com/xiebaiyuan/opencl_cook/blob/master/array_add/array_add.cpp).
This article will use this as an example , To illustrate OpenCL workflow .
OpenCL The overall process is mainly divided into the following steps :
initialization OpenCL Related to the environment , Such as cl_device、cl_context、cl_command_queue etc.
cl_int status;
// init device
runtime.device = init_device();
// create context
runtime.context = clCreateContext(nullptr, 1, &runtime.device, nullptr, nullptr, &status);
// create queue
runtime.queue = clCreateCommandQueue(runtime.context, runtime.device, 0, &status);
Initialization program to execute program、kernel
cl_int status;
// init program
runtime.program = build_program(runtime.context, runtime.device, PROGRAM_FILE);
// create kernel
runtime.kernel = clCreateKernel(runtime.program, KERNEL_FUNC, &status);
Prepare input and output , Set to CLKernel
// init datas
float input_data[ARRAY_SIZE];
float bias_data[ARRAY_SIZE];
float output_data[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++) {
input_data[i] = 1.f * (float) i;
bias_data[i] = 10000.f;
}
// create buffers
runtime.input_buffer = clCreateBuffer(runtime.context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR, ARRAY_SIZE * sizeof(float), input_data, &status);
runtime.bias_buffer = clCreateBuffer(runtime.context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR, ARRAY_SIZE * sizeof(float), bias_data, &status);
runtime.output_buffer = clCreateBuffer(runtime.context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR, ARRAY_SIZE * sizeof(float), output_data, &status);
// config cl args
status = clSetKernelArg(runtime.kernel, 0, sizeof(cl_mem), &runtime.input_buffer);
status |= clSetKernelArg(runtime.kernel, 1, sizeof(cl_mem), &runtime.bias_buffer);
status |= clSetKernelArg(runtime.kernel, 2, sizeof(cl_mem), &runtime.output_buffer);
Execute get results
// clEnqueueNDRangeKernel
status = clEnqueueNDRangeKernel(runtime.queue, runtime.kernel, 1, nullptr, &ARRAY_SIZE,
nullptr, 0, nullptr, nullptr);
// read from output
status = clEnqueueReadBuffer(runtime.queue, runtime.output_buffer, CL_TRUE, 0,
sizeof(output_data), output_data, 0, nullptr, nullptr);
// do with output_data
...
Four 、 summary
With CPU The arrival of the bottleneck ,GPU Or the programming of other special computing devices will be an important technical direction in the future .
边栏推荐
- FPGA基础篇目录
- UE4_ Ue5 combined with Logitech handle (F710) use record
- Description of longitude and latitude PLT file format
- Adults have only one main job, but they have to pay a price. I was persuaded to step back by personnel, and I cried all night
- Vs extension tool notes
- V-for traversal object
- POJ2392 SpaceElevator [DP]
- UE4_UE5结合罗技手柄(F710)使用记录
- Cloud native data warehouse analyticdb MySQL user manual
- Bea-3xxxxx error code
猜你喜欢

Oracle-数据库的备份与恢复

Mysql索引优化实战一
![MATLAB signal processing [Q & A essays · 2]](/img/be/0baa92767c3abbda9b0bff47cb3a75.png)
MATLAB signal processing [Q & A essays · 2]

B_QuRT_User_Guide(36)

Adults have only one main job, but they have to pay a price. I was persuaded to step back by personnel, and I cried all night
13、 System optimization
移动端异构运算技术 - GPU OpenCL 编程(基础篇)
UE4_ Use of ue5 blueprint command node (turn on / off screen response log publish full screen display)
Live-Server使用
Oracle database backup and recovery
随机推荐
经纬度PLT文件格式说明
PCB wiring rules of PCI Express interface
Unity3d learning notes 4 - create mesh advanced interface
USB (XV) 2022-04-14
Solution of intelligent supply chain collaboration platform in electronic equipment industry: solve inefficiency and enable digital upgrading of industry
B_QuRT_User_Guide(38)
Unity3D学习笔记5——创建子Mesh
Adrnoid Development Series (XXV): create various types of dialog boxes using alertdialog
漏洞复现----49、Apache Airflow 身份验证绕过 (CVE-2020-17526)
UE4_UE5蓝图command节点的使用(开启关闭屏幕响应-log-发布全屏显示)
HDU 4747 mex "recommended collection"
USB (XVIII) 2022-04-17
PHP uses Alibaba cloud storage
Explain
移动端异构运算技术 - GPU OpenCL 编程(基础篇)
Illegal behavior analysis 1
[compilation principle] lexical analysis design and Implementation
力扣解法汇总648-单词替换
Install Fedora under RedHat
B_ QuRT_ User_ Guide(37)