当前位置:网站首页>[neural network] convolutional neural network CNN [including Matlab source code 1932]
[neural network] convolutional neural network CNN [including Matlab source code 1932]
2022-07-07 11:55:00 【Poseidon light】
One 、 How to get the code
How to get the code 1:
The complete code has been uploaded to my resources :【 neural network 】 Convolutional neural networks CNN【 contain Matlab Source code 1932 period 】
How to get the code 2:
By subscribing to Ziji Shenguang blog Paid column , With proof of payment , Private Blogger , This code is available .
remarks :
Subscribe to Ziji Shenguang blog Paid column , Free access to 1 Copy code ( The period of validity From the Subscription Date , Valid for three days );
Two 、 Convolutional neural networks CNN brief introduction
1 Neuron
Neuron is the basic processing unit of artificial neural network , Generally, it is a multi input single output unit , Its structural model is shown in Figure 1 Shown . among :xi Represents the input signal ;n Multiple input signals are input to neurons at the same time j.wij Represents the input signal xi And neurons j The weight value of the connection , bj Indicates the internal state of neurons, i.e. bias value , yj For the output of neurons . The corresponding relationship between input and output can be expressed by the following formula :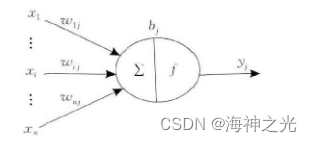
chart 1 Neuron model 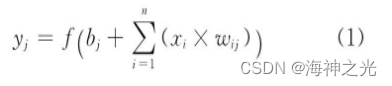
f (·) Is the excitation function , There are many options , It can be a linear correction function (Rectified Linear Unit, ReLU) [25], sigmoid function 、tanh (x) function 、 Radial basis function, etc .
2 Multilayer perceptron
Multilayer perceptron (Multilayer Perceptron, MLP) By the input layer 、 Hidden layer ( One or more layers ) And the neural network model composed of the output layer , It can solve the linear inseparable problem that cannot be solved by single-layer perceptron . chart 2 Contains 2 A hidden layer multilayer perceptron network topology diagram .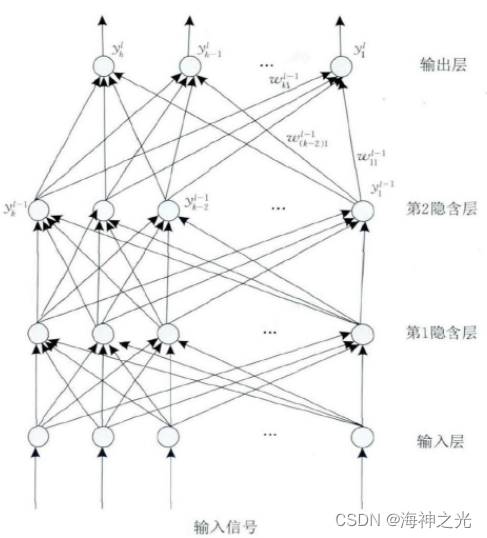
chart 2 Structure diagram of multilayer perceptron
Input layer neurons receive input signals , Each neuron of the hidden layer and the output layer is connected with all neurons of its adjacent layer , Full connection , Neurons in the same layer are not connected . chart 2 in , The line segment with arrow indicates the connection between neurons and the direction of signal transmission , And each connection has a connection weight . The input of each neuron in the hidden layer and the output layer is the weighted sum of the output values of all neurons in the previous layer . hypothesis xml yes MLP pass the civil examinations l Layer m Input values of neurons , yml and bml Are the output value and bias value of the neuron respectively , wiml-1 For this neuron and the l-1 Layer i The connection weight of neurons , Then there are :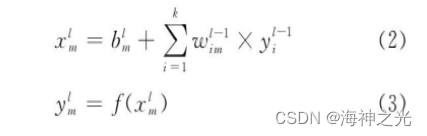
When multilayer perceptron is used for classification , The number of input neurons is the dimension of the input signal , The number of output neurons is the number of categories , The number of hidden layers and hidden layer neurons depends on the specific situation . But in practice , Due to the influence of parameter learning efficiency , Generally no more than 3 Shallow model of layer .BP The algorithm can be divided into two stages : Forward propagation and backward propagation , Backward propagation begins with MLP The output layer of . In an effort to 2 For example , Then the loss function is 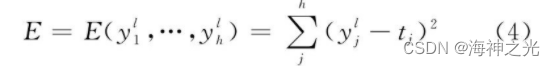
Among them the first l Layer is the output layer , tj For output layer No j Expected output of neurons , Find the first-order partial derivative of the loss function , Then the network weight update formula is 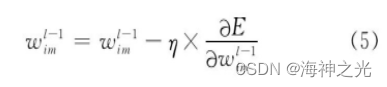
among , η For learning rate .
3 CNN
1962 year , biologist Hubel and Wiesel[28] Through the study of cat visual cortex , It is found that there are a series of cells with complex structures in the visual cortex , These cells are sensitive to local areas of the visual input space , They are called “ Feel the field ”. The receptive field covers the whole visual field in some way , It plays a local role in the input space , Therefore, it can better mine the strong local spatial correlation existing in natural images . The literature [28] These cells, called receptive fields, are divided into simple cells and complex cells . according to HubelWiesel Hierarchical model of , Neural networks in the visual cortex have a hierarchical structure : Lateral geniculate body → Simple cells → Complex cells → Low order hypercomplex cells → High order hypercomplex cells [29]. The neural network structure between low-order hypercomplex cells and high-order hypercomplex cells is similar to that between simple cells and complex cells . In this hierarchy , Cells at higher stages usually have such a tendency : Selectively respond to more complex features of stimulus patterns ; At the same time, it also has a larger feeling field , More insensitive to changes in the location of the stimulus pattern [29].1980 year , Fukushima according to Huble and Wiesel The hierarchical model proposed a neurocognitive machine with a similar structure (Neocognitron) [29]. The neurocognitive machine uses a simple cell layer (S-layer, S layer ) And complex cell layer (C-layer, C layer ) Alternate composition , among S Layer and Huble-Wiesel The simple cell layer or the low-order super complex cell layer in the hierarchical model corresponds to , C Layer corresponds to complex cell layer or high-order hypercomplex cell layer .S The layer can respond to specific edge stimuli in the receptive field to the greatest extent , Extract the local features of its input layer , C The layer is locally insensitive to stimuli from the exact location . Although not in neurocognitive machines like BP The global supervised learning process like algorithm can be used , But it can still be considered CNN The first project to realize the network , Convolution and pooling ( Also known as down sampling ) Inspired by Hubel-Wiesel The concept of simple cells and complex cells , It can accurately identify the input mode with displacement and slight deformation [29,30]. And then , LeCun And so on Fukushima The research work uses BP The algorithm is designed and trained CNN ( The model is called LeNet-5) , LeNet-5 It's classic CNN structure , There are many subsequent works to improve based on this , It has achieved good classification results in some areas of pattern recognition [19].
CNN The basic structure of consists of an input layer 、 Convolution layer (convolutional layer) 、 Pooling layer (pooling layer, Also known as sampling layer ) 、 Full connection layer and output layer . Convolution layer and pooling layer generally take several , Convolution layer and pool layer are set alternately , That is, a volume layer is connected to a pool layer , After the pool layer, connect a convolution layer , And so on . Because each neuron of the output characteristic surface in the convolution layer is locally connected with its input , And through the corresponding connection weight and local input for weighted sum, plus the offset value , Get the neuron input value , This process is equivalent to the convolution process , CNN It's also called .
3.1 Convolution layer
The convolution layer consists of multiple characteristic surfaces (Feature Map) form , Each feature plane is composed of multiple neurons , Each of its neurons is connected to the local area of the upper feature plane through convolution nucleus . The convolution kernel is a weight matrix ( For example, for two-dimensional images, it can be 3×3 or 5×5 matrix ) [19,31].CNN The convolution layer extracts different features of the input through convolution operation , The first 1 Convolution layer extracts low-level features such as edges 、 line 、 Corner , Higher level convolution layer extracts higher-level features (1) . In order to better understand CNN, Let's take one dimension CNN (1D CNN) For example , Two and three dimensions CNN It can be expanded accordingly . chart 3 One dimensional is shown CNN Structure diagram of convolution layer and pooling layer of , The top layer is the pool layer , The middle layer is a convolution layer , The bottom layer is the input layer of the convolution layer .
From the figure 3 It can be seen that the neurons of the convolution layer are organized into various feature planes , Each neuron is connected to the local area of the upper feature plane through a set of weights , That is, the neurons in the convolution layer are locally connected with the characteristic surface in its input layer . Then the local weighted sum is transferred to a nonlinear function such as ReLU Function to obtain the output value of each neuron in the convolution layer . In the same input feature plane and the same output feature plane , CNN Weight sharing , Pictured 3 Shown , Weight sharing occurs in the same color , Different color weights are not shared . Through weight sharing, we can reduce 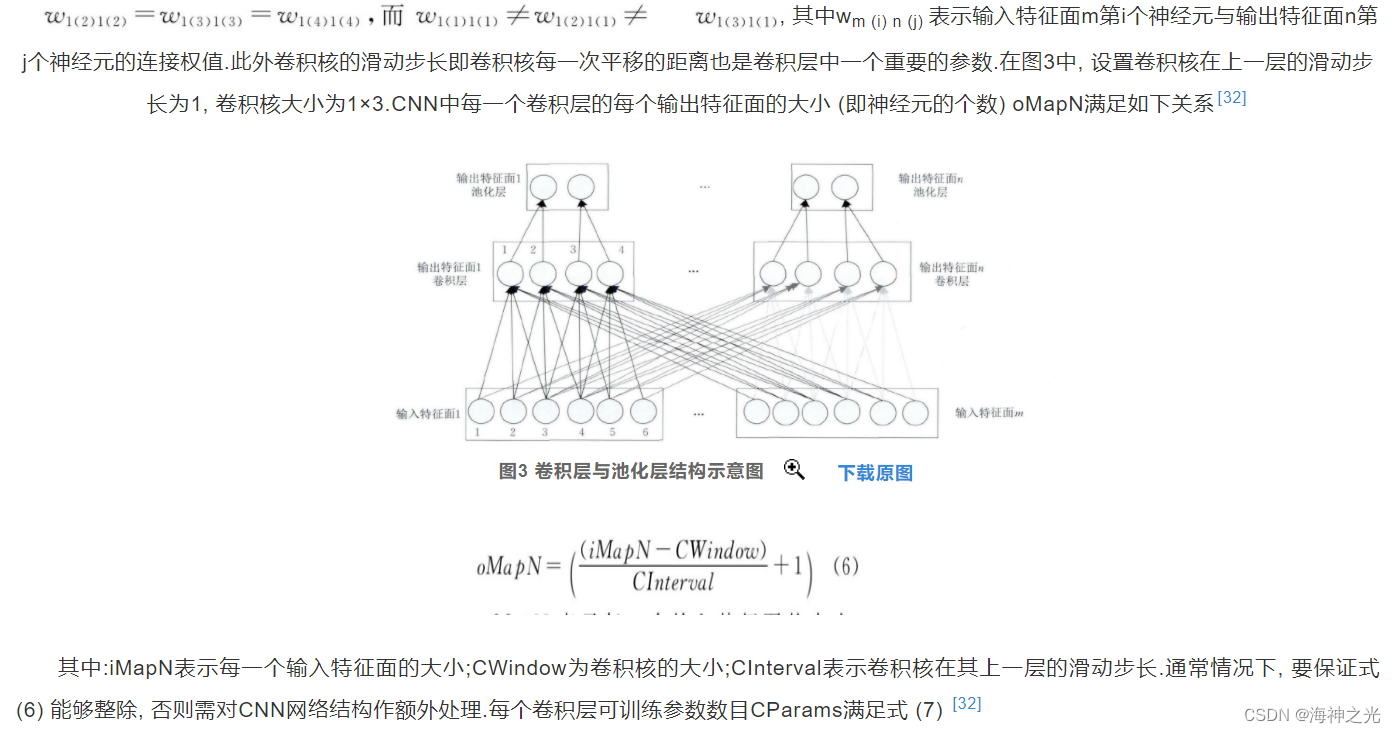
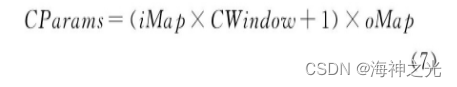
among :oMap Output the number of characteristic surfaces for each convolution layer ;iMap Is the number of input characteristic surfaces .1 Represents offset , Offsets are also shared in the same output feature plane . Suppose that the characteristic surface is output in the convolution layer n The first k The output value of neurons is xnkout, and xmhin Represents its input characteristic surface m The first h The output value of a neuron , In an effort to 3 For example , be .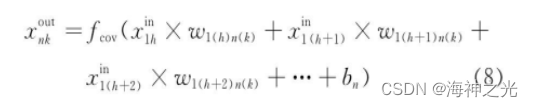
type (8) in , bn Is the output feature surface n The offset value of .fcov (·) Is a nonlinear excitation function . In traditional CNN in , The excitation function generally uses a saturated nonlinear function (saturating nonlinearity) Such as sigmoid function 、tanh Functions, etc . Compared with saturated nonlinear function , Unsaturated nonlinear function (non-saturating nonlinearity) It can solve the gradient explosion / The gradient vanishing problem , At the same time, it can also accelerate the convergence speed [33].Jarrett wait forsomeone [34] Different nonlinear correction functions in convolution networks are discussed (rectified nonlinearity, Include max (0, x) Nonlinear functions ) , Experiments show that they can significantly improve the performance of convolutional Networks , Nair wait forsomeone [25] This conclusion is also verified . So at present CNN Unsaturated nonlinear function is often used as the excitation function of convolution layer in structures, such as ReLU function .ReLU The calculation formula of the function is as follows 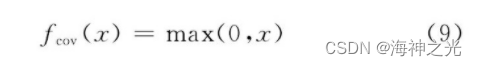
chart 4 The middle solid line is ReLU curve , The dotted line is tanh curve . about ReLU for , If the input is greater than 0, Then the output is equal to the input , Otherwise, the output is 0. From the picture 4 It can be seen that , Use ReLU function , The output will not become saturated with the gradual increase of input .Chen The impact is analyzed in its report CNN The performance of the 3 One factor : The layer number 、 Number of feature planes and network organization (1) . This report uses 9 A structural CNN Carry out Chinese handwriting recognition experiment , Through the statistical test results, we get CNN Some conclusions of structure : (1) Increasing the depth of the network can improve the accuracy ; (2) Increasing the number of feature planes can also improve the accuracy ; (3) Adding a convolution layer can obtain a higher accuracy than adding a full connection layer .Bengio wait forsomeone [35] It is pointed out that the deep network structure has two advantages : (1) It can promote the reuse of features ; (2) Be able to obtain more abstract features in high-level expression , Because more abstract concepts can be constructed according to less abstract concepts , Therefore, deep structure can obtain more abstract expression , For example, in CNN This abstraction is established through pooling operations , More abstract concepts are usually invariant to most local changes in input .He wait forsomeone [36] This paper discusses how to balance the limitation of computational complexity and time CNN Depth in network structure 、 Number of feature surfaces 、 Convolution kernel size and other factors . The literature first studies the depth (Depth) And the size of convolution kernel , Use a smaller convolution kernel instead of a larger convolution kernel , At the same time, increase the network depth to increase the complexity , The experimental results show that the network depth is more important than the convolution kernel size ; When the time complexity is roughly the same , With smaller convolution kernel and deeper CNN The structure has a larger convolution core and a shallower depth CNN The structure can obtain better experimental results . secondly , This paper also studies the relationship between network depth and the number of feature planes , CNN The network structure is set to : When increasing the network depth, appropriately reduce the number of feature planes , At the same time, the size of convolution kernel remains unchanged , Experimental results show that , The deeper the depth , The better the performance of the network ; However, as the depth increases , Network performance is also gradually reaching saturation . Besides , This paper also studies the relationship between the number of characteristic surfaces and the size of convolution kernel through fixed network depth , Through the comparison of experiments , It is found that the priority of the number of feature surfaces and the size of convolution kernel is about the same , Its role is not as deep as the network .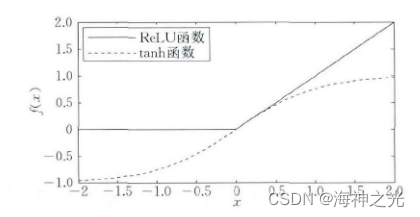
chart 4 ReLU And tanh Function graph
stay CNN In structure , The deeper the depth 、 The more feature planes there are , The larger the feature space that the network can represent 、 The stronger the ability of e-learning , However, it will also make the calculation of the network more complex , It is very easy to over fit . thus , The network depth should be properly selected in practical application 、 Number of feature surfaces 、 The size of convolution kernel and the sliding step during convolution , So that the training can obtain a good model and reduce the training time .
3.2 Pooling layer
The pool layer follows the convolution layer , It is also composed of multiple feature surfaces , Each feature surface of it uniquely corresponds to a feature surface of its upper layer , It will not change the number of characteristic surfaces . Pictured 3, The convolution layer is the input layer of the pooling layer , A characteristic surface of the convolution layer uniquely corresponds to a characteristic surface in the pool layer , And the neurons in the pool layer are also connected to the local receiving domain of its input layer , The local receptive domains of different neurons do not overlap . The purpose of pooling layer is to obtain spatial invariant features by reducing the resolution of feature surface [37]. The pooling layer plays the role of secondary feature extraction , Each of its neurons pool the local acceptance domain . Common pooling methods include maximum pooling, that is, taking the point with the largest value in the local acceptance domain 、 Mean pooling is to find the mean of all values in the local acceptance domain 、 Random pooling [38,39].Boureau wait forsomeone [40] A detailed theoretical analysis of maximum pooling and mean pooling is given , Through analysis, we can get the following predictions : (1) Maximum pooling is especially suitable for separating very sparse features ; (2) It may not be optimal to use all sampling points in a local area to perform pooling operations , For example, mean pooling makes use of all sampling points in the local acceptance domain .Boureau wait forsomeone [41] The two methods of maximum pooling and mean pooling are compared , It is found through experiments that : When the classification layer adopts linear classifier, such as linear SVM when , Maximum pooling method can achieve a better classification performance than mean pooling . The random pooling method is to assign a probability value to the sampling point in the local acceptance domain according to its value , Then select randomly according to the probability value , This pooling method ensures that neurons in the feature plane that are not the maximum excitation can also be utilized [37]. Random pooling has the advantage of maximum pooling , At the same time, it can avoid over fitting due to randomness . Besides , And mixing pooling 、 Space Pyramid pooling 、 Spectrum pooling and other pooling methods [37]. In the commonly used pooling method , Different neurons on the same characteristic plane of the pool layer do not overlap with the local acceptance domain of the upper layer , However, overlapping pooling can also be used . The so-called overlapping pooling method is that there are overlapping areas between adjacent pooling windows .Krizhevsky The overlapping pooling framework is adopted to make top-1 and top-5 The error rate of each of them is reduced 0.4% and 0.3%, Compared with the non overlapping pooling framework , Its generalization ability is stronger , More difficult to produce over fitting . Set the second in the pool layer n Output characteristic surface No l The output value of neurons is tnlout, In the same way 3 For example , Then there are :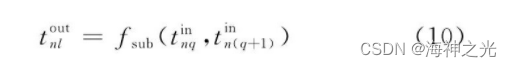
among :tnqin Represents the... Of the pool layer n The first input feature plane q The output value of a neuron ;fsub (·) It can be a function with maximum value 、 Take the mean function, etc .
The window where the pool layer slides on the upper layer is also called the pool core . in fact , CNN The convolution kernel and pooling kernel in are equivalent to HubelWiesel The realization of the receptive field in the model in Engineering , Convolution layer is used to simulate Hubel-Wiesel Simple cells of theory , The pool layer simulates the complex cells of this theory .CNN The size of each output characteristic surface of each pool layer in ( Number of neurons ) DoMapN by 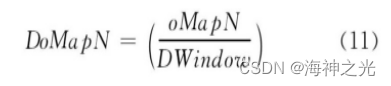
among , The size of the pooled core is DWindow, In the figure 3 in DWindow=2. Pooling layer reduces the number of connections between convolution layers , That is, the number of neurons is reduced by pooling , It reduces the calculation of the network model .
3.3 Fully connected layer
stay CNN In structure , After multiple convolution layers and pooling layers , Connected to 1 Or 1 More than one fully connected layer . And MLP similar , Each neuron in the full connectivity layer is fully connected to all neurons in the previous layer . The fully connected layer can integrate local information with class differentiation in the convolution layer or pooling layer [42]. In order to improve CNN network performance , The excitation function of each neuron in the full connectivity layer is usually ReLU function [43]. The output value of the last full connection layer is passed to an output layer , May adopt softmax Logical regression (softmax regression) To classify , This layer can also be called softmax layer (softmax layer) . For a specific classification task , It is very important to choose an appropriate loss function , Gu wait forsomeone [37] It introduces CNN Several commonly used loss functions and their respective characteristics are analyzed . Usually , CNN The whole connection layer of and MLP Same structure , CNN Most of the training algorithms are BP Algorithm .
When a large feedforward neural network trains a small data set , Because of its high capacity , It is storing test data (held-out test data, It can also be called a check set ) Usually underperforms in business [30]. In order to avoid training over fitting , Regularization method is often used in the full connection layer ——— Lost data (dropout) technology , Even if the output value of hidden layer neurons is 0.5 The probability becomes 0, Through this technology, some hidden layer nodes fail , These nodes do not participate CNN Forward propagation process of , And will not participate in the backward communication process [24,30]. For each sample input into the network , because dropout The randomness of Technology , Its corresponding network structure is different , But all these structures share weights [24]. Because a neuron cannot depend on other specific neurons , So this technology reduces the complexity of mutual adaptation between neurons , So that neuron learning can get more robust features [24]. at present , About CNN Most of the studies used ReLU+dropout technology , And achieved good classification performance [24,44,45].
3.4 Characteristic surface
The number of feature surfaces is taken as CNN An important parameter of , It is usually set according to the actual application , If the number of feature surfaces is too small , It may cause some features conducive to e-learning to be ignored , This is not conducive to network learning ; But if there are too many characteristic surfaces , The number of training parameters and network training time will also increase , This is also not conducive to learning the network model .Chuo wait forsomeone [46] A theoretical method is proposed to determine the optimal number of feature planes , However, this method is only effective for the minimal acceptance domain , It cannot be extended to any size of the accepted domain . The literature found through experiments : The same number of characteristic surfaces as each layer CNN Compared with the structure , Pyramid architecture ( The number of characteristic surfaces of the network structure increases by a multiple ) More efficient use of computing resources . at present , about CNN The number of network feature planes is usually set manually , Then experiment and observe the classification performance of the training model , Finally, the number of feature surfaces is selected according to the network training time and classification performance .
3.5 CNN Further description of the structure
CNN The implementation process of has actually included the feature extraction process , In an effort to 5、 chart 6 As an example, it shows CNN Extracted features .Cao wait forsomeone [47] use CNN Conduct fingerprint direction field evaluation , chart 5 For its model structure . chart 5 share 3 Convolution layers (C1, C3, C5) 、2 A pool layer (M2, M4) 、1 All connection layers (F6) and 1 Output layers (O7) . The size entered is 160×160, C1 in 96×11×11×1 (4) Express C1 Layer has a 96 Size is 11×11 Convolution kernel , 1 Input the number of characteristic surfaces for it , 4 Is the sliding step size of convolution kernel on its input characteristic surface , 38×38 For each output feature surface size . The convolution layer extracts various local features of the previous layer through convolution operation , From the figure 5 It can be seen that , C1 Layer extract the edge of the input image 、 Contour feature , It can be regarded as an edge detector . The role of the pooling layer is to combine similar features semantically , The pooling layer makes the feature robust to noise and deformation through pooling operation [11]. As can be seen from the picture , The features extracted from each layer represent the original image from different angles in an enhanced way , And as the number of layers increases , Its expression is more and more abstract [48]. Fully connected layer F6 Each neuron in is fully connected with its previous layer , This layer integrates various local features extracted in the early stage , Finally, the posterior probability of each category is obtained through the output layer . From the perspective of pattern classification , Satisfy Fisher The characteristics of the criteria are most conducive to classification , Through the regularization method (dropout Method ) , Network parameters are effectively adjusted , So that the features extracted from the full connection layer can meet Fisher Criterion , Finally, it is conducive to classification [48]. chart 6 given CNN Extract ECG (electrocardiogram, ECG) The process of characterizing , First, through the convolution unit A1、B1、C1 ( Each convolution unit includes a convolution layer and a pooling layer ) The extracted features , Finally, all local features are summarized by the full connection layer . It can also be seen from the figure , The higher the number of layers , The more abstract the expression of features . obviously , These features have no physical significance for clinical diagnosis , Just mathematical value [48].
3、 ... and 、 Partial source code
%%
X1=rand(100,2048);
X2=20*rand(100,2048); %%% Generate two kinds of random sequences with different amplitudes , As two types of samples to be classified
Xtrain1=[X1;X2];
for i=1:1:200
for j=1:1:2048
Xtrain(1,j,1,i)=Xtrain1(i,j);%% Input data dimension conversion
end
end
Four 、 Running results
5、 ... and 、matlab Edition and references
1 matlab edition
2014a
2 reference
[1] Baoziyang , Yu Jizhou , Poplar . Intelligent optimization algorithm and its application MATLAB example ( The first 2 edition )[M]. Electronic industry press ,2016.
[2] Zhang Yan , Wu Shuigen .MATLAB Optimization algorithm source code [M]. tsinghua university press ,2017.
[3] Zhou pin .MATLAB Neural network design and application [M]. tsinghua university press ,2013.
[4] state .MATLAB The principle of neural network and the explanation of examples [M]. tsinghua university press ,2013.
[5] Zhou Feiyan , Jinlinpeng , Dong Jun . A review of convolutional neural networks [M]. Journal of Computer Science . 2017,40(06)
3 remarks
This part of the introduction is taken from the Internet , For reference only , If infringement , Contact deletion
边栏推荐
- [filter tracking] strapdown inertial navigation simulation based on MATLAB [including Matlab source code 1935]
- Camera calibration (2): summary of monocular camera calibration
- Technology sharing | packet capturing analysis TCP protocol
- Time bomb inside the software: 0-day log4shell is just the tip of the iceberg
- 聊聊SOC启动(九) 为uboot 添加新的board
- 竟然有一半的人不知道 for 与 foreach 的区别???
- 110.网络安全渗透测试—[权限提升篇8]—[Windows SqlServer xp_cmdshell存储过程提权]
- 5V串口接3.3V单片机串口怎么搞?
- 清华姚班程序员,网上征婚被骂?
- La voie du succès de la R & D des entreprises Internet à l’échelle des milliers de personnes
猜你喜欢

浙江大学周亚金:“又破又立”的顶尖安全学者,好奇心驱动的行动派

What is cloud computing?
总结了200道经典的机器学习面试题(附参考答案)
How to connect 5V serial port to 3.3V MCU serial port?
正在运行的Kubernetes集群想要调整Pod的网段地址
Matlab implementation of Huffman coding and decoding with GUI interface
The Oracle message permission under the local Navicat connection liunx is insufficient
![[extraction des caractéristiques de texture] extraction des caractéristiques de texture de l'image LBP basée sur le mode binaire local de Matlab [y compris le code source de Matlab 1931]](/img/65/bf1d0f82878a49041e8c2b3a84bc15.png)
[extraction des caractéristiques de texture] extraction des caractéristiques de texture de l'image LBP basée sur le mode binaire local de Matlab [y compris le code source de Matlab 1931]
![[filter tracking] comparison between EKF and UKF based on MATLAB extended Kalman filter [including Matlab source code 1933]](/img/90/ef2400754cbf3771535196f6822992.jpg)
[filter tracking] comparison between EKF and UKF based on MATLAB extended Kalman filter [including Matlab source code 1933]

【最短路】ACwing 1127. 香甜的黄油(堆优化的dijsktra或spfa)
随机推荐
Ask about the version of flinkcdc2.2.0, which supports concurrency. Does this concurrency mean Multiple Parallelism? Now I find that mysqlcdc is full
【神经网络】卷积神经网络CNN【含Matlab源码 1932期】
相机标定(2): 单目相机标定总结
Learning notes | data Xiaobai uses dataease to make a large data screen
QT implements the delete method of the container
Visual Studio 2019 (LocalDB)\MSSQLLocalDB SQL Server 2014 数据库版本为852无法打开,此服务器支持782版及更低版本
[encapsulation of time format tool functions]
总结了200道经典的机器学习面试题(附参考答案)
R语言使用quantile函数计算评分值的分位数(20%、40%、60%、80%)、使用逻辑操作符将对应的分位区间(quantile)编码为分类值生成新的字段、strsplit函数将学生的名和姓拆分
R语言使用magick包的image_mosaic函数和image_flatten函数把多张图片堆叠在一起形成堆叠组合图像(Stack layers on top of each other)
STM32 entry development write DS18B20 temperature sensor driver (read ambient temperature, support cascade)
Stm32f1 and stm32subeide programming example -max7219 drives 8-bit 7-segment nixie tube (based on SPI)
【数据聚类】基于多元宇宙优化DBSCAN实现数据聚类分析附matlab代码
[filter tracking] strapdown inertial navigation simulation based on MATLAB [including Matlab source code 1935]
核舟记(一):当“男妈妈”走进现实,生物科技革命能解放女性吗?
R language uses image of magick package_ Mosaic functions and images_ The flatten function stacks multiple pictures together to form a stack layers on top of each other
Zhou Yajin, a top safety scholar of Zhejiang University, is a curiosity driven activist
【全栈计划 —— 编程语言之C#】基础入门知识一文懂
Two week selection of tdengine community issues | phase II
How to add aplayer music player in blog